
Определение
Приставка “микро” в термине микросервисы является не только показателем размера сервиса. При переходе на архитектуру микросервисов команды стремятся повысить свою подвижность, а именно получить возможность внедрять функционал автономно и часто. Для этого архитектурного стиля трудно сформулировать одно краткое определение. Мне понравился вариант, предложенный Адрианом Кокрофтом: “сервис-ориентированная архитектура, состоящая из слабо сцепленных элементов, имеющих ограниченный контекст.”
Несмотря на то, что это определяет эвристику высокоуровневого дизайна, архитектура микросервисов имеет уникальные характеристики, отличающие её от устоявшейся сервис-ориентированной архитектуры. Некоторые из этих характеристик приведены ниже. Кстати, для них и некоторых других имеется хорошая документация.
- У сервисов есть чётко определённые границы, сосредоточенные вокруг контекста бизнеса, а не произвольных технических абстракций.
- Детали реализации должны быть скрыты, а функциональность демонстрируется через информативные интерфейсы.
- Сервисы не демонстрируют внутреннюю структуру за пределами своих границ. Например, не предоставляют доступа к базам данных.
- Сервисы устойчивы к сбоям.
- В распоряжении каждой команды есть собственная функциональность и возможность автономного выпуска изменений.
- В командах прививается культура автоматизации. Например, автоматическое тестирование, непрерывная интеграция и непрерывная поставка приложений.
Коротко и ёмко можно определить этот архитектурный стиль так:
Слабо сцепленная сервис-ориентированная архитектура, где каждый сервис заключен внутри грамотно определённого ограниченного контекста и позволяет быстро, часто и надёжно поставлять приложения.
Предметно-ориентированное проектирование (DDD) и ограниченный контекст
Преимущества микросервисов происходят из ясного определения их задачи и установки между ними границ. В этом случае целью является создание сильной связности внутри границ и слабого зацепления за их пределами. Это значит, что элементы, предполагающие совместное изменение, должны располагаться вместе. Как и во многих реальных задачах, на деле это осуществить сложнее, чем на словах — бизнес развивается и условия меняются. Поэтому способность к рефакторингу является ещё одним важным критерием при выборе системы проектирования.
Предметно-ориентированное проектирование — это ключевое средство при построении микросервисов, независимо от того разбивка ли это монолитной системы или же реализация нового проекта. Этот вид проектирования, получивший известность благодаря книге Эрика Эванса, представляет набор идей, принципов и паттернов, помогающих проектировать ПО, отталкиваясь от основополагающей области действия бизнеса. Разработчики тесно сотрудничают с экспертами в предметной области бизнеса, создавая бизнес-модели на едином языке. После этого они привязывают эти модели к подходящим системам, устанавливают протоколы взаимодействия между этими системами и командами, работающими над сервисами. Самое важное здесь то, что они проектируют концептуальные границы вокруг таких систем.
Проектирование микросервисов опирается на эти принципы, поскольку все они помогают создать модульные системы, которые могут изменяться и развиваться независимо друг от друга.
Прежде чем продолжить, давайте вкратце пробежимся по некоторым из основных технологий DDD. Полный обзор предметно-ориентированного проектирования выходит за рамки этой статьи, и мы рекомендуем обратиться к соответствующей литературе для более подробного ознакомления.
Область: представляет предметную область деятельности организации. В примере ниже это будет розничная торговля (Retail) и электронная коммерция (eCommerce). Область составляется из нескольких подобластей.
Подобласть: подразделение организации.
Единый язык: язык выражения моделей. В примере ниже Item является моделью, относящейся к единому языку каждой из этих подобластей. Разработчики, менеджеры по продукту, эксперты предметной области и управляющее звено организации устанавливают один язык и используют его во всех артефактах — в коде, документации продукта и т.д.
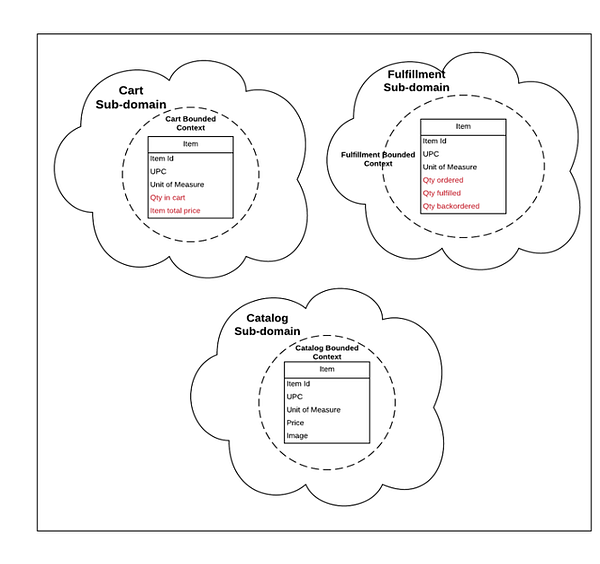
Ограниченный контекст. Предметно-ориентированное проектирование определяет ограниченный контекст так: “Установка, в которой появляется слово или фраза, определяющая её значение”. Говоря коротко, это означает границу, внутри которой модель имеет смысл. В примере выше “Item” принимает различное значение в каждом из вариантов контекста. В контексте Catalog Item означает продаваемый продукт, а в контексте Cart оно означает предмет хранилища, который отправляется клиенту. Каждая из этих моделей своеобразна, имеет различное значение и, скорее всего, содержит разные атрибуты. Разделяя и изолируя эти модели внутри соответствующих им границ, мы можем легко и без двусмысленности выражать модели.
