
Импорт в Python. Основы
В Python ключевое слово import применяется для того, чтобы сделать код в одном модуле доступным для работы в другом. Импорт в Python важен для эффективного структурирования кода. Правильное применение импорта сделает вас более продуктивным: вы сможете повторно использовать код и при этом продолжать осуществлять поддержку своих проектов.
В статье представлен подробный обзор инструкции import в Python и того, как она работает. Здесь мощная система импорта. Вам предстоит узнать, как эту мощь задействовать, а также изучить ряд понятий, лежащих в основе системы импорта в Python. Их изложение в статье построено главным образом на примерах (в помощь вам будут несколько примеров кода).
В этой статье вы узнаете, как:
- Работать с модулями, пакетами и пакетами пространств имён;
- Импортировать ресурсы и файлы данных внутри ваших пакетов;
- динамически импортировать модули во время выполнения;
- настраивать систему импорта в Python.
На протяжении всей статьи даются примеры: вы сможете поэкспериментировать с тем, как организован импорт в Python, чтобы работать наиболее эффективно. Хотя в статье показан весь код, имеется также возможность скачать его по ссылке ниже:
Получить исходный код: Нажмите здесь и получите исходный код, в этой статье для изучения системы импорта в Python.
Базовый импорт Python
Код в Python организован в виде модулей и пакетов. В этой части статьи мы объясним, чем они отличаются друг от друга и как с ними можно работать.
А чуть дальше вы узнаете о нескольких продвинутых и менее известных примерах применения системы импорта в Python. Но начнём с основ — импортирования модулей и пакетов.
Модули
В Python.org glossary даётся следующее определение модуля:
Объект, который служит организационной единицей кода в Python.Модули имеют пространство имён, в котором содержатся произвольные объекты Python.Модули загружаются в Python посредством импортирования. (Источник)
На практике модуль соответствует, как правило, одному файлу с расширением .py. В этом файле содержится код на Python.
Модули обладают сверхспособностью импортироваться и повторно использоваться в другом коде. Рассмотрим следующий пример:
import math
math.piВ первой строке import math вы импортируете код в модуль math и делаете его доступным для использования. Во второй строке вы получаете доступ к переменной в модуле math. Модуль math является частью стандартной библиотеки Python, поэтому он всегда доступен для импорта, когда вы работаете с Python.
Обратите внимание, что пишется не просто pi, а math.pi. math — это не только модуль, а ещё и пространство имён, в котором содержатся все атрибуты этого модуля. Пространства имён важны для читаемости и структурированности кода. Как сказал Тим Петерс:
Пространства имён — это отличная идея. Их должно быть больше! (Источник.)
Содержимое пространства имён можно посмотреть с помощью dir():
>>> import math
>>> dir()
['__annotations__', '__builtins__', ..., 'math']
>>> dir(math)
['__doc__', ..., 'nan', 'pi', 'pow', ...]Если не указывать при этом никаких аргументов, т.е. просто dir(), то можно увидеть, что находится в глобальном пространстве имён. Посмотреть содержимое пространства имён math можно, указав его в качестве аргумента вот так: dir(math).
Вы уже видели самый простой способ импортирования. Есть и другие, которые позволяют импортировать отдельные части модуля и переименовывать его в процессе импортирования.
Вот код, который импортирует из модуля math только переменную pi:
>>> from math import pi>>> pi3.
141592653589793
>>> math.piNameError: name 'math' is not definedОбратите внимание, что pi помещается в глобальное пространство имён, а не в пространство имён math.
А вот как в процессе импортирования переименовываются модули и атрибуты:
>>> import math as m>>> m.pi
3.141592653589793
>>> from math import pi as PI
>>> PI
3.141592653589793Пакеты
Пакет представляет собой следующий после модуля уровень в организационной иерархии кода. В Python.org glossary даётся следующее определение пакета:
Это модуль Python, который может содержать подмодули или (рекурсивно) подпакеты.Строго говоря, пакет — это модуль Python с атрибутом__path__. (Источник.)
То есть пакет — это тоже модуль. Пользователю обычно не приходится задумываться о том, что у него импортируется: модуль или пакет.
На практике пакет — это, как правило, каталог файлов, внутри которого находятся файлы Python и другие каталоги. Как создать пакет Python самостоятельно? Создаёте каталог, а внутри него — файл с именем __init__.py. В __init__.py файле находится содержимое этого пакета-модуля. И он может быть пустым.
Обратите внимание: каталоги без файла __init__.py Python всё равно считает пакетами. Но это уже будут не обычные пакеты, а то, что можно назвать пакетами пространства имён. Подробнее о них чуть дальше в статье.
Вообще подмодули и подпакеты нельзя импортировать вместе с пакетом. Это можно сделать с помощью __init__.py, включив любой или все подмодули и подпакеты, если захотите. В качестве примера создадим пакет для Hello world на разных языках. Пакет будет состоять из следующих каталогов и файлов:
world/
│
├── africa/
│ ├── __init__.py
│ └── zimbabwe.py
│
├── europe/
│ ├── __init__.py
│ ├── greece.py
│ ├── norway.py
│ └── spain.py
│
└── __init__.pyДля файла каждой страны выводится соответствующее приветствие, а файлы __init__.py выборочно импортируют некоторые подпакеты и подмодули. Вот точное содержимое этих файлов:
# world/africa/__init__.py (пустой файл)
# world/africa/zimbabwe.pyprint("Shona: Mhoroyi vhanu vese")print("Ndebele: Sabona mhlaba")
# world/europe/__init__.pyfrom . import greecefrom . import norway
# world/europe/greece.pyprint("Greek: Γειά σας Κόσμε")
# world/europe/norway.pyprint("Norwegian: Hei verden")
# world/europe/spain.pyprint("Castellano: Hola mundo")
# world/__init__.pyfrom . import africa
# world/africa/__init__.py (пустой файл)
Обратите внимание: world/__init__.py импортирует только africa, а не europe; world/africa/__init__.py ничего не импортирует; world/europe/__init__.py импортирует greece и norway, а не spain. Модуль каждой страны при импортировании выводит приветствие.
