
Обширная экосистема Python содержит в себе пакеты, модули и библиотеки, которые можно использовать для создания собственных приложений. Некоторые пакеты и модули включены в Python по умолчанию, они известны как стандартная библиотека.
Стандартная библиотека состоит из модулей, предоставляющих стандартизованные решения для самых распространённых задач программирования. Они являются прекрасными строительными блоками для приложений во многих дисциплинах. Однако большинство разработчиков предпочитает альтернативные пакеты или расширения, облегчающие использование модулей стандартной библиотеки.
В этой статье вы познакомитесь с пакетами, которые авторы Real Python используют в качестве альтернативы тем, что предоставлены в стандартной библиотеке:
pudb: продвинутый графический отладчик с текстовым интерфейсом;requests: красивый API для HTTP-запросов;parse: интуитивно понятный, легко читаемый инструмент для поиска соответствия строк;dateutil: расширение популярной библиотекиdatetime;typer: интуитивно понятный парсер интерфейса командной строки.
Начнём с графической альтернативы pdb.
pudb для графической отладки
Я провожу много времени, работая на удалённых машинах через SSH, поэтому я не могу воспользоваться преимуществами большинства IDE. Мой отладчик — pudb с текстовым интерфейсом, который я нахожу интуитивно понятным и простым в использовании.
Python поставляется с pdb, разработанным на примере gdb, который в свою очередь вдохновлён dbx. Преимущество pdb в том, что он встроен в Python. Однако, поскольку он основан на командной строке, вам необходимо помнить множество горячих клавиш, а для просмотра доступна лишь небольшая часть кода.
Альтернативой является пакет pudb. Он отображает исходный код в полноэкранном режиме с полезной для отладки информацией. Также мне приятно было поностальгировать по тем временам, когда я писал на Turbo Pascal:
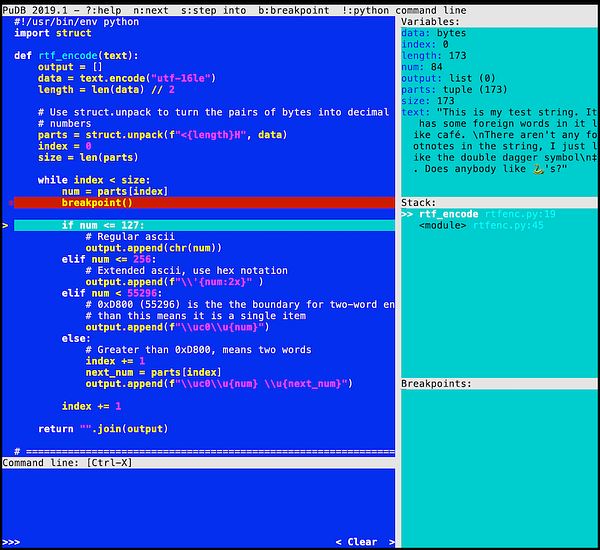
Интерфейс разделён на две основные части: левая панель для исходного кода, правая для контекстной информации. Правая панель в свою очередь делится на три части:
- Переменные.
- Стек.
- Контрольные точки.
Всё, что вам может пригодиться в отладчике, доступно на одном экране.
Взаимодействие с pudb
Устанавливаем pudb с помощью pip:
$ python -m pip install pudbПри использовании Python 3.7 и выше можно воспользоваться breakpoint(), задав в среде PYTHONBREAKPOINT значение переменной pudb.set_trace. В ОС на основе Unix, таких как Linux или macOS, зададим переменную так:
$ export PYTHONBREAKPOINT=pudb.set_traceВ Windows используем другую команду:
C:\> set PYTHONBREAKPOINT=pudb.set_traceИли можно вставить import pudb; pudb.set_trace() непосредственно в код.
