
Это вторая часть в серии, где мы строим мощный API GraphQL. Пожалуйста, посмотрите первую часть нашей статьи,если вы до сих пор этого не сделали.
Я знаю, оставил вас на самом интересном ― реализации GraphQL.

Что такое GraphQL и почему он так популярен?
«Вся мощь GraphQL заключается в простой идее — вместо того, чтобы определять структуру ответов на сервере, эта задача предоставляется клиенту. В каждом запросе определяется, какие поля и связи нужно вернуть обратно. GraphQL строит такой запрос, адаптированный для каждого конкретного случая. Преимущество: для извлечения всех данных сразу, требуется только один path. В противном случае потребуется несколько конечных точек REST. В то же время, возвращаются только те данные, которые фактически необходимы и ничего больше.» Источник
GraphQL избавляет нас от проблем, которые могут возникнуть с традиционными REST API. Вот некоторые из них:
- Over-fetching ― в ответе есть данные, которые вы не используете.
- Under-fetching — недостаточно данных после первого запроса, что приводит к повторному вызову.
Этот пост на StackOverflow, объясняет оба сценария.
GraphQL стал настолько популярным, отчасти потому, что у людей есть веские основания полагать, что он полностью заменит REST — так же, как REST заменил SOAP.
 Любители REST (шучу, я сам люблю и REST и GraphQL❤)
Любители REST (шучу, я сам люблю и REST и GraphQL❤)
Начнём работать с GraphQL
Сначала нам нужно установить соответствующие зависимости.

Главный пакет GraphQL имеет одноименное название, а apollo-server-hapi ― это “клей” между Hapi сервером и GraphQL.
Давайте создадим новую папку graphql, а внутри файл с именем PaintingType.js
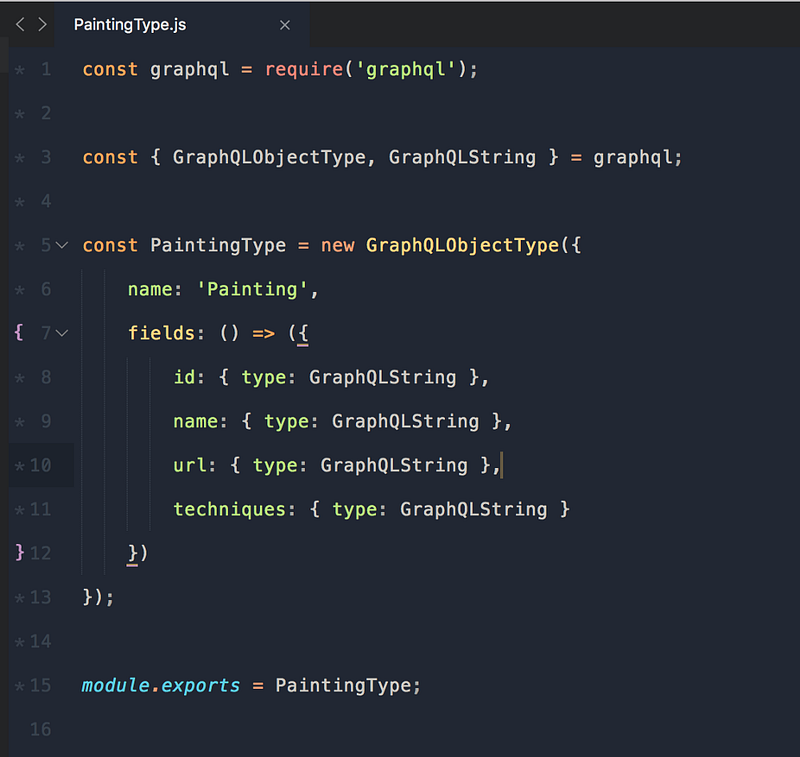
Разберём по порядку, сверху вниз:
Мы запрашиваем библиотеку GraphQL (require).
В 3 строке мы деконструируем объекты из GraphQL.
const { GraphQLObjectType, GraphQLString } = graphql
Тоже самое:
const GraphQLObjectType = graphql.GraphQLObjectType
const GraphQLString = graphql.GraphQLString
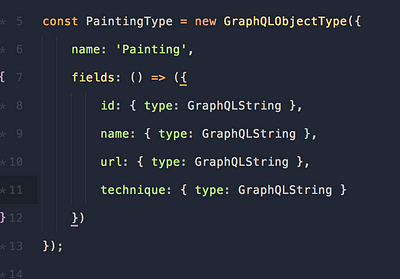
Далее, мы создаём GraphQLObjectType
Почти все типы GraphQL, которые вы определяете, будут объектными. У них есть имена, но самое главное, они описывают свои поля.