Разберёмся, как ведут себя подпакеты и подмодули в пакете world:
>>> import world>>> world<module 'world' from 'world/__init__.py'>
>>> # Подпакет africa автоматически импортирован
>>> world.africa
<module 'world.africa' from 'world/africa/__init__.py'>
>>> # Подпакет europe не импортирован
>>> world.europe
AttributeError: module 'world' has no attribute 'europe'При импортировании europe модули europe.greece и europe.norway тоже импортируются. Это происходит потому, что модули этих стран выводят приветствие при импортировании:
>>> # Импортирование europe явным образом
>>> from world import europe
Greek: Γειά σας Κόσμε
Norwegian: Hei verden
>>> # Подмодуль greece автоматически импортирован
>>> europe.greece
<module 'world.europe.greece' from 'world/europe/greece.py'>
>>> # world импортируется, поэтому europe также находится в пространстве имён world
>>> world.europe.norway
<module 'world.europe.norway' from 'world/europe/norway.py'>
>>> # Подмодуль spain не импортирован
>>> europe.spain
AttributeError: module 'world.europe' has no attribute 'spain'
>>> # Импортирование spain непосредственно внутри пространства имён world
>>> import world.europe.spain
Castellano: Hola mundo
>>> # Обратите внимание: spain также доступен непосредственно внутри пространства имён europe
>>> europe.spain
<module 'world.europe.spain' from 'world/europe/spain.py'>
>>> # Импортирование norway не выполняет повторного импорта (не выводит приветствие), но добавляет
>>> # norway в глобальное пространство имён
>>> from world.europe import norway
>>> norway
<module 'world.europe.norway' from 'world/europe/norway.py'>
Файл world/africa/__init__.py пуст. Это означает, что импортирование пакета world.africa создаёт пространство имён, но этим и ограничивается:
>>> # Да, africa импортирована, но zimbabwe — нет
>>> world.africa.zimbabwe
AttributeError: module 'world.africa' has no attribute 'zimbabwe'
>>> # Импортирование zimbabwe непосредственно в глобальное пространство имён
>>> from world.africa import zimbabwe
Shona: Mhoroyi vhanu vese
Ndebele: Sabona mhlaba
>>> # Подмодуль zimbabwe теперь доступен
>>> zimbabwe
<module 'world.africa.zimbabwe' from 'world/africa/zimbabwe.py'>
>>> # Обратите внимание: до zimbabwe можно добраться и через подпакет africa
>>> world.africa.zimbabwe
<module 'world.africa.zimbabwe' from 'world/africa/zimbabwe.py'>Не забывайте: при импорте модуля загружается его содержимое и одновременно создаётся пространство имён с этим содержимым. Последние несколько примеров показывают, что один и тот же модуль может быть частью разных пространств имён.
Технические нюансы: пространство имён модуля реализовано в виде словаря Python и доступно в атрибуте .__dict__:
>>> import math>>> math.__dict__["pi"]3.141592653589793Но вам не придётся часто взаимодействовать с .__dict__ напрямую.
Глобальное пространство имён в Python тоже является словарём. Доступ к нему можно получить через globals().
Импортировать подпакеты и подмодули в файле __init__.py — это обычное дело. Так они становятся более доступными для пользователей. Вот вам пример того, как это происходит в популярном пакете запросов.
Абсолютный и относительный импорт
Напомним исходный код world/__init__.py предыдущего примера:
from . import africaЧуть ранее мы уже разбирали операторы типа from...import, такие как from math import pi. Что же означает точка (.) в from . import africa?
Точка указывает на текущий пакет, а сам оператор — это пример относительного импорта. Можно прочитать этот
from . import africaтак: «из текущего пакета импортируется подпакет africa».
Существует эквивалентный ему оператор абсолютного импорта, в котором прямо указывается название этого текущего пакета:
from world import africaНа самом деле, все импорты в world можно было бы сделать в виде таких вот абсолютных импортов с указанием названия текущего пакета.
Относительные импорты должны иметь такую (from...import) форму, причём обозначение места, откуда вы импортируете, должно начинаться с точки.
В руководстве по стилю PEP 8 рекомендуется в основном абсолютный импорт. Однако относительный импорт (в качестве альтернативы абсолютному) тоже имеет право на существование при организации иерархии пакетов.
Путь импорта в Python
А как Python находит модули и пакеты, которые импортирует? Более подробно о специфике системы импорта в Python расскажем чуть дальше в статье. А пока нам достаточно просто знать, что Python ищет модули и пакеты в своём пути импорта. Это такой список адресов, по которым выполняется поиск модулей для импорта.
Примечание: когда вы вводите import чего-то (что надо импортировать), Python будет искать это что-то в нескольких разных местах, прежде чем переходить к поиску пути импорта.
Так, он заглянет в кэш модулей и проверит, не было ли это что-то уже импортировано, а также проведёт поиск среди встроенных модулей.
Подробнее о том, как организован импорт в Python, расскажем чуть дальше в статье.
Путь импорта в Python можно просмотреть, выведя на экран sys.path. В этом списке будет три различных типа адресов:
- Каталог текущего скрипта или текущий каталог, если скрипта нет (например, когда Python работает в интерактивном режиме).
- Содержимое переменной окружения
PYTHONPATH. - Другие каталоги, зависящие от конкретной системы.
Поиск Python, как правило, стартует в начале списка адресов и проходит по всем адресам до первого совпадения с искомым модулем. Каталог скрипта или текущий каталог всегда идёт первым в этом списке. Поэтому можно организовать каталоги так, чтобы скрипты находили ваши самодельные модули и пакеты. При этом надо внимательно следить за тем, из какого каталога вы запускаете Python.
Стоит следить и за тем, чтобы не создавались модули, которые затеняют или скрывают другие важные модули. В качестве примера предположим, что вы определяете следующий модуль math:
# math.py
def double(number): return 2 * number
Всё пока идёт как надо:
>>> import math>>> math.double(3.14)6.28Вот только модуль этот затеняет модуль math, который входит в состав стандартной библиотеки. Это приводит к тому, что наш предыдущий пример поиска значения π больше не работает:
>>> import math>>> math.piTraceback (most recent call last): File "<stdin>", line 1, in <module>AttributeError: module 'math' has no attribute 'pi'
>>> math<module 'math' from 'math.py'>Вместо того, чтобы искать модуль math в стандартной библиотеке, Python теперь ищет ваш новый модуль math для pi.
Во избежание подобных проблем надо быть осторожным с названиями модулей и пакетов. Имена модулей и пакетов верхнего уровня должны быть уникальными. Если math определяется как подмодуль внутри пакета, то он не будет затенять встроенный модуль.
Структурируем импорт
Несмотря на то, что мы можем организовать импорт, используя текущий каталог, переменную окружения PYTHONPATH и даже sys.path, этот процесс часто оказывается неконтролируемым и подверженным ошибкам. Типичный пример даёт нам следующее приложение:
structure/
│
├── files.py
└── structure.pyПриложение воссоздаст данную файловую структуру с каталогами и пустыми файлами. Файл structure.py содержит основной скрипт, а files.py — это библиотечный модуль с функциями для работы с файлами. Вот что выводит приложение, запускаемое в данном случае в каталоге structure:
$ python structure.py .
Create file: /home/gahjelle/structure/001/structure.py
Create file: /home/gahjelle/structure/001/files.py
Create file: /home/gahjelle/structure/001/__pycache__/files.cpython-38.pycДва файла исходного кода плюс автоматически созданный файл .pyc повторно создаются внутри нового каталога с именем 001.
Обратимся теперь к исходному коду. Основная функциональность приложения определяется в structure.py:
# structure/structure.py
# Импорты стандартной библиотеки
import pathlib
import sys
# Локальные импорты
import files
def main():
# Считывание пути из командной строки
try:
root = pathlib.Path(sys.argv[1]).resolve()
except IndexError:
print("Need one argument: the root of the original file tree")
raise SystemExit()
# Воссоздание файловой структуры
new_root = files.unique_path(pathlib.Path.cwd(), "{:03d}")
for path in root.rglob("*"):
if path.is_file() and new_root not in path.parents:
rel_path = path.relative_to(root)
files.add_empty_file(new_root / rel_path)
if __name__ == "__main__": main()В строках с 12 по 16 читается корневой путь из командной строки. Точкой здесь обозначается текущий каталог. Этот путь — root файловой иерархии, которую вы воссоздадите.
