
Сначала мы посмотрим, как подготовить текстовые данные для подачи их в модель машинного обучения. Затем покажем, как использовать Scikit-learn для реализации модели классификатора, а в конце поговорим об эффективности модели.
Обзор данных
Датасет, который мы будем использовать, можно найти по следующей ссылке. Это двоичный набор данных для классификации настроений, разделенный на две папки: положительные и отрицательные отзывы (по 1000 штук в каждой папке).
Поскольку отзывы о фильмах представляют собой текстовые файлы, нам необходимо предварительно обработать данные, чтобы подготовить их, а затем передать модели машинного обучения. После загрузки текстовых данных нужно разделить их, чтобы создать обучающий и тестовый датасеты.
def get_text_data(path, label = None):
X = []
for review in os.listdir(path):
with open(os.path.join(path,review)) as f:
rev = f.read()
X.append(rev)
y = [label]*len(X)
return X, y
# Путь папки
positive_review = "review_polarity/txt_sentoken/pos"
negative_review = "review_polarity/txt_sentoken/neg"
X,y = get_text_data(positive_review, label = "pos")
X_neg, y_neg = get_text_data(negative_review, label = "neg")
X += X_neg
y += y_neg
# Разделение данных
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.33, random_state = 42)Извлечение признаков
Поскольку мы не можем использовать текстовые данные для передачи модели машинного обучения, нам нужно провести подготовительную работу, чтобы машина их распознала. Есть несколько способов извлечь признаки из текстовых данных. Один из наиболее распространенных методов преобразования текстовых данных в числовые — использование частоты появления каждого слова в данных.
vocab = {}
for word in X[0].split():
if word in vocab.keys():
vocab[word] += 1
else:
vocab[word] = 0Показанный выше код создает словарь, который сопоставляет каждое слово с частотой его появления. Частота слова показывает, сколько раз оно появляется в тексте, поэтому длина нашего словаря равна количеству различных слов в тексте.
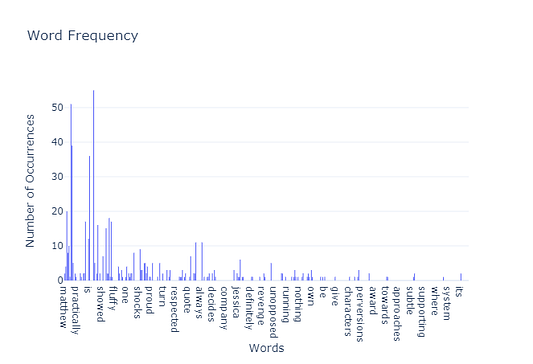
На этой картинке мы видим частоту слов в одном документе (т.е. отзыве о фильме). Ноль означает, что слово появляется только один раз в тексте. Этот процесс заканчивает разреженный вектор с большим количеством нулей. Если мы повторим данный процесс для всех отзывов, то получим разреженную матрицу, в которой большинство элементов равно нулю.
Частота элементов
Разреженная матрица, полученная после применения вышеуказанного метода, не имеет для вас смысла, если вы незнакомы с понятием “частота элемента”. Как правило, под ним подразумевают определение веса или важности элемента в документе (отзыве). Суть этого метода анализа можно свести к следующему.
Вес элемента, встречающегося в документе, пропорционален частоте использования элемента.
Как мы вычисляем частоту элемента? Мы делим число вхождений слова на общее количество слов в документе.
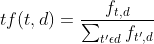
Здесь “d” обозначает документ, с которым мы работаем. Одна из проблем такого подхода заключается в том, что в отзывах со словами “the” или “is” будет больше выделений, поскольку эти слова встречаются чаще и называются “стоп-словами”. И наоборот, более значимые слова не будут иметь достаточного веса, поскольку эти слова, как правило, встречаются не так часто или вообще редко.
Обратная частота документа
Чтобы перевести функцию count в значения с плавающей точкой, подходящие для подачи в классификатор, а также придать большее значение редким или менее частым словам, обычно используется преобразование tf-idf. Его суть заключается в том, что частота элемента умножается на обратную частоту документа. Это преобразование реализуется инструментом Scikit-learn с помощью класса TfidTransformer.
Извлечение признаков из текстовых данных с помощью Scikit-learn
Scikit-learn включает встроенные функции для преобразования текстовых данных в числовые. Ниже показаны шаги, которые необходимо выполнить.
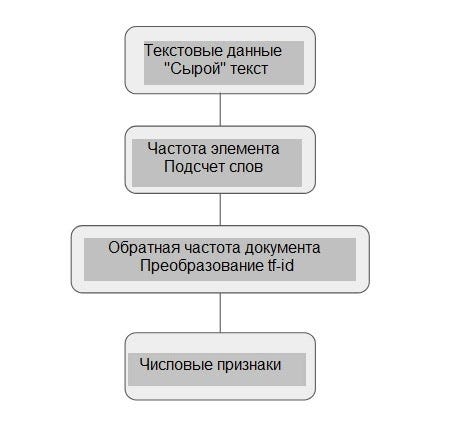
Остановимся подробно на каждом процессе, участвующем в извлечении признаков из текстовых данных.
Частота элемента
Чтобы преобразовать “сырой” текст в матрицу подсчета слов, Scikit-learn оснастили классом CountVectorizer, который превращает набор текстовых документов в матрицу подсчета токенов. Этот класс также может отфильтровывать стоп-слова. Посмотрим, как это работает.
