
Одна из основных задач команды Criteo CAMLET (Catalog & Applied Machine Learning — Enrichment & Text) заключается в ежедневном обогащении более 2 миллиардов продуктов. Делается это с целью создания одного из крупнейших в мире каталогов электронной коммерции, содержащего 25+ миллиардов позиций.
Эти продукты предоставляются нашими партнерами по электронной коммерции и изначально обладают определенной информацией, которую мы стандартизируем, дополняем и улучшаем с помощью машинного обучения. Один из этапов обогащения состоит в извлечении атрибутов продукта на основе его названия и описания (например, определение цвета платья, жанра видеоигры или размера телевизора).
Создание обучающих данных для этих моделей всегда было дорогостоящим и длительным процессом. Однако последние достижения в области zero-shot-моделей с открытым исходным кодом позволяют применять новые подходы к созданию подобных данных за недорогую плату.
У компании Criteo несколько десятков тысяч партнеров в сфере электронной коммерции. Благодаря этому наша пользовательская рекомендательная система обладает каталогом из более чем 25 миллиардов товаров на выбор. К сожалению, данные в каталогах партнеров были созданы с применением огромного количества пользовательских правил и классификаций, определенных ими самими.
Чтобы обеспечить релевантность онлайн-рекламы, которую мы предлагаем пользователям Интернета, и рекламных кампаний наших партнеров по электронной коммерции, нам необходимо стандартизировать и улучшить этот набор разнородных каталогов путем последовательного обогащения. Каждое обогащение выполняется с помощью определенного входного подмножества данных, предоставленных партнерами, а также результатов предыдущих обогащений и передачи их специальной модели машинного обучения.
Десятки тысяч партнеров по электронной коммерции предоставляют нам десятки миллиардов товаров, разбитых на тысячи категорий и описанных на более чем десяти языках. При таком колоссальном разнообразии данных, которые должны обрабатывать модели, каждая из этих моделей требует огромного количества обучающих данных, подлежащих аннотированию. Как и большинство компаний, столкнувшихся с этой проблемой, Criteo в данном случае полагается на сторонние организации, предлагающие услуги аннотирования.
После назначения группы аннотаторов для выполнения задачи им необходимо объяснить цели данного конкретного процесса обогащения и набора данных. Это нужно сделать до того, как вручную добавлять ожидаемый результат к десяткам тысяч образцов продукции. Этот процесс очень дорогостоящий и длительный, но, что еще хуже, он приводит к очень шумным данным, в которых много как ложноположительных, так и ложноотрицательных результатов.
Действительно, процесс аннотирования часто неоднозначен, и трудно обеспечить предоставление всеми аннотаторами согласованных результатов и недопущения ошибок из-за повторяющегося характера поставленной задачи.


Конечно, можно несколько “смягчить” эти проблемы, например, используя двойные аннотации и самостоятельно просматривая часть объема данных. Но это только увеличит затраты, как временные, так и денежные, необходимые для создания обучающих данных для наших моделей.
Более того, со временем эти данные обесцениваются, как потому, что предпочтения потребителей меняются со временем, так и потому, что спецификации и потребности моделей диверсифицируются, чтобы мы могли подстраиваться под стратегии наших клиентов. Таким образом, обучающие данные необходимо регулярно обновлять, чтобы предотвратить ухудшение производительности моделей с течением времени.

Сложность и дороговизна генерации обучающих данных долгое время считались издержками бизнеса в машинном обучении. Однако последние достижения в области zero-shot-моделей открывают возможности для создания высококачественных синтетических данных — обучающих данных, созданных без дорогостоящих аннотаций.
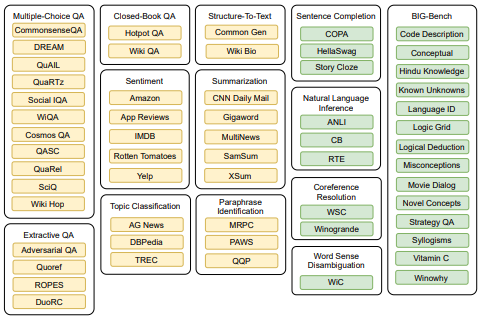
Zero-shot модели
Самые впечатляющие модели в области обработки естественного языка за последние несколько лет в основном были основаны на архитектуре трансформеров. Модели-трансформеры полагаются на умный механизм внимания, который позволяет им правильно представлять степень связи слов в предложении.
При достаточном количестве параметров такие модели-трансформеры способны изучить структуру человеческой письменности и большую часть отношений, заложенных в текстовом корпусе данных Интернета. Обучение таких моделей с нуля — очень дорогостоящее занятие, которое не под силу большинству групп, интересующихся обработкой естественного языка (NLP). Однако их можно самостоятельно обучить на огромном количестве неструктурированных данных, загруженных из Интернета, маскируя некоторые слова в заданном предложении и требуя от модели угадать эти слова.