Когда исполняемый код достигает контрольной точки, pudb прерывает выполнение и разворачивает интерфейс:
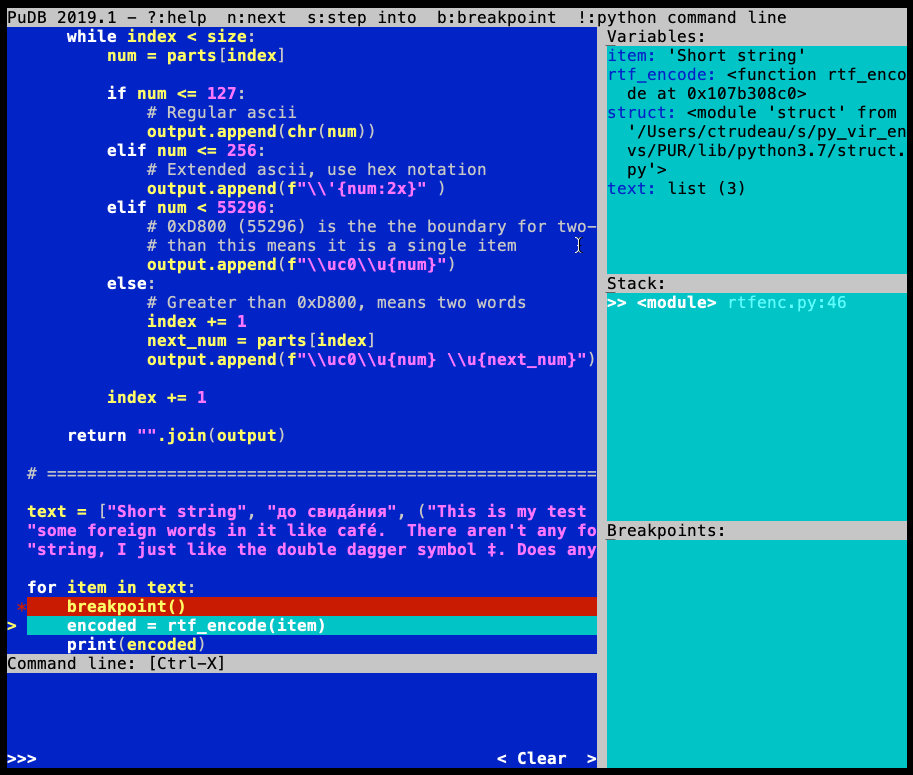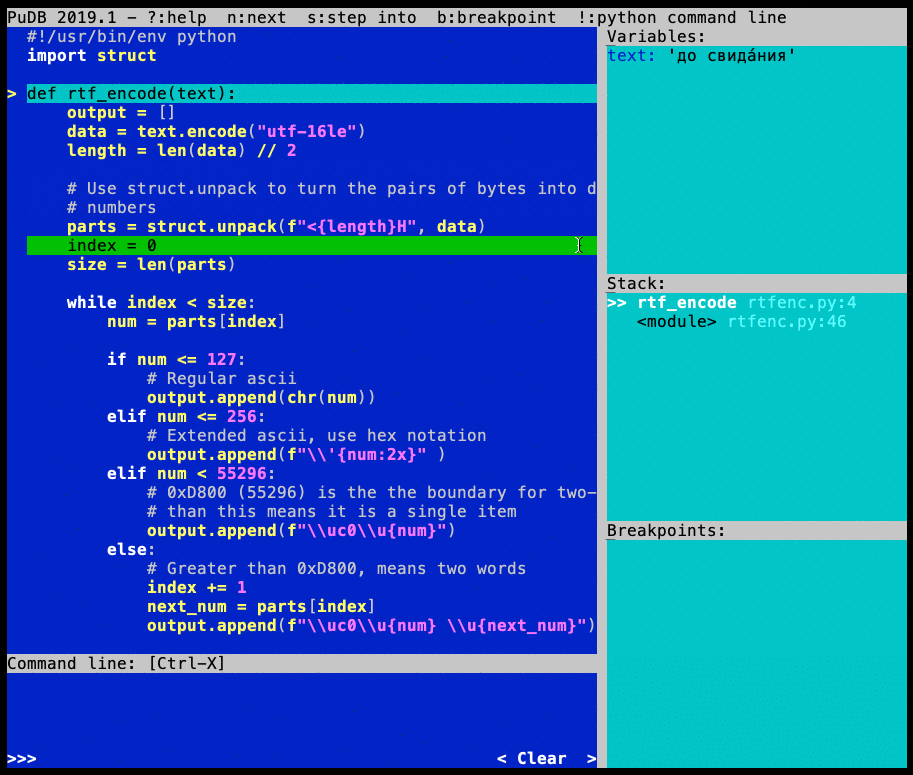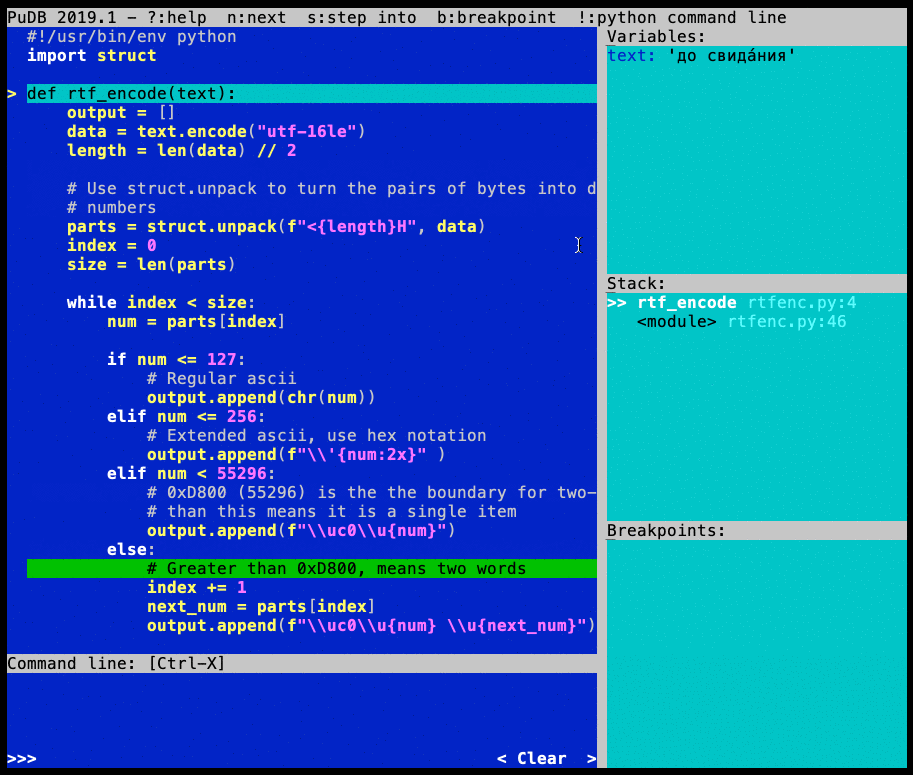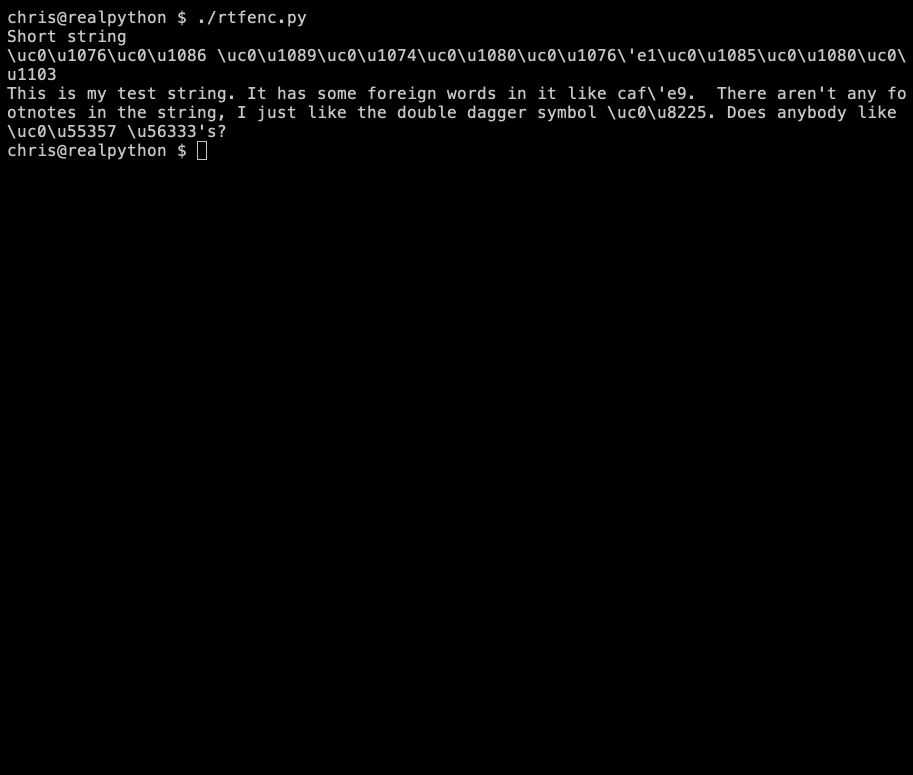
Перемещаться по исходному коду и выполнять его можно с клавиатуры:
UP или K — переместиться на одну строку вверх;
Down или J — переместиться на одну строку вниз;
Page Up или Ctrl + B— прокрутить страницу вверх;
Page Down или Ctrl + F — прокрутить страницу вниз;
N — выполнить текущую строку;
S— перейти на текущую строку, если это функция;
C — продолжать выполнение до следующей контрольной точки.
