
Поиск повсюду и сталкиваемся мы с ним ежедневно. Эта функция реализована на каждом сайте и является частью любого IT-продукта. Вызов меню поиска простой комбинацией клавиш можно назвать современным чудом, которое работает независимо от того, покупаете вы нижнее белье, выбираете на Netflix интересный фильм или даже ведете передовую исследовательскую команду.
Но раз поиск настолько вездесущ, почему же во многих случаях он так плохо работает? Нередко эта функция реализуется в виде второсортного компонента или даже просто бонуса. Его просто встраивают, ожидая, что он так и заработает. Но для проектирования грамотного и удобного функционала поиска требуется время, анализ и множество усилий.
Вступление
Обсуждать концепции без фактического примера — непростая задача. Поэтому в текущей статье мы будем опираться на образец из почти 10 000 книг, взятых с сайта Goodreads. Сам этот набор данных и скрипты для его загрузки в Elasticsearch можно взять здесь.
Принцип 1. Поисковые движки тупы
Нередко поисковый движок реализуется просто как еще одна база данных. Они во многом выглядят и ведут себя похоже, но если копнуть поглубже, то обнаружится множество запутанных алгоритмов и высокооптимизированных структур данных, существенно отличающихся от стандартного хранилища.
Для создания инструмента поиска нам нужно разобрать и уяснить ряд понятий:
- анализ (разбивка части текста на фрагменты);
- обратный индекс (сверхбыстрое сопоставление токенов с документами, где они встречаются);
- алгоритм ранжирования (определение и упорядочивание информации на основе ее релевантности запросу).
Анализ
При передаче документов поисковому движку они разделяются на много мелких частей. Эти части или, как мы их будем дальше называть, токены выступают основной валютой системы поиска.

Способ генерации токенов мы контролируем через определение схемы индекса. Этот рычаг определяет дальнейшее поведение движка, поэтому его настройка является важным аспектом. Для этого у нас есть большой диапазон выбора, включающий такие преобразования, как размер токена (N-грамма), удаление проблемных стоп-слов (“и”, “это” “т.д.”), а также стемминг (сопоставление основ слов). Вскоре мы рассмотрим примеры.
Индекс
Возьмем любое научно-популярное произведение и откроем последние страницы. Здесь расположена структура данных, сопоставляющая ключевые выражения предметной области книги с отрывками, где они чаще всего встречаются.
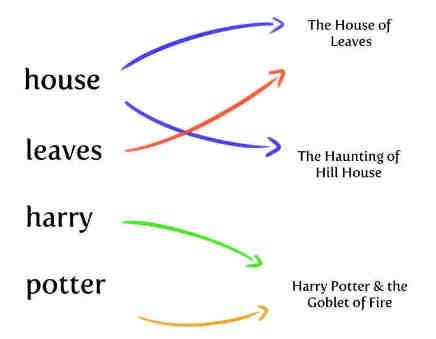
Обратный индекс в поисковом движке действует очень схоже. На примитивном уровне он сопоставляет представленные в документе токены с документами, в которых они встречаются.
Ранжирование
Когда вы что-либо ищете, движок сопоставляет ваш токенизированный запрос с индексом и оценивает каждый результат на основе алгоритма ранжирования. Обычно для этого используются такие алгоритмы, как TF-IDF (обратная частота документа).
Всем записям присваиваются баллы соответствия, на основе которых в процессе сопоставления выбирается победитель, а именно ваши результаты поиска.
Так поисковые движки все же умны?
Не совсем. Несмотря на всю внутреннюю инженерию, которую можно назвать мечтой специалиста по информатике, эти движки не способны размышлять сами. Если сгенерированные из запроса токены не подойдут в точности ни одному индексу, то вам не повезло. К примеру, если ваш индекс — это horses, а анализатор запроса генерирует horse — дела плохи. Какие вводные, такой и результат, следить должны вы.
Не стоит слепо добавлять кучу данных в поисковый движок. Именно вам нужно преобразовывать входящие объемы текста в полезные данные.
Принцип 2. В деле не только токены, но и признаки
Сгенерированные из документа токены не просто являются элементами индекса. Они представляют его ключевые идеи.
Что вообще такое признак? Возьмем в качестве примера классический заголовок Dracula из нашего датасета.