Как вы, наверное, уже заметили, GraphQL является статически типизированным языком, что означает необходимость объявлять все типы для наших полей. Сейчас все типы полей назначена как GraphQLString
Это был наш запрос на выборку картин. Теперь нам нужно подключить его к корню запроса, который будет обрабатывать сервер и откуда он будет получать все данные.

Давайте создадим файл schema.js в папке GraphQL.
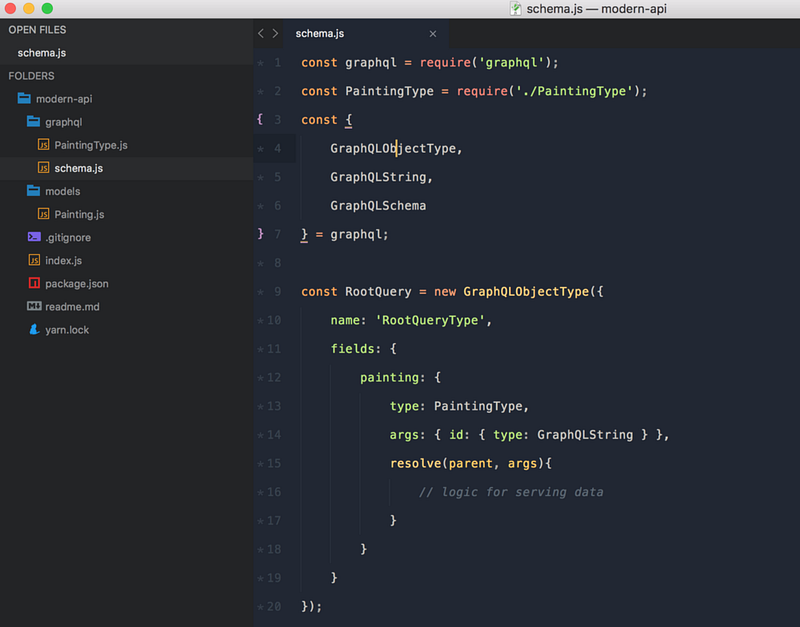
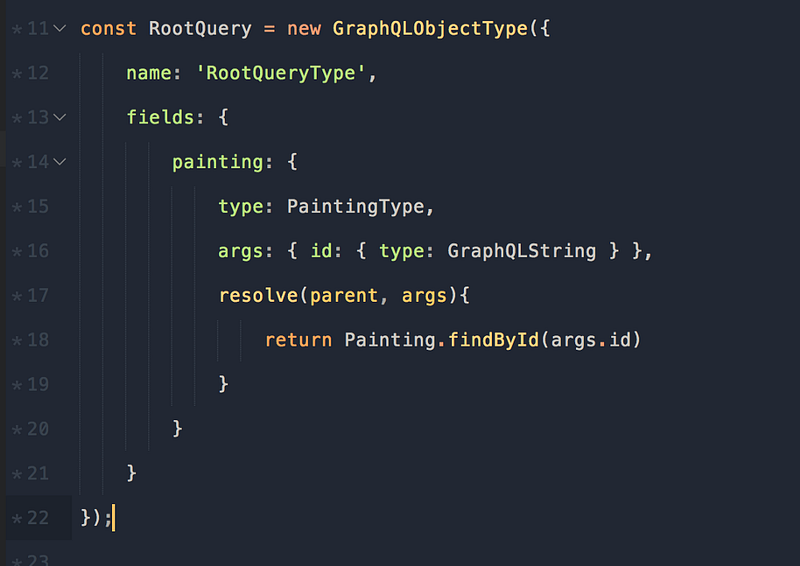
Это наш корневой запрос, который мы будем обрабатывать на сервере.
Обратите внимание, что раздел с полями теперь более запутанный — мы передаём имя поля с типом PaintingType и полем args. Позвольте спросить: как бы мы нашли конкретную картину? Нам нужен какой-то аргумент для сортировки, в данном случае это будет id .
Далее, у нас есть функция resolve, которая имеет два параметра, parent и args .