Модели-трансформеры, предварительно обученные исследовательскими группами, работающими в сфере ИИ и обладающими огромными ресурсами, часто выкладываются в открытый доступ и становятся общедоступными. Затем эти модели можно использовать для решения множества различных задач с помощью трансферного обучения. Сначала удалите верхний слой модели — ее “голову” — и замените его слоем, предназначенным для решения новой NLP-задачи, например, классификации описания продукта по категориям продукции. Затем, отладив работу модели на нескольких тысячах аннотированных примеров для новой задачи, можно добиться качественных результатов для широкого круга последующих задач.
За последние несколько лет специалисты обучали модели-трансформеры со значительно большим количеством параметров, и эти модели начали демонстрировать замечательные zero-shot-возможности. Теперь уже не нужно было требовать тонкой настройки модели на аннотированных примерах последующей задачи. Вместо этого задачу можно было описать на естественном языке как часть входных данных, подаваемых модели, после чего модель могла интерпретировать задачу и непосредственно предоставлять желаемый выход.
Первой моделью, продемонстрировавшей такие возможности в значительном объеме, была GPT-3 от OpenAI. Однако GPT-3 не имеет открытого исходного кода, и даже если бы он был, из-за наличия 175 миллиардов параметров она практически непригодна для использования в большинстве организаций.
В конце 2021 года компания Hugging Face выпустила значительно более легкую модель — T0PP. Ее создатели заявили о производительности, близкой к GPT-3, продемонстрированной на широком спектре задач, несмотря на использование всего 11 миллиардов параметров. Такой результат был достигнут путем преобразования большинства открытых NLP-датасетов в подсказки на естественном языке и использования их в качестве обучающих данных.
Полученная модель оказалась гораздо менее универсальной, чем GPT-3, и попытка использовать ее, например, для генерации текста в свободной форме приводит к гораздо менее впечатляющим результатам. Тем не менее, T0PP отлично справляется с большинством стандартных задач NLP и даже способна к генерализации объектов, не входящих в обучающий набор данных, без какой-либо тонкой настройки.
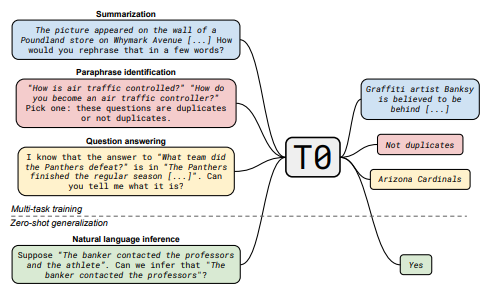
Тщательно разработав подсказки для модели, можно за несколько часов обогатить тысячи примеров, а затем использовать эти данные в качестве обучающего набора для тонкой настройки других алгоритмов.
Но если T0PP может непосредственно выполнять такие задачи, почему мы не можем использовать ее вместо других моделей? К сожалению, T0PP с ее 11 миллиардами параметров занимает намного больше места, чем стандартные модели-трансформеры, такие как Bert (250 миллионов параметров).
К тому же, T0PP можно загрузить только в память новейших GPU промышленного класса, таких как A100 от NVIDIA. Поскольку мы не располагали графическими процессорами такого уровня, нам пришлось довольствоваться результатами CPU, каждый из которых занял около 5 секунд.
Такой темп хорош для генерации от нескольких тысяч до десятков тысяч примеров в течение нескольких часов или дней, но это по крайней мере на 4 порядка медленнее, чем нам нужно для обогащения всех наших продуктов. Пока что нам придется довольствоваться генерированием высококачественных обучающих данных по той относительно скромной цене, к которой мы уже привыкли.
Предпроцессинг и постпроцессинг
Учитывая универсальный характер T0PP, ее использование, вероятно, подойдет для широкого круга задач NLP и процесса обогащения. Изначально мы решили сосредоточиться на генерации данных для обогащения Product ATtributes Extraction (PATE). Производство высококачественных обучающих данных для PATE было больной темой для Criteo в течение прошлого года.
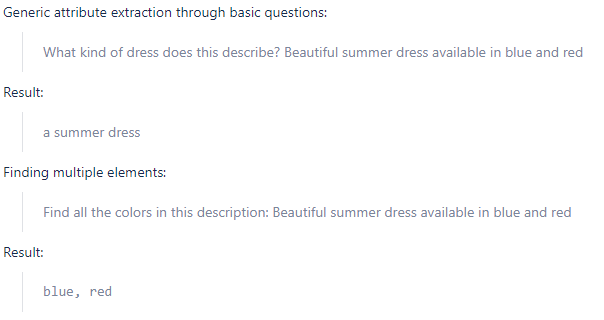
Целью PATE является поиск модальностей атрибутов в названии и описании продукта определенной категории. Например, нам нужно найти вхождения названий цвета в описаниях платьев или разрешения в описаниях телевизоров. Для каждой категории товаров заранее определен список атрибутов (например, цвет, длина и материал для платья), а цель наших моделей — классифицировать товар по соответствующим модальностям.
