
Статистика в режиме реального (или почти реального) времени чрезвычайно важна для любой компании. Каждый бизнес нуждается в таком уровне отслеживания данных, который позволяет быстро реагировать на форс-мажоры и сокращать цепи обратной связи для исправления ситуаций. SSENSE не является исключением из этого правила. Мы доверяем бизнес-показателям, которые позволяют оценивать наши достижения и намечать планы, соответствующие нашим целям и ожиданиям. Недавно моя команда столкнулась с проблемами отслеживания одной из бизнес-метрик:
- Отсутствие источника истины: источники были разнотипными и ОЧЕНЬ ненадежными.
- Слишком долгие циклы обратной связи: данные готовились в течение нескольких дней и управлялись другой командой; мы не получали вовремя должной обратной связи, чтобы быстро реагировать на вызовы и принимать контрмеры.
Нам почти сразу же потребовалась ценная информация, позволяющая сократить цикл обратной связи. Источник истины был только в одном из наших устаревших микросервисов.
В этой статье мы расскажем о том, как получили достоверную информацию, не выполнив ни одной строки кода в этом сервисе, используя только захват изменения данных и сервис миграции базы данных AWS.
Проблема
Как я уже упомянул, моя команда должна была получать бизнес-метрику почти в режиме реального времени, чтобы максимально ускорить реагирование и сократить цикл обратной связи. В качестве источника истины у нас был наш устаревший микросервис. Вроде бы ничего сложного, не так ли? Просто возьмите нужный показатель и разом покончите с этим! Увы… на деле все оказалось не так просто. В частности, у этого микросервиса выявилось несколько характеристик проблемного проекта:
- Трудности с поддержкой. Любая новая функция при добавлении в этот сервис требует либо полного рефакторинга, либо изменения нескольких файлов в проекте.
- Нестабильные тесты. Набор тестов в проекте крайне ненадежен, в то время как любое изменение кода также требует серьезных изменений в тестах.
- Отсутствие прежних сопроводителей проекта. Вам знакома ситуация, когда все ненавидят человека, написавшего фрагмент кода, который никто не может понять?
Как вы понимаете, загрузка нужного показателя из этого устаревшего микросервиса не показалась нам выходом из положения. По крайней мере, это самое последнее, что можно было предпринять. Что же мы сделали, чтобы получить фрагмент ценных данных? Мы нашли способ добыть его с минимальным количеством изменений в сервисе.
Наш путь к решению
Мы точно знали только одно: источником истины для показателя была система управления базами данных PostgreSQL, используемая нашим микросервисом. Первый проект решения, разработанный нами, предполагал извлечение информации из базы данных через определенные промежутки времени и помещение ее куда-либо, например в очередь или поток событий. В блоге AWS Database мы нашли статью “Изменение потока с Amazon RDS на PostgreSQL с использованием потоков данных Amazon Kinesis и AWS Lambda”. Она показалась нам ключом к решению.
В статье предлагалось использовать захват изменения данных (CDC) в нашей базе данных. К счастью, в PostgreSQL есть функция, предназначенная для этого. Она называется Logical Replication (Логическая Репликация) и описывается как “метод репликации, основанный на механизме Издатель-Подписчик (pubsub) для репликации объектов данных и их изменений”. Сама природа этого pubsub-шаблона идеально соответствует нашим событийно-ориентированным потребностям. Простой процесс использования ее начинается с репликации всех изменений из таблицы источника, который мы указали. Функция Lambda cron принимает каждое из этих изменений, преобразует его в общий формат, такой как JSON, а затем передает в поток AWS Kinesis.
В конце этого конвейера приемник информации получает эти изменения в виде событий и извлекает нужный нам показатель.
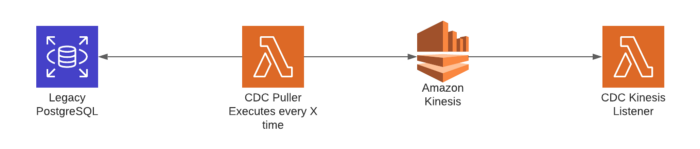
Выглядит неплохо, не правда ли? Но у такого решения проблемы обнаружилось несколько неудобных для нас моментов:
- Мы должны были применить время простоя к нашей базе данных (к сожалению, это оказалось неизбежным).
