
Данные есть везде, на каждом посещенном вами сайте. Чаще всего они уже представлены в читаемом текстовом формате, пригодном для использования в новом проекте, однако, несмотря на то, что нужный текст всегда можно скопировать и вставить прямо со страницы сайта, когда речь заходит о больших данных — о тексте с десятка тысяч веб-сайтов — скрейпинг приходит на помощь.
Обучаться веб-скрейпингу (web-scraping) поначалу сложно, однако если вы начнете своё знакомство с большими данными, используя правильные инструменты, то предстоящий вам путь существенно облегчится.
В пошаговом руководстве вы узнаете, как сделать скрейпинг нескольких страниц веб-сайта с помощью самой простой и популярной библиотеки Python для скрейпинга: Beautiful Soup.
Руководство состоит из двух разделов. В первом разделе речь пойдет о том, как осуществить скрейпинг одной страницы, а во втором — о том, как скрейпить сразу нескольких страниц с помощью примера кода, из первого раздела.
Список рассматриваемых в руководстве тем:
- Что нужно для начала веб-скрейпинга?
- Установка, запуск и настройка Python-библиотеки Beautiful Soup.
- Раздел 1: cкрапинг одной страницы:
— Импорт библиотек.
— Получение HTML-содержимого веб-сайта.
— Анализ веб-сайта и его HTML-разметки.
— Одновременное нахождение нескольких HTML-элементов с помощью Beautiful Soup.
— Экспорт данных вtxt-файл. - Раздел 2: cкрапинг нескольких страниц:
— Получение атрибутаhref.
— Нахождение нескольких элементов с помощью Beautiful Soup.
— Переход по каждой из необходимых ссылок.
Что нужно для начала веб-скрейпинга?
- Beautiful Soup: это пакет Python для анализа веб-сайтов, построенных на технологиях HTML и CSS, то есть, без использования JavaScript-фреймворков вроде React, Angular, VueJS. Beautiful Soup хорошо справляется с разбором HTML и XML документов на части: библиотека создаёт дерево синтаксического анализа веб-страниц для последующего извлечения с них разнообразных данных в удобном для программиста формате. Не волнуйтесь, вам не нужны предыдущие знания о Beautiful Soup, чтобы выполнять указания из руководства — во время чтения вы всему научитесь с нуля!
- Библиотека requests: это стандарт индустрии для выполнения HTTP-запросов на языке программирования Python. Данная библиотека используется в дополнение к Beautiful Soup, когда нужно получить HTML-файл с веб-сайта.
- Python: чтобы следовать руководству, вам не нужно быть экспертом в Python, однако, по крайней мере, вы должны знать, как работают циклы for и списки.
Перед началом руководства, убедитесь, что на вашем компьютере установлен Python 3 версии.
Давайте начнем ознакомление с пособием для новичков по настройке Beautiful Soup в Python!
Установка, запуск и настройка Python-библиотеки Beautiful Soup
- Начнём с установки Beautiful Soup на ваш компьютер. Для этого выполните следующую команду в командной строке или терминале:
pip install bs4- Теперь установите парсер: он понадобится для извлечения данных из HTML-документов. В руководстве предлагается использовать библиотеку-парсер
lxml, следовательно, выполните установочную команду:
pip install lxml- Пришло время устанавливать библиотеку
requests. Для этого выполните следующую команду в командной строке или терминале:
pip install requestsНаконец-то настройка окружения завершена — можно приступать к программированию!
Раздел 1: Скрейпинг одной страницы
Руководство бережно проведёт вас через каждую строчку кода, необходимого для создания вашего первого скрейпера веб-сайтов. Полный код вы найдете в самом конце статьи. Давайте начнем!
Импорт библиотек
Для скрейпинга нам пригодятся библиотеки BeautifulSoup и request, поэтому импортируем их в программу с помощью двух строчек кода:
from bs4 import BeautifulSoup
import requestsПолучение HTML-содержимого веб-сайта
Теперь, в образовательных целях, давайте получим все данные сайта, содержащего сотни страниц информации о фильмах; начнём со скрейпинга первой страницы, а затем уже разберёмся со скрейпингом множества страниц одновременно.
В самом начале нам стоит выбрать ссылку на веб-сайт, для примера возьмём страницу диалогов фильма “Титаник”, но вы можете выбрать любой фильм; затем нужно сформировать и отправить HTTP-запрос на сайт, чтобы получить ответ, в котором и содержится нужное описание фильма. Получив ответ на запрос, сохраняем его в переменной с идентификатором result, чтобы использовать метод .text для получения содержимого страницы сайта:
website = 'https://subslikescript.com/movie/Titanic-120338'
result = requests.get(website)
content = result.textНаконец, воспользуемся парсером lxml для получения “супа” — объекта, содержащего все данные во вложенной структуре, которая понадобится нам в работе позднее:
soup = BeautifulSoup(content, 'lxml')
print(soup.prettify())Теперь, когда у нас уже есть объект soup, доступ к HTML в читабельном формате легко получается с помощью функции .prettify(). Несмотря на то, что HTML в текстовом редакторе также пригоден для ручного поиска конкретных его элементов, гораздо лучше сразу перейти к HTML-коду необходимого нам элемента страницы: в следующем шаге мы как раз это сделаем.
