
Каждый понедельник моя жизнь озаряется одним событием. И учёба или работа здесь ни при чём — я говорю об еженедельном обновлении чудесного плейлиста “Открытия недели” на Spotify. Эта подборка удивительна тем, что ты никогда не слышал эти композиции, но уже их любишь.
Сложив вместе недавно обретённые навыки программирования и уже довольно давно обретённую любовь к Spotify, я попыталась создать свою собственную рекомендательную систему и попутно изучить ещё и анализ данных.
Если захотите взглянуть на мой код, он здесь (разделён на несколько записных книжек).
Установка Spotify API
Магия начинается с использования Spotify API для создания приложения в среде Spotify для разработчиков. После создания аккаунта разработчика и среды приложения я получила доступ к данным всех публичных плейлистов. Вот тут можно увидеть, как я начала работу с API.
При первом обращении к API я брала только два плейлиста: понравившиеся и непонравившиеся песни. Внимание, спойлер: в дальнейшем они использовались для контролируемого обучения.
Я написала основную функцию для превращения любого плейлиста во фрейм данных:
def master_function(uri):
uri = playlist_uri
username = uri.split(':')[2]
playlist_id = uri.split(':')[4]
results = {'items':[]}
for n in range(0,3000,100):
new = sp.user_playlist_tracks(username, playlist_id, offset = n)
results['items'] += new['items']
playlist_tracks_data = results
playlist_tracks_id = []
playlist_tracks_titles = []
playlist_tracks_artists = []
for track in playlist_tracks_data['items']:
playlist_tracks_id.append(track['track']['id'])
playlist_tracks_titles.append(track['track']['name'])
#добавление списка исполнителей трека в список исполнителей всего плейлиста
for artist in track['track']['artists']:
artist_list = []
artist_list.append(artist['name'])
playlist_tracks_artists.append(artist_list[0])
df = pd.DataFrame([])
for i in range(0, len(playlist_tracks_id)):
features = sp.audio_features(playlist_tracks_id[i])
features_df = pd.DataFrame(features)
df = df.append(features_df)
df['title'] = playlist_tracks_titles
#features_df['first_artist'] = playlist_tracks_first_artists
df['main_artist'] = playlist_tracks_artists
#features_df = features_df.set_index('id')
df = df[['id', 'title', 'main_artist',
'danceability', 'energy', 'key', 'loudness',
'mode', 'acousticness', 'instrumentalness',
'liveness', 'valence', 'tempo',
'duration_ms', 'time_signature']]
return dfРазведочный анализ данных
К счастью, Spotify предоставляет возможность провести такой анализ с помощью объекта свойств аудио (Audio Feature Object) или попросту свойств. Давайте подробнее ознакомимся с каждым из них.
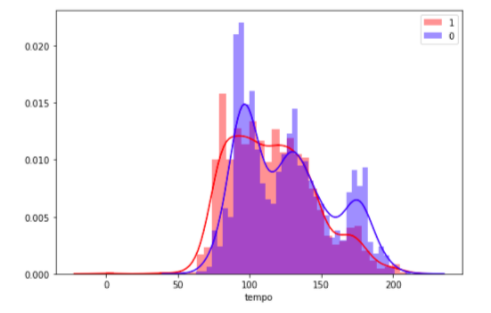
ТЕМП. Проще говоря, количество ударов в песне в минуту (BPM)
Разные жанры музыки обладают разным темпом: хип-хоп — 85–95 BPM, техно — 120–125 BPM, хаус и поп — 115–130 BPM, электро — 128 BPM, реггетон — >130 BPM, дабстеп — 140 BPM.
ЭНЕРГИЧНОСТЬ. Мера интенсивности и активности
Это первая из более субъективных метрик Spotify.
Энергичность представляет собой воспринимаемую степень интенсивности и активности звучания.