Вся работа происходит в строках с 19 по 23. Сначала создаётся уникальный путь new_root, который будет корневым каталогом новой файловой иерархии. Затем в цикле проходятся все пути ниже исходного root, и они воссоздаются в виде пустых файлов внутри новой файловой иерархии.
В строке 26 вызывается main(). О проверке условия if в строке 25 подробнее узнаем дальше в статье. А пока нам достаточно знать, что специальная переменная __name__ внутри скриптов имеет значение __main__, а внутри импортируемых модулей получает имя модуля.
Обратите внимание: в строке 8 импортируютсяфайлы. В этом библиотечном модуле содержатся две служебные функции:
# structure/files.py
def unique_path(directory, name_pattern):
"""Найти имя пути, которого уже не существует"""
counter = 0
while True:
counter += 1
path = directory / name_pattern.format(counter)
if not path.exists():
return path
def add_empty_file(path):
"""Создать пустой файл в заданном пути"""
print(f"Create file: {path}")
path.parent.mkdir(parents=True, exist_ok=True)
path.touch()unique_path() работает со счётчиком для обнаружения пути, которого уже не существует. В приложении он нужен, чтобы найти уникальный подкаталог, который будет использоваться в качестве new_root вновь созданной файловой иерархии. add_empty_file() обеспечивает создание всех необходимых каталогов до того, как с помощью .touch() будет создан пустой файл.
Ещё раз взглянем на импорт файлов:
# Локальные импорты
import filesВыглядит он совершенно невинно. Однако по мере роста проекта эта строка станет источником некоторых проблем. Даже если импорт файлов происходит из проекта structure, этот импорт абсолютный: он не начинается с точки. А это означает, что файлы должны быть найдены в пути импорта, чтобы импорт состоялся.
К счастью, каталог с текущим скриптом всегда находится в пути импорта Python. Так что, пока проект не набрал обороты, импорт работает нормально. Но дальше возможны варианты.
Например, кто-то захочет импортировать скрипт в Jupyter Notebook и запускать его оттуда. Или иметь доступ к библиотеке файлов в другом проекте. Могут даже с помощью PyInstaller создавать исполняемые файлы, чтобы упростить их дальнейшее распространение. К сожалению, любой из этих сценариев может вызвать проблемы с импортом файлов.
Каким образом? Вот вам пример. Возьмём руководство по PyInstaller и создадим точку входа в приложение. Добавим дополнительный каталог за пределами каталога приложения:
structure/
│
├── structure/
│ ├── files.py
│ └── structure.py
│
└── cli.pyВ этом внешнем каталоге создадим скрипт точки входа cli.py:
# cli.py
from structure.structure import main
if __name__ == "__main__":
main()Этот скрипт импортирует из исходного скрипта main() и запускает его. Обратите внимание: когда импортируется structure, main() не запускается из-за проверки условия if в строке 25 внутри structure.py. То есть нужно запускать main() явным образом.
По идее, это должно быть аналогично прямому запуску приложения:
$ python cli.py structure
Traceback (most recent call last):
File "cli.py", line 1, in <module>
from structure.structure import main
File "/home/gahjelle/structure/structure/structure.py", line 8, in <module>
import files
ModuleNotFoundError: No module named 'files'Почему же запуск не удался? При импорте файлов неожиданно возникает ошибка.
Проблема в том, что при запуске приложения с cli.py поменялся адрес текущего скрипта, а это, в свою очередь, меняет путь импорта. Файлы больше не находятся в пути импорта, поэтому их абсолютный импорт невозможен.
Одно из возможных решений — поменять путь импорта Python. Вот так:
# Локальные импорты
sys.path.insert(0, str(pathlib.Path(__file__).parent))
import filesЗдесь в пути импорта есть папка со structure.py и files.py. Поэтому это решение работает. Но такой подход неидеален, ведь путь импорта может стать очень неаккуратным и трудным для понимания.
Фактически происходит воссоздание функции ранних версий Python, называемой неявным относительным импортом. Она была удалена из языка в руководстве по стилю PEP 328 со следующим обоснованием:
В Python 2.4 и более ранних версиях при чтении модуля, расположенного внутри пакета, неясно: относится лиimport fooк модулю верхнего уровня или к другому модулю внутри пакета.По мере расширения библиотеки Python всё больше и больше имеющихся внутренних модулей пакета вдруг случайно затеняют модули стандартной библиотеки.Внутри пакетов эта проблема усугубляется из-за невозможности указать, какой модуль имеется в виду. (Источник.)
Другое решение — использовать вместо этого относительный импорт. Меняем импорт в structure.py:
#Локальные импорты
from . import files
Теперь приложение можно запустить через скрипт точки входа:
$ python cli.py structure
Create file: /home/gahjelle/structure/001/structure.py
Create file: /home/gahjelle/structure/001/files.py
Create file: /home/gahjelle/structure/001/__pycache__/structure.cpython-38.pyc
Create file: /home/gahjelle/structure/001/__pycache__/files.cpython-38.pycНо вызвать напрямую приложение больше не получится:
$ python structure.py .
Traceback (most recent call last):
File "structure.py", line 8, in <module>
from . import files
ImportError: cannot import name 'files' from '__main__' (structure.py)Проблема в том, что относительный импорт разрешается в скриптах иначе, чем импортируемые модули. Конечно, можно вернуться и восстановить абсолютный импорт, а затем выполнить непосредственный запуск скрипта или даже попытаться провернуть акробатический трюк с try...except и реализовать абсолютный или относительный импорт файлов (в зависимости от того, что сработает).
Есть даже официально санкционированный хакерский приём, позволяющий работать с относительным импртом в скриптах. Вот только в большинстве случаев при этом придётся менять sys.path. Цитируя Реймонда Хеттинджера, можно сказать:
Должен же быть способ получше! (Источник.)
И действительно, лучшее (и более стабильное) решение — поэкспериментировать с системой управления пакетами и импорта Python, устанавливая проект в качестве локального пакета с помощью pip.
Создание и установка локального пакета
При установке пакета из PyPI этот пакет становится доступным для всех скриптов в вашей среде. Но пакеты можно установить и с локального компьютера, и они точно также будут доступны.
Создание локального пакета не приводит к большому расходу вычислительных ресурсов. Сначала создаём минимальный набор файлов setup.cfg и setup.py во внешнем каталоге structure:
# setup.cfg
[metadata]
name = local_structure
version = 0.1.0
[options]
packages = structure
# setup.py
import setuptools
setuptools.setup()Теоретически name (имя) и version (версия) могут быть любыми. Надо лишь учесть, что они задействованы pip при обращении к пакету, поэтому стоит выбрать для него значения, легко узнаваемые и выделяющие его из массы других пакетов.
Рекомендуется давать всем таким локальным пакетам общий префикс, например local_ или ваше имя пользователя. В пакетах должен находиться каталог или каталоги, содержащие исходный код. Теперь можно установить пакет локально с помощью pip:
$ python -m pip install -e .Эта команда установит пакет в вашу систему. structure после этого будет находиться в пути импорта Python. То есть можно будет выполнить её в любом месте, не беспокоясь о каталоге скрипта, относительном импорте или других сложностях. -e означает editable (редактируемый). Это важная опция, позволяющая менять исходный код пакета без его переустановки.
