
В мире распределенной архитектуры становится все сложнее работать. И мы должны были это предвидеть.
Наша команда только что закончила разработку новой функциональности для создания субтитров к видео наших клиентов с использованием технологии от OpenAI. Архитектура продукта впечатляла: микросервисы, очереди событий, воркеры… Вполне достаточно, чтобы составить предмет гордости любого разработчика. Единственное, чем сложно было гордиться, — это стандартной системой опроса в браузере, которая требовалась каждые 2 секунды для проверки готовности субтитров.
Функция работала, но можно было найти куда более эффективное решение.
В таких случаях на помощь приходят события на стороне сервера или веб-сокеты. Они позволяют поддерживать активное соединение между браузером и сервером, чтобы данные могли передаваться без выполнения других запросов. И те, и другие прекрасно работают с одним браузером и одним экземпляром сервера. Тем не менее, если вы стремитесь к масштабированию приложения, у вас, вероятно, будет балансировщик нагрузки с уникальной конечной точкой и несколькими экземплярами бэкенда за ним.
Вот тут-то и начинаются проблемы. Соединение браузера с бэкендом происходит не на балансировщике нагрузки, а на одном из экземпляров сервера. Предположим, пользователь подключается через SSE и делает вызов, требующий асинхронного процесса, например отправляет событие в очередь с воркером.
Когда воркер завершает работу, ему необходимо уведомить конкретный экземпляр сервера, подключенный к браузеру пользователя. Как же выбрать нужный экземпляр, если можно вызвать только балансировщик нагрузки?
Используя непосредственный опыт работы в качестве технического руководителя, имеющего дело с событиями на стороне сервера в высокораспределенной системе, расскажу сегодня о проблемах, с которыми мы столкнулись, и их решениях.
Что такое события на стороне сервера и как они работают?
События на стороне сервера — не такая известная функциональная особенность браузера, как более успешные веб-сокеты.
И те, и другие используют одни и те же технологии, позволяющие браузеру поддерживать соединение между ним и сервером.
Вместо того чтобы делать HTTP-вызов, который непосредственно получает ответ и закрывает соединение, в данном случае соединение поддерживается даже после получения ответа от сервера, чтобы браузер и сервер могли продолжать поддерживать связь.
Различия между веб-сокетами и событиями на стороне сервера заключаются в следующем.
- В случае с сокетами обмен происходит двунаправленно: и браузер, и сервер могут отправлять друг другу события. Это отлично подходит для таких приложений, как интерактивные чаты.
- События на стороне сервера являются однонаправленными: только сервер может отправлять события браузеру. Такая функциональность — оптимальный вариант, например, для загрузчика, который обновляет процент выполнения текущего действия.
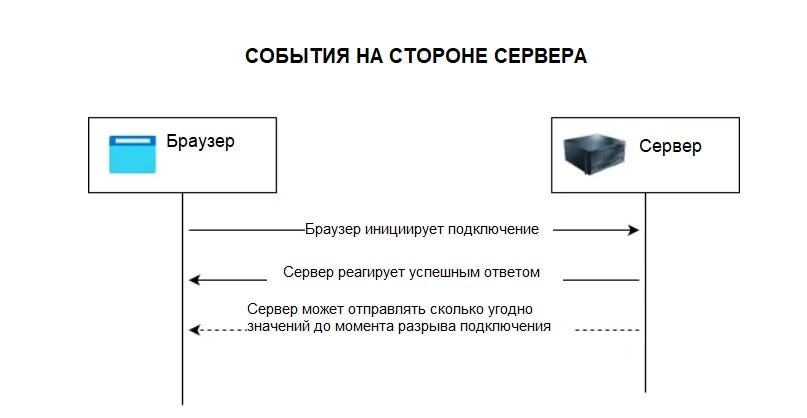
Технология и способ ее применения кажутся относительно простыми. Именно так мы и думали.