Обычно энергичные треки кажутся быстрыми, громкими и шумными. К примеру, у дэт-метала высокие показатели энергичности, а у прелюдий Баха — низкие.
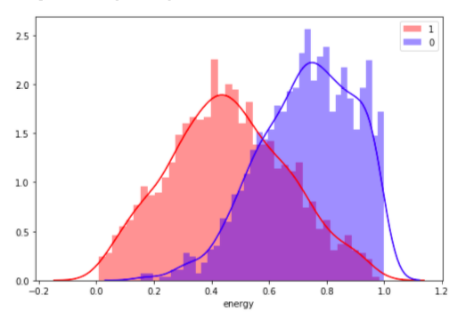
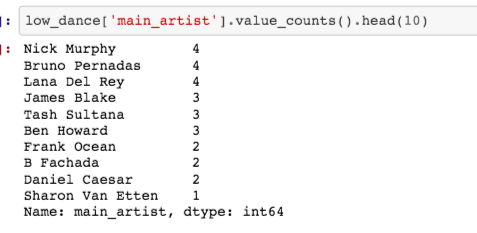
Кто из исполнителей тянет энергичность моих любимых треков вниз?

ТАНЦЕВАЛЬНОСТЬ
Метрика “танцевальность” описывает, насколько трек подходит для танцев на основе комбинации музыкальных элементов: темпа, стабильности ритма, силы ударов и общей упорядоченности.
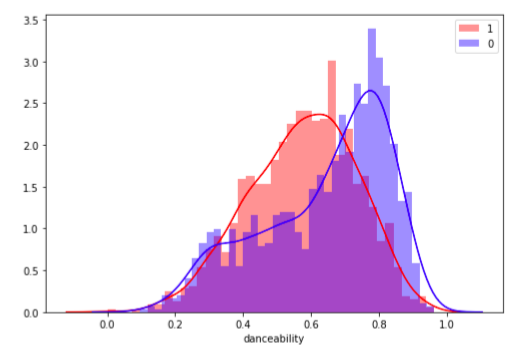
Похоже, в то время как “нелюбимые” треки демонстрируют асимметричное распределение в сторону большей танцевальности, весьма необычное распределение любимых указывает, что мне нравятся песни с разными показателями танцевальности.

ЭНЕРГИЧНОСТЬ против ТАНЦЕВАЛЬНОСТИ
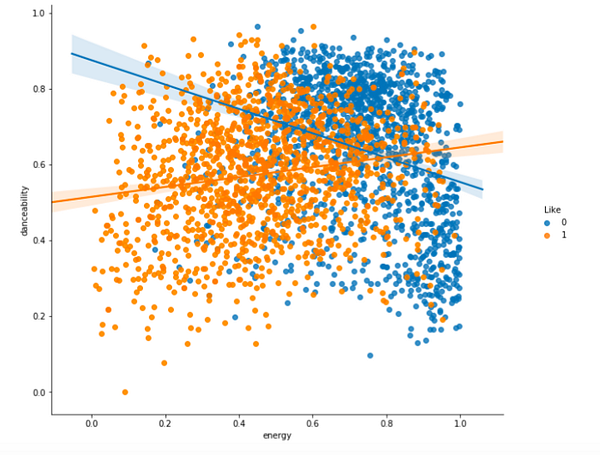
Из графика видно, что мне нравится музыка с нормальным уровнем танцевальности, но низкой степенью энергичности — можно увидеть два отдельных кластера.
Что это за музыка такая?