Примечание: такой установочный файл отлично подходит для самостоятельной работы с проектами. Если же вы планируете поделиться кодом ещё с кем-то, то стоит добавить в установочный файл кое-какую дополнительную информацию.
Теперь, когда structure в системе установлена, можно использовать следующую инструкцию импорта:
#Локальные импорты
from structure import files
Она будет работать независимо от того, чем закончится вызов приложения.
Совет: старайтесь разделять в коде скрипты и библиотеки. Вот хорошее практическое правило:
- Скрипт предназначен для запуска.
- Библиотека предназначена для импорта.
Возможно, у вас есть код, который вы хотите запускать самостоятельно и импортировать из других скриптов. На этот случай стоит провести рефакторинг кода, чтобы разделить общую часть на библиотечный модуль.
Разделять скрипты и библиотеки — неплохая идея, тем не менее в Python все файлы можно запускать и импортировать. Ближе к завершению статьи подробнее расскажем о том, как создавать модули, которые хорошо справляются и с тем, и с другим.
Пакеты пространства имён
Модули и пакеты в Python очень тесно связаны с файлами и каталогами. Это отличает Python от многих других языков программирования, в которых пакеты — это не более чем пространства имён без обязательной привязки к тому, как организован исходный код. Для примера можете ознакомиться с обсуждением на PEP 402.
Пакеты пространства имён доступны в Python с версии 3.3. Они в меньшей степени зависят от имеющейся здесь файловой иерархии. Так, пакеты пространств имён могут быть разделены на несколько каталогов. Пакет пространства имён создаётся автоматически, если у вас есть каталог, содержащий файл .py, но нет __init__.py. Подробное объяснение смотрите в PEP 420.
Замечание: справедливости ради стоит отметить, что пакеты неявных пространств имён появились в Python 3.3. В более ранних версиях Python пакеты пространств имён можно было создавать вручную несколькими различными несовместимыми способами. Все эти ранние подходы обобщены и в упрощённом виде представлены в PEP 420.
Для лучшего понимания пакетов пространства имён попробуем реализовать один из них. В качестве поясняющего примера рассмотрим такую задачу. Дано: объект Song. Требуется преобразовать его в одно из строковых представлений. То есть нужно сериализовать объекты Song.
А конкретнее — нужно реализовать код, который работает примерно так:
>>> song = Song(song_id="1", title="The Same River", artist="Riverside")
>>> song.serialize()
'{"id": "1", "title": "The Same River", "artist": "Riverside"}'Предположим, нам повезло наткнуться на стороннюю реализацию нескольких форматов, в которые нужно сериализовать объекты, и она организована как пакет пространства имён:
third_party/
│
└── serializers/
├── json.py
└── xml.pyЭтого несколько ограниченного интерфейса сериализатора будет достаточно, чтобы продемонстрировать, как работают пакеты пространства имён.
В файле xml.py содержится аналогичный XmlSerializer, который может преобразовать объект в XML:
# third_party/serializers/json.py
import json
class JsonSerializer:
def __init__(self):
self._current_object = None
def start_object(self, object_name, object_id):
self._current_object = dict(id=object_id)
def add_property(self, name, value):
self._current_object[name] = value
def __str__(self):
return json.dumps(self._current_object)Обратите внимание, что оба этих класса реализуют один и тот же интерфейс с помощью методов .start_object(), .add_property() и .__str__().
Затем создаём класс Song, который может применять эти сериализаторы:
# song.py
class Song:
def __init__(self, song_id, title, artist):
self.song_id = song_id
self.title = title
self.artist = artist
def serialize(self, serializer):
serializer.start_object("song", self.song_id)
serializer.add_property("title", self.title)
serializer.add_property("artist", self.artist)
return str(serializer)Song (песня) определяется по идентификатору, названию и исполнителю. Обратите внимание, что .serialize() не нужно знать, в какой формат происходит преобразование, потому что он использует общий интерфейс, определённый ранее.
Установив пакет сторонних serializers, можно работать с ним так:
>>> from serializers.json import JsonSerializer
>>> from serializers.xml import XmlSerializer
>>> from song import Song
>>> song = Song(song_id="1", title="The Same River", artist="Riverside")
>>> song.serialize(JsonSerializer())
'{"id": "1", "title": "The Same River", "artist": "Riverside"}'
>>> song.serialize(XmlSerializer())
'<song id="1"><title>The Same River</title><artist>Riverside</artist></song>'Для разных объектов сериализатора, вызывая .serialize() получаем разные представления песни.
Примечание: при запуске кода можно получить ModuleNotFoundError или ImportError. Всё потому, что serializers нет в пути импорта Python. Но скоро мы увидим, как решить эту проблему.
Пока все идёт хорошо. Но теперь песни нужно преобразовать и в представление YAML, которое не поддерживается сторонней библиотекой. Тут-то в дело и вступают пакеты пространства имён: можем добавить в пакет serializers собственный YamlSerializer, не прибегая к сторонней библиотеке.
Сначала создаём каталог в локальной файловой системе под названием serializers. Важно, чтобы имя каталога совпадало с именем настраиваемого пакета пространства имён:
local/
│
└── serializers/
└── yaml.pyВ файле yaml.py определяем собственный YamlSerializer. Делаем это с помощью пакета PyYAML, который должен быть установлен из PyPI:
$ python -m pip install PyYAMLФорматы YAML и JSON очень похожи, поэтому здесь можно повторно использовать большую часть реализации JsonSerializer:
# local/serializers/yaml.py
import yaml
from serializers.json import JsonSerializer
class YamlSerializer(JsonSerializer):
def __str__(self):
return yaml.dump(self._current_object)Смотрите: YamlSerializer здесь основан на JsonSerializer, который импортируется из этих самых serializers. А раз json и yaml являются частью одного и того же пакета пространства имён, то мы можем даже использовать относительный импорт: from .json import JsonSerializer.
Поэтому, продолжая этот пример, мы теперь можем преобразовать песню в YAML:
>>> from serializers.yaml import YamlSerializer
>>> song.serialize(YamlSerializer())
"artist: Riverside\nid: '1'\ntitle: The Same River\n"Подобно обычным модулям и пакетам, пакеты пространства имён должны находиться в пути импорта Python. Если бы мы делали, как в предыдущих примерах, то могли бы столкнуться с проблемами: Python не находил бы serializers. В реальном коде мы бы использовали pip для установки сторонней библиотеки, так что они автоматически оказывались бы в нашем пути.
Примечание: в исходном примере выбор сериализатора делался более динамично. Позже мы увидим, как использовать пакеты пространств имён в соответствующем шаблоне «фабричный метод».
И нужно позаботиться о том, чтобы локальная библиотека была доступна так же, как и обычный пакет. Как мы уже убедились, это можно сделать либо запустив Python из соответствующего каталога, либо опять-таки используя pip для установки локальной библиотеки.
В этом примере мы тестируем, как можно интегрировать фейковый сторонний пакет с нашим локальным пакетом. Будь сторонний third_party реальным пакетом, то мы бы загрузили его из PyPI с помощью pip. А так мы можем сымитировать его, установив third_party локально, как уже было сделано ранее в примере со structure.
