
Наука о данных — это экспериментальная наука. Она берет свое начало с “Теоремы о бесплатном обеде”, которая гласит следующее: не существует универсального алгоритма, который бы лучше всего подходил для решения любой задачи. Именно поэтому ученые, занимающиеся исследованием данных, используют экспериментальные системы отслеживания, которые помогают им настраивать гиперпараметры проектов машинного обучения для достижения наилучшей производительности.
В этой статье будем рассматривать конвейер RAG (Retrieval-Augmented Generation — генерация с расширенным извлечением) с точки зрения специалиста по изучению данных. Мы обсудим потенциальные “гиперпараметры”, с которыми можно экспериментировать, чтобы улучшить производительность конвейера RAG. В качестве аналогии можно привести опыты в сфере глубокого обучения, где, например, методы расширения данных — это не гиперпараметры, а своеобразные рычаги, которые настраивают и с которыми проводят эксперименты. В этой статье мы также рассмотрим различные применимые стратегии настроек, сами по себе не являющиеся гиперпараметрами.
Мы обсудим нижеуказанные гиперпараметры, распределенные по соответствующим этапам. На этапе поглощения данных конвейером RAG можно добиться повышения производительности за счет:
- очистки данных;
- разбивки на фрагменты;
- эмбеддинг-моделей;
- использования метаданных;
- мультииндексации;
- алгоритмов индексирования.
На этапе вывода (извлечения и генерации) вы можете воспользоваться:
- преобразованием запросов;
- оптимизацией параметров извлечения;
- продвинутыми стратегиями извлечения;
- моделями повторного ранжирования;
- LLM;
- промпт-инжинирингом.
Обратите внимание: в этой статье рассматриваются варианты использования RAG по отношению к текстам. Для мультимодальных RAG-приложений могут применяться иные соображения.
Этап поглощения (Ingestion Stage)
Поглощение — это подготовительный этап для создания RAG-конвейера, аналогичный этапам очистки и предварительной обработки данных в МО-конвейере. Обычно этап поглощения состоит из следующих шагов:
- Сбор данных.
- Разбивка данных на фрагменты.
- Генерация векторных вложений фрагментов.
- Сохранение векторных вложений и фрагментов в векторной базе данных.
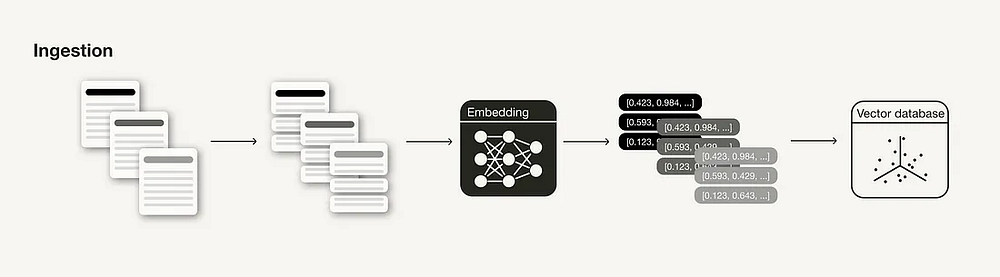
Далее речь пойдет об эффективных методах и гиперпараметрах, которые можно применять и настраивать для повышения релевантности извлеченных контекстов на этапе вывода.
Очистка данных
Как и в любом другом процессе науки о данных, качество данных в значительной степени влияет на результативность RAG-конвейера. Прежде чем переходить к следующим шагам, убедитесь, что данные соответствуют следующим критериям.
- Чистота. Примените хотя бы базовые методы очистки данных, обычно используемые в сфере обработки естественного языка (например, убедитесь в том, что специальные символы закодированы правильно).
- Корректность. Проверьте последовательность информации и ее фактологическую точность, чтобы исключить противоречивые данные, которые могут запутать LLM.
Разбивка на фрагменты
Разбивка документов на фрагменты — важный этап подготовки внешнего источника знаний в конвейере RAG, который может оказать определенное влияние на производительность. Это техника создания логически последовательных фрагментов информации, обычно путем разбиения длинных документов на более мелкие разделы (но можно также объединять более мелкие фрагменты в последовательные абзацы).