Запросы GraphQL выглядят следующим образом:
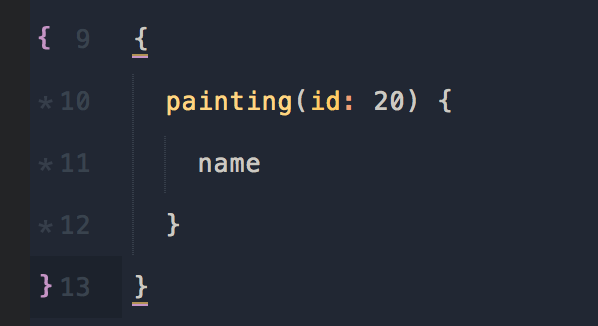
Запрос painting из PaintingType.js и parent будут использоваться в более сложных запросах, где у вас больше вложенности. (обратите внимание на то, как мы передаём аргумент, параметр args в resolve())
Давайте экспортируем наш RootQuery и передадим его на сервер Hapi. Обратите внимание на тип GraphQLSchema — это определение RootQuery/schema, который мы передаём на сервер.
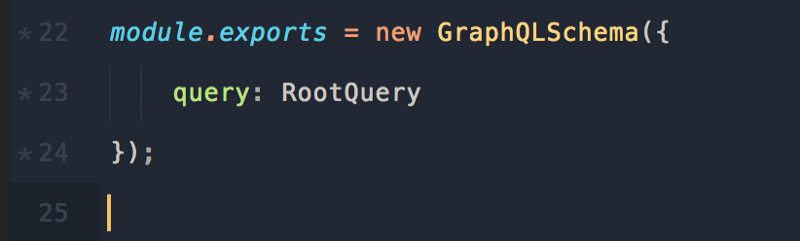
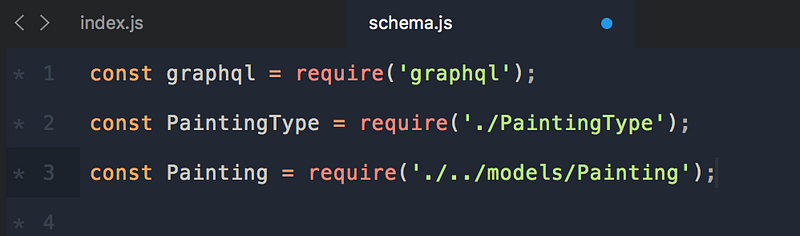
Возвращаясь к нашему index.js, мы запрашиваем пакеты GraphQL и schema.js

Далее нам нужно зарегистрировать плагин hapi-graphql.
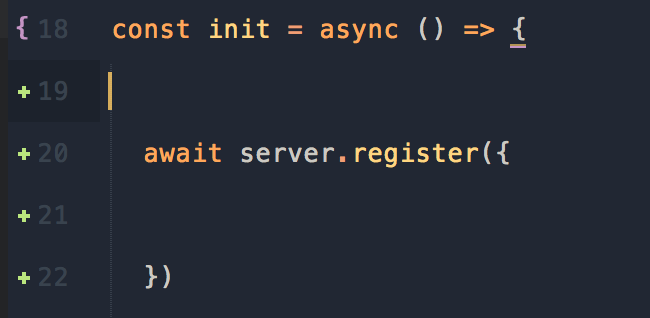
Внутри server.register({}мы передаём конфигурацию GraphQL.
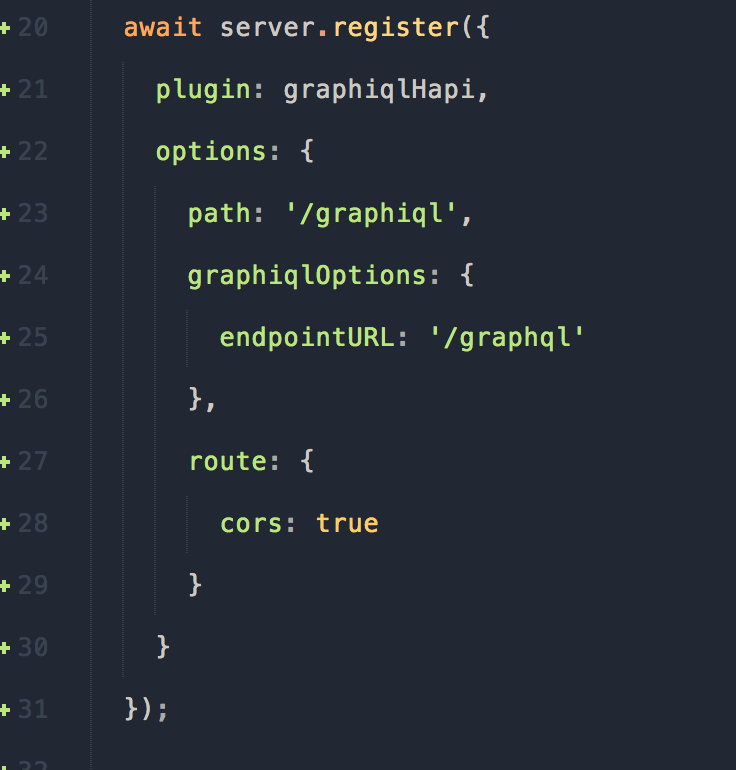
Довольно просто, не так ли? Мы установили плагин graphiql. Обратите внимание, что graphiql и graphql- две разные вещи. Graphiql ― это браузерная IDE для просмотра GraphQL.
