
mondayDB — это новый механизм обработки данных, созданный разработчиками monday.com. Он полностью изменил парадигму работы с данными организации и, безусловно, является самым сложным и полезным проектом, над которым мне довелось работать.
В этой статье вы получите представление о проблемах, с которыми мы столкнулись при внедрении mondayDB, а также узнаете о наших креативных решениях.

Несколько слов о платформе monday.com
Вкратце расскажу о том, чем занимается monday.com.
Мы называем себя Work OS (рабочей операционной системой), поскольку предоставляем пользователям платформу, которую они могут настраивать и расширять, создавая индивидуальную систему для управления и автоматизации любого аспекта своей работы.
Ключевым элементом платформы является доска (Board). По сути, это очень насыщенная таблица для управления любыми данными — от задач и проектов до сделок, маркетинговых кампаний и всего того, что необходимо для управления командой или бизнесом. Каждая доска имеет табличные столбцы, которые могут содержать различные данные — от простых (текст, числа и даты) до более сложных типов (человек, команда, тег, файлы и формулы). Мы предлагаем более 40 типов столбцов, и наши пользователи имеют возможность фильтровать, сортировать и агрегировать практически любые комбинации столбцов, каждый из которых отличается собственной логикой для таких операций. Например, отфильтровать данные по человеку можно по его электронной почте, имени и даже команде, в которую он входит.
В дополнение к данным, хранящимся на досках клиентов, мы предлагаем такие функции, как инструменты для совместной работы, сложные дашборды, настраиваемые формы, документы и сложные механизмы автоматизации. Кроме того, в Apps Marketplace есть множество интеграций и приложений. Возможности продуктов и рабочих процессов, разработанных на нашей платформе, практически безграничны — на ее основе можно создать бесконечное количество продуктов.

Вы упомянули DB — о чем идет речь?
До недавнего времени, когда пользователь попадал на свою доску, мы перебрасывали все данные этой доски прямо в клиент (обычно это был веб-браузер, работающий на настольном компьютере).
Такой подход сыграл большую роль в формировании продукта. Пользователи могли выполнять самые разные операции с данными: фильтровать по любому признаку (мы предлагаем десятки различных типов столбцов, каждый из которых имеет уникальную структуру и, соответственно, логику фильтрации), сортировать/агрегировать по любому признаку и даже объединять данные на разных досках. Кроме того, данные были изменчивы, и их постоянно могли обновлять другие пользователи.
Это был очень эффективный подход, но со своими очевидными недостатками. Прежде всего, клиент ограничен в своих ресурсах. В зависимости от устройства клиента и структуры доски, клиент начинал испытывать трудности, и после нескольких тысяч элементов (“строк таблицы” в терминологии monday.com) происходил сбой. Если очень постараться, то можно было обработать до 20 тыс. элементов. После этого все заканчивалось.
Нужно было что-то менять. Поэтому мы решили перенести все на сервер, позволив клиенту получать только подмножество элементов на страницах по мере их прокрутки. Это было проще для клиента, но не так тривиально для бэкенда.
Вот каким требованиям должна была удовлетворять БД:
- неограниченные таблицы;
- бессхемные таблицы;
- фильтрация по чему угодно (не зная этого “чего угодно” заранее);
- сортировка по чему угодно (опять же, ничего не зная заранее);
- агрегирование по чему угодно (также ничего не зная);
- динамические значения по формуле (функции, определяемой пользователем);
- выполнение соединения;
- низкая задержка;
- горизонтальное масштабирование;
- пагинация;
- свежесть данных (новые данные сразу же доступны для запросов);
- гибридный режим (для небольших досок на клиенте должна выполняться одна и та же логика);
- права доступа на уровне таблицы (запрет на просмотр любой доски);
- права доступа на уровне элементов (запрет на просмотр элементов).
И конечно, все это должно быть надежным, устойчивым, отказоустойчивым и т.д.
Приходилось ли вам сталкиваться с таким количеством требований к базе данных?
Зачем создавать собственную БД?
Как бы банально это ни звучало, никто не хочет изобретать велосипед. Поскольку существует множество проверенных баз данных, первым нашим шагом было изучение их возможностей.