Важно учитывать один момент — выбор техники разбиения на фрагменты. Так, в LangChain различные разделители текста разбивают документы по разным логическим ориентирам, например по символам, токенам и т. д. Все зависит от типа имеющихся данных. Например, вам понадобятся разные техники разбиения на фрагменты для входных данных в виде кода и Markdown-файлов.
Идеальная длина фрагмента (chunk_size) зависит от сценария использования. Если цель — ответы на вопросы, могут понадобиться короткие конкретные фрагменты, а если задача заключается в резюмировании, полезными окажутся более длинные фрагменты. Вместе с тем следует помнить: слишком короткий фрагмент может не содержать достаточного контекста. С другой стороны, чересчур длинные фрагменты подчас содержат слишком много нерелевантной информации.
Кроме того, нужно позаботиться о “скользящем окне” между фрагментами (overlap) для ввода дополнительного контекста.
Эмбеддинг-модели
Эмбеддинг-модели являются основой процесса извлечения. Качество эмбеддингов влияет на результаты получения ответа. Обычно чем выше размерность генерируемых эмбеддингов, тем выше их точность.
Чтобы получить представление о том, какие существуют альтернативные эмбеддинг-модели, взгляните на таблицу Massive Text Embedding Benchmark (MTEB) Leaderboard, в которую попали 164 текстовые эмбеддинг-модели (на момент написания этой статьи).
Вы можете применять готовые эмбеддинг-модели общего назначения “из коробки”. Но в некоторых случаях имеет смысл точно настроить эмбеддинг-модель под конкретный кейс использования, чтобы в дальнейшем избежать проблем, связанных с выходом за рамки области применимости. Согласно экспериментам, проведенным LlamaIndex, точная настройка эмбеддинг-модели может привести к увеличению производительности на 5–10% в метриках оценки извлечения результата.
Обратите внимание: вы не можете точно настроить все эмбеддинг-модели (например, на данный момент нельзя точно настроить модель text-ebmedding-ada-002 от OpenAI).
Использование метаданных
Процесс хранения векторных эмбеддингов в векторной базе данных иногда предусматривает их совместное содержание с метаданными (или данными, не являющимися векторными). Аннотирование векторных эмбеддингов метаданными может быть полезно в ходе дополнительной постобработки результатов поиска, такой как фильтрация метаданных. Например, можно добавить такие метаданные, как дата, ссылка на главу или подглаву.
Мультииндексация
Если метаданных недостаточно, чтобы предоставить дополнительную информацию для логического разделения различных типов контекста, можно поэкспериментировать с несколькими индексами. Попробуйте использовать разные индексы для разных типов документов. Учтите, что вам придется включить маршрутизацию индексов во время процесса извлечения информации. Если хотите более глубоко погрузиться в метаданные и отдельные коллекции, можете узнать больше о концепции нативной мультиарендности.
Алгоритмы индексирования
Чтобы обеспечить полномасштабный молниеносный поиск сходств, векторные базы данных и библиотеки векторного индексирования используют поиск по принципу приближенного поиска ближайшего соседа (Approximate Nearest Neighbor, ANN) вместо поиска k-ближайших соседей (k-nearest neighbor, kNN). Как следует из названия, алгоритмы ANN аппроксимируют ближайших соседей и поэтому могут оказаться менее точными, чем алгоритм kNN.
Существуют различные ANN-алгоритмы, с которыми можно поэкспериментировать, например Facebook Faiss (кластеризация), Spotify Annoy (деревья), Google ScaNN (сжатие векторов) и HNSWLIB (графы близости). Кроме того, многие из этих ANN-алгоритмов обладают некоторыми параметрами, поддающимися настройке, например ef, efConstruction и maxConnections для HNSW.
Кроме того, можно включить сжатие векторов для этих алгоритмов индексирования. Как и в случае с ANN-алгоритмами, при сжатии векторов вы столкнетесь со снижением точности. Однако в зависимости от выбора алгоритма такого сжатия и его настройки можно оптимизировать и это.
Следует заметить, что на практике указанные параметры уже настраиваются не разработчиками RAG-систем, а исследовательскими группами, занимающимися векторными базами данных и библиотеками векторного индексирования, в ходе бенчмаркинговых экспериментов.