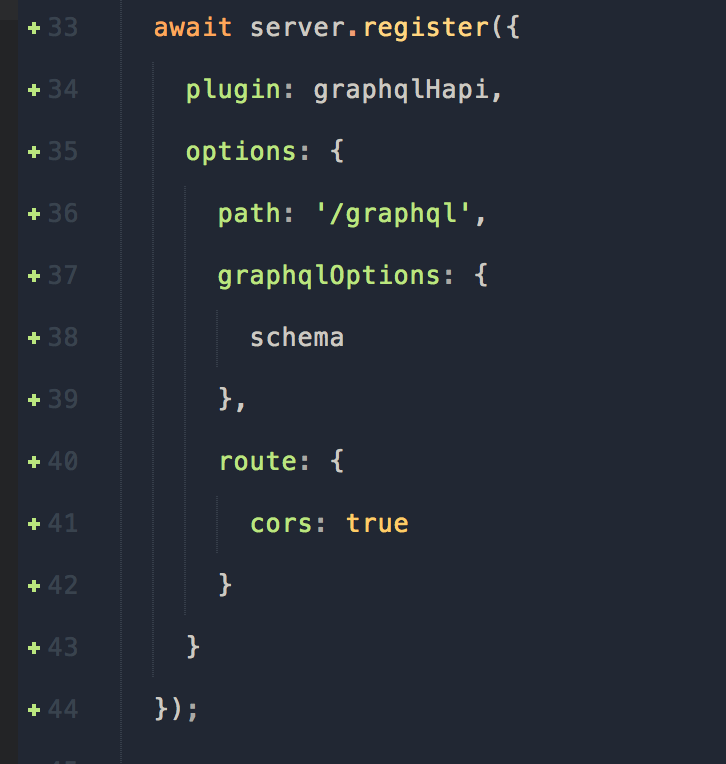
Далее, давайте зарегистрируем новый плагин: graphqlHapi, который включает в себя схему, которую мы сделали ранее.
Теперь, если мы перейдём по http://localhost:4000/graphiql
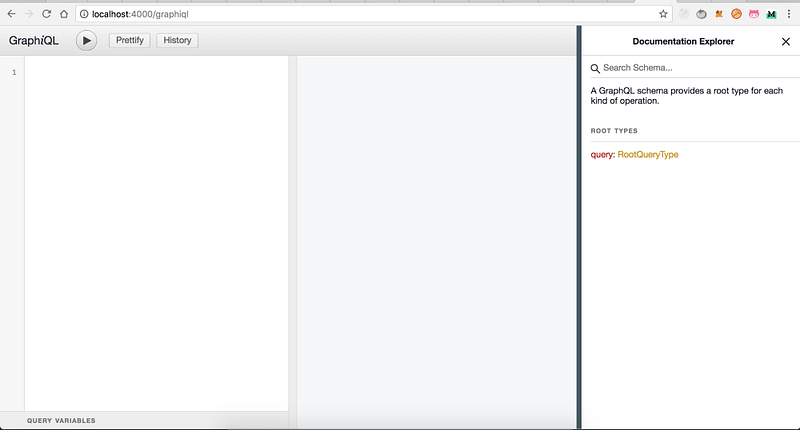
Ураа, заработало!