- Нам пришлось бы управлять новым сервисом только для того, чтобы получить изменения и перенести их в AWS. Управление новым сервисом, даже таким как Lambda, означает создание нового кода, техническое обслуживание и устранение ошибок.
- По своей природе базы данных Lambda и SQL не являются удачной комбинацией, так как пулинг управления соединением БД особенно сложен в таком случае и грозит риском прерывания соединения с базой данных.
- Прямое использование базы данных не является хорошей моделью интеграции между сервисами из-за жесткого связывания.
Это решение было достаточно хорошим, но все же не идеальным. Мы вернулись к электронной “доске”, и после некоторых обсуждений познакомились с продуктом Amazon Web Services (AWS) — Сервисом миграции базы данных (DMS). По сути, он создан для решения проблем, подобных нашей.
DMS легко интегрируется с базами данных в качестве источника для внесения изменений в целевой объект (в нашем случае в Kinesis). Этот продукт действительно полностью отвечает нашим потребностям, и вот почему:
- Нам не нужно управлять каким-либо новым кодом для получения изменений из PostgreSQL. Это значительно снижает риски, поскольку избавляет от воздействия устаревшего микросервиса.
- Мы можем сосредоточиться на главном — работе с CDC-событием, то есть обработке бизнес-показателя и выводе его на контрольную панель.
- Мы не зависим от множества особенностей устаревшего микросервиса.
- Мы можем расширить функциональность этого приложения для других внутрикорпоративных нужд.
Наша архитектура с использованием бессерверной платформы оказалось простой, но мощной. Вот как она выглядит:
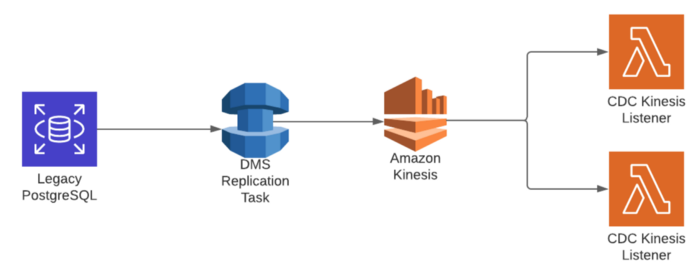
Чего мы добились?
- Создали экземпляр DMS-репликации, чтобы временно сохранить наши CDC-события.
- Наладили DMS-миграцию данных: после считывания всех CDC-событий в режиме реального времени из нашей устаревшей базы данных они перенаправляются в поток Kinesis.
- Подключили сервис Lambda, который будет принимать этот поток и реагировать на новые события, которые придут (фактическое содержание Lambda выходит за рамки данной статьи).
Операционные проблемы и сбои
“С большой властью приходит большая ответственность”, — говорил Дядя Бен Питеру Паркеру. То же самое можно сказать об этом сервисе. Появление новых рабочих инструментов в вашей организации в конечном итоге создает новые операционные проблемы:
- более высокий уровень мониторинга ваших сервисов;
- дополнительные затраты;
- необходимость в оптимизации ресурсов.
Для реализации своего решения нам пришлось установить несколько аварийных сигналов для оповещения:
- О превышении возможностей пропускной способности потока Kinesis (в случае перегрузки Kinesis, сообщения в потоке начнут накапливаться и вызовут возможную задержку в потреблении).
- О прекращении поступления элементов в поток Kinesis (PutRecord = 0 по крайней мере в течение 10 минут, например).
Поначалу мы были уверены, что этого достаточно. Но какой-то момент тестирования — к счастью, не процессе производства — мы заметили, что в нашей базе данных стремительно сокращается объем доступного дискового хранилища. В конце концов свободного места на диске не осталось.
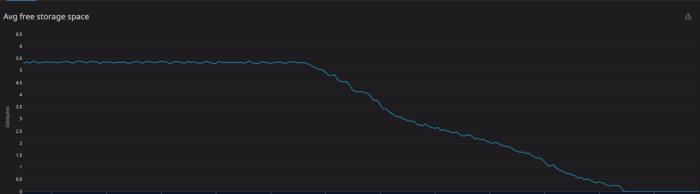
Быстрым решением на тот момент было увеличение объема дискового хранилища. Но оно послужило лишь заплатой для более серьезной проблемы.