При перезапуске кода pudb запоминает контрольные точки предыдущей сессии. Right и Left позволяют перемещаться между исходным кодом и управляющим блоком справа.
Внутри раздела Переменные видны все переменные, находящиеся в области видимости в данный момент:

По умолчанию отображение переменных свёрнуто, но, нажав \, можно увидеть всё содержимое поля. В расширенном виде элементы отображаются кортежем, списком или полным содержимым двоичной переменной. T и R переключают режим визуального отображения между repr и type.
Использование контрольных выражений и доступ к REPL
Когда область Переменные в правом окне активна, можно добавить контрольное выражение. Контрольным может быть любое выражение Python. Эта функция полезна для изучения данных, скрытых глубоко внутри объекта, пока сам объект находится в свёрнутой форме, или для расчёта сложных отношений между переменными.
Примечание: контрольные выражения добавляются нажатием клавиши N. Так как N используется для выполнения текущей строки кода, перед нажатием клавиши убедитесь, что активна именно правая область экрана.
Нажатие ! переводит вас в режим REPL в контексте текущей запущенной программы. Этот режим также показывает любые выходные данные, отправленные на экран до запуска отладчика. Перемещаясь по интерфейсу с помощью горячих клавиш, можно настраивать контрольные точки, менять местоположение в стеке и загружать другие файлы исходного кода.
Чем хорош pudb
Интерфейс pudb требует от вас запоминать меньше горячих клавиш, чем pdb, кроме того он предназначен для отображения как можно большего объёма кода. В нём есть большинство функций отладчиков, которые можно найти в IDE, но при этом их можно использовать в терминале. Поскольку этот пакет легко устанавливается вызовом pip, его легко добавить в любую среду. Попробуйте, когда застрянете в командной строке!
requests для веб-взаимодействий
Один из моих фаворитов вне стандартной библиотеки Python — это популярный пакет requests. У него особый статус на моём компьютере, ведь это единственный внешний пакет, который я установил во всей системе. Все остальные пакеты живут в выделенных виртуальных средах.
И я не одинок в своём предпочтении requests для веб-взаимодействия: согласно его документации, этот пакет скачивают 1.6 миллионов раз в день! И эти цифры вполне оправданы, ведь программные веб-взаимодействия предлагают множество возможностей, будь то публикация записей через веб-API или выборка данных через веб-скрапинг. Но стандартная библиотека Python уже включает в себя пакет urllib для решения этих задач. Так зачем же использовать внешний пакет? Что делает requests столь популярным?
requests легко читается
Библиотека requests представляет собой хорошо разработанный API, который читается как обычный английский, в полном соответствии с идеологией Python. Разработчики requests кратко сформулировали эту идею в слогане “HTTP для людей”.
Используем pip для установки requests:
$ python -m pip install requestsДавайте рассмотрим, как requests справляется с читаемостью, используя его для доступа к тексту на сайте. Решая эту задачу с помощью браузера, мы выполняем следующие шаги:
- Открываем браузер.
- Вводим URL.
- Просматриваем текст.
Как добиться того же с помощью кода? Во-первых, разложим необходимые шаги в псевдокод:
- Импортируем необходимый инструмент.
- Получаем данные сайта.
- Отображаем текст сайта.
После пояснения логики, переводим псевдокод в Python с помощью библиотеки requests:

>>> import requests
>>> response = requests.get("http://www.example.com")
>>> response.textКод читается почти как обычный английский язык, он лаконичный и понятный. Хотя этот пример не намного сложнее реализовать с помощью пакета urllib стандартной библиотеки, requests поддерживает этот простой, ориентированный на человека синтаксис и в куда более сложных сценариях.
В следующем примере мы увидим, чего можно достичь буквально несколькими строками кода.
Сила requests
Давайте испытаем requests на более сложной задаче:
- Войдём в учётную запись GitHub.
- Сохраним эти учётные данные для обработки нескольких запросов.
- Создадим новый репозиторий.
- Создадим новый файл с некоторым содержимым.
- Запустим второй запрос, только если первый выполнен успешно.
