
Дизайнер должен досконально знать материалы, с которыми работает. В прошлом это было понимание особых свойств древесины, металлов, печатных станков и, наконец, пикселей. Современным дизайнерам цифровых систем приходится иметь дело с более эфемерной материей — алгоритмами.
Раньше правила, по которым работали приложения (например, для показа постов тех, на кого подписан пользователь) были относительно простыми. Теперь же в силу применения искусственного интеллекта они стали невероятно сложными рекурсивными процессами, которые порой выходят за грань человеческого понимания. Алгоритмы активно участвуют в нашей повседневной жизни, однако большая часть посвящённой этому литературы акцентирует внимание лишь на том, заменят ли эти роботы людей. Давайте лучше обсудим, как труд дизайнеров может дополнить инженерные достижения и модифицировать дизайн-решения для более качественной работы алгоритмов.
Уже недостаточно создавать дизайн, ориентированный целиком на пользователя — интерфейсы будущего должны быть такими, чтобы людям было удобно их использовать, а алгоритмам — анализировать.

Потребности алгоритмов
Алгоритмы отвечают за большую часть контента в цифровых продуктах, которыми мы пользуемся: популяризация постов в социальных сетях, разделы “С этим обычно покупают/Вам также может понравиться” в корзинах интернет-магазинов, фразовые рекомендации в электронной почте. Они показывают нам то, что мы хотим видеть, и когда мы этого хотим — словно услужливые помощники или консультанты в магазине. Самопровозглашённый “технолог-гуманист” Джон Маэда в своей новой книге “How To Speak Machine: Computational Thinking For The Rest Of Us” сравнивает цель алгоритмов с японской философией “омотэнаси” (“omotenashi”): догадаться, чего хочет клиент, не спрашивая его об этом.
Однако в одиночку алгоритмы работать не могут: успех обеспечен только при гармоничном сочетании алгоритмов и продуманных интерфейсов.
Цель и процесс
Большинство алгоритмов ориентировано на автоматическое обнаружение закономерностей в данных и создание на их основе релевантных рекомендаций. Это достигается сочетанием особого набора данных и параметров анализа — иными словами, с помощью модели. Со временем модель обучается на большем объёме данных, что приводит к теоретическим уточнениям. То, что получается на выходе, часто используется для персонализации продукта, индивидуализации пользовательского опыта.
“Более высокий уровень персонализации обычно означает рост релевантности для пользователей, что в свою очередь ведёт к повышению конверсии”.
Fabricio Teixeira, UX Collective
Это объясняет, почему данные — это новое золото. Однако ценностные предложения большинства компаний уникальны, а это значит, что вряд ли есть общедоступный качественный набор данных, который помог бы эффективно обучить модели этих компаний.
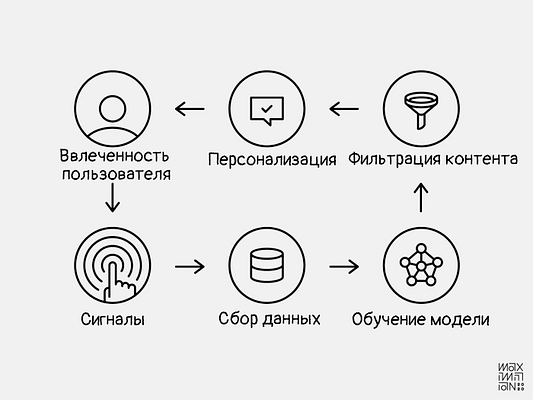
Цепи обратной связи и сигналы
Чтобы обучить новую модель компании должны уподобиться Уроборосу, превратив свой продукт в механизм сбора данных, который тут же использует эти данные для самосовершенствования. В этой цепи обратной связи значимые действия пользователя трактуются как сигналы: нажатия на кнопки, жесты и даже полное отсутствие действий.
“Если вы смотрите на какое-то изображение дольше, чем на остальные, это говорит о вашей заинтересованности. Если вы начали что-то печатать, но в итоге так и не заполнили поле до конца, это значит, что вы сомневаетесь”.
Джон Маэда
Хорошо спроектированное взаимодействие интуитивно понятно, но также позволяет отличать сигнал от шума.

Дизайн, удобный для алгоритмов
Термин “дизайн, удобный для алгоритмов” (“algorithm-friendly design”) был введён Юджином Фэем (для редактора — не уверена, что фамилия читается так)(Eugene Wei), бывшим руководителем продуктовой разработки в Amazon, Hulu и Oculus, чтобы описать интерфейсы, которые способствуют обучению модели:
“Если алгоритм станет одной из ключевых функций приложения, как разработать дизайн, который позволит алгоритму увидеть то, что тот должен видеть?”