Упрощенная распределенная архитектура
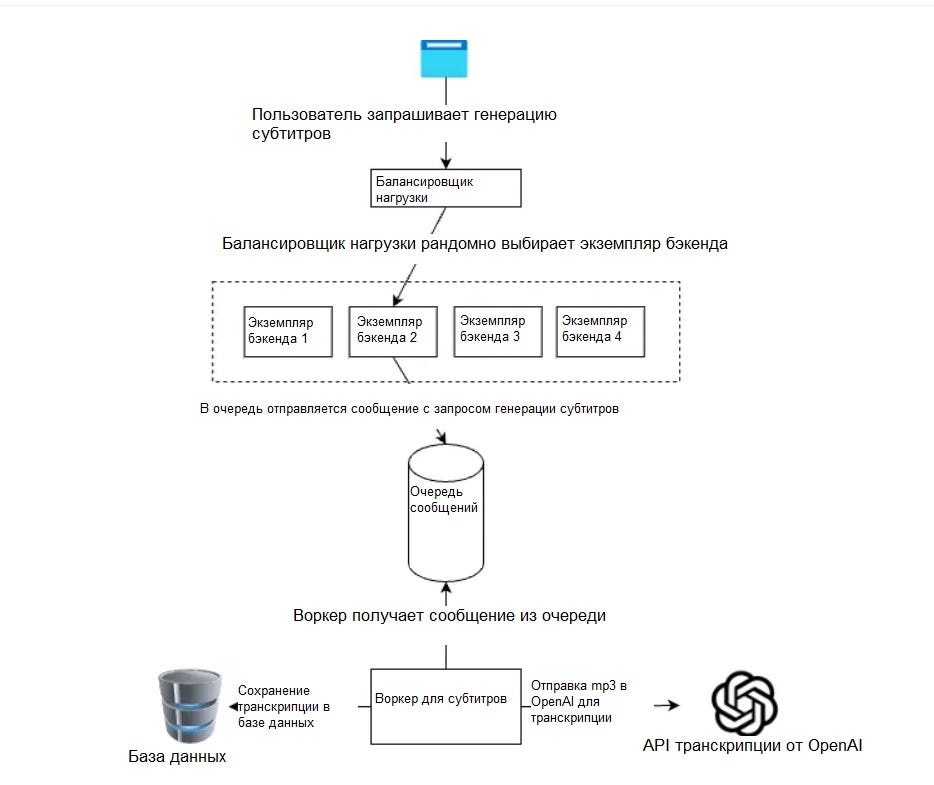
На этой схеме я несколько упростил архитектуру, чтобы убрать шум. Мы видим, что происходит, когда один из пользователей запрашивает новые субтитры для видео.
- Браузеру известна только конечная точка балансировщика нагрузки, поэтому он вызывает именно ее.
- Балансировщик нагрузки случайным образом выбирает один из экземпляров бэкенда, который затем отправляет сообщение в очередь создания субтитров.
- Воркер для субтитров, который слушает новые сообщения, начинает обрабатывать видео и использует транскрипцию от OpenAI для получения текста из видео, а затем сохраняет контент в базе данных.
Я еще буду говорить о событиях на стороне сервера. Для простой системы опроса этого достаточно.
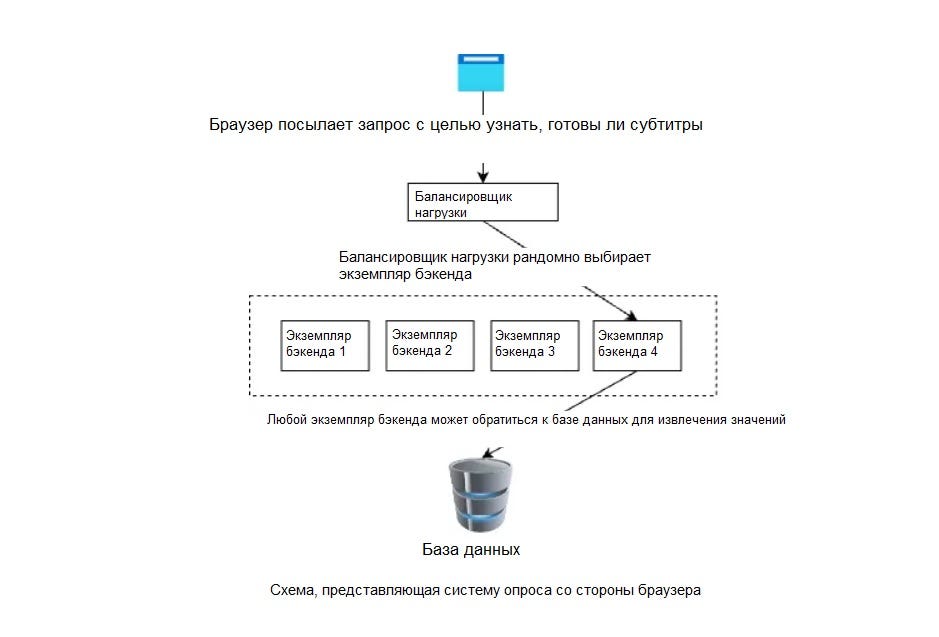
Периодически браузер мог посылать HTTP-вызов, чтобы проверить, готовы ли субтитры. Можно было вызвать любой экземпляр бэкенда, чтобы обратиться к базе данных и получить ответ.