{
"title": "Dracula",
"genres": [
"classics",
"horror",
"fiction",
"gothic",
"paranormal",
"vampire"
],
"year": 1897,
"isbn": "393970124",
"description": "A Chronology and a Selected Bibliography are included.",
"publisher": "Norton",
"average_rating": 3.98,
"ratings_count": 618973,
"authors": [
"Bram Stoker"
]
}Здесь мы видим всего несколько относящихся к роману признаков — это готическая классика, изданная в 1897 году, написанная Брэмом Нортоном и имеющая средний рейтинг 3.98/5.
Исходный материал обычно содержит множество признаков, которые только и ждут, чтобы их выбрали. Но зачастую большинство самых ценных нужно добывать из глубины. Для этого требуется моделировать признаки, которые помогут передать идеи вашего документа. Эта техника называется извлечением признаков. Вот здесь вы можете поиграть в безумного ученого, рассекающего текст вплоть до его голой сути, отбрасывая все двусмысленности и путаницу.
Инженерия признаков выполняется при анализе во время индексации. В поисковом движке есть ряд инструментов, помогающих повысить эффективность этого процесса. Давайте рассмотрим парочку из них.
N-граммы
По умолчанию техника токенизации любого поискового движка обычно подразумевает (а) удаление всей пунктуации и специальных символов, после чего идет (б) разделение по пробелам. Все это может неплохо работать в качестве начальной тактики, потому что поиск конкретного слова будет выдавать успешное совпадение. Однако для длинных слов, которые мы и выговариваем то с трудом, такой подход уже не будет столь эффективен.
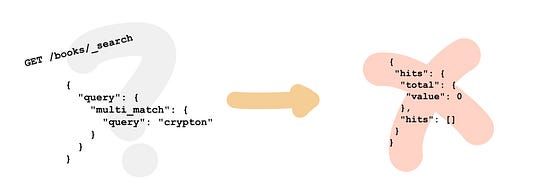
Представьте себе поиск книги Cryptonomicon. Половина ваших пользователей просто введут “Crypton” и нажмут ввод. При использовании стандартного анализатора далеко такой поиск не зайдет. Помните, что поисковые движки тупы, и предустановленная в них техника просто произведет один токен Cryptonomicon, который, естественно, не совпадет с поисковым запросом.
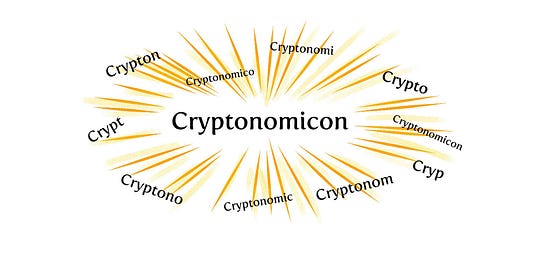
N-граммы и, в частности, N-граммы границ отлично подходят для ситуаций, в которых требуется частичное сопоставление. Взгляните, как много токенов было сгенерировано для Cryptonomicon с помощью N-грамм.
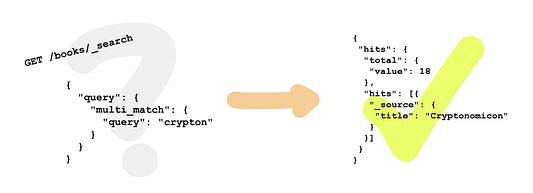
При использовании этой стратегии мы получаем искомое совпадение, поскольку запрос crypto содержится в сгенерированных токенах.
Стемминг
Стемминг подразумевает извлечение основы слова. У многих выражений есть общий корень, например в словах программирование, программировать, запрограммированный.
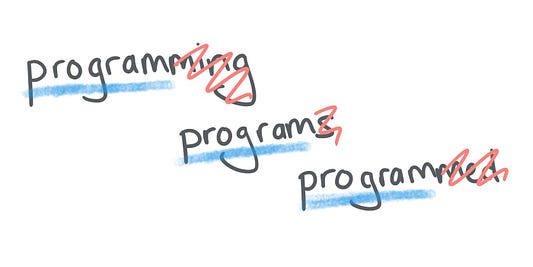
Уменьшая слово до его основы, вы приближаетесь к его ключевому значению. С помощью этого подхода можно на основе предполагаемых мыслей пользователей добиться успешных поисковых результатов, позволив им доносить свои идеи, не беспокоясь о синтаксисе.
Более подробное описание принципа стемминга доступно в следующем разделе документации к Elasticsearch (англ.).
