
Предыдущая часть: “MongoDB: введение, преимущества и настройка среды”
Данные в MongoDB обладают гибкой схемой хранения документов в одной коллекции. Документам не обязательно иметь одинаковый набор полей или структуру. Общие поля в них могут содержать разные типы данных.
Типы моделей данных
MongoDB предоставляет два типа моделей данных: встроенную и нормализованную. В зависимости от требований допускается применение любой из моделей при подготовке документа.
Встроенная модель данных
Данная модель, еще известная как денормализованная, позволяет встраивать все связанные данные в один документ.
Предположим, мы получаем данные о сотрудниках в трех разных документах: Personal_details, Contact и Address. Встроим все три документа в один, как показано ниже:
{
_id: ,
Emp_ID: "2C325A33F6"
Personal_details:{
First_Name: "Ivan",
Last_Name: "Ivanov",
Date_Of_Birth: "1980-01-01"
},
Contact: {
e-mail: "ivan.ivanych@gmail.com",
phone: "9098022338"
},
Address: {
city: "Moscow",
country: "Russia"
}
}Нормализованная модель данных
Данная модель позволяет обращаться к поддокументам в исходном документе, используя ссылки. Перепишем ранее рассмотренный документ согласно нормализованной модели:
Employee:
{
_id: <ObjectId101>,
Emp_ID: "2C325A33F6"
}Personal_details:
{
_id: <ObjectId102>,
empDocID: " ObjectId101",
First_Name: "Ivan",
Last_Name: "Ivanov",
Date_Of_Birth: "1980-01-01"
}Contact:
{
_id: <ObjectId103>,
empDocID: " ObjectId101",
e-mail: "ivan.ivanych@gmail.com",
phone: "9098022338"
}Address:
{
_id: <ObjectId104>,
empDocID: " ObjectId101",
city: "Moscow",
country: "Russia"
}Рекомендации при проектировании схемы в MongoDB
- Проектируйте схему в соответствии с требованиями пользователя.
- Если вы планируете использовать объекты вместе, объедините их в один документ. В противном случае разъедините их, но прежде убедитесь, что необходимость в соединении отсутствует.
- Дублируйте данные (умеренно), поскольку пространство на диске дешевле, чем время вычисления.
- Выполняйте операции соединения при написании, а не при чтении.
- Оптимизируйте схему для наиболее частых случаев использования.
- Выполняйте сложные операции агрегации в схеме.
Пример
Допустим, нужно создать проект базы данных для блога/веб-сайта клиента и показать ему отличия между схемами РСУБД и MongoDB. К каждой публикации на сайте предъявляются следующие требования. Она должна:
- обладать уникальным заголовком, описанием и url;
- иметь один или два тега;
- сопровождаться упоминанием имени ее автора и общим количеством лайков;
- иметь комментарии пользователей с их именами, сообщениями, лайками, указанием даты и времени;
- иметь несколько комментариев или ни одного.
Учитывая данные требования, в схеме РСУБД проект будет состоять, как минимум, из 3 таблиц:
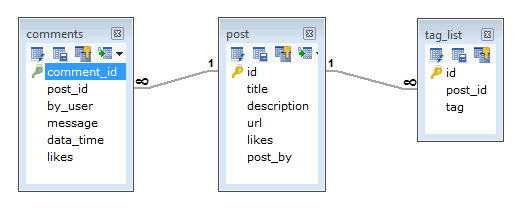
А в схеме MongoDB он будет включать одну коллекцию Post и следующую структуру:
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}Таким образом, для показа данных в РСУБД потребуется объединить три таблицы, тогда как в MongoDB данные будут отображаться только из одной коллекции.
Читайте также:
- Как создать приложение на Go с gRPC
- Завершаем настройку мощного API на Nodejs, GraphQL, MongoDB, Hapi, и Swagger
- Управление файлами в Google Colab
Читайте нас в Telegram, VK и Яндекс.Дзен