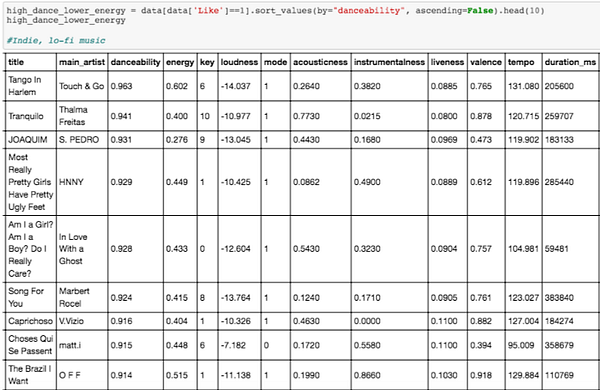
РЕГИСТР
Свойство означает общий регистр (высоту тона) композиции. Числа соответствуют регистрам с использованием стандартной нотации высотного класса: например 0 = C, 1 = C♯/D♭, 2 = D и т. д. Если регистр не определён, значение равняется -1.

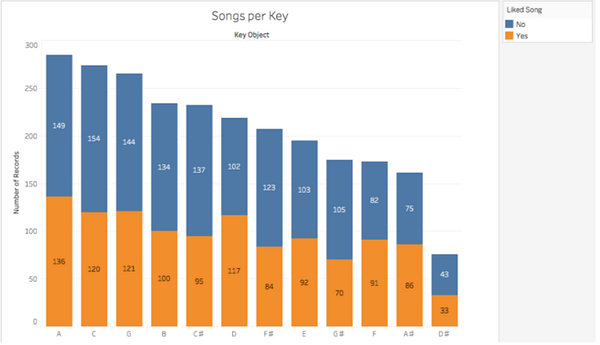
Songs per Key - Песни по регистру
Number of Records - Количество композиций
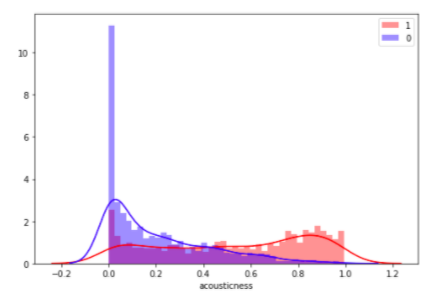
АКУСТИЧНОСТЬ
Мера достоверности (от 0.0 до 1.0) того, что композиция является акустической. Значение 1.0 указывает на высокую вероятность акустичности трека.
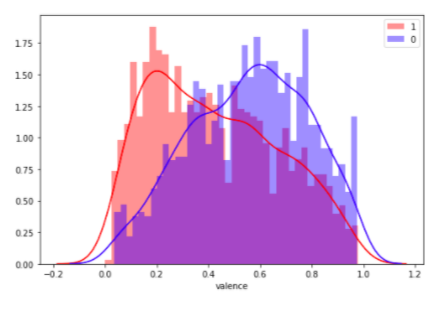
НАСТРОЕНИЕ
Это одна из самых интересных метрик в Spotify — она означает степень позитивности композиции:
- треки с высоким уровнем настроения звучат позитивнее (выражают счастье, радость, эйфорию);
- треки с низким уровнем настроения звучат более негативно (выражают печаль, депрессию, злость).
ГРОМКОСТЬ. Общая громкость композиции в децибелах (dB)
Значение громкости усредняется в целом по треку и в дальнейшем используется для сравнения относительной громкости разных треков. Громкость — это свойство звука, имеющее прямую психологическую корреляцию с физической силой (амплитуда). Значения варьируются от 60 до 0 dB.
К слову, вы знали, что Spotify отбирает треки по громкости?
Контролируемое обучение
Код целиком вы можете посмотреть здесь.
Первый этап — разделить данные на набор для обучения и набор для проверки. Я взяла из scikit-learn функцию train_test_split(), которая делит данные согласно проценту test_size, указанному в методе. Код ниже делит данные так: 85% — для обучения и 10% — для проверки.
from sklearn.model_selection import train_test_split
features = ['danceability', 'energy', 'key','loudness', 'mode', 'acousticness', 'instrumentalness', 'liveness','valence', 'tempo', 'duration_ms', 'time_signature']
X = data[features]
y = data['Like']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.1)Логистическая регрессия
Первая модель, которую я попробовала применить, — логистическая регрессия. Точность получилась равной 80%.