Но это было не то, чего мы хотели. Нам не нужна была система опроса. Нам требовалось, чтобы сервер уведомлял браузер о готовности.
Итак, снова посмотрим на первую схему после завершения всего процесса генерации субтитров (схема начинается снизу).
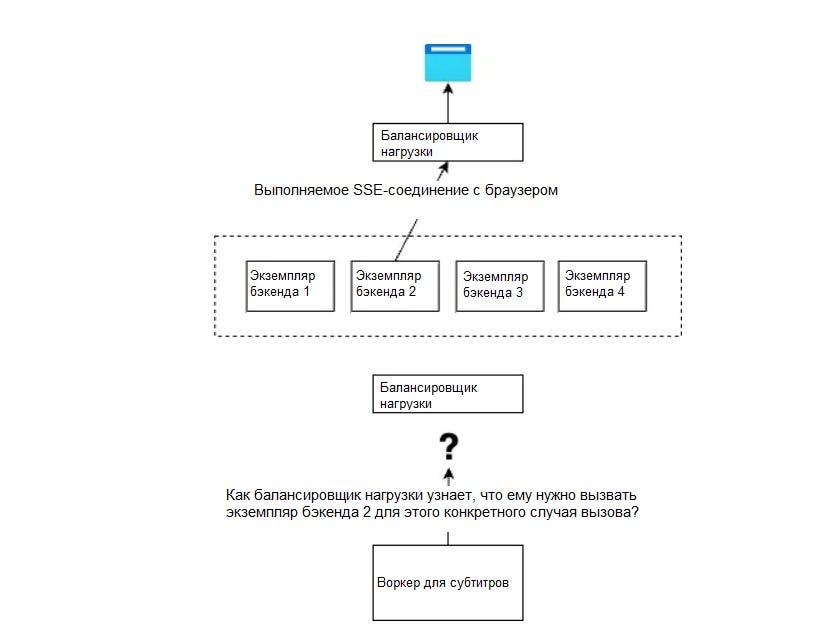
SSE-соединение устанавливается между конкретным экземпляром бэкенда и браузером. Как балансировщик нагрузки узнает, что для вызова воркера для субтитров ему нужно выбрать именно экземпляр 2, а не какой-либо другой?
Ход рассуждений и варианты решений
У нас было много идей, как решить эту проблему, и большинство из них были ужасны.
Главный вопрос заключался в следующем: как уведомить нужный экземпляр бэкенда о том, что процесс, которого ждет пользователь, завершен?
Первое решение — хранить IP-адрес экземпляра сервера, связанного с идентификатором субтитров, во внешнем кэше. Таким образом, когда воркер закончит генерировать субтитры, мы сможем получить список IP-адресов (если результат ожидает несколько пользователей) и уведомить все экземпляры о завершении процесса.
Теоретически это могло сработать, но были некоторые трудности.
Экземпляры серверов автоматически масштабируются вверх и вниз, а оркестратор может закрыть сервер в любой момент, даже при наличии выполняемого соединения. События на стороне сервера пытаются автоматически переподключаться при потере соединения, чтобы можно было без проблем повторно подсоединиться к другому серверу.
Нам бы все равно пришлось ввести способ очистки кэша, чтобы удалить отсутствующий IP-адрес сервера. Кроме того, адрес будет потерян, если процесс завершится именно в этот момент и будет предпринята попытка вызвать старый IP до того, как сохранится новый.
В общем, надо было искать лучшие варианты.