Это объясняет наличие огромного количества взаимодействий, которые существуют исключительно для считывания настроя пользователя: к примеру, дизлайки на Reddit или смахивание карточек влево в Tinder — сами по себе эти функции бесполезны, но для алгоритма они представляют ценность.
Инновационный интерфейс TikTok
Согласно Закону Хуанга (Huang’s law), искусственный интеллект развивается огромными темпами, поэтому появляются более элегантные дизайнерские решения, которые меняют парадигму доступности интерфейса для алгоритмов. Легендарный алгоритм TikTok использует интерфейс приложения для быстрого сбора больших объёмов пользовательских данных, чтобы предложить крайне привлекательные рекомендации контента. Как ни странно, для этого используется один из “смертных грехов” дизайна: замедление взаимодействия.
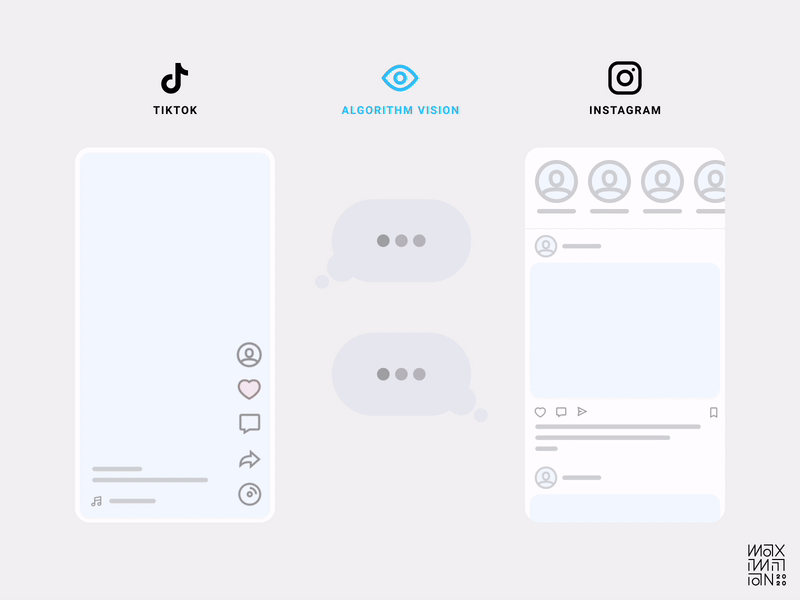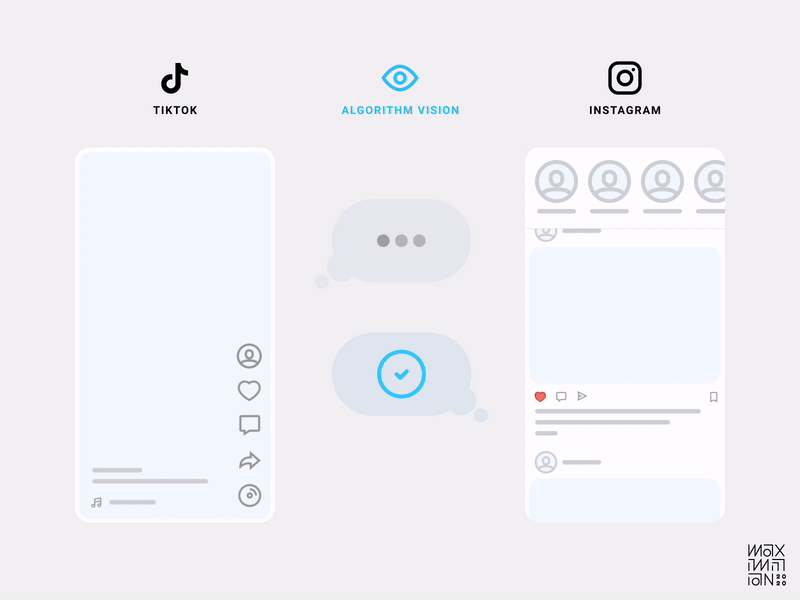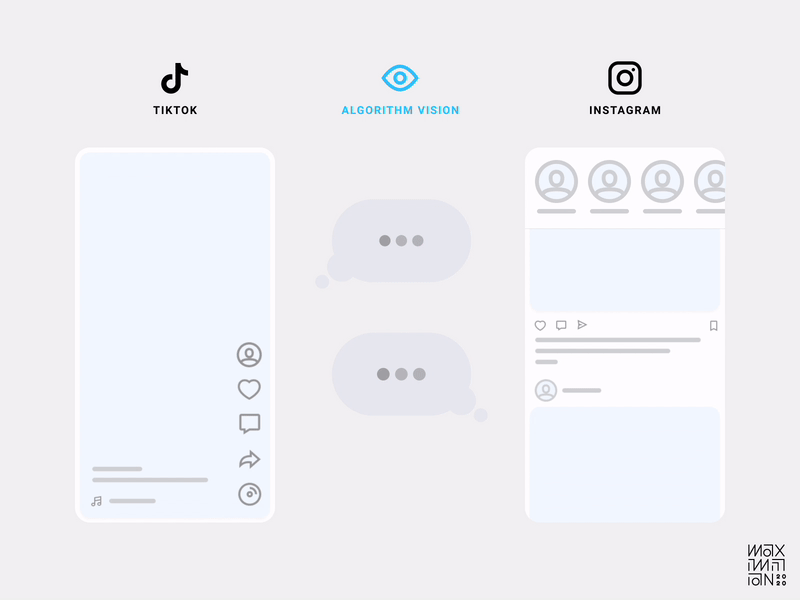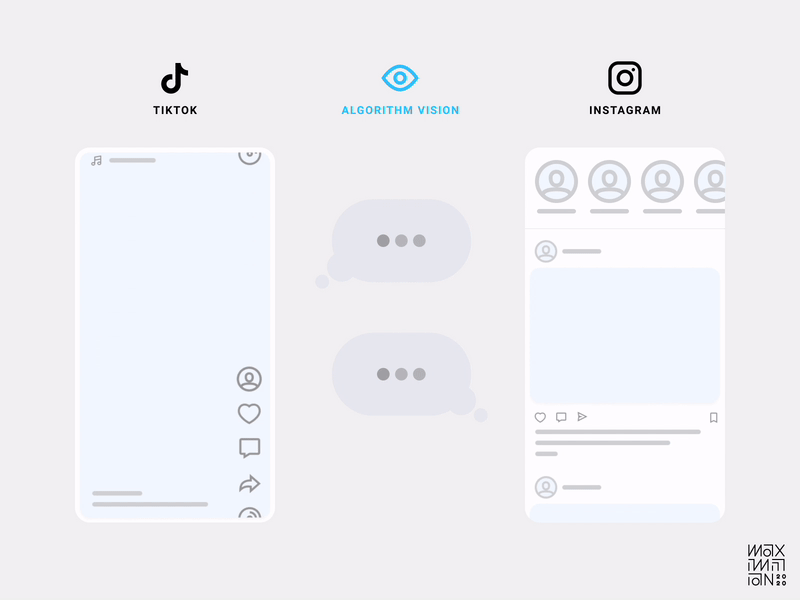
Показ на экране только одного видео в один момент времени явным образом локализует все сигналы, указывающие на восприятие контента. Теперь сравните это с обилием отвлекающих факторов в ленте Instagram, и станет проще увидеть разницу в способности приложений собирать качественные данные. Вот почему появился Instagram Reels.