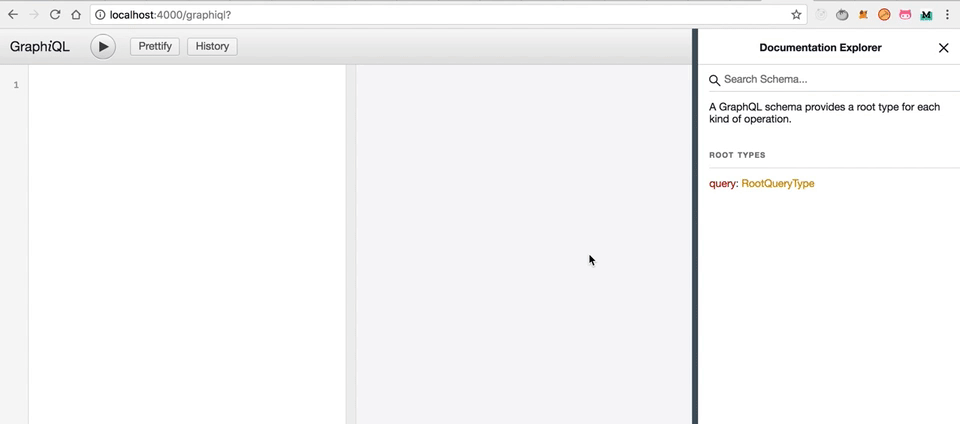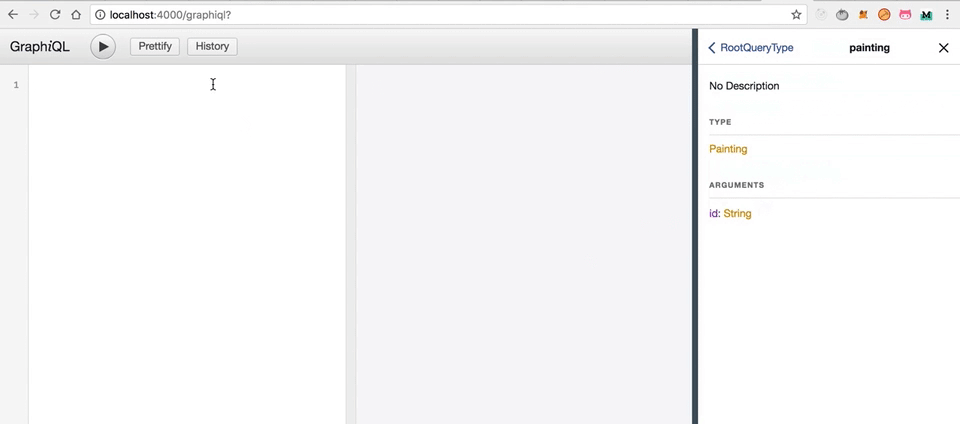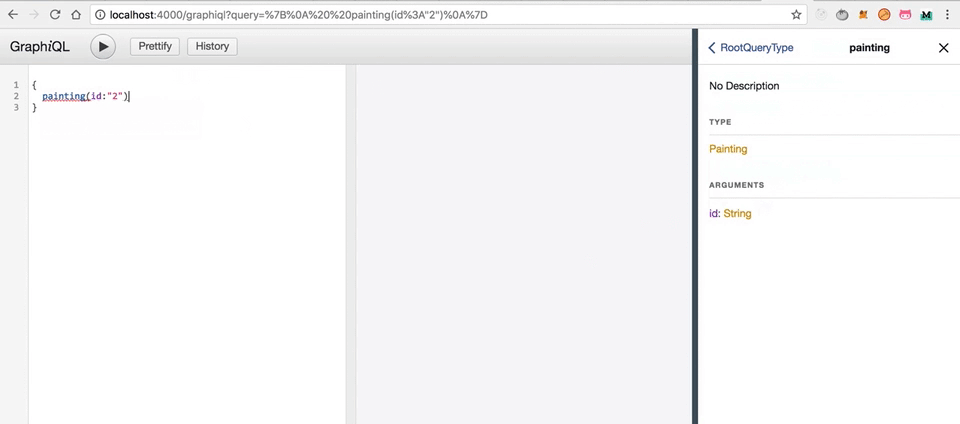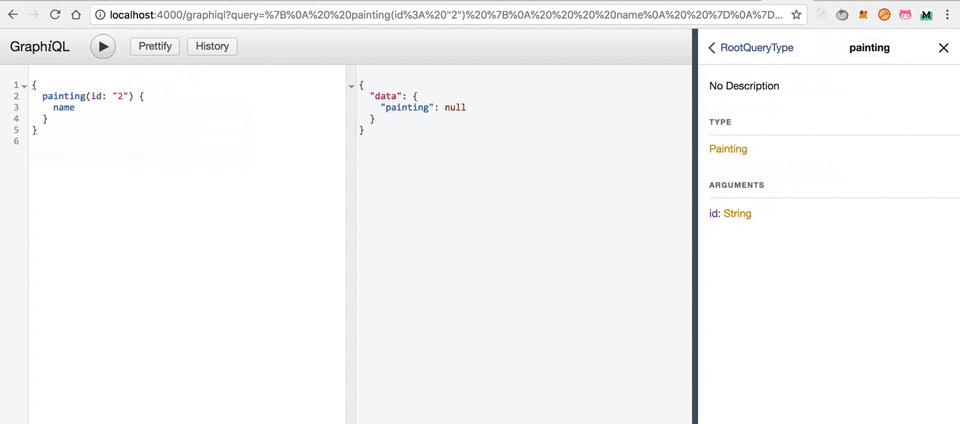
Но почему возвращается null? Есть две причины.