Или же можно поколдовать с путём импорта. Поместите каталоги third_party и local в одну папку, а затем настройте путь Python вот так:
>>> import sys
>>> sys.path.extend(["third_party", "local"])
>>> from serializers import json, xml, yaml
>>> json
<module 'serializers.json' from 'third_party/serializers/json.py'>
>>> yaml
<module 'serializers.yaml' from 'local/serializers/yaml.py'>Теперь можно использовать все сериализаторы, не беспокоясь о том, где они определены: в стороннем пакете или локально.
Руководство по стилю импорта
В руководстве по стилю Python PEP 8 есть ряд рекомендаций, касающихся импорта. Как всегда, в Python важное значение придаётся читаемости и лёгкости сопровождения кода. Вот несколько общих практических правил относительно того, какого стиля надо придерживаться при оформлении импорта:
- Находится в верхней части файла.
- Прописывается в отдельных строках.
- Организуется в группы: сначала идут импорты стандартной библиотеки, затем сторонние импорты, а после — импорты локальных приложений или библиотек.
- Внутри каждой группы импорты располагаются в алфавитном порядке.
- Предпочтение отдаётся абсолютному импорту над относительным.
- Импорты со спецсимволами типа звёздочки (
from module import *) стараются не использовать.
Инструменты isort и reorder-python-imports отлично подходят для реализации этих рекомендаций в последовательном стиле импорта. Вот пример раздела импорта внутри пакета Real Python feed reader package:
# Импорты стандартной библиотеки
import sys
from typing import Dict, List
# Сторонние импорты
import feedparser
import html2text
# Импорты ленты новостей
from reader import URLОбратите внимание на чёткую организацию по группам. Сразу позволяет обозначить зависимости этого модуля, которые должны быть установлены: feedparser и html2text. Обычно подразумевается, что стандартная библиотека доступна. Разделение импортов внутри пакета даёт некоторое представление о внутренних зависимостях кода.
Бывают случаи, когда имеет смысл немного отойти от этих правил. Мы уже видели, что относительный импорт может быть альтернативой при организации иерархии пакетов. В конце статьи мы увидим, как в некоторых случаях можно переместить импорт в определение функции, чтобы прервать циклы импорта.
Импорт в Python. Ресурсы и динамический импорт
Иногда наш код зависит от файлов данных или других ресурсов. В небольших скриптах это не проблема — мы можем указать путь к файлу данных и продолжить работу!
Однако, если файл ресурсов важен для нашего пакета и хочется поделиться им с другими пользователями, возникает несколько проблем:
- У нас не будет контроля над путём к ресурсу, так как это будет зависеть от настроек пользователя, а также от того, как пакет распространяется и устанавливается. Можно попробовать узнать путь к ресурсу с помощью атрибутов пакета
__file__или__path__, но такой способ не всегда может сработать так, как мы ожидаем. - Пакет может находиться внутри ZIP-файла или старого файла
.eggfile, и в этом случае ресурс даже не будет физическим файлом в компьютере пользователя.
Было предпринято несколько попыток решить эти проблемы, в том числе с помощью setuptools.pkg_resources. Однако с появлением в стандартной библиотеке Python 3.7 importlib.resources теперь есть один стандартный способ работы с ресурсными файлами.
Представляем importlib.resources
importlib.resources предоставляет доступ к ресурсам внутри пакетов. В этом контексте ресурс — это любой файл, находящийся в импортируемом пакете. Файл может соответствовать, а может и не соответствовать физическому файлу в файловой системе.
Здесь есть несколько преимуществ: при повторном использовании системы импорта получаем более последовательный способ работы с файлами внутри пакетов плюс более лёгкий доступ к ресурсным файлам в других пакетах. Вот что об этом сказано в документации:
Если вы можете импортировать пакет, то можете иметь доступ к ресурсам внутри этого пакета. (Источник.)
importlib.resources стали частью стандартной библиотеки в Python 3.7. А для более старых версий Python имеется бэкпорт importlib_resources. Чтобы задействовать бэкпорт, надо установить его из PyPI:
$ python -m pip install importlib_resourcesБэкпорт совместим с Python 2.7, а также Python 3.4 и более поздними версиями.
При работе с importlib.resources есть одно условие: ресурсные файлы должны быть доступны внутри обычного пакета. Пакеты пространства имён не поддерживаются. На практике это означает, что файл должен находиться в каталоге, содержащем файл __init__.py.
В качестве первого примера предположим, что у нас в пакете есть такие ресурсы:
data/
│
├── __init__.py
└── WPP2019_TotalPopulationBySex.csv__init__.py — это просто пустой файл, необходимый для указания на то, что books (книги) — это обычный пакет.
Затем можем использовать open_text() и open_binary() для открытия текстовых и бинарных файлов соответственно:
>>> from importlib import resources
>>> with resources.open_text("books", "alice_in_wonderland.txt") as fid:
... alice = fid.readlines()
...
>>> print("".join(alice[:7]))
ГЛАВА I, в которой Алиса чуть не провалилась сквозь землю
Алиса сидела со старшей сестрой на берегу и маялась: делать ей было совершенно нечего, а сидеть без дела, сами знаете, дело нелёгкое; раз-другой она, правда, сунула нос в книгу, которую сестра читала, но там не оказалось ни картинок, ни стишков. «А что толку в книге, - подумала Алиса, - без картинок и стишков?».
>>> with resources.open_binary("books", "alice_in_wonderland.png") as fid:
... cover = fid.read()
...
>>> cover[:8] # Сигнатура файла PNG
b'\x89PNG\r\n\x1a\n'open_text() и open_binary() эквивалентны встроенному open() с параметром mode, имеющим значения rt и rb соответственно. Также доступны в виде read_text() и read_binary() удобные функции для чтения текстовых или двоичных файлов. Ещё больше узнать можно в официальной документации.
Примечание: чтобы полностью перейти на бэкпорт для старых версий Python, импортируем importlib.resources:
try: from importlib import resourcesexcept ImportError: import importlib_resources as resourcesБольше узнать об этом можно в разделе «Полезные советы» этой статьи. Далее в этой части статьи покажем несколько сложных примеров работы с ресурсными файлами на практике.
Файлы данных
В качестве более полного примера работы с файлами данных рассмотрим, как можно реализовать программу викторины, основанную на демографических данных Организации Объединенных Наций. Сначала создаём пакет data и загружаем WPP2019_TotalPopulationBySex.csv с веб-сайта ООН:
data/
│
├── __init__.py
└── WPP2019_TotalPopulationBySex.csvОткроем файл CSV и посмотрим на данные:
LocID,Location,VarID,Variant,Time,PopMale,PopFemale,PopTotal,PopDensity
4,Afghanistan,2,Medium,1950,4099.243,3652.874,7752.117,11.874
4,Afghanistan,2,Medium,1951,4134.756,3705.395,7840.151,12.009
4,Afghanistan,2,Medium,1952,4174.45,3761.546,7935.996,12.156
4,Afghanistan,2,Medium,1953,4218.336,3821.348,8039.684,12.315
...В каждой строке мы видим данные о населении страны за определённый год и вариант, указывающий на соответствующий прогнозный сценарий. В файле содержатся прогнозы численности населения по странам мира до 2100 года.