В лентах большинства приложений можно смахивать контент с разной степенью интенсивности, что позволяет нам мгновенно пропускать гигантские объёмы контента, не объясняя алгоритму причины. Происходит такой анализ:
- Пролистали ли контент настолько быстро, что взаимодействие не успело зафиксироваться?
- Был ли предпросмотр доступен на экране лишь частично?
- Присутствовал ли сверху или снизу отвлекающий контент?
Замедление взаимодействия через прокрутку позволяет провести очень качественный анализ настроя пользователя. Подлинная красота такого решения — в наличии невидимой кнопки “дизлайк”: сочетание смахивания контента и отсутствия положительной вовлечённости можно с полным правом расценивать как отрицательный сигнал.
Замедление устраняет замедление
Несмотря на то что такое дизайн-решение изначально предполагает замедление взаимодействия, с течением времени это приводит к противоположному эффекту. Благодаря наращиванию объёма качественных данных создаётся высокая степень персонализации, что в итоге приводит к уменьшению числа повторяющихся действий. В свете сказанного традиционный подход к обработке данных выглядит неуклюже — Фэй (для редактора — тот же Eugene Wei, сомневаюсь в правильности прочтения фамилии) приводит в пример Twitter:
“Если бы алгоритм лучше понимал, что вам нравится, он бы сам позаботился о скрытии каких-то тем или блокировке пользователей, и вам не нужно было бы делать всё это самим”.