Начиная с исходного набора данных названий и описаний товаров, мы создали блокнот, который генерирует подсказки для каждого атрибута на основе шаблона и передает их в модель T0PP для вывода. Полученные необработанные прогнозы сохраняются на диске для дальнейшего использования.
После выполнения всех прогнозов второй блокнот загружает результаты. Далее следует постпроцессинг для очистки данных, который включает в себя следующие этапы:
- Отбрасывание всех прогнозов T0PP, которые не встречаются в соответствующем тексте продукта. T0PP пытается предсказать наиболее вероятный ответ на наши вопросы, и это может позволить ей найти полезные данные, которых нет в тексте. Например, если попросить определить производителя автомобиля Focus, T0PP может сделать вывод, что это Ford. Однако, если попросить модель определить цвет платья, о котором нет информации, T0PP даст примерный ответ (например, “синий”), независимо от степени его точности. Отбрасывая все творческие ответы, мы можем значительно уменьшить количество ложноположительных результатов в нашем наборе данных.
- Группировка всех прогнозов T0PP для данного атрибута по частоте и отбрасывание всех прогнозов ниже того порога, который определяется вручную путем быстрого просмотра отсортированного списка. T0PP может давать катастрофические сбои и бессмысленные ответы, а прогнозы, которые встречаются очень редко, часто являются иррелевантными. Кроме того, хранение сотен модальностей часто оказывается практически бесполезным, и в большинстве случаев лучше ограничить возможные значения несколькими наиболее релевантными десятками модальностей.
- Просмотр полученного списка вручную для удаления ненужных модальностей, которые обычно являются либо просто неправильными ответами, либо подкатегориями другой модальности (например, при наличии консоли “PlayStation 4 Pro” обычно лучше оставить только часть “PlayStation 4”, которая в любом случае будет более частой модальностью).
Полученный обогащенный набор данных сохраняется на диске в отдельном файле и готов к использованию в качестве обучающих данных.
Анализ результатов
До сих пор мы рассматривали только некоторые примеры при отладке наших первоначальных подсказок. Чтобы проверить полезность данных, мы отправили необработанный исходный датасет по видеоиграм на аннотирование с помощью нашего обычного конвейера. Мы привлекли для этой цели специалистов по аннотированию, а потом сравнили результаты с обработанным набором данных, созданным с помощью T0PP. Нами был также проведен анализ каждого различия в прогнозах на 600 примерах; мы классифицировали их либо как ошибки T0PP, либо как ошибки человека.
Нам удалось обнаружить, что прогнозы T0PP сохранили точность на уровне более 95% для каждого атрибута. Более того, общая точность прогнозов T0PP была даже выше, чем точность аннотаций человека. T0PP допустила несколько ошибок из-за отсутствия определенного имплицированного контекста. Так, она предсказала, что франшизой игры была “SimCity”, в то время как описание продукта содержало следующее предложение: “Создайте свой собственный город в стиле SimCity”. Однако такие ошибки встречались гораздо реже, чем ошибки, допущенные людьми из-за непоследовательности, пропущенных кликов или просто отсутствия знаний в данной области.
Учитывая впечатляющую эффективность модели, мы уже приступили к масштабированию процесса в отношении других категорий. Впервые в нашем распоряжении оказался реальный метод масштабирования проекта PATE на большое количество новых категорий продуктов. Мы также планируем использовать этот подход для эффективного решения множества других задач, например, генерировании данных для модели, отвечающей за предсказание того, к какой категории относится каждый продукт.
Да, результаты работы модели T0PP кажутся чрезвычайно многообещающими и позволят нам масштабировать множество продуктов в гораздо большем объеме, чем мы думали. Тем не менее, при работе с большими языковыми моделями крайне важно помнить о потенциальных предубеждениях, происходящих из данных, используемых для обучения подобных моделей. Большое спасибо компании HuggingFace за то, что она предоставляет возможность анализировать на предмет предубеждений и честности каждую из своих моделей.
T0PP не является исключением, и предубеждения, заложенные либо в Интернет-данных, использованных для обучения оригинальной модели T5, либо в открытых датасетах, которые Hugging Face использовала для превращения T5 в T0PP, влияют на итоговую модель. Контроль человека над извлеченными данными — необходимый этап для отслеживания и уменьшения количества таких предубеждений в наших моделях.

Спасибо за прочтение!
Читайте также:
- Создание модели машинного обучения с помощью Google Colab без дополнительных настроек
- Машинное обучение без данных
- Машинное обучение. С чего начать? Часть 2
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nicolas Kowalski, No data? No problem! Generating synthetic training data at scale for NLP tasks using T0PP