Рабочее решение
События! Ответ был у нас перед глазами с самого начала.
Как только воркер для субтитров завершает обработку, он должен отправить событие в определенную очередь. Мы решили использовать технологию Redis Pub/Sub из соображений удобства, потому что она уже была доступна и работала в нашей системе, но это можно реализовать и с помощью других сервисов очередей.
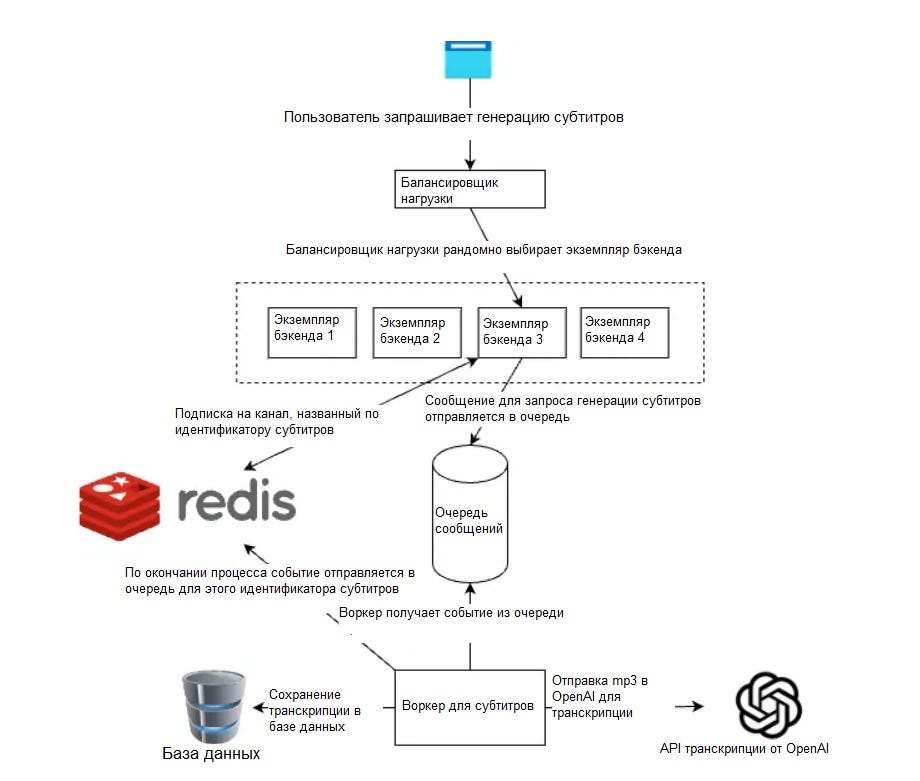
Когда пользователь просит создать субтитры для видео, мы создаем новую очередь (канал) для этого идентификатора субтитров и подписываемся на него. На канал подписывается только тот экземпляр сервера, на котором открыто SSE-соединение.
Если во время этого процесса на страницу зайдет другой пользователь и зарегистрируется на событие на стороне сервера в другом экземпляре, этот экземпляр также подпишется на канал.
Как только воркер для субтитров закончит обработку субтитров, ему останется лишь отправить событие в канал Redis для идентификатора субтитров. Все зарегистрированные в нем экземпляры серверов смогут оповещать пользователей, подключенных к событиям на стороне сервера.
Предположим, один из серверов “упадет” из-за автоматического уменьшения масштаба. В этом случае браузер автоматически переподключится, а при переподключении сервер подпишется на канал, если еще этого не сделал.
Работа над такой простой задачей привела к тому, что мы стали руководствоваться туннельным мышлением, пытаясь осуществить прямой вызов между воркером для субтитров и основным бэкендом. Из-за этого мы проигнорировали потенциал событий на стороне сервера.
Нам просто нужно было сделать шаг назад. Тогда бы мы сразу поняли, что решение кроется в событиях — они повсюду в нашем приложении. Как говорится, слона-то мы и не приметили.
Читайте также:
- История создания одного бессерверного приложения рассылки с открытым ПО
- Эволюция серверной архитектуры: n-слойная, DDD, шестиугольная, луковичная, чистая
- Что такое сервер TURN?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Alexandre Olive: The One Issue Developers Were Not Prepared For With Server-Side Events