Вызов принят, и задача успешно выполнена! Код ниже выполняет все необходимые действия. Нужно только заменить строки "YOUR_GITHUB_USERNAME" и "YOUR_GITHUB_TOKEN" на ваше имя пользователя GitHub и токен персонального доступа.
Примечание:чтобы создать токен персонального доступа, кликните на Generate new token и выберите область определения repo. Скопируйте сгенерированный токен и используйте для аутентификации вместе с вашим именем пользователя.
Прочтите фрагмент кода ниже, скопируйте и сохраните в ваш скрипт Python, заполните учётные данные и посмотрите на requests в действии:
import requests
session = requests.Session()
session.auth = ("YOUR_GITHUB_USERNAME", "YOUR_GITHUB_TOKEN")
payload = {
"name": "test-requests",
"description": "Created with the requests library"
}
api_url ="https://api.github.com/user/repos"
response_1 = session.post(api_url, json=payload)
if response_1:
data = {
"message": "Add README via API",
# 'content' должен быть строкой в кодировке base64,
# стандартная библиотека Python поможет с этим.
# Секрет этой испорченной строки можно раскрыть,
# загрузив её на GitHub с этим скриптом :)
"content": "UmVxdWVzdHMgaXMgYXdlc29tZSE="
}
repo_url = response_1.json()["url"]
readme_url = f"{repo_url}/contents/README.md"
response_2 = session.put(readme_url, json=data)
else:
print(response_1.status_code, response_1.json())
html_url = response_2.json()["content"]["html_url"]
print(f"See your repo live at: {html_url}")
session.close()После запуска кода пройдите по ссылке, выведенной в самом конце, и вы увидите новый репозиторий, созданный в вашем аккаунте GitHub. Новый репозиторий содержит файл README.md с текстом внутри; всё это сгенерировано скриптом выше.
Примечание: вы наверняка заметили, что код проходит аутентификацию только один раз, но всё ещё может отправлять множественные запросы. Это возможно потому, что объект requests.Session позволяет сохранять информацию для множественных запросов.
Как видим, короткий фрагмент кода выше способен на многое и всё ещё остаётся понятным.
Чем хороша requests
Библиотека Python request является одной из наиболее широко используемых внешних библиотек, благодаря своей читаемости, доступности и мощности для веб-взаимодействий.
parse для поиска соответствия строк
Я люблю регулярные выражения. С их помощью можно найти практически любой шаблон в заданной строке. Однако чем мощнее инструмент, тем сложнее с ним работать! Создание регулярных выражений требует множества проб и ошибок, а разобраться во всех тонкостях заданного регулярного выражения бывает ещё сложнее, чем его написать.
parse — это библиотека, обладающая мощностью регулярных выражений, но использующая более понятный и знакомый синтаксис. Коротко говоря, parse — это f-строки наоборот. По существу, вы можете просто использовать те же выражения для поиска и анализа строк, что и для их форматирования. Давайте рассмотрим, как это работает на практике.
Поиск строки по шаблону
Для примера нам нужен какой-нибудь текст. Используем PEP 498, оригинальную спецификацию f-строк. Текст документов Python Enhancement Proposal (PEP) можно загрузить с помощью маленькой утилиты pepdocs.
Устанавливаем parse и pepdocs из PyPI:
$ python -m pip install parse pepdocsЧтобы начать, скачаем PEP 498:
>>> import pepdocs>>> pep498 = pepdocs.get(498)Используя parse можно, к примеру, найти автора PEP 498:
>>> import parse>>> parse.search("Author: {}\n", pep498)<Result ('Eric V. Smith <eric@trueblade.com>',) {}>В данном случае parse.search() ищет шаблон во всей заданной строке. Также можно использовать parse.parse(), который сравнивает шаблон с целой строкой. Как и в f-строках используем фигурные скобки {} для указания переменных, которые хотим проанализировать.
Хотя можно использовать пустые фигурные скобки, чаще всего нужно добавлять имена к поисковым шаблонам. Имя и адрес электронной почты автора PEP 498 Эрика Смита можно выделить так:
>>> parse.search("Author: {name} <{email}>", pep498)<Result () {'name': 'Eric V. Smith', 'email': 'eric@trueblade.com'}>Этот код возвращает объект Result с информацией о совпадениях. Ко всем результатам поиска можно получить доступ, используя .fixed, .named и .spans. Для получения одного значения можно использовать []:
>>> result = parse.search("Author: {name} <{email}>", pep498)>>> result.named{'name': 'Eric V. Smith', 'email': 'eric@trueblade.com'}
>>> result["name"]'Eric V. Smith'
>>> result.spans{'name': (95, 108), 'email': (110, 128)}
>>> pep498[110:128]'eric@trueblade.com'.spans выдаёт совпадающие с шаблоном индексы строки.