- Вероятно, у нас нет картины с id 2.
- Во-вторых, даже если бы у нас была картина с id 2, мы все ещё не извлекаем её из нашего MongoDB. Помните функцию
resolve, которую мы оставили пустой? Да, вот где мы будем осуществлять выборку данных из базы.
Давайте сделаем это!
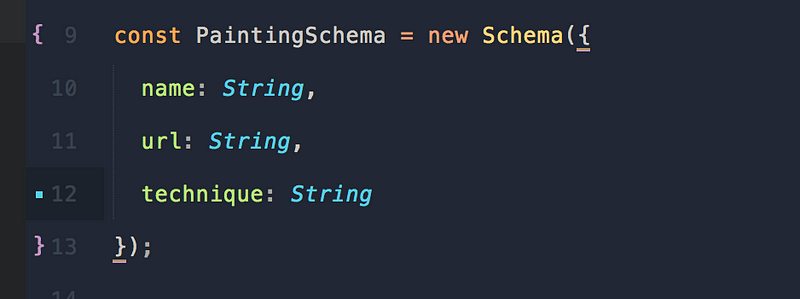
Небольшое изменение для нашей модели: давайте определим technique как просто строку, вместо массива строк.
Сделайте новый запрос с postman и изменённым полем technique. Посмотрите первую часть статьи, если вы забыли 🙂
Теперь вернёмся к нашему Graphiql. (Кстати, проверьте соответствие id в своём документе mLab. id должен совпадать, чтобы получить ответ 200.)
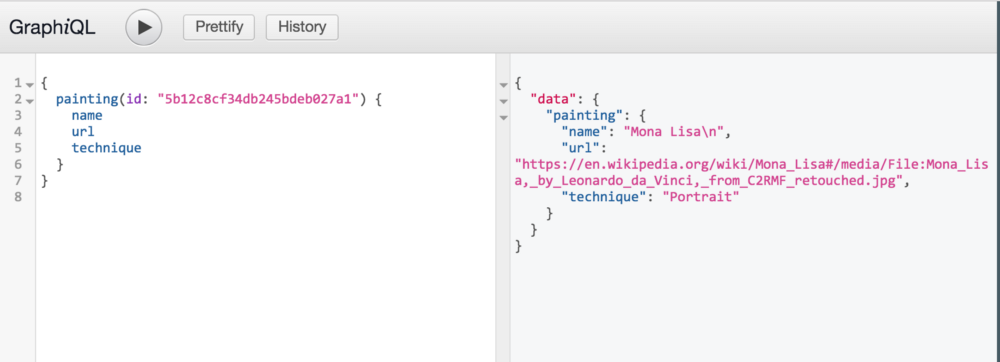
Работает как по волшебству! Отличная особенность graphiql в том, что у вас сразу есть API документация.

Последние штрихи. Swagger.

Согласно сайту Swagger,
Swagger предлагает самые мощные и простые в использовании инструменты для использования всех преимуществ спецификации OpenAPI.
Давайте установим зависимости.