Следующая функция считывает этот файл и выдаёт общую численность населения той или иной страны за конкретный year (год) и variant (вариант):
import csv
from importlib import resources
def read_population_file(year, variant="Medium"):
population = {}
print(f"Reading population data for {year}, {variant} scenario")
with resources.open_text(
"data", "WPP2019_TotalPopulationBySex.csv"
) as fid:
rows = csv.DictReader(fid)
# Считывание данных, отбор данных по заданному году
for row in rows:
if row["Time"] == year and row["Variant"] == variant:
pop = round(float(row["PopTotal"]) * 1000)
population[row["Location"]] = pop
return populationВыделенные жирным шрифтом строки показывают применение importlib.resources для открытия файла данных. Функция возвращает словарь с численностью населения:
>>> population = read_population_file("2020")
Reading population data for 2020, Medium scenario
(Считывание данных по численности населения на 2020 год, средний сценарий)
>>> population["Norway"]
5421242Имея такой словарь с данными по численности населения, можно сделать много чего интересного, например анализ и визуализации. Ну а мы создадим игру-викторину, в которой участников просят определить, какая страна в наборе имеет самую большую численность населения. Вот как будет выглядеть эта игра:
$ python population_quiz.py
Вопрос 1:
1. Тунис
2. Джибути
3. Белиз
Какая страна имеет наибольшую численность населения? 1
Верно, больше всего населения имеет Тунис (11 818 618)
Вопрос 2:
1. Мозамбик
2. Гана
3. Венгрия
Какая страна имеет наибольшую численность населения? 2
Ответ неверный, в Мозамбике (31 255 435) численность населения выше, чем в Гане (31 072 945)
...Вдаваться в подробности этой реализации не будем, так как они совершенно не имеют отношения к предмету рассмотрения нашей статьи. Однако полный исходный код мы можем показать.
Исходный код демографической викторины:
# population_quiz.py
import csv
import random
try:
from importlib import resources
except ImportError:
import importlib_resources as resources
def read_population_file(year, variant="Medium"):
"""Read population data for the given year and variant""" (Считываются данные о численности населения по конкретному году и варианту)
population = {}
print(f"Reading population data for {year}, {variant} scenario")
with resources.open_text(
"data", "WPP2019_TotalPopulationBySex.csv"
) as fid:
rows = csv.DictReader(fid)
# Считывание данных, отбор данных по заданному году
for row in rows:
if (
int(row["LocID"]) < 900
and row["Time"] == year
and row["Variant"] == variant
):
pop = round(float(row["PopTotal"]) * 1000)
population[row["Location"]] = pop
return population
def run_quiz(population, num_questions, num_countries):
"""Run a quiz about the population of countries""" (Запускается демографическая викторина)
num_correct = 0
for q_num in range(num_questions):
print(f"\n\nQuestion {q_num + 1}:")
countries = random.sample(population.keys(), num_countries)
print("\n".join(f"{i}. {a}" for i, a in enumerate(countries, start=1)))
# Получение данных от пользователя
while True:
guess_str = input("\nWhich country has the largest population? ")
try:
guess_idx = int(guess_str) - 1
guess = countries[guess_idx]
except (ValueError, IndexError):
print(f"Please answer between 1 and {num_countries}")
else:
break
# Проверка ответа
correct = max(countries, key=lambda k: population[k])
if guess == correct:
num_correct += 1
print(f"Yes, {guess} is most populous ({population[guess]:,})")
else:
print(
f"No, {correct} ({population[correct]:,}) is more populous "
f"than {guess} ({population[guess]:,})"
)
return num_correct
def main():
"""Read population data and run quiz""" (Считывание данных по численности населения и запуск викторины)
population = read_population_file("2020")
num_correct = run_quiz(population, num_questions=10, num_countries=3)
print(f"\nYou answered {num_correct} questions correctly")
if __name__ == "__main__":
main()Обратите внимание: здесь в строке 24 мы проверяем, что LocID меньше 900. LocID, равный 900 и выше, указывает не на страновые данные, а на данные по миру, частям света, такие как World, Asia и т.д.
Пример: значки и Tkinter
При создании графических пользовательских интерфейсов (ГПИ) часто требуется включать ресурсные файлы, такие как значки. На следующем примере научимся делать это с помощью importlib.resources. В итоге приложение будет выглядеть довольно просто, но со вкусом благодаря оригинальному значку и оформлению кнопки Goodbye:
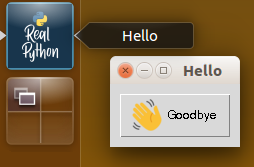
В примере используется пакет ГПИ Tkinter, доступный в стандартной библиотеке. Он основан на оконной системе Tk, изначально разработанной для языка программирования Tcl. Существует множество других пакетов ГПИ, доступных для Python. Если вы используете один из них, то должны уметь добавлять значки в своё приложение с помощью идей, подобных тем, что представлены здесь.
В Tkinter изображения обрабатываются классом PhotoImage. Чтобы создать PhotoImage, передаём путь к файлу изображения.
При распространении пакета вовсе не гарантируется, что ресурсные файлы будут существовать в файловой системе как физические файлы. importlib.resources решает эту проблему с помощью path(). Эта функция вернёт путь к ресурсному файлу, создав при необходимости временный файл.
Чтобы убедиться, что все временные файлы очищены правильно, задействуем path() в качестве менеджера контекста, используя ключевое слово with:
>>> from importlib import resources
>>> with resources.path("hello_gui.gui_resources", "logo.png") as path:
... print(path)
...
/home/gahjelle/hello_gui/gui_resources/logo.pngДля полного примера предположим, что у нас есть следующая файловая иерархия:
hello_gui/
│
├── gui_resources/
│ ├── __init__.py
│ ├── hand.png
│ └── logo.png
│
└── __main__.pyХотите попробовать пример самостоятельно? Скачайте эти файлы вместе с остальным исходным кодом, приведённым в этой статье, перейдя по ссылке ниже:
Получить исходный код: Нажмите здесь и получите исходный код, используемый для изучения системы импорта Python в этой статье.
Код хранится в файле со специальным именем __main__.py. Это имя указывает на то, файл является точкой входа для пакета. Благодаря файлу __main__.py наш пакет может выполняться с python -m:
$ python -m hello_guiГПИ определяется в классе Hello. Обратите внимание, что для получения пути к файлам изображений используется importlib.resources:
# hello_gui/__main__.py
import tkinter as tk
from tkinter import ttk
try:
from importlib import resources
except ImportError:
import importlib_resources as resources
class Hello(tk.Tk):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.wm_title("Hello")
# Изображение считывается, ссылка на него сохраняется и устанавливается в качестве значка
with resources.path("hello_gui.gui_resources", "logo.png") as path:
self._icon = tk.PhotoImage(file=path)
self.iconphoto(True, self._icon)
# Изображение считывается, создаётся кнопка, а ссылка на изображение сохраняется
with resources.path("hello_gui.gui_resources", "hand.png") as path:
hand = tk.PhotoImage(file=path)
button = ttk.Button(
self,
image=hand,
text="Goodbye",
command=self.quit,
compound=tk.LEFT, # Add the image to the left of the text
)
button._image = hand
button.pack(side=tk.TOP, padx=10, pady=10)
if __name__ == "__main__":
hello = Hello()
hello.mainloop()ГПИ определяется в классе Hello. Обратите внимание, что для получения пути к файлам изображений используется importlib.resources:
Официальная документация содержит хороший список ресурсов, с которого можно начать изучение. Ещё один отличный ресурс — это «Руководство по TkDocs», которое показывает, как использовать Tk в других языках.