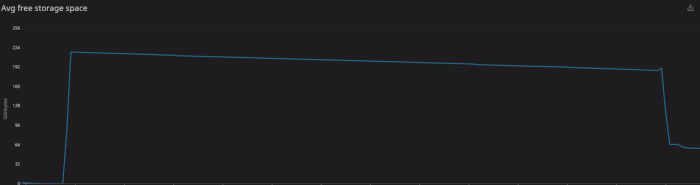
Источник проблем был связан с тем, как PostgreSQL обрабатывает репликацию. Все изменения сохраняются в WAL-журналах до тех пор, пока все узлы репликации не восстановятся. Это влияет на показатель, называемый задержкой репликации.
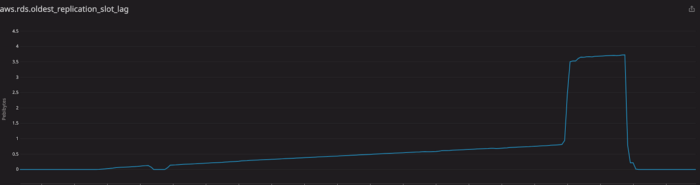
Решение оказалось проще, чем мы думали. Мы обнаружили узлы репликации, также известные как слоты репликации, с помощью запроса:
SELECT * FROM pg_replication_slots;Мы нашли один неиспользуемый слот и удалили его с помощью запроса:
SELECT pg_drop_replication_slot(‘replication_slot_id’);После этого все пошло, как обычно:
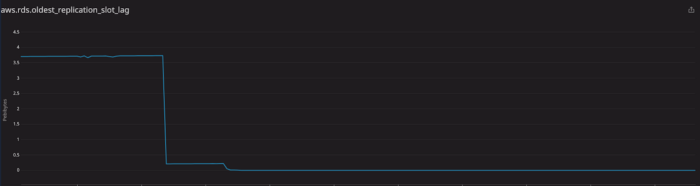
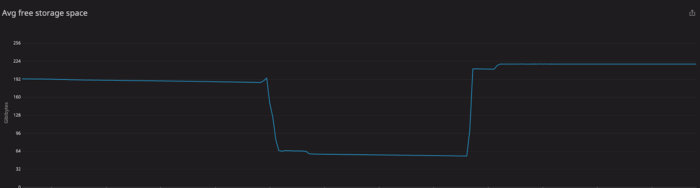
Этот инцидент заставил нас осознать несколько моментов в нашей производственной деятельности:
- Нужно следить за изменениями в таблице для CDC в DMS и при необходимости обязательно удалить слот репликации.
- Следует создавать аварийные сигналы для показателей самой первой задержки репликации в слоте и свободного места хранения, чтобы вовремя узнать, не перегружает ли DMS-задача имеющиеся ресурсы.
Для оптимизации затрат мы приняли несколько решений:
- Отключать рабочий процесс и удалять все ресурсы в среде тестирования, поскольку соответствующие данные всегда находятся в Prod.
- Использовать инфраструктуру в качестве кода — для нас с бессерверной платформой — для того, чтобы иметь возможность создавать/уничтожать эти ресурсы при необходимости тестирования.
- Экземпляр репликации используется по требованию и на один уровень ниже текущей базы данных, с которой он реплицируется.
Заключение
При работе с устаревшими системами всегда учитывайте риск, связанный с добавлением дополнительных функций, каким бы простым это ни казалось. Иногда лучше получить эту функциональность из более новой/внешней системы, способной реагировать на изменения в устаревшей системе, чтобы обеспечить ожидаемый результат.
Это всего лишь один пример того, как вы можете работать с системами такого типа. В конце концов, мы ведь все ненавидим устаревшие микросервисы, верно? Отказ от устаревшего фреймворка и переход к более элегантному и масштабируемому решению стали для SSENSE значительным шагом вперед.
Читайте также:
- Все, что вам нужно знать о переходе на реляционную базу данных AWS
- Архитектура ПО: создайте свое приложение с AWS
- Как создать бессерверное приложение с Netlify и JavaScript
Читайте нас в Telegram, VK и Дзен
Перевод статьи Fernando Alvarez: How We Achieved Real-time Metrics From A Legacy System Without Changing A Single Line Of Code