Грамотно оформленный онбординг в приложении минимизирует неудобство от замедления взаимодействия, чтобы пользователь с лёгкостью дошёл до нужной степени персонализации.

Эффект алгоритма-наблюдателя
С ростом популярности таких документальных фильмов, как “Социальная дилемма”, многие пользователи всё больше подозревают приложения в неправомерном использовании данных и манипулировании поведением. Пользователи ощущают на себе “взгляд” алгоритма, и это меняет их взаимодействие с приложением: некоторые не решаются нажимать на какие-то кнопки из страха, что их данные используют недолжным образом, другие совершают лишние действия, чтобы запутать излишне любопытный алгоритм.
Если пользователи не доверяют продукту, значит продукт не может доверять собранным данным.
Как представлять алгоритм пользователям?
Когда Клифф Куан, бывший руководитель отдела продуктовых инноваций в Fast Company, брал интервью у команды Microsoft по внедрению ИИ в PowerPoint, он выделил такую ключевую мысль:
“Если бы человек не ощущал никакой связи с машиной, то никогда не дал бы ей шанса исправиться, соверши она хотя бы одну ошибку”.
Эта идея зародилась из сравнения полностью автономных виртуальных ассистентов и ассистентов, которым перед генерацией собственных рекомендаций требовалось задать изначальное направление. Получается, что пользователи доверяют алгоритмам, которые сами помогают обучать. Это вполне резонно, поскольку наши оценки часто субъективны, а изначальные рекомендации алгоритма имеют мало общего с предпочтениями пользователя, чтобы от них отталкиваться.
Возможность принимать изначальные решения удовлетворяет эмоциональные потребности пользователей и даёт модели достаточное время для обучения.
Прозрачность как стратегия
В одном из выпусков подкаста a16z Фэй (для редактора — снова этот Фэй) особо выделил решение TikTok показать всем работу их алгоритма путём добавления счётчика просмотров для хэштегов и использования контент-челленджей. Это мотивирует создателей контента прикладывать дополнительные усилия так, как это нужно приложению, чтобы многократно увеличить количество просмотров. Когда-то такое поведение называли обманом алгоритма, однако стратегия работает, а значит и негативные коннотации должны исчезнуть. Если пользователи по своей воле заполняют пробелы в наборах данных, параллельно достигая своих целей, такое следует называть, скорее, сотрудничеством.
Создатель Twitter уже размышляет над внедрением чего-то подобного:
“Дать пользователям возможность выбирать созданные третьими сторонами алгоритмы, чтобы ранжировать и фильтровать контент, — великолепная идея, за которой стоит лишь протянуть руку”.
Джек Дорси
Если непрозрачные алгоритмы лишь создают информационный пузырь (как на Blue Feed, Red Feed), то, с прозрачными он, вероятно, лопнет.
Заключение: алгоритму всё ещё нужен человек
Главный специалист Spotify по исследованию и совершенствованию продукта Густав Сёдерстрём в интервью с Лексом Фридманом говорил об установлении ожиданий пользователей в отношении музыкальных рекомендаций. Когда люди расположены к открытию нового (не против сомнительных рекомендаций), Spotify работает по принципам машинного обучения. И, напротив, в ситуации, когда ошибки нежелательны, сервис всё ещё полагается на самих пользователей, поскольку проигрывает им.
“По сравнению с нашими алгоритмами человек невероятно умён. Алгоритмы способны воспринимать культурные и другие особенности, однако они не могут принимать 200 миллионов решений в час для всех, кто заходит в приложение”.
Чтобы сделать работу алгоритмов эффективнее, в Spotify придумали симбиоз под названием “algotorial”, предполагающий, что алгоритм следует указаниям пользователя — знакомая идея, не так ли? Это хорошее напоминание о незаменимости человека, а мы, дизайнеры, понимаем, что способствовать успеху алгоритма — теперь часть нашей работы. По крайней мере, до тех пор, пока они у нас её не отберут 😉
Читайте также:
- Уникальный пример использования SocketCluster для распределенных вычислений
- Простыми словами о рекурсии
- 4 принципа успешной поисковой системы и не только
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Maximillian Piras: “Designing algorithm-friendly interfaces”