Анализ веб-сайта и его HTML-разметки
Важным шагом перед тем, как перейти к написанию кода, является анализ веб-сайта, скрейпинг которого производится, и полученного HTML-кода, ради нахождения самого лучшего подхода к решению задачи. Ниже приведен скриншот страницы описания фильма, по которому видно, что элементами, текст которых нужно получить, являются название фильма и реплики из него:
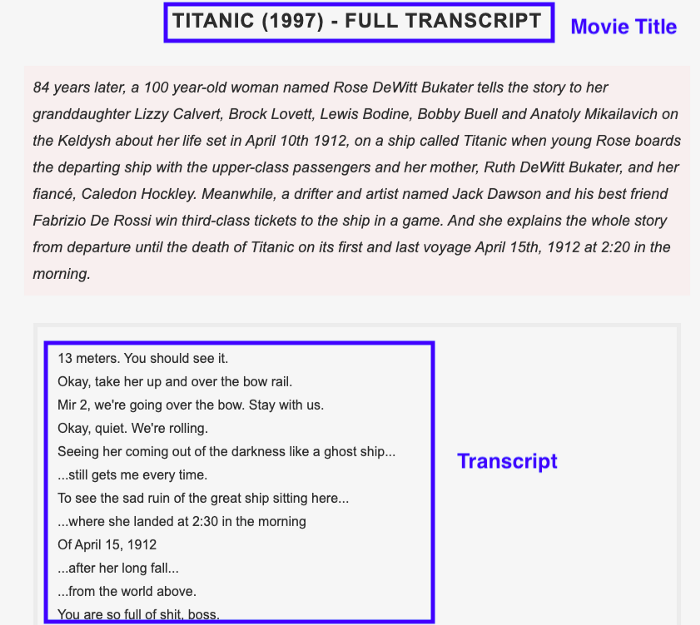
Теперь необходимо разобраться, как получить HTML только этих двух нужных нам элементов; выполните следующие действия:
- Перейдите на веб-страницу с диалогами из выбранного вами фильма.
- Наведите курсор на название фильма или его диалоги, а затем щелкните правой кнопкой мыши: появится меню, в котором выберите пункт “Исследовать”, чтобы открыть исходный код страницы сразу на нужном месте.
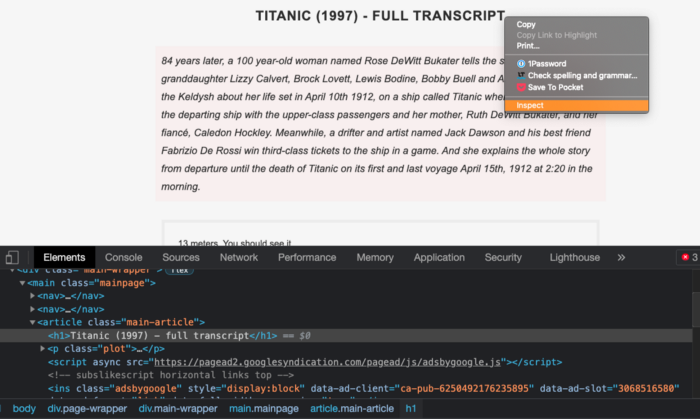
Ниже приведена уменьшенная версия HTML-кода, полученного после нажатия на пункт меню “Исследовать”. В дальнейшем в качестве справочника используется именно эта HTML-разметка, полезная при определении местоположения элементов в следующем шаге руководства.
<article class ="main-article">
<h1> Титаник(1997) </h1>
<p class ="plot" > 84 года спустя... </p>
<div class ="full-script">
"13 метров. Можешь сам посмотреть. "
<br>
"Хорошо, поднимите её и перекиньте через носовой поручень. "
<br>
...
</div>
</article>Поиск HTML-элемента с помощью Beautiful Soup
Найти конкретный HTML-элемент в объекте, полученном с помощью Beautiful Soup — проще простого: нужно всего-то применить метод .find() к созданному ранее объекту из переменной soup.