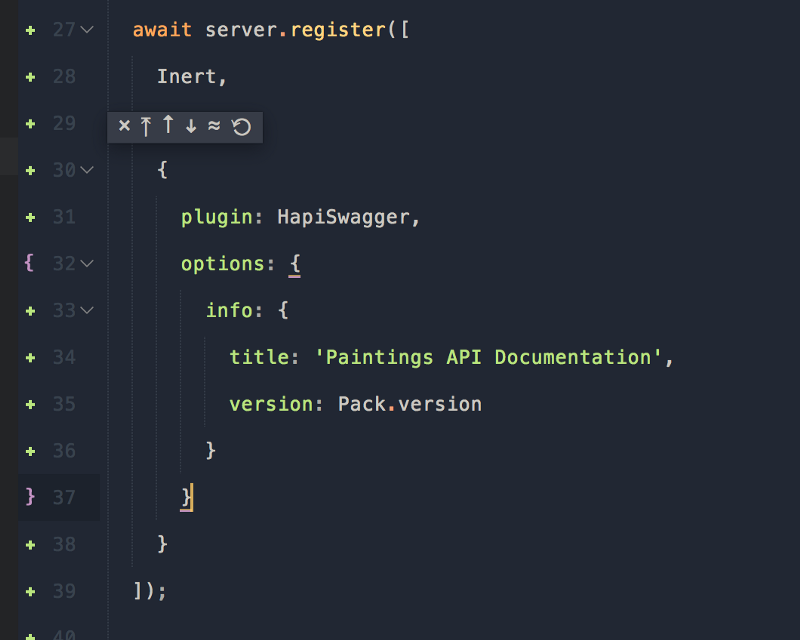
Теперь, регистрируем плагин.
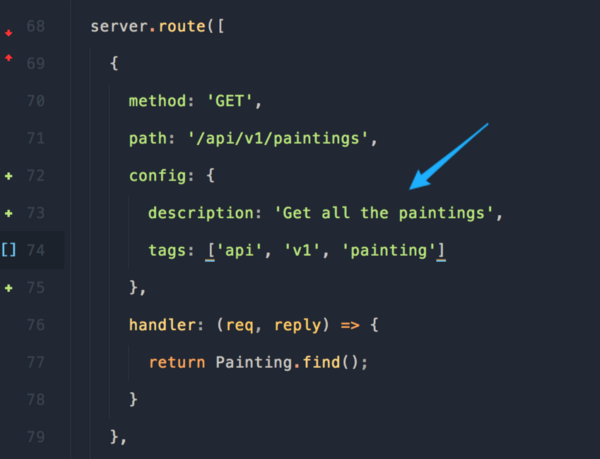
И наконец, нам нужно добавить описания и теги к нашим маршрутам.
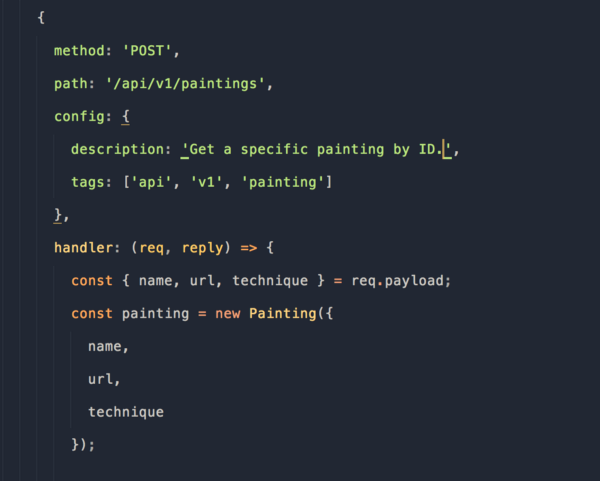
Всё готово! Перейдите по ссылке http://localhost:4000/documentation
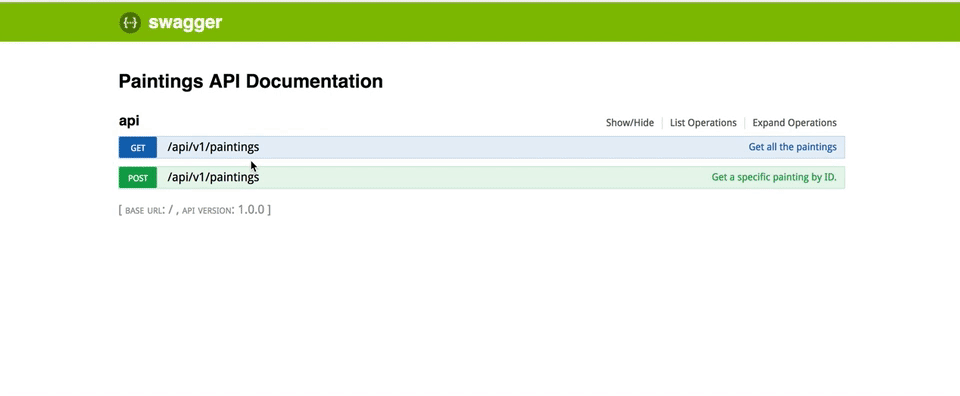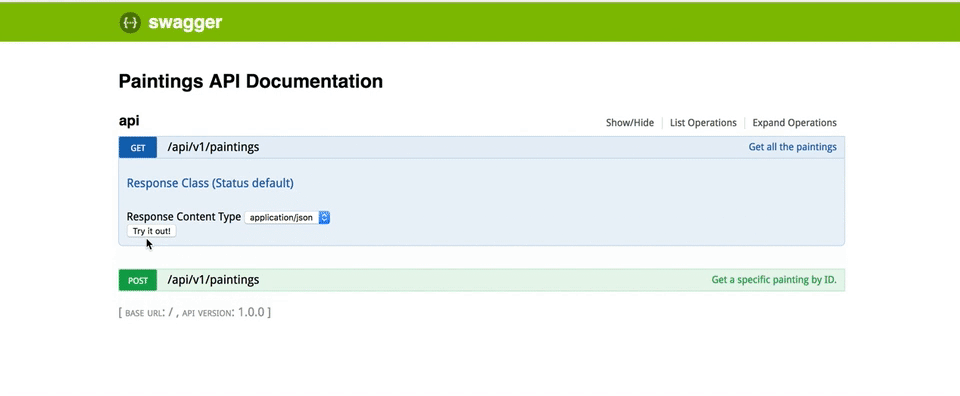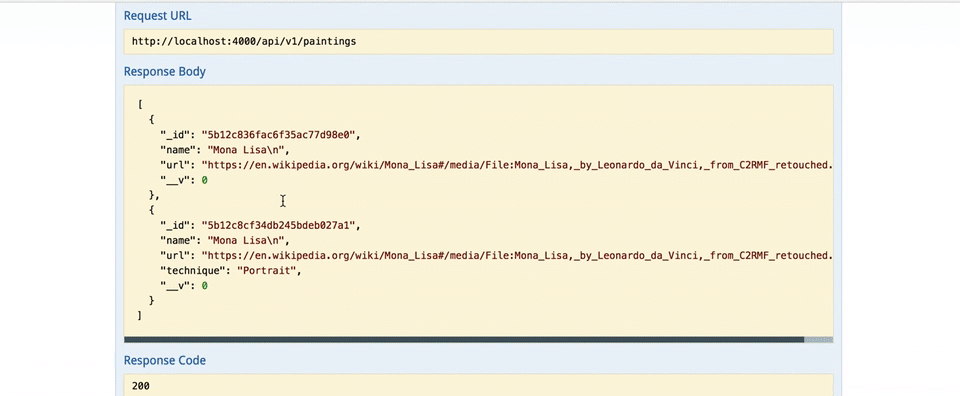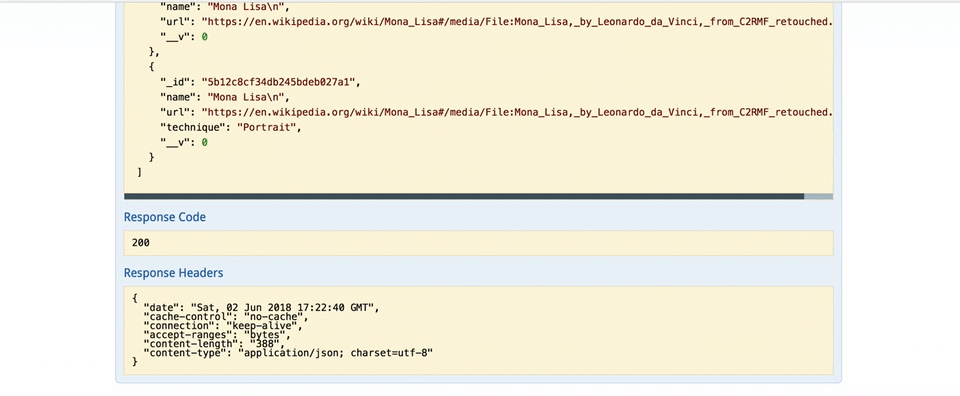
Круто, теперь у нас есть самодокументирующийся API, который мы просто передаём нашей команде.
Мы можем сделать гораздо больше. Мутации GraphQL, интерфейс для использования нашего API, рефакторинг серверного кода и так далее.
Спасибо за то, что дошли до конца, надеюсь, вы узнали много нового. Веселитесь с вашим новым API! ❤
Исходный код проекта.
Перевод статьи: Indrek Lasn How to finish setting up your powerful API with Nodejs, GraphQL, MongoDB, Hapi, and Swagger (Part II)