Это, наверное, заслуживает отдельной статьи, но мы изучили многие из них, включая традиционные базы данных RDBMS с разделами (представьте себе экземпляр MySQL для каждого аккаунта с выделенной таблицей для каждой доски), ElasticSearch, аналитические базы данных, такие как Apache Pinot, ClickHouse и Apache Druid, широкий спектр NoSQL, таких как CockroachDB, Couchbase и другие.
В итоге мы пришли к выводу, что ни один из этих вариантов полностью не отвечает нашим требованиям. Но действовать без подготовки не стали: мы встретились с командами, разрабатывающими эти инструменты, и они согласились с тем, что их базы данных не предназначены для использования в нашем конкретном случае. Причины такого вердикта были самыми разными: изменяемость данных, наша потребность в большом количестве таблиц, невозможность заранее определить, что именно пользователи захотят фильтровать, и многое другое.
При этом мы заметили, что несколько “небольших” компаний столкнулись с аналогичной дилеммой. И они создали собственную систему. В качестве примера можно привести Porcella от Google, Husky от Datadog и Snowflake Elastic Warehouse. Поэтому мы прочли всю документацию этих компаний и взяли на вооружение многие из их ключевых концепций, адаптировав к выполнению наших задач.
Концепция №1: столбцовое хранение данных
В традиционных RDBMS, таких как MySQL, строка — это главный элемент, и все данные строки хранятся на диске как единое целое. Строковая схема удобна при доступе ко всем данным из строки, но менее эффективна при выполнении таких операций, как фильтрация определенного столбца. Связано это с тем, что приходится вытаскивать все данные таблицы, если только вы заранее не подготовили индекс столбца (что невозможно сделать без предварительного знания схемы или запросов).
Столбцовая база данных, напротив, разделяет данные по вертикали по столбцам. Это означает, что значения ячеек каждого столбца хранятся на диске как единое целое.
Чтобы понять суть этой идеи, представьте следующую таблицу с точки зрения традиционного “строкового хранилища” (“row store”) и сравните ее со “столбцовым хранилищем” (“columnar store”):
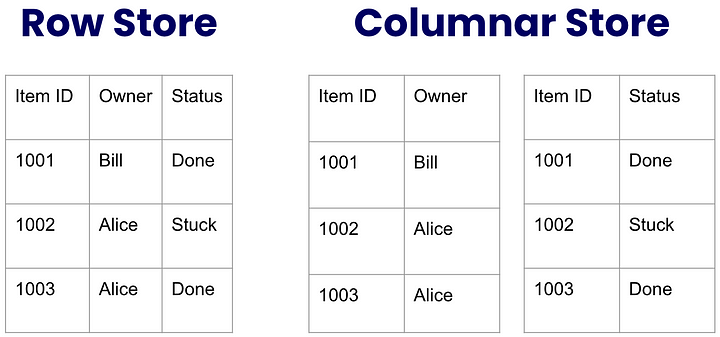
Сразу же бросается в глаза тот факт, что столбцовое хранилище позволило бы хранить больше данных, поскольку идентификатор элемента должен был бы повторяться для каждого значения ячейки. Однако эта проблема становится гораздо менее проблематичной, учитывая, что данные сильно сжимаются, особенно если столбец имеет низкую кардинальность, то есть у нас ограниченное количество повторяющихся значений.
Тем не менее преимущества огромны. Рассмотрим стандартный запрос на нашей доске, обычно включающий 1–3 столбца. Чтобы понять, какие элементы удовлетворяют условиям фильтра, нам потребуется получить лишь малую часть данных, участвующих в фильтре. Более того, поскольку многие столбцы у нас довольно разрежены, даже если доска обширна, количество данных, которые необходимо получить и обработать, может быть относительно небольшим.
Наконец, столбцовая структура открывает массу возможностей для оптимизации — будь то сжатые данные или предварительно вычисленные метаданные, которые могут ускорить работу. Вот пример: для столбца с малой кардинальностью можно заранее подготовить идентификаторы элементов для каждого уникального значения. Это означает, что выполнение фильтров по этим значениям практически не займет времени на обработку.