Этап вывода (извлечение и генерация)
Основными составляющими RAG-конвейера являются компоненты извлечения и генерации. Далее будут обсуждаться стратегии улучшения получения информации (преобразование запросов, оптимизация параметров извлечения, продвинутые стратегии извлечения и модели повторного ранжирования), так как компонент извлечения оказывает большее влияние на конечный результат, чем компонент генерации. Но мы также кратко затронем стратегии улучшения генерации (LLM и промпт-инжиниринг).
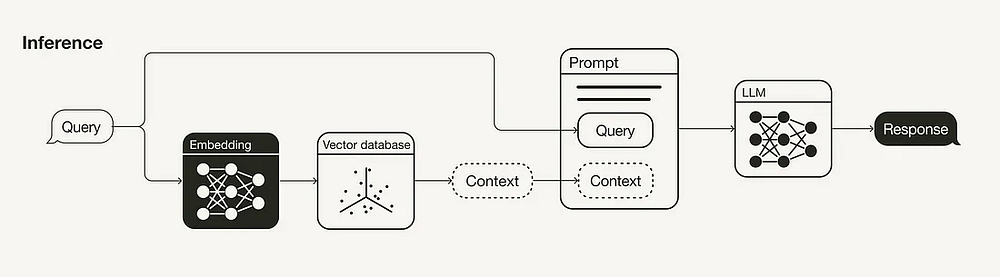
Поскольку поисковый запрос для извлечения дополнительного контекста в конвейере RAG также встраивается в векторное пространство, его формулировка может повлиять на выдачу поиска. Поэтому, если поисковый запрос не приводит к удовлетворительным результатам, попробуйте использовать различные техники преобразования запросов. Вот несколько примеров.
- Перефразирование. Используйте LLM, чтобы перефразировать запрос и повторить попытку.
- Гипотетические эмбеддинги документов (Hypothetical Document Embeddings, HyDE). Используйте LLM для генерации гипотетического ответа на поисковый запрос и задействуйте оба ответа для извлечения нужной информации.
- Подзапросы. Разбивайте длинные запросы на более короткие.
Оптимизация параметров извлечения
Извлечение — важный компонент конвейера RAG. В первую очередь необходимо решить, будет ли достаточно семантического поиска для вашего случая использования или нужно будет экспериментировать с гибридным поиском.
В последнем случае необходимо проводить эксперименты с весовыми коэффициентами агрегирования разреженных и плотных методов извлечения в рамках гибридного поиска. Таким образом, потребуется настройка параметра alpha, который управляет распределением веса между семантическим (alpha = 1) и основанным на ключевых словах поиском (alpha = 0).
Кроме того, важную роль играет количество результатов извлечения. Количество извлекаемых контекстов влияет на длину используемого контекстного окна (см. “Промпт-инжиниринг”). А если вы применяете модель повторного ранжирования, вам необходимо учитывать, сколько контекстов нужно ввести в модель (см. “Модели повторного ранжирования”).
Обратите внимание: хотя используемая мера сходства для семантического поиска — это параметр, который можно изменить, не стоит экспериментировать с ним. Лучше всего установить его в соответствии с применяемой эмбеддинг-моделью (например, text-embedding-ada-002 поддерживает косинусное сходство, а multi-qa-MiniLM-l6-cos-v1 — косинусное сходство, точечное произведение и евклидово расстояние).
Продвинутые стратегии извлечения
Технически этот раздел мог бы стать отдельной статьей. В данном обзоре постараюсь изложить его суть максимально кратко.
Основная идея заключается в том, что фрагменты для извлечения не обязательно должны быть фрагментами, которые использовались для генерации. В идеале нужно встраивать фрагменты меньшего размера для извлечения (см. “Разбивка на фрагменты”), но извлекать большие контексты.
- Извлечение окон предложений. Извлекайте не только соответствующее предложение, но и окно подходящих предложений до и после найденного.
- Извлечение на основе автослияния. Документы организованы в древовидную структуру. Во время запроса отдельные, но связанные между собой небольшие фрагменты можно объединять в более крупный контекст.