Примечание: единственное, что может вызывать неудобство при работе с изображениями в Tkinter, так это то, что здесь нужно следить за тем, чтобы изображения не удалялись механизмом автоматического управления памятью. Из-за того, как Python и Tk взаимодействуют, сборщик мусора в Python (по крайней мере, в CPython) не регистрирует, что .iconphoto() и Button используют изображения.
Чтобы убедиться, что изображения сохраняются, нужно вручную добавлять ссылку на них. В нашем коде это было сделано в строках 18 и 31.
Динамический импорт
Одна из отличительных особенностей Python в том, что это очень динамичный язык. Можно много чего сделать с программой Python во время её выполнения (хотя иногда делать этого не стоит), например добавлять атрибуты к классу, переопределять методы или изменять строку документации модуля. Мы можем изменить print() так, чтобы он ничего не делал:
>>> print("Hello dynamic world!")
Hello dynamic world!
>>> # Переопределяем встроенный print()
>>> print = lambda *args, **kwargs: None
>>> print("Hush, everybody!")
>>> # Ничего не выводитсяНа самом деле, мы не переопределяем print(). Мы определяем другой print(), который затеняет встроенный print(). Для возвращения к исходному print() удаляем наш пользовательский print() с помощью del print. Так можно затенить любой объект Python, встроенный в интерпретатор.
Обратите внимание: в приведенном выше примере мы переопределяем print() с помощью лямбда-функции. Также можно было бы использовать определение обычной функции:
>>> def print(*args, **kwargs):... passВ этой части статьи мы ещё узнаем, как выполнять динамический импорт в Python. Освоив его, вы избавитесь от необходимости решать, что импортировать во время выполнения программы.
importlib
До сих пор мы использовали ключевое слово import для явного импорта модулей и пакетов в Python. Однако весь механизм импорта доступен в пакете importlib, что позволяет нам выполнять импорт более динамично. Следующий скрипт запрашивает у пользователя имя модуля, импортирует этот модуль и выводит строку его документации:
# docreader.py
import importlib
module_name = input("Name of module? ")
module = importlib.import_module(module_name)
print(module.__doc__)import_module() возвращает объект модуля, который можно привязать к любой переменной. После чего мы можем обращаться с этой переменной как с обычным импортируемым модулем. Этот скрипт можно использовать вот так:
$ python docreader.py
Имя модуля? math
Этот модуль всегда доступен. Он предоставляет доступ к математическим функциям, определяемым стандартом С.
$ python docreader.py
Имя модуля? csv
CSV-парсинг и запись..
Этот модуль предоставляет классы, которые помогают в чтении и записи
файлов Comma Separated Value (CSV), т.е. файлов со значениями, разделёнными запятыми. Кроме того, он реализует интерфейс,
описанный в PEP 305. Хотя парсинг многих CSV файлов очень прост,
этот формат формально не определяется стабильной спецификацией и
едва уловим. Настолько, что парсинг строк CSV-файла с чем-то
вроде line.split(",") обречен на неудачу. Модуль поддерживает три
базовые API: чтение, запись и регистрацию диалектов..
[...]В каждом случае модуль импортируется динамически с помощью import_module().
Фабричный метод с пакетами пространства имён
Вернёмся к примеру с сериализаторами. Благодаря serializers, реализованным в качестве пакета пространства имён, у нас появилась возможность добавлять пользовательские сериализаторы. Сериализаторы создаются с помощью фабрики сериализаторов. Попробуем сделать это, использовав importlib.
Добавим в наш локальный пакет пространства имён serializers следующий код:
# local/serializers/factory.py
import importlib
def get_serializer(format):
try:
module = importlib.import_module(f"serializers.{format}")
serializer = getattr(module, f"{format.title()}Serializer")
except (ImportError, AttributeError):
raise ValueError(f"Unknown format {format!r}") from None
return serializer()
def serialize(serializable, format):
serializer = get_serializer(format)
serializable.serialize(serializer)
return str(serializer)Фабрика get_serializer() может создать сериализаторы динамически на основе параметра format , а затем serialize() может применить сериализатор к любому объекту, реализующему метод .serialize().
Фабрика делает строгие предположения об именовании модуля и класса, которые содержат конкретные сериализаторы. Далее в статье мы узнаем об архитектуре плагинов, которая придаёт больше гибкости.
А пока воссоздадим предыдущий пример вот таким образом:
>>> from serializers import factory
>>> from song import Song
>>> song = Song(song_id="1", title="The Same River", artist="Riverside")
>>> factory.serialize(song, "json")
'{"id": "1", "title": "The Same River", "artist": "Riverside"}'
>>> factory.serialize(song, "yaml")
"artist: Riverside, id: '1', title: The Same River\n"
>>> factory.serialize(song, "toml")
ValueError: Unknown format 'toml'В этом случае нам больше не нужно выполнять явный импорт каждого сериализатора. Имя сериализатора указываем со строкой. Строка может быть даже выбрана пользователем во время выполнения.
Обратите внимание: в обычном пакете мы бы, наверное, реализовали get_serializer() и serialize() в файле __init__.py. Так мы могли бы просто импортировать serializers , а затем вызвать serializers.serialize().
Но пакеты пространства имён не могут использовать __init__.py, поэтому нужно реализовать эти функции в отдельном модуле.
Последний пример показывает, что мы получаем соответствующее сообщение об ошибке, если пытаемся сериализоваться в формат, который не был реализован.
Пакет плагинов
Рассмотрим ещё один пример использования динамического импорта. Мы можем использовать следующий модуль для настройки гибкой архитектуры плагинов в коде. Это похоже на то, что было в предыдущем примере, в котором мы могли подключить сериализаторы для различных форматов, добавив новые модули.
Эскпериментальное средство визуализации Glue — это одно из приложений, эффективно использующих плагины. Оно сходу может читать множество различных форматов данных. Если всё-таки нужный формат данных не поддерживается, можно написать собственный пользовательский загрузчик данных.
Просто добавляется функция, которая декорируется и помещается в специальное место, чтобы Glue было легче её найти. И никакую часть исходного кода Glue менять не надо. Все детали смотрите в документации.
Мы можем настроить аналогичную архитектуру плагина для использования в своих проектах. В этой архитектуре два уровня:
- Пакет плагинов — это набор связанных плагинов, соответствующих пакету Python.
- Плагин — это пользовательское поведение, доступное в модуле Python.
Модуль plugins, который предоставляет архитектуру плагина, имеет следующие функции:
# plugins.py
def register(func):
"""Decorator for registering a new plugin""" (Декоратор для регистрации нового плагина)
def names(package):
"""List all plugins in one package""" (Приводит список всех плагинов в одном пакете)
def get(package, plugin):
"""Get a given plugin""" (Получает данный плагин)
def call(package, plugin, *args, **kwargs):
"""Call the given plugin""" (Вызывает этот плагин)
def _import(package, plugin):
"""Import the given plugin file from a package""" (Импортирует файл этого плагина из пакета)
def _import_all(package):
"""Import all plugins in a package""" (Импортирует все плагины в пакете)
def names_factory(package):
"""Create a names() function for one package""" (Создаёт функцию names() для одного пакета)
def get_factory(package):
"""Create a get() function for one package""" (Создаёт функцию get() для одного пакета)
def call_factory(package):
"""Create a call() function for one package""" (Создаёт функцию call() для одного пакета)Фабричные функции используются для удобного добавления функциональности в пакеты плагинов. Вскоре увидим примеры того, как это происходит.