Концепция №2: лямбда-архитектура
Как уже говорилось, мы храним все ячейки столбца вместе как единую неделимую единицу данных. Это означает, что мы не можем получить или обновить одну ячейку отдельно. Итак, каков же процесс обновления одной ячейки в нашей столбцовой структуре?
- Получение данных обо всех ячейках столбца.
- Нахождение с последующим обновлением данных конкретной ячейки.
- Переписывание всех обновленных данных ячеек столбца.
А чтобы предотвратить возникновение условий гонки при одновременном обновлении, необходимо блокировать запись во время обновления.
Но, скажем прямо, постоянно получать и перезаписывать весь столбец для каждого обновления ячеек не только нецелесообразно, но и чревато катастрофическими последствиями, поскольку каждую секунду у нас происходят тысячи обновлений ячеек.
На помощь приходит лямбда-архитектура (не путать с лямбда-функциями AWS: они были придуманы специалистами в индустрии больших данных для того, чтобы можно было заранее просчитывать результаты запросов к данным в режиме оффлайн). Таким образом, запросы быстро выполняются во время исполнения. Основное преимущество заключается в том, что при этом обслуживаются свежие данные, поступившие после последнего предварительного расчета в автономном режиме.
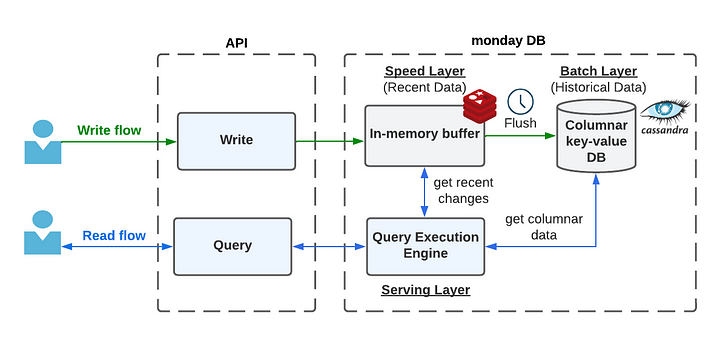
Мы разделяем нашу систему на три компонента:
- Скоростной слой (Speed layer) содержит только недавно измененные данные
- Пакетный слой (Batch layer) содержит все прошлые исторические данные
- Обслуживающий слой (Serving layer) обслуживает запросы, объединяя данные скоростного и пакетного слоев во время выполнения.
Потоки данных направляются от скоростного к пакетному слою. Это происходит благодаря запланированному автономному заданию на очистку данных, создание метаданных и другие сложные предварительные вычисления.
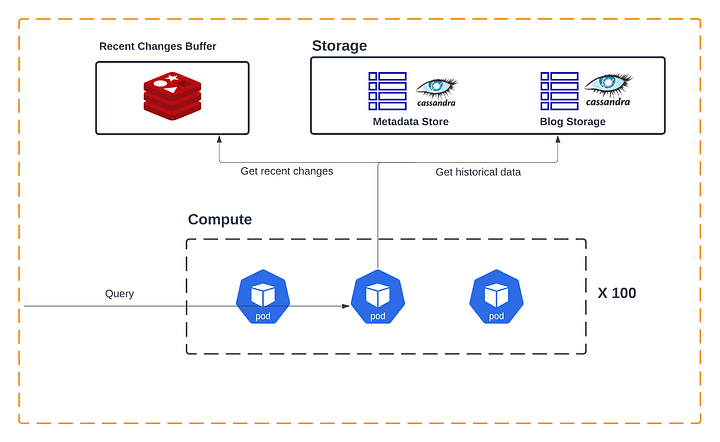
В качестве хранилища скоростного слоя мы используем Redis, а в качестве хранилища пакетного слоя — Cassandra. Оба эти хранилища рассматриваются как простое хранилище ключ-значение, где ключ соответствует идентификатору столбца, а значение — данным ячеек столбца.
Рассмотрим еще раз поток обновления для одной ячейки:
- Сохранение значения ячейки в хранилище скоростного слоя.