Использование спецификаторов преобразования
Все совпадения с шаблоном можно найти, используя parse.findall(). Попробуем найти другие PEP, упомянутые в PEP 498:
>>> [result["num"] for result in parse.findall("PEP {num}", pep498)]
['p', 'd', '2', '2', '3', 'i', '3', 'r', ..., 't', '4', 'i', '4', '4']Выглядит не особо полезно. На PEP ссылаются по номерам. Поэтому, чтобы указать, что мы ищем числа, используем синтаксис формата:
>>> [result["num"] for result in parse.findall("PEP {num:d}", pep498)]
[215, 215, 3101, 3101, 461, 414, 461]Добавление :d говорит parse, что мы ищем целые числа. В качестве бонуса все результаты преобразуются из строк в числа. Кроме :d можно использовать большинство спецификаторов преобразования, используемых f-строками.
Используя специальные двухсимвольные спецификаторы, можно анализировать даты:
>>> parse.search("Created: {created:tg}\n", pep498)
<Result () {'created': datetime.datetime(2015, 8, 1, 0, 0)}>:tg ищет даты, написанные в формате день/месяц/год. Если порядок или формат другие, используйте :ti, :ta и другие опции.
Доступ к основным регулярным выражениям
parse построен поверх библиотеки регулярных выражений Python, re. Каждый раз при поиске parse скрыто создаёт соответствующее регулярное выражение. Если один и тот же поиск нужно выполнить несколько раз, регулярное выражение можно создать предварительно с помощью parse.compile.
В следующем примере отображены все описания ссылок на другие документы в PEP 498:
>>> references_pattern = parse.compile(".. [#] {reference}")
>>> for line in pep498.splitlines():
... if result := references_pattern.parse(line):
... print(result["reference"])
...
%-formatting
str.format
[ ... ]
PEP 461 rejects bytes.format()Цикл использует оператор “морж”, доступный в Python 3.8 и выше, для проверки каждой строки на соответствие заданному шаблону. Вы можете посмотреть на скомпилированный шаблон, чтобы увидеть регулярное выражение, скрывающееся за новыми возможностями поиска:
>>> references_pattern._expression'\\.\\. \\[#\\] (?P<reference>.+?)'Исходный шаблон parse — ".. [#] {reference}" — более прост и для чтения, и для записи.
Чем хорош parse
Регулярные выражения чрезвычайно удобны. Тем не менее про все их тонкости написано немало весьма увесистых книг. Небольшая библиотека parse предоставляет большинство возможностей регулярных выражений, но с гораздо более дружелюбным синтаксисом.
Сравните ".. [#] {reference}" и "\\.\\. \\[#\\] (?P<reference>.+?)", и вы сразу поймёте, почему я люблю parse даже больше, чем сами регулярные выражения.
dateutil для работы с датами и временем
Если вы когда-либо программировали что-то, связанное со временем, вы в курсе, что здесь легко запутаться. Во-первых, приходится справляться с часовыми поясами, помня, что в двух разных точках на Земле разное время в один и тот же момент. Затем есть сложности с переходом на летнее время: событием, происходящим дважды в год или не происходящим вовсе, но только в определённых странах.
Также приходится учитывать високосные годы и високосные секунды, чтобы синхронизировать часы с вращением Земли вокруг Солнца. Вы вынуждены программировать с учётом проблем 2000 года и 2038 года. Список можно продолжать бесконечно.
К счастью, в стандартную библиотеку Python включён действительно полезный модуль datetime, помогающий удобно хранить и получать доступ к информации о дате и времени. Однако в некоторых случаях интерфейс datetime не так хорош.
Прекрасное сообщество Python разработало несколько различных библиотек и API для осмысленной работы с датами и временем. Некоторые из них расширяют встроенную datetime, другие заменяют её полностью. Моя любимая библиотека — это dateutil.
Чтобы следовать приведённым ниже примерам, установите dateutil:
$ python -m pip install python-dateutilТеперь рассмотрим все возможности dateutil на примерах, а также её взаимодействие с datetime.
Устанавливаем часовой пояс
У dateutil есть пара функций для этого. Во-первых, в дополнение к datetime для работы с часовыми поясами и переходом на летнее время в документации Python рекомендовано использовать tz.