Принцип 3. Настройка на сигналы
Извлечение признаков — это первооснова построения грамотного поискового движка, но при ее реализации всегда необходимо учитывать конечного пользователя. Каков контекст использования поиска? Какие элементы пользователи скорее всего будут искать? Какие свойства максимально помогут определить или предположить это? Как можно изменить признаки для получения максимального эффекта?
Мы должны понимать пользователей и стараться предугадывать их намерения. Один из вариантов, который нам в этом поможет — это сила сигнала.
Сигналы
При выполнении поискового запроса ищущий заинтересован найти документы, наиболее соответствующие его замыслу. Такой пользователь дает нам несколько ключей, позволяющих ему помочь: автор, жанр, название, год издания и т.д. Документы, максимально соответствующие этим критериям, отвечают с более сильным сигналом (что измеряется баллами релевантности).

Некоторые сигналы сильнее, некоторые слабее, а некоторые могут даже играть против вас. В то время как один признак может вызывать четкое совпадение, другие иногда генерируют шум, вызывая ложные положительные срабатывания, что ухудшает результаты поиска в целом. Хорошая новость в том, что у нас есть инструменты для усиления отчетливых сигналов и ослабления тех, которые хоть иногда и могут быть полезны, но чаще только мешаются.
Бустинг
Как правило, ценность обнаружения одного свойства (например, названия) оказывается выше ценности других (например, описания). При этом можно запрограммировать поисковый движок с учетом этих наших предпочтений.
Повышая значимость одного поля над другим, мы повышаем его важность при ранжировании найденных соответствий. Свойства, которые отвечают критериям запроса, будут проявляться более отчетливо, а ложные положительные варианты наоборот будут свою значимость утрачивать. Для применения бустинга к определенному полю достаточно просто повысить его значение по отношению к остальным.
Предположим, нас интересует классическое произведение Чарльза Диккенса, и мы передаем алгоритму поиска выражение dickens.

Результаты весьма смешаны. Некоторые, без сомнения, относятся к книгам Чарльза Диккенса, но с лидирующих позиций их вытеснили смежные варианты. Пользователи могут удивиться, что Моби Дик оказался в этой ситуации победителем соответствий. Такую выдачу можно исправить, просто выровняв значимость поля playing и повысив значение поля authors.

Имена нередко выступают в качестве более точных соответствий, чем название или описание — особенно если имя полное. Но это мы рассмотрим чуть позже. Усиливая поле authors, мы выделяем соответствующие записи как более релевантные нашему запросу.
Однако при этом нужно быть осторожным. Процесс взвешивания и балансирования полей достаточно утончен. Стоит немного перестараться, и в итоге вы исправите одну проблему (например, поиск по названию), но создадите другую (например, возможность поиска по издателю).
Сложность сопоставления и бустинг
Для выравнивания этой проблемы можно, например, соотнести размер веса со сложностью получения выигрышного совпадения для поля.
К дающим нам отчетливый сигнал свойствам относятся:
- ID;
- Full name;
- ISBN.
Ищите по одному из них, и вы получите наилучшее соответствие. Если же делать сопоставление с полем description (описание), то вы никогда не сможете быть уверены на 100%, потому что в выдаче будет присутствовать широкий спектр контента.
Надежнее всего будет задействовать признак, который практически идентичен двоичному сигналу, т.е. либо совпадает, либо нет.
Одинаковый текст, разный анализ
Возьмем имя автора. В нем вы можете увидеть не менее двух сигналов:
- Частичное совпадение, например фамилия: King.
- Полное совпадение, например полное имя: Stephen King.
Последний сигнал, очевидно, более значим, чем первый. Нам гораздо проще помочь пользователю, если он ищет автора по его полному имени. Тем не менее это не значит, что частичное совпадение не имеет ценности, ведь по воле случая вы можете и не знать точного написания полного имени автора.
Как же нам обработать оба случая, когда у нас есть только одно поле имени? В этой ситуации с помощью моделирования признаков мы разделяем его на два поля. Каждый признак можно настроить независимо, установив баланс, в котором приоритет будет отдаваться более широкому совпадению, но при этом в подходящих случаях задействовать и менее значимый признак частичного совпадения.
Мульти-сопоставление
Поиск не всегда включает только один признак. Зачастую в поисковый запрос включается множество разных ключей. Вы можете искать не только автора, но и конкретный его текст, например “Christmas novels by Charles Dickens”.