В качестве примера давайте найдем блок, содержащий название фильма, описание и диалоги; нужный блок находится внутри тега article и обозначен классом main-article. Доступ к данному блоку осуществляется с помощью одной-единственной строчки кода:
box = soup.find('article', class_='main-article')Теперь давайте найдем название фильма и список реплик. Название фильма находится внутри тега h1 и не обозначено никаким классом, что никак не помешает нам его найти; после нахождения нужного элемента, было бы неплохо получить из него текст, используя метод .get_text():
title = box.find('h1').get_text()Список реплик из фильма расположен внутри тега div и обозначен классом full-script. В таком случае, чтобы получить текст, нужно изменить параметры по умолчанию в методе .get_text(). Во-первых, устанавливаем настройку strip=True, чтобы удалить все лишние пробелы. Затем добавим пробел в качестве разделителя separator="", чтобы пробел ставился после каждой новой строки, то есть, после каждого нового символа перехода на новую строку \n:
transcript = box.find('div', class_='full-script')
transcript = transcript.get_text(strip=True, separator=' ')На данный момент скрейпинг данных с одной страницы успешно завершён. Выведите в консоль или терминал значения переменных title и transcript, чтобы убедиться в корректности собственного кода на Python.
Экспорт данных в txt-файл
Скорее всего, ради возможности дальнейшего использования только что полученных в результате успешного скрейпинга данных, вы захотите куда-то их сохранить: например, экспортировать данные в формат .csv, .json или какой-либо другой; в данном примере извлеченные данные сохраняются в файле формата .txt:
При экспорте данных пригодится ключевое слово with, как показано в приведенном ниже коде:
with open(f'{title}.txt', 'w') as file:
file.write(transcript)Имейте в виду, что в примере при установке названия фильма в качестве имени файла используется f-string, известная как “форматируемая строка”.
После выполнения кода в вашем рабочем каталоге должен появиться файл в формате .txt.
Теперь, когда вы успешно выполнили скрейпинг данных с одной страницы, вы готовы приступать к скрейпингу сразу нескольких страниц!
Раздел 2: Скрейпинг нескольких страниц
Ниже представлен скриншот первой страницы сайта с диалогами из фильмов: сайт предоставляет аж 1 234 такие страницы, на каждой из которых размещено около 30-ти фильмов:
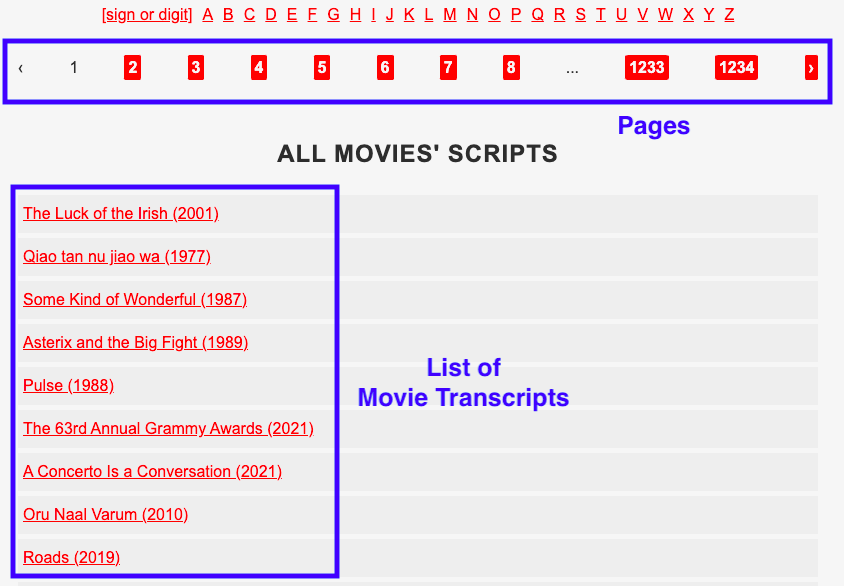
Во второй части руководства вы узнаете, как скрейпить несколько ссылок, получая атрибут href для каждой из них. Во-первых, понадобится изменить веб-сайт для скрейпинга с используемого в первом примере на приведённый выше.
Новая переменная с идентификатором website, содержащая ссылку на веб-сайт, оформляется следующим образом:
root = 'https://subslikescript.com'
website = f'{root}/movies'Вы можете заметить в коде примера ещё одну новую переменную с идентификатором root — она пригодится позже.
Получение атрибута href
Сейчас вы узнаете, как получить атрибут href сразу для всех 30-ти фильмов, перечисленных на одной странице: для начала выберите любое название фильма из блока “список фильмов” на скриншоте выше.