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression()
lr_model.fit(X_train, y_train)
lr_pred = lr_model.predict(X_test)
score = metrics.accuracy_score(y_test, lr_pred)*100
print("Accuracy using Logistic Regression: ", round(score, 3), "%")Дерево решений
Часто дерево решений проще всего поддаётся визуализации. Оно основано всего-навсего на свойствах, поэтому можно легко проследить цепочку и увидеть, как принимается решение.
model = DecisionTreeClassifier(max_depth = 8)
model.fit(X_train, y_train)
score = model.score(X_test,y_test)*100
print("Accuracy using Decision Tree: ", round(score, 2), "%")
#Визуализация дерева
export_graphviz(model, out_file="tree.dot", class_names=["malignant", "benign"],
feature_names = data[features].columns, impurity=False, filled=True)
import graphviz
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
#Значимость свойства
def plot_feature_importances(model):
n_features = data[features].shape[1]
plt.barh(range(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), features)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.title("Spotify Features Importance - Decision Tree")
plot_feature_importances(model)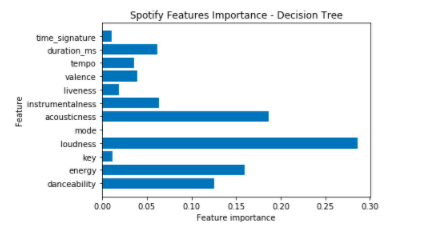
Метод k-ближайших соседей (KNN)
Классификатор k-ближайших соседей для определения выхода анализирует “соседей” точки данных. Этот метод дал чуть более точные по сравнению с предыдущими подходами результаты.
knn = KNeighborsClassifier(n_neighbors = 2)
knn.fit(X_train, y_train)
knn_pred = c.predict(X_test)
score_test_knn = accuracy_score(y_test, knn_pred) * 100
print("Accuracy using Knn Tree: ", round(score_test_knn, 3), "%")Случайный лес
Случайный лес — это модель, которая состоит из множества деревьев решений. Вместо того чтобы просто вывести средний показатель прогнозов деревьев (которые можно назвать “лесом”), эта модель использует выборку и случайные подмножества для построения деревьев и разделения узлов. Точность — 87%.
model=RandomForestClassifier(n_estimators=100)
model = clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
score = metrics.accuracy_score(y_test, y_pred)*100
print("Accuracy with Random Forest:", round(score, 4), "%")Проверка результатов
После того как я выяснила, какие треки в моём наборе данных для проверки были неверно классифицированы, я решила провести сравнение с внешними плейлистами.
Для этого я использовала лучший классификатор (случайный лес) с predict_proba, а не одно толькопрогнозирование. Благодаря этому получился не простой бинарный выход, а вероятность как зависимая переменная.
pred = clf.predict_proba(felipe_df[features])[:,1]
felipe_df['prediction'] = pred
print("How similar is it to my taste?", round(felipe_df['prediction'].mean()*100,3), "%")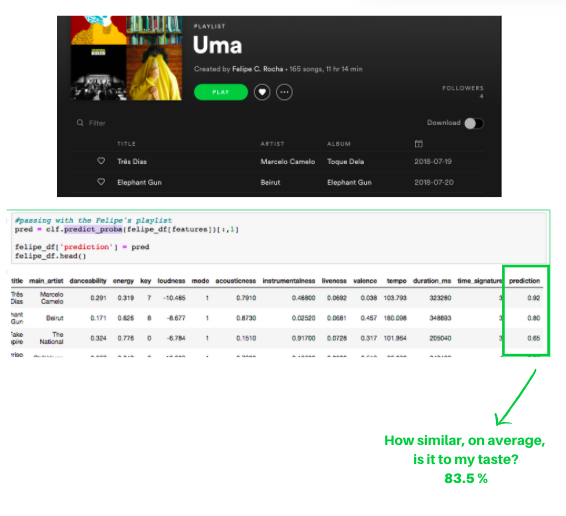
Неконтролируемое обучение
В контролируемом обучении есть входные переменные (X) и выходная переменная (Y), а для обучения отображающей функции от входа до выхода используется алгоритм. В неконтролируемом же обучении есть только входные данные (X) без соответствующих им выходных переменных.