При использовании подхода “полей с максимальным соответствием” Elasticsearch выберет из всей кучи наилучшее совпадение: сигнал с максимальной отдачей. Если же рассматривать предложенный выше запрос, включающий несколько признаков, то такой подход может привести к путанице. Нам нужно произвести сопоставление в первую очередь с самым сильным сигналом Christmas, а затем задействовать и второе поле, чтобы выделить его значимость.
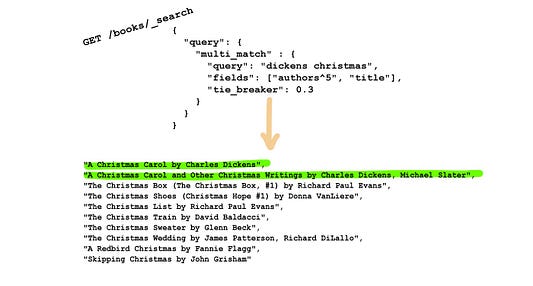
Если установить в качестве прерывателя значение между 0 и 1, поисковый движок продолжит делать сопоставления с максимально подходящими полями, но затем будет выполнять дополнительный шаг, используя другие сигналы для дальнейшего уточнения результатов. В нашем примере Christmas может быть первичной целью, после чего Dickens внесет дополнительный вес, достаточный для вывода соответствующих романов на первое место.
Принцип 4. Обратная связь
Поисковая система — это не однонаправленный механизм. Ее функционирование заключается не только в обработке запросов и слепом обслуживании пользователей. Очень важно поддерживать с этими пользователями обратную связь.
Автоподстановка
Нередко бывает, что пользователи не до конца понимают, что именно ищут. Они просто вводят примерное представление запроса и смотрят, какой будет выдача. Если в этой ситуации им не помочь, то такой запрос может оказаться выстрелом в пустоту. Человек будет пробовать раз за разом, не получая годных результатов, и в итоге либо выберет что-то хоть приблизительно подходящее, либо просто откажется от своей затеи.
Если же вы предложите опцию автоподстановки, то таким образом дадите моментальную обратную связь о доступных вариантах, к тому же пользователю уже не придется додумывать правильное написание.
Автоподстановка по умолчанию поддерживается если не всеми, то большинством поисковых движков. В Elasticsearch это просто еще одно (хоть и особое) поле, в которое вы можете скопировать названия книг, имена авторов, жанры и тому подобное.

Выделение
Случалось ли вам, при поиске чего-нибудь задаваться вопросом “Откуда берутся такие результаты?”. Если ваши документы содержат обширный объем данных, то иногда становится сложно разобраться в результате выдачи.
Предоставляя подсказки путем выделения в общем тексте успешно сопоставленных выражений, вы можете оказать неоценимую помощь пользователям, позволив им конкретизировать запрос или исключить ненужные результаты.
Подробнее о выделении в документации Elasticsearch (англ.).
Мониторинг и повторение
“Что измерено, тем можно управлять”, — Питер Драккер.
Для создания поистине полезного поискового опыта необходимо анализировать поведение пользователей. Опыт в конкретной области непременно важен, но фактический анализ запросов пользователей может раскрыть наиболее ценные моменты.
Блуждание? Продолжительное повторение поиска, без выбора какого-либо конечного результата. Почему это происходит? Какие выражения пользователь ищет?
Нет результатов? Многие ли пользователи ищут что-то безуспешно? Может в таком случае плохо настроен движок или требуется другая доработка?
Успешна ли выдача? Закончилась ли сессия успешно? Было ли что-то куплено, просмотрено, прочитано?
Собирайте и анализируйте информацию, чтобы непрерывно совершенствовать свое решение.
Заключение
Мы затронули немало разных аспектов, которые необходимо учитывать при организации поисковой системы. При этом углубляться мы не стали, так что рекомендую ознакомиться с соответствующими ресурсами и руководствами для получения более детальной информации.
Поиск — это самостоятельная область, которая разветвляется на разные передовые направления, включая систему рекомендаций и машинное обучение. Как и в большинстве инженерных проектов к успешной реализации здесь стоит двигаться небольшими шагами. Постарайтесь начать с простого, собрать обратную связь, внести доработки и развивать систему по мере необходимости.
Читайте также:
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Matthew Lucas: “Finding Stuff” — Building a Great Search Experience