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document',
'And this is the third one',
'Is this the first document?'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
vectorizer.get_feature_names()Поскольку каждый из отзывов довольно объемный, создадим корпус данных в качестве примера. После реализации класса CountVectorizer можно настроить объект, вызывающий функцию fit_transform. Чтобы увидеть слова в словаре, используем функцию get_feature_names, которая возвращает:
['and','document','first','one','second','the','third','this']
Мы видим, как частота слов преобразует вектор X в массив NumPy, где каждая строка соответствует документу в корпусе (строкам, хранящимся в списке). Числа в матрице представляют количество вхождений каждого слова в документах.
X.toarray()
array([[0, 1, 1, 1, 0, 0, 1, 0, 1],
[0, 2, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 1, 1, 0, 1, 1, 1],
[0, 1, 1, 1, 0, 0, 1, 0, 1]])По умолчанию класс предлагает набор параметров, которых в большинстве случаев вполне достаточно. Если же мы хотим удалить “стоп-слова” из словаря, то можем изменить этот параметр с “None“ на “English”. Эта библиотека использует предопределенный список слов, считающихся “стоп-словами”, и может отфильтровывать их из корпуса данных.
vectorizer = CountVectorizer(stop_words = "english")
Если мы изменим этот параметр, то уменьшим количество слов в словаре. Для данного примера мы получили следующие слова и их соответствующую частотную матрицу.
>>>vectorizer.get_feature_names()
['document', 'second']
>>>X.toarray()
array([[1, 0],
[2, 1],
[0, 0],
[1, 0]])Применим этот способ к нашему датасету с отзывами о фильмах.
freq_vector = CountVectorizer(stop_words = "english")
X_train_freq = freq_vector.fit_transform(X_train)
X_train_freq.shape
>>>(1340, 33470)Данный способ возвращает матрицу с 1340 строками (отзывами) и 33470 признаками. Теперь посмотрим, как преобразовать эту матрицу вхождений слов в плавающую матрицу с более значимой информацией касательно отзывов о контенте. Для этого используем класс TfidfTransformer, который преобразует матрицу подсчета в нормализованное представление tf-idf.
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transf = TfidfTransformer()
X_train_tfidf = tfidf_transf.fit_transform(X_train_freq)
X_train_tfidf.shapeПостроение модели
Преобразование tf-id возвращает матрицу признаков, которую можно использовать для обучения модели классификатора. Создадим базовый классификатор и посмотрим на его работу. Будем использовать алгоритм Linear Support Vector: он способен обрабатывать разреженные признаки и большое количество выборок.
from sklearn.svm import LinearSVC
classifier = LinearSVC()
classifier.fit(X_train_tfidf,y_train)Вот и все. Процесс создания классификатора отзывов о фильмах завершен.
Разработка модели классификатора для оперирования текстовыми данными может быть довольно сложным процессом. К счастью, Scikit-learn оснащен классом Pipeline для составления нескольких шагов, которые можно проверить путем перекрестной проверки. Кроме того, мы можем использовать класс TfidVectorizer, непосредственно преобразующий набор документов в матрицу признаков tf-idf.
Итак, сожмем код для разработки текстового классификатора.
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
text_classifier = Pipeline([
('tfidvectorizer',TfidfVectorizer()),
('LinearSVC',LinearSVC())
])
text_classifier.fit(X_train,y_train)Этот способ дает более компактный результат, чем если бы мы выполняли каждый шаг по отдельности. Помните: для корректной работы модели нужно использовать исходные, то есть текстовые данные.
Эффективность модели
С помощью матрицы неточностей мы можем сразу увидеть информацию об эффективности модели. Воспользуемся тестовым набором данных, чтобы сделать прогноз и посмотреть, насколько хороша наша модель.
from sklearn.metrics import plot_confusion_matrix
# Построение ненормализованной матрицы неточностей
title = "Confusion matrix"
normalize = None
class_names = text_classifier.classes_
disp = plot_confusion_matrix(text_classifier, X_test, y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize=normalize)
disp.ax_.set_title(title)Приведенный выше код возвращает матрицу неточностей.
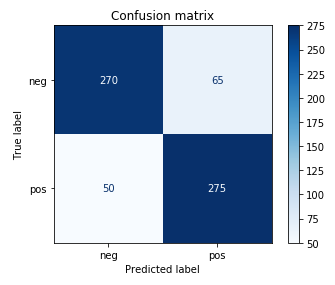
Уровень эффективности данной модели довольно высок. Она хорошо подходит в качестве базового инструмента классификации текста. Правда, она иногда принимает негативные отзывы за положительные. Но поведение довольно схоже для обеих меток. Общая ее точность такова:
>>>from sklearn.metrics import accuracy_score
>>>print(accuracy_score(y_test,predictions))
0.8257575757575758Вывод
В этой статье мы изучили основные аспекты задач обработки естественного языка (НЛП). В рамках этого небольшого проекта многие темы не были рассмотрены, но мы уже знаем, насколько мощным может быть инструмент Scikit-learn для разработки проектов НЛП. Код для этого проекта можно найти в репозитории на GitHub.
Читайте также:
- Как с помощью Python создавать математическую мультипликацию типа 3Blue1Brown
- Функциональное программирование на Python
- Как отслеживать события файловой системы в Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Manuel Gil: Movie Review Text Classification Using scikit-learn