Цель — извлечь информацию из любых взятых образцов без присвоения меток понравившимся и непонравившимся композициям. Задачи неконтролируемого обучения можно далее разделить на задачи кластеризации и задачи ассоциации.
Метод главных компонент (PCA)
Метод главных компонент (PCA) выделяет отклонения и выявляет значимые образцы в наборе данных. Другими словами, метод берёт все переменные и представляет их в меньшем пространстве, сохраняя структуру исходных данных, насколько это возможно.
- Первая главная компонента в 1 измерении будет вмещать максимум отклонений набора данных;
- Вторая компонента будет вмещать столько оставшихся отклонений, сколько возможно, чтобы оставаться ортогональной первой компоненте, и т. д.
from sklearn.decomposition import PCA
pca = PCA(n_components=3, random_state=42)
df_pca = pd.DataFrame(data=pca.fit_transform(features_scaled), columns=[‘PC1’,’PC2',’PC3'])
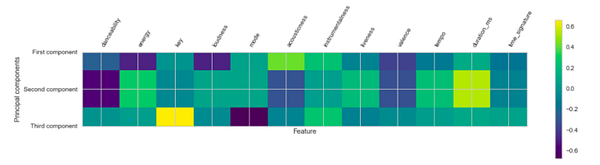
plt.matshow(pca.components_, cmap='viridis')
plt.yticks([0, 1, 2], ["First component", "Second component", "Third component"])
plt.colorbar()
plt.xticks(range(len(data[features].columns)),data[features], rotation=60, ha='left')
plt.xlabel("Feature")
plt.ylabel("Principal components")
Представление в 3D: я выбрала танцевальность для цветовой дифференциации, поскольку анализ выше показал важность этого свойства.
# Представление PCA в 3D
px.scatter_3d(df_pca_fix,
x='PC1',
y='PC2',
z='PC3',
title='Principal Component Analysis Projection (3-D)',
color='danceability',
size=np.ones(len(df_pca_fix)),
size_max=5,
height=600,
hover_name='title',
hover_data=['main_artist'],
color_continuous_scale=px.colors.cyclical.mygbm[:-6])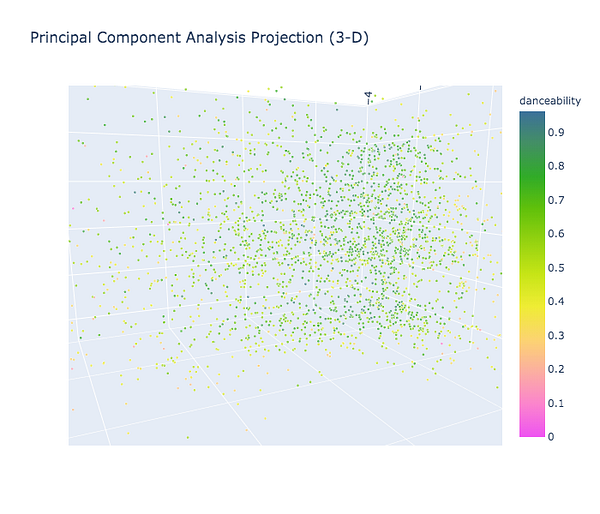
Мы можем видеть позицию каждого трека и расстояние от него до других треков, основанное на трансформированных аудио-свойствах. Большинство точек сконцентрировано в зелёных областях. Отображение также подтверждает, что танцевальность в некоторой степени соотносится со второй компонентой. Песня ‘Am I boy? Am I a girl? Do I really care’ (к слову, она входит в список понравившихся) находится напротив треков с гораздо более низким уровнем танцевальности (к примеру, “Hallowen” Hellowen).