>>> from dateutil import tz
>>> from datetime import datetime
>>> london_now = datetime.now(tz=tz.gettz("Europe/London"))
>>> london_now.tzname() # 'BST' in summer and 'GMT' in winter
'BST'Но dateutil способен на куда большее, чем просто предоставление конкретного экземпляра tzinfo. Это настоящая удача, поскольку после Python 3.9 стандартная библиотека Python будет содержать собственную возможность доступа к базе данных IANA.
Анализ строк даты и времени
dateutil значительно упрощает анализ строк в экземплярах datetime с помощью модуля parser:
>>> from dateutil import parser
>>> parser.parse("Monday, May 4th at 8am") # May the 4th be with you!
datetime.datetime(2020, 5, 4, 8, 0)Имейте в виду, что dateutil автоматически определяет год для этой даты, даже если вы его не указали! Интерпретацию и добавление часовых поясов можно контролировать с помощью parser или работы с датами в формате ISO-8601. Эта библиотека даёт вам значительно больше гибкости, чем datetime.
Вычисление разницы во времени
Ещё одна прекрасная функция dateutil — это модуль relativedelta, способный рассчитывать время. Вы с лёгкостью можете добавить или вычесть произвольные единицы времени из экземпляра datetime или вычислить разницу между двумя экземплярами datetime:
>>> from dateutil.relativedelta import relativedelta
>>> from dateutil import parser
>>> may_4th = parser.parse("Monday, May 4th at 8:00 AM")
>>> may_4th + relativedelta(days=+1, years=+5, months=-2)
datetime.datetime(2025, 3, 5, 8, 0)
>>> release_day = parser.parse("May 25, 1977 at 8:00 AM")
>>> relativedelta(may_4th, release_day)
relativedelta(years=+42, months=+11, days=+9)Эта функция куда гибче datetime.timedelta, потому что вы можете задавать более длинные, чем день, интервалы, например месяц или год.
Расчёт повторяющихся событий
И напоследок крутой модуль rrule для вычисления дат в будущем в соответствии с iCalendar RFC. Скажем, нам нужно создать регулярное расписание на июнь с событиями, происходящими в 10:00 по понедельникам и пятницам:
>>> from dateutil import rrule
>>> from dateutil import parser
>>> list(
... rrule.rrule(
... rrule.WEEKLY,
... byweekday=(rrule.MO, rrule.FR),
... dtstart=parser.parse("June 1, 2020 at 10 AM"),
... until=parser.parse("June 30, 2020"),
... )
... )
[datetime.datetime(2020, 6, 1, 10, 0), ..., datetime.datetime(2020, 6, 29, 10, 0)]Имейте в виду, что необязательно знать, являются ли начальная и конечная даты понедельниками или пятницами — dateutil вычислит это за вас. Ещё один способ применения rrule — это расчёт даты с конкретными параметрами. Давайте вычислим, когда в следующий раз 29 февраля выпадет на субботу как в 2020 году:
>>> list(
... rrule.rrule(
... rrule.YEARLY,
... count=1,
... byweekday=rrule.SA,
... bymonthday=29,
... bymonth=2,
... )
... )
[datetime.datetime(2048, 2, 29, 22, 5, 5)]Это произойдёт в 2048. В документации dateutil есть множество примеров и упражнений.
Чем хорош dateutil
Мы рассмотрели четыре функции dateutil, которые делают вашу работу с настройками времени проще:
- Удобный способ установки часовых поясов, совместимый с объектами
datetime. - Удобный метод преобразования строк в даты.
- Мощный интерфейс для расчёта времени.
- Прекрасный метод расчёта повторяющихся или будущих событий.
Попробуйте dateutil, если вы устали от настройки времени.
typer для анализа в интерфейсе командной строки
Разработчики Python часто начинают анализ CLI с модуля sys; sys.argv можно использовать для получения списка аргументов, который пользователь передаёт в скрипт:
# command.py
import sys
if __name__ == "__main__":
print(sys.argv)Имя скрипта и аргументов, введённых пользователем, выводятся в виде строковых значений в sys.argv:
$ python command.py one two three
["command.py", "one", "two", "three"]
$ python command.py 1 2 3
["command.py", "1", "2", "3"]Однако с добавлением функций к скрипту вам может понадобиться более глубокий анализ аргументов, управление аргументами разных типов или более понятное информирование пользователя о доступных вариантах.
argparse хороший, но громоздкий
Встроенный модуль Python argparse помогает создавать именованные аргументы, приводить пользовательские значения к соответствующим типам данных и автоматически создавать справочное меню для скрипта.