Вот и все. Никаких блокировок. Максимально быстро. Со временем накапливается все больше таких мелких обновлений. В фоновом режиме, когда их накопится достаточно, или через запланированные интервалы времени происходит следующее:
- Получение всех данных столбца из пакетного слоя.
- Получение всех накопленных обновлений из скоростного слоя.
- Объединение.
- Перезаписывание обновленных данных столбцов в пакетный слой.
- <Представьте себе всевозможные предварительные вычисления для оптимизации чтения>.
Если пользователь хочет произвести фильтрацию по столбцу, ему следует помнить: обслуживающий слой получает данные с обоих слоев, объединяет их и выполняет требуемую фильтрацию, сортировку или агрегирование.
Что мы получили?
- Решили проблему получения/перезаписи столбцов.
- Недавно обновленные данные сразу же становятся доступны для запросов.
- В фоновом режиме можно заняться предварительным расчетом метаданных, индексов, представлений, сжатий и т. д.
- Изменения данных происходят очень быстро.
- Никаких блокировок.
Прежде чем продолжить, должен признаться: я упомянул, что мы храним все данные столбца на диске как единую единицу данных. На самом деле мы разбиваем большие столбцы на более мелкие разделы. Это соответствует лучшим практикам Cassandra, нашего хранилища пакетного слоя, позволяющего избегать больших сегментов. Это также открывает широкие возможности для оптимизации (параллельного выполнения запросов к разделам, кэширования разделов с инвалидацией обновленных, пропуск получения/перезаписи для неизменных сегментов и т. д.).
Концепция №3: отделение хранения от вычислений
Природа нашей системы такова, что ее пропускная способность динамична в течение дня. Большинство наших клиентов находятся в часовом поясе США. Таким образом, в обычные рабочие часы в США пропускная способность значительно выше.
Кроме того, запросы очень изменчивы. Иногда наблюдается всплеск небольших запросов, в другое время — меньшее количество, но более интенсивных и сложных запросов. Одни запросы требуют много места в хранилище, другие — много вычислительной мощности. Кроме того, не стоит забывать, что данные продолжают расти и накапливаться с течением времени, при этом не всегда сохраняется четкая взаимосвязь между данными и запросами, которые их обрабатывают.
Таким образом, мы должны позаботиться о гибкости архитектуры. Когда требуется больше вычислительной мощности (ресурсов CPU) для более “тяжелых” запросов или в часы пиковой нагрузки, необходимо увеличить количество вычислительных серверов. Аналогичным образом мы должны иметь возможность масштабировать уровень хранения для удовлетворения потребностей в емкости данных. Причем это не должно быть связано с соображениями обработки данных.
Наша архитектура именно это и предлагает. Пакетный слой является слоем хранения данных и может масштабироваться независимо от серверов, выполняющих логику запросов, и эти серверы также масштабируются независимо.
Эффективная фильтрация… А что дальше?
Итак, мы разработали систему, которая может обрабатывать множество условий фильтрации и сообщать нам, какие элементы удовлетворяют этим условиям. Что дальше? Как мы можем вернуть пользователю все данные? Как включить пагинацию в отношении этих данных?
Данные вопросы выходят за рамки статьи, но если вкратце коснуться их, то вот основные пункты:
- Выполняем запрос с использованием описанной выше архитектуры, сужая круг идентификаторов элементов, удовлетворяющих условиям фильтра.
- Идентификаторы элементов сохраняем на быстром временном хранилище.
- Генерируем уникальный идентификатор ответа на запрос (Query Response ID), который присваиваем результату запроса.
- На основе конкретной страницы, запрошенной клиентом, берем следующие N идентификаторов элементов и извлекаем все их данные из специального хранилища элементов. Обратите внимание: это не столбцовое, а обычное строковое хранилище, которое невероятно эффективно при получении полных строк по определенным идентификаторам.
- Клиенту возвращаем элементы вместе с идентификатором ответа на запрос.
Представьте себе идентификатор ответа на запрос как снапшот, т. е. момент, застывший во времени. Когда пользователь прокручивает страницу дальше вниз, этот идентификатор передается в бэкенд, который затем просто отделяет следующую страницу и получает данные о последующих элементах страницы.