Теперь необходимо получить HTML-разметку страницы. Каждый из HTML-тегов <a></a> относится к определенному названию фильма, причем ссылочный тег <a></a> выбранного вами фильма должен быть выделен синим цветом, как показано на скриншоте:
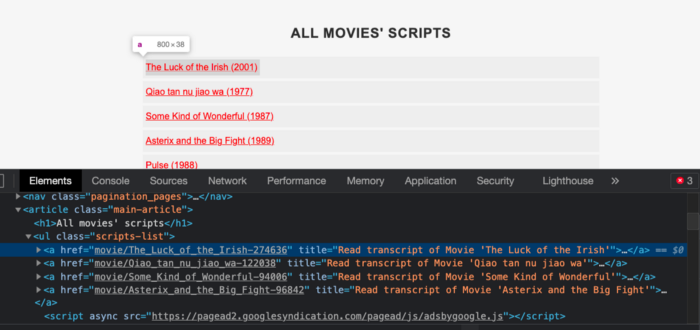
На скриншоте видно, что ссылки внутри href не содержат корня ссылки на веб-сайт subslikescript.com: именно поэтому для составления полного веб-адреса пригодится ранее созданная переменная root, содержащая как раз корень для ссылок.
Теперь давайте найдем все ссылочные теги <a></a> на странице со списком фильмов.
Одновременное нахождение нескольких HTML-элементов с помощью Beautiful Soup.
Для нахождения нескольких элементов в Beautiful Soup пригодится специальный метод .find_all() с параметром-настройкой href=True: данный метод позволяет удобно и быстро извлекать ссылки, соответствующие каждой из страниц с диалогами:
box.find_all('a', href=True)Извлечь ссылки из href можно с помощью добавления указания на атрибут [‘href’] к выражению выше; однако метод .find_all() возвращает список, а не строки, поэтому придется получать атрибут href по одному внутри обходного цикла:
for link in box.find_all('a', href=True):
link['href']Теперь было бы неплохо создать свой список из ссылок в нужном формате, в чём нам поможет списковое включение, также известное как генератор списка:
links = [link['href'] for link in box.find_all('a', href=True)]
print(links)При выводе списка ссылок на экран с помощью функции print(), вы увидите все те ссылки, веб-страницы которых планируется скрейпить. В следующем шаге руководства мы как раз реализуем скрейпинг каждой из них.
Переход по каждой из необходимых ссылок
Для получения диалогов фильмов по каждой из полученных на предыдущем этапе ссылок, выполним те же шаги, что и для одной ссылки ранее, но на этот раз воспользуемся циклом for, повторив таким образом все действия по нескольку раз:
for link in links:
result = requests.get(f'{root}/{link}')
content = result.text
soup = BeautifulSoup(content, 'lxml')Как вы помните, сохранённые ранее ссылки не содержат корня веб-сайта subslikescript.com, поэтому следующим шагом будет форматирование ссылок выражением f’{root}/{link}’ для добавления пресловутого корня. Остальной же код программы-скрейпера остаётся таким же, как в первой части руководства.
Полный код для проекта выглядит следующим образом:
from bs4 import BeautifulSoup
import requests
root = 'https://subslikescript.com'
website = f'{root}/movies'
result = requests.get(website)
content = result.text
soup = BeautifulSoup(content, 'lxml')
box = soup.find('article', class_='main-article')
links = [link['href'] for link in box.find_all('a', href=True)]
# print(links) # ссылки без корней веб-сайта
for link in links:
result = requests.get(f'{root}/{link}')
content = result.text
soup = BeautifulSoup(content, 'lxml')
box = soup.find('article', class_='main-article')
title = box.find('h1').get_text()
transcript = box.find('div', class_='full-script').get_text(strip=True, separator=' ')
with open(f'{title}.txt', 'w') as file:
file.write(transcript)Для перемещения по страницам сайта у вас есть два варианта действий:
- Вариант 1:
Просмотрите детали о любой из страниц, отображаемых на сайте (например, 1,2,3, …1234) с целью получения тега<a></a>, содержащего атрибутhrefсо ссылками на каждую страниц описания фильмов. Получив ссылки, объедините их с корнем и выполните действия, описанные в разделе 2. - Вариант 2:
Перейдите на страницу под номером 2 и скопируйте полученную ссылку. Она должна выглядеть так:subslikescript.com/movies?page=2. Как вы заметили, для каждой страницы сайт генерирует ссылку, следуя одному шаблону:f’{website}?page={i}’. Вы можете повторно использовать переменнуюwebsiteи выполнить цикл по диапазону чисел между единицей и десяткой, если хотите перейти по первым десяти ссылкам.
Читайте также:
- 15 Python пакетов, которые нужно попробовать
- 7 Способов вывести свои новые навыки Python на следующий уровень
- Как я создал веб-скрапер на Python для поиска жилья
Читайте нас в Telegram, VK и Дзен
Перевод статьи Frank Andrade: How To Easily Scrape Multiple Pages of a Website Using Python