Одним из преимуществ argparse является то, что аргументы CLI можно задавать более декларативным образом, сокращая изрядное количество процедурного и условного кода.
Рассмотрим следующий пример, в котором sys.argv используется для вывода введённой пользователем строки заданное число раз с минимальной обработкой пограничных случаев:
# string_echo_sys.py
import sys
USAGE = """
USAGE:
python string_echo_sys.py <string> [--times <num>]
"""
if __name__ == "__main__":
if len(sys.argv) == 1 or (len(sys.argv) == 2 and sys.argv[1] == "--help"):
sys.exit(USAGE)
elif len(sys.argv) == 2:
string = sys.argv[1] # Первый аргумент после имени скрипта
print(string)
elif len(sys.argv) == 4 and sys.argv[2] == "--times":
string = sys.argv[1] # Первый аргумент после имени скрипта
try:
times = int(sys.argv[3]) # Аргумент после --раз
except ValueError:
sys.exit(f"Invalid value for --times! {USAGE}")
print("\n".join([string] * times))
else:
sys.exit(USAGE)Этот код предоставляет пользователям способ получить полезную документацию об использовании скрипта:
$ python string_echo_sys.py --help
USAGE:
python string_echo_sys.py <string> [--times <num>]Пользователи могут предоставить строку и количество выводов строки (опционально):
$ python string_echo_sys.py HELLO! --times 5
HELLO!
HELLO!
HELLO!
HELLO!
HELLO!Чтобы добиться того же с помощью argparse, можно написать что-то вроде:
# string_echo_argparse.py
import argparse
parser = argparse.ArgumentParser(
description="Echo a string for as long as you like"
)
parser.add_argument("string", help="The string to echo")
parser.add_argument(
"--times",
help="The number of times to echo the string",
type=int,
default=1,
)
if __name__ == "__main__":
args = parser.parse_args()
print("\n".join([args.string] * args.times))Код argparse более описательный, кроме того, argparse предоставляет полный анализ аргументов, а функция --help объясняет использование скрипта — всё совершенно бесплатно.
И хотя argparse значительно лучше непосредственного использования sys.argv, он всё ещё требует думать о парсинге CLI. А вы обычно думаете над тем, чтобы написать полезный скрипт, и не хотите впустую тратить силы на парсинг CLI!
Чем хорош typer
typer предоставляет несколько функций, аналогичных функциям argparse, но основывается на совершенно другой парадигме разработки. Вместо написания декларативной, процедурной или условной логики для парсинга пользовательского ввода, typer выгодно использует подсказки при вводе кода для анализа и создания CLI, поэтому вам не приходится тратить много усилий на обдумывание пользовательского ввода.
Начнём с установки typer из PyPI:
$ python -m pip install typerТеперь можно написать скрипт, выполняющий ту же задачу, что и в примере с argparse:
# string_echo_typer.py
import typer
def echo(
string: str,
times: int = typer.Option(1, help="The number of times to echo the string"),
):
"""Echo a string for as long as you like"""
typer.echo("\n".join([string] * times))
if __name__ == "__main__":
typer.run(echo)Этот подход использует ещё меньше функциональных строк, и в этих строках основное внимание уделено функциям скрипта. Тот факт, что скрипт повторяет строку несколько раз, здесь более очевиден.
typer даже предоставляет пользователям возможность создавать заполнение для оболочек нажатием клавиши Tab, чтобы использование CLI скрипта было ещё быстрее.
Я люблю typer за лаконичность и эффективность.
Заключение: пять полезных пакетов Python
Сообщество Python разработало множество прекрасных пакетов. В этой статье мы рассмотрели некоторые из них, используемые как альтернатива обычным пакетам стандартной библиотеки Python или в качестве их расширений.
Мы разобрались:
- Как
pudbможет помочь в отладке кода. - Как
requestsможет улучшить взаимодействие с веб-сервисами. - Как использование
parseупрощает сопоставление строк. - Что функция
dateutilпредлагает для работы с датами и временем. - Почему стоит использовать
typerдля парсинга аргументов командной строки.
Читайте также:
- Встроенная база данных Python
- Идиоматический Python для новичков
- Пространства имен и области видимости в Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи RealPython: Python Packages: Five Real Python Favorites