Кластеризация по k-средним
Основным принципом кластеризации по k-средним является то, что мы можем выбрать, сколько кластеров хотим создать (обычно это число обозначается буквой k). Это делается, исходя из предметных знаний (к примеру, у нас есть маркетинговое исследование по количеству групп разных типов, на которые мы сможем разделить клиентов) на основе наиболее вероятного предположения или вовсе случайным образом.
В результате получатся области, которые определяют, в какой кластер попадёт новая единица данных.
# Начнём с 2 кластеров (2 свойств)
kmeans = KMeans(n_clusters=2)
model = kmeans.fit(features_scaled)
data_2 = data.copy()
data_2['labels'] = model.labels_
data_2['labels'].value_counts()#Проверим количество меток в каждом кластере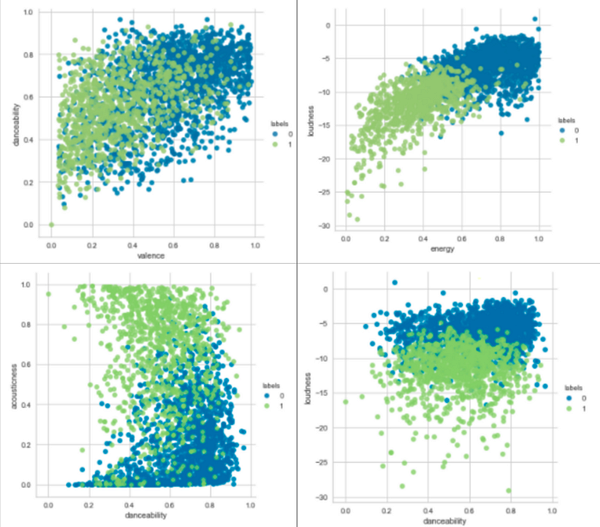
Отображение кластеров
danceability - танцевальность
valence - настроение
loudness - громкость
energy - энергичность
acousticness - акустичность
labels - меткиКаково оптимальное количество кластеров? Смысл кластеризации состоит в том, чтобы выделить относительно небольшое количество общих черт в наборе данных. Слишком большое число кластеров может означать, что мы мало изучили данные, слишком маленькое — что мы искусственно группируем несхожие элементы.
Есть множество разных методов выбора подходящего количества кластеров, наиболее часто используемый — вычислить метрику для каждого числа кластеров, а затем отобразить вместе интеграл вероятности ошибок и количество кластеров.
- Визуализатор K-Elbow Visualizer от Yellowbrick использует “локтевой” метод выбора оптимального количества кластеров сопоставлением модели k-средних с рядом значений K.
X = features_scaled
# Создать экземпляры кластеризующей модели и визуализатора
model = KMeans()
visualizer = KElbowVisualizer(model, k=(1,10))
visualizer.fit(X) # Вписать данные в визуализатор
visualizer.show() # Завершить процесс и отрисовать фигуру
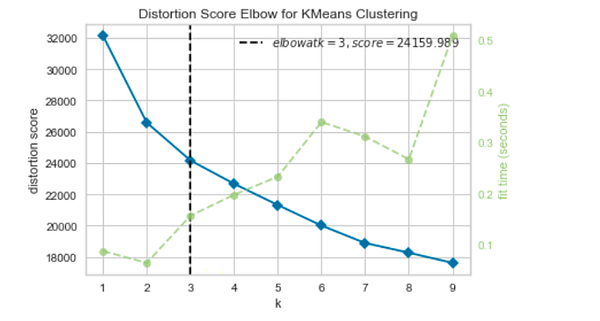
Также для неконтролируемого обучения я использовала две другие методологии: Гауссову смесь распределений и иерархическую агломеративную кластеризацию (HAC). Код можно посмотреть здесь.