Рассматривать код во всех деталях не будем: это выходит за рамки статьи. Если вам интересно, можем показать реализацию ниже.
В следующем коде показана реализация plugins.py, описанная выше:
# plugins.py
import functools
import importlib
from collections import namedtuple
from importlib import resources
# Базовая структура для хранения информации об одном плагине
Plugin = namedtuple("Plugin", ("name", "func"))
# Словарь с информацией обо всех зарегистрированных плагинах
_PLUGINS = {}
def register(func):
"""Decorator for registering a new plugin"""
package, _, plugin = func.__module__.rpartition(".")
pkg_info = _PLUGINS.setdefault(package, {})
pkg_info[plugin] = Plugin(name=plugin, func=func)
return func
def names(package):
"""List all plugins in one package"""
_import_all(package)
return sorted(_PLUGINS[package])
def get(package, plugin):
"""Get a given plugin"""
_import(package, plugin)
return _PLUGINS[package][plugin].func
def call(package, plugin, *args, **kwargs):
"""Call the given plugin"""
plugin_func = get(package, plugin)
return plugin_func(*args, **kwargs)
def _import(package, plugin):
"""Import the given plugin file from a package"""
importlib.import_module(f"{package}.{plugin}")
def _import_all(package):
"""Import all plugins in a package"""
files = resources.contents(package)
plugins = [f[:-3] for f in files if f.endswith(".py") and f[0] != "_"]
for plugin in plugins:
_import(package, plugin)
def names_factory(package):
"""Create a names() function for one package"""
return functools.partial(names, package)
def get_factory(package):
"""Create a get() function for one package"""
return functools.partial(get, package)
def call_factory(package):
"""Create a call() function for one package"""
return functools.partial(call, package)Эта реализация немного упрощена. Так, она не выполняет явной обработки ошибок. Более полная реализация доступна по ссылке на проект PyPlugs.
_import() использует importlib.import_module() для динамической загрузки плагинов. А _import_all() использует importlib.resources.contents() для перечисления всех доступных плагинов в данном пакете.
Рассмотрим несколько примеров использования плагинов. Первый пример — это пакет greeter, который можно использовать для добавления различных приветствий в приложение. Полная архитектура плагинов здесь определённо избыточна, но она показывает, как работают плагины. Представьте, что у вас такой пакет greeter:
greeter/
│
├── __init__.py
├── hello.py
├── howdy.py
└── yo.pyКаждый модуль greeter определяет функцию, которая принимает один аргумент name. Посмотрите, как с помощью декоратора @register все они регистрируются в качестве плагинов:
# greeter/hello.py
import plugins
@plugins.register
def greet(name):
print(f"Hello {name}, how are you today?")
# greeter/howdy.py
import plugins
@plugins.register
def greet(name):
print(f"Howdy good {name}, honored to meet you!")
# greeter/yo.py
import plugins
@plugins.register
def greet(name):
print(f"Yo {name}, good times!")Обратите внимание: для упрощения обнаружения и импорта плагинов имя каждого плагина содержит не имя функции, а имя модуля, в котором он находится. Поэтому на каждый файл может быть только один плагин.
В завершение настройки greeter как пакета плагинов можно использовать фабричные функции в plugins для добавления функциональности в сам пакет greeter:
# greeter/__init__.py
import plugins
greetings = plugins.names_factory(__package__)
greet = plugins.call_factory(__package__)Теперь мы можем использовать greetings() и greet() вот так:
>>> import greeter
>>> greeter.greetings()
['hello', 'howdy', 'yo']
>>> greeter.greet(plugin="howdy", name="Guido")
Howdy good Guido, honored to meet you!Заметьте, что greetings() автоматически обнаруживает все плагины, доступные в пакете.
Мы также можем более динамически выбирать, какой плагин вызывать. В следующем примере выбираем плагин случайным образом. Плагин также можно выбрать на основе конфигурационного файла или пользовательских данных:
>>> import greeter
>>> import random
>>> greeting = random.choice(greeter.greetings())
>>> greeter.greet(greeting, name="Frida")
Hello Frida, how are you today?
>>> greeting = random.choice(greeter.greetings())
>>> greeter.greet(greeting, name="Frida")
Yo Frida, good times!Для обнаружения и вызова различных плагинов их нужно импортировать. Остановимся ненадолго на том, как plugins работают с импортом. Всё самое главное происходит в следующих двух функциях внутри plugins.py:
import importlib
import pathlib
from importlib import resources
def _import(package, plugin):
"""Import the given plugin file from a package""" (Импортирует файл этого плагина из пакета)
importlib.import_module(f"{package}.{plugin}")
def _import_all(package):
"""Import all plugins in a package""" (Импортирует все плагины в пакете)
files = resources.contents(package)
plugins = [f[:-3] for f in files if f.endswith(".py") and f[0] != "_"]
for plugin in plugins:
_import(package, plugin)- Система импорта Python гарантирует, что каждый плагин импортируется только один раз.
- Декораторы
@register, определённые внутри каждого модуля plugin, регистрируют каждый импортированный плагин. - В полной реализации для работы с отсутствующими плагинами будет обработка ошибок.
_import_all() обнаруживает все плагины в пакете. Вот как это работает:
contents()изimportlib.resourcesвыводит список всех файлов внутри пакета.- Результаты фильтруются для поиска потенциальных плагинов.
- Каждый файл Python, не начинающийся с подчеркивания, импортируется.
- Плагины в любом из файлов обнаруживаются и регистрируются.
Завершим эту часть статьи финальной версией пакета пространства имён. Одной из нерешённых проблем было то, что фабрика get_serializer() делала строгие предположения об именовании классов сериализатора. С помощью плагинов можно сделать их более гибкими.
Первым делом добавляем строку, регистрирующую каждый из сериализаторов. Вот пример того, как это делается в сериализаторе yaml:
# local/serializers/yaml.py
import plugins
import yaml
from serializers.json import JsonSerializer
@plugins.register
class YamlSerializer(JsonSerializer):
def __str__(self):
return yaml.dump(self._current_object)Затем обновляем get_serializers() для использования plugins:
# local/serializers/factory.py
import plugins
get_serializer = plugins.call_factory(__package__)
def serialize(serializable, format):
serializer = get_serializer(format)
serializable.serialize(serializer)
return str(serializer)Мы реализуем get_serializer() с помощью call_factory() , так как это автоматически инстанцирует каждый сериализатор. При таком рефакторинге сериализаторы работают точно так же, как и раньше. Но теперь у нас больше гибкости в именовании классов сериализаторов.
Ещё больше об использовании плагинов можно узнать в PyPlugs на PyPI и презентации Плагины: добавление гибкости приложениям из PyCon 2019.
Читайте также:
- Продвинутый Python: 9 важнейших аспектов при определении классов
- Как автоматизировать электронную почту с помощью Python
- Контейнеризация в Python. Часть 1
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Geir Arne Hjelle: Python import: Advanced Techniques and Tips