Прелесть такого подхода заключается в том, что не нужно заново выполнять запрос на каждой странице, которую запрашивает клиент. Кроме того, клиент может пропустить страницу по определенному смещению, не перебирая все элементы, расположенные ниже этого смещения (представьте, что пользователь нажимает клавишу “end” — и мгновенно получает последнюю страницу).
Кроме того, если клиент захочет просмотреть все данные доски через API, он сможет получать их страница за страницей, не заботясь об изменениях между каждым запросом страницы, которые очень сложно поддерживать.
Однако такой подход не лишен недостатков. Например, как пользователь узнает, как отобразить страницу для имитации длинной полосы прокрутки? Или как понять, какое смещение нужно пропустить при быстрой прокрутке? И как обновлять представление с учетом изменений в режиме live, сделанных другими пользователями с момента последнего снимка?
Это отличные вопросы, но они заслуживают отдельной статьи.
Сработало ли это?
Да. Вся парадигма данных в компании была изменена, и мы только начинаем собирать плоды этих изменений. Мы уже наблюдаем значительное улучшение времени загрузки досок, особенно больших. Посмотрим на один из наших мониторов.
Время загрузки доски (> 5 тыс. элементов) p99:
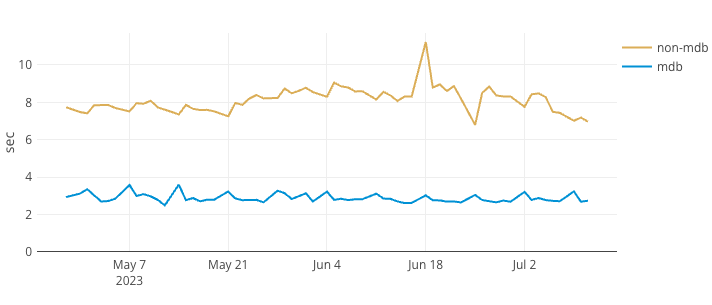
Параллельное сравнение с mondayDB и без него:
Что дальше?
Это долгий путь, поскольку каждый компонент системы должен быть адаптирован для работы только с подмножествами данных с использованием пагинации, а не со всеми данными, доступными клиенту. Мы реализовали эту функцию для досок, но у нас есть много других компонентов, таких как мобильные приложения, API, представления, дашборды и документы. Кроме того, нам нужен более интеллектуальный клиент, способный работать в гибридном режиме. Это позволит оперировать небольшими наборами данных исключительно на стороне клиента, сохраняя непревзойденную производительность внутри клиента и не жертвуя преимуществами больших досок.
Пока наш текущий подход хорошо себя зарекомендовал, но есть существенные возможности для улучшения и множество оптимизаций, которые еще предстоит реализовать. В частности, у нас есть много распараллеливаемых внутрипроцессных операций, и мы могли бы значительно выиграть от добавления предварительных вычислений для генерации метаданных, индексов и оптимизирующих структур, таких как фильтр Блума, и т. д.
Как уже упоминалось, у нас есть десятки различных типов столбцов, каждый из которых имеет свою уникальную логику фильтрации, сортировки и агрегирования. Все это — JavaScript, инкапсулированный в общий пакет между клиентом и бэкендом, что позволяет работать в гибридном режиме. Соответственно, движок также полностью создан на JavaScript. Мы выбрали это направление, чтобы оптимизировать наши усилия, хотя ни для кого не секрет, что JavaScript может оказаться не самым оптимальным выбором для высокопроизводительной системы.
Заглядывая в будущее, мы обдумываем дальнейшие действия. Возможно, отрефакторим часть логики, чтобы она выполнялась на высокопроизводительных технологиях, таких как DuckDB. Возможно, воспользуемся преимуществами столбцовых форматов, таких как Arrow и Parquet. Возможно, даже отрефакторим логику, используя язык Rust в качестве дополнительного или специального микросервиса.
Наше путешествие только начинается.
Читайте также:
- Исследование данных - основные понятия
- Как создать опрос удовлетворенности сотрудников с Angular и сохранить его результаты в коллекции MongoDB
- Будущее данных: децентрализованная графовая база данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Liran Brimer: Nice to meet you, mondayDB architecture