Итоги
Выполняя этот проект, я изучила Spotify API, провела разведочный анализ данных на понравившихся и непонравившихся треках, а также на моём плейлисте Musical Journey, и даже применила несколько методов контролируемого и неконтролируемого машинного обучения.
В результате получилась программа, в которую пользователь может ввести URI своего (публичного) плейлиста и получить разведочный анализ данных по свойствам треков, а также новые музыкальные рекомендации. Это будет сделано с помощью методов неконтролируемого обучения, поскольку такой плейлист будет состоять целиком из понравившихся треков, к которым неприменимы метки.
Я создала огромную функцию, которую можно найти здесь. Давайте пройдёмся по самым важным частям:
- Используем основную функцию, которая принимает URI плейлиста и преобразует его во фрейм данных.
- Создаём крупный, разнообразный плейлист, который послужит библиотекой для рекомендаций.
- Применяем к этим двум плейлистам метод главных компонент с 3 компонентами.
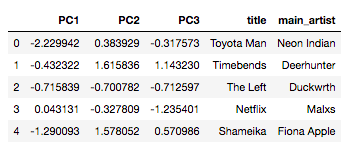
4. Получаем рекомендации методами главных компонент и ближайших соседей. Экспортируем результат в PDF.
from scipy.spatial import KDTree
columns = [‘PC1’, ‘PC2’, ‘PC3’]
kdB = KDTree(df_pca_all_songs[columns].values)
neighbours = kdB.query(df_pca[columns].values, k=1)[-1]
#Выход рекомендаций: 30 треков, которые могут вам понравиться
recomendations = all_songs[all_songs.index.isin(neighbours[:31])]
recomendations_output = recomendations[['title', 'main_artist']]
recomendations_output.columns = ['Song Title', 'Artist']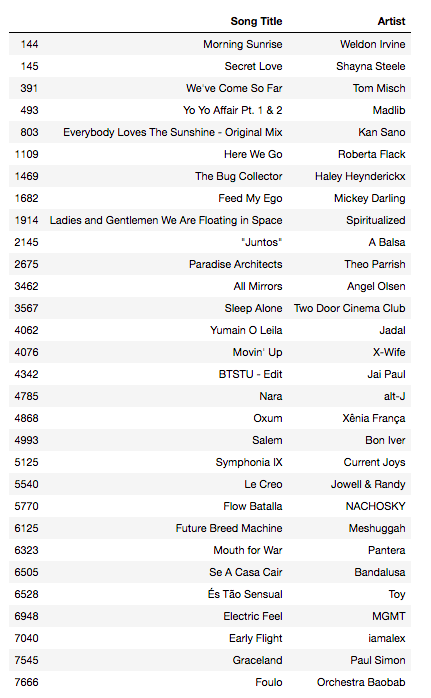
5. Проводим разведочный анализ данных с плейлистом Обамы, топом альбомов и песен Pitchfork и чартом “ТОП-100 композиций” на Billboard.
from sklearn.preprocessing import MinMaxScaler #scale
data_scaled = pd.DataFrame(MinMaxScaler().fit_transform(data[features]),
columns=data[features].columns)
data_scaled[‘Playlist’] = data[‘Playlist’]
df_radar = data_scaled.groupby(‘Playlist’).mean().reset_index() \
.melt(id_vars=’Playlist’, var_name=”features”, value_name=”avg”) \
.sort_values(by=[‘Playlist’,’features’]).reset_index(drop=True)
fig = px.line_polar(df_radar,
r=”avg”,
theta=”features”,
title=’Mean Values of Each Playlist Features’,
color=”Playlist”,
line_close=True,
line_shape=’spline’,
range_r=[0, 0.9],
color_discrete_sequence=px.colors.cyclical.mygbm[:-6]
fig.show()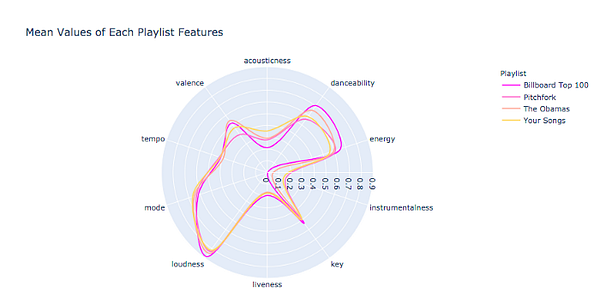
acousticness - акустичность
danceability - танцевальность
energy - энергичность
instrumentalness - инструментальность
key - регистр
liveness - живость
loudness - громкость
mode - тональность
tempo - темп
valence - настроениеАндеграунд или мейнстрим? Сравниваем мой музыкальный вкус с Billboard и Pitchfork.