Модели повторного ранжирования
Несмотря на то, что семантический поиск извлекает контекст на основе его семантического сходства с поисковым запросом, “наиболее похожий” не обязательно означает “наиболее релевантный”. Модели повторного ранжирования, такие как модель компании Cohere, помогают исключить нерелевантные результаты поиска, вычисляя оценку релевантности запроса для каждого найденного контекста.
“Наиболее похожий” не обязательно означает “наиболее релевантный”.
Если вы используете модель повторного ранжирования, вам может потребоваться изменить количество результатов поиска на входе такой модели, а также количество результатов повторного ранжирования, которые нужно передать в большую языковую модель (LLM).
Как и в случае с эмбеддинг-моделями, можете поэкспериментировать с точной настройкой модели повторного ранжирования для конкретного случая использования.
LLM
LLM — основной компонент для генерации ответа. Существует обширный спектр LLM, которые можно выбрать в зависимости от требований (открытые и проприетарные модели, стоимость вывода, длина контекста и т. д.).
Как и в случае с эмбеддинг-моделями или моделями повторного ранжирования, LLM открывают широкое поле для экспериментов с точными настройками под конкретный случай использования (например, включение специфических формулировок или тона голоса).
Промпт-инжиниринг
От формулировки промпта во многом зависит результативность LLM.
Пожалуйста, обосновывай свой ответ только на результатах поиска
и ни на чем другом!
Очень важно! Твой ответ ДОЛЖЕН основываться на результатах поиска.
Пожалуйста, объясни, почему твой ответ основан на результатах поиска!
Кроме того, использование few-shot-примеров в промпте может улучшить качество работы модели.
Как уже упоминалось в разделе “Оптимизация параметров извлечения”, количество контекстов, подаваемых в промпт — это параметр, с которым стоит поэкспериментировать. Хотя производительность конвейера RAG может улучшиться с увеличением количества релевантных контекстов, вы рискуете столкнуться с эффектом “Lost in the Middle”, когда релевантный контекст не распознается LLM как таковой, если он находится посреди множества контекстов.
Вывод
По мере того как все больше разработчиков приобретают опыт создания прототипов RAG-конвейеров, становится насущным обсуждение стратегий доведения RAG-конвейеров до производительности, пригодной для сферы производства. В этой статье обсуждались различные гиперпараметры и другие регуляторы, которые можно настроить в RAG-конвейере в соответствии с определенными этапами.
Мы рассмотрели следующие стратегии на этапе поглощения.
- Очистка данных. Обеспечение чистоты и корректности данных.
- Разбивка на фрагменты. Выбор техники разбиения на фрагменты, размера фрагментов (
chunk_size) и их перекрытий (overlap). - Эмбеддинг-модели. Выбор эмбеддинг-модели, включая размерность, и необходимость ее тонкой настройки.
- Использование метаданных. Применение метаданных и их выбор.
- Мультииндексация. Использование нескольких индексов для различных коллекций данных.
- Алгоритмы индексирования. Выбор и настройка алгоритмов ANN и сжатия векторов (обычно не настраиваются специалистами-практиками, хотя такая возможность не исключается).
Также мы обсудили нижеприведенные стратегии на этапе вывода (извлечение и генерация).
- Преобразование запросов. Эксперименты с перефразированием, HyDE или подзапросами.
- Оптимизация параметров извлечения. Выбор техники поиска (
alpha, если включен гибридный поиск) и количества извлекаемых результатов поиска. - Продвинутые стратегии извлечения. Использование продвинутых стратегий извлечения, таких как окно предложений или автослияние.
- Модели повторного ранжирования. Использование модели повторного ранжирования и ее выбор, количество результатов поиска для ввода в модель повторного ранжирования и возможность ее точной настройки.
- LLM. Выбор LLM и необходимость ее точной настройки.
- Промпт-инжиниринг. Эксперименты с различными формулировками и few-shot-примерами.
Читайте также:
- 10 способов повысить эффективность RAG-системы
- Основы качественного анализа данных
- ULTRA: базовые модели для формирования рассуждений на графах знаний
Читайте нас в Telegram, VK и Дзен
Перевод статьи Leonie Monigatti: A Guide on 12 Tuning Strategies for Production-Ready RAG Applications

 следует использовать стрелочные функции ES6, а где не следует")