def big_graph(feature, label1="", label2="", label3 = ""):
sns.kdeplot(data[data['Playlist']=='Your Songs'][feature],label=label1)
sns.kdeplot(data[data['Playlist']=='Pitchfork'][feature],label=label2)
sns.kdeplot(data[data['Playlist']=='Billboard Top 100'][feature],label=label3)
plt.title(feature)
plt.grid(b=None)
plots =[]
plt.figure(figsize=(16,16))
plt.suptitle("Hipster or Mainstream?", fontsize="x-large")
for i, f in enumerate(features):
plt.subplot(4,4,i+1)
if ((i+1)% 4 == 0) or (i+1==len(features)):
big_graph(f,label1="Your Songs", label2="Pitchfork", label3="Billboard Top 100")
else:
big_graph(f)
plots.append(plt.gca())
#Для плейлиста Обамы код будет таким же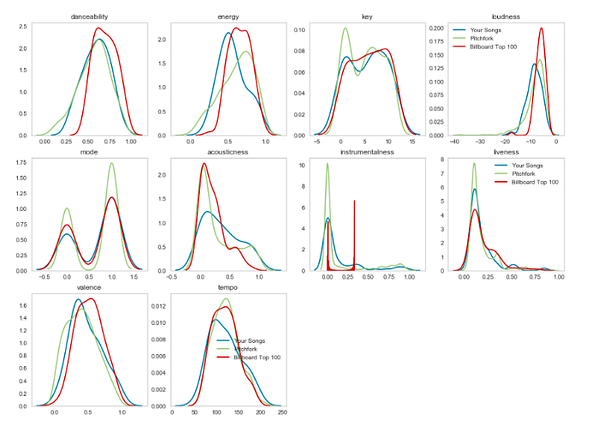
Я и Обама? Сравним мой музыкальный вкус со вкусом семейства Обама.

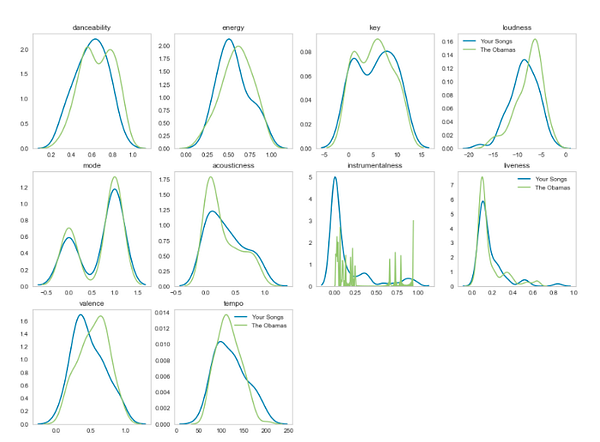
6. Собираем результаты в итоговый документ. Вот и всё!
Читайте также:
- Наглядное объяснение алгоритма Беллмана-Форда
- Выбор оптимального алгоритма поиска в Python
- 5 секретов наилучшего использования кортежей в Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Rita Pereira: My Spotify Journey towards a Recommendation System