На заметку: важно понимать разницу между подобластями и ограниченным контекстом. Подобласть принадлежит к пространству задачи и определяет то, как эту задачу видит ваш бизнес. Ограниченный контекст принадлежит к пространству решения и определяет то, как мы реализуем решение задачи. Теоретически каждая подобласть может иметь несколько ограниченных контекстов, хотя мы стремимся, чтобы для одной подобласти он был один.
Как микросервисы относятся к ограниченному контексту
Итак, где же тут уместны микросервисы? Верно ли считать, что каждый ограниченный контекст отображается в микросервис? И да, и нет. Бывают случаи, когда граница вашего контекста весьма обширна.
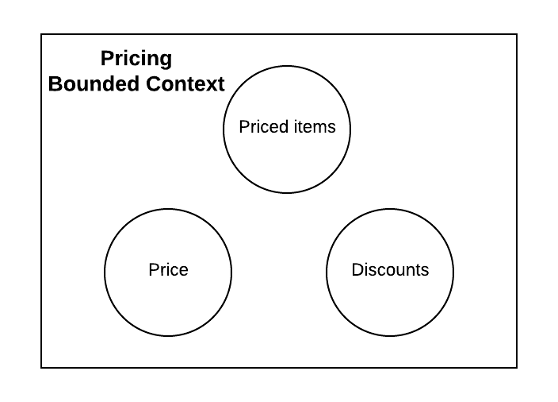
Рассмотрим пример выше. Ограниченный контекст Pricing (ценообразование) имеет три раздельные модели: Price (цена), Priced items (сумма за товары) и Discounts (скидки). Они отвечают за цену товара в каталоге, вычисление суммы списка товаров и применение скидки соответственно. Мы можем создать единую систему, охватывающую все вышеперечисленные модели, но тогда приложение получится неоправданно большим. Как упоминалось ранее, каждая модель данных имеет инварианты и бизнес-правила. Если же мы не будем осторожны, то с течением времени структура системы может стать неразборчивой, зоны задач пересекутся, и в конце концов вся она вернётся к своему изначальному монолитному состоянию.
Ещё один способ моделирования приведённой системы — это разделение или группирование связанных моделей в раздельные микросервисы. В DDD эти модели Price, Priced items и Discounts называются агрегатами. Агрегат — это автономная модель, которая объединяет связанные модели. Состояние агрегата можно изменить только через опубликованный интерфейс. Сам же агрегат обеспечивает согласованность и то, что инварианты останутся действительны.
Формально агрегат является кластером связанных объектов, рассматриваемых как единица для изменения данных. Внешние ссылки ограничены одним членом агрегата, определённым в качестве корня. В рамках границ агрегата применяется набор правил согласованности.
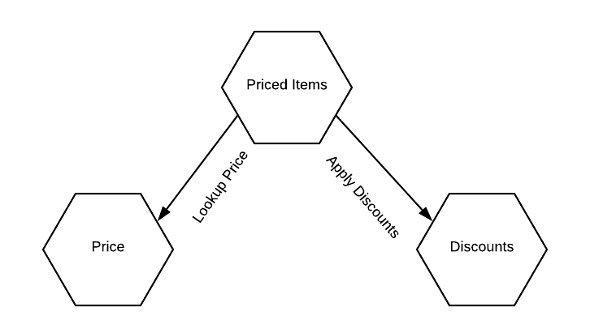
И снова нет необходимости моделировать каждый агрегат как отдельный микросервис. Для сервисов (агрегатов) на Рис. 3 это потребовалось, но правилом при этом не является. В некоторых случаях может оказаться более разумным разместить несколько агрегатов в одном сервисе, особенно, когда мы не до конца понимаем предметную область бизнеса. Важно помнить, что согласованность можно гарантировать только внутри одного агрегата, и агрегаты могут быть изменены только через опубликованный интерфейс. Любое нарушение этих утверждений несёт риск получения системы с нераспознаваемой структурой (так называемого кома грязи).
Карты контекстов — способ аккуратно разметить границы микросервисов
Ещё один важный набор инструментов для вашего арсенала — это принцип карт контекстов, который также происходит из предметно-ориентированного проектирования. Обычно монолит состоит из несопоставимых моделей, которые по большей части тесно сцеплены — могут знать внутренние подробности друг друга, изменение одной может вызвать побочные эффекты в другой и т.д. При разделении такого монолита очень важно распознать эти модели (в данном случае агрегаты), а также их связи. Карты контекстов помогают нам это сделать. Они используются для распознания и определения связей между различными ограниченными контекстами и агрегатами. В то время как в примере выше ограниченные контексты определяют границы моделей — Price, Discounts и т.д., карты контекстов определяют связи между этими моделями и между разными контекстами. После выявления этих зависимостей мы можем подобрать подходящую модель взаимодействия между командами, которые будут эти сервисы реализовывать.
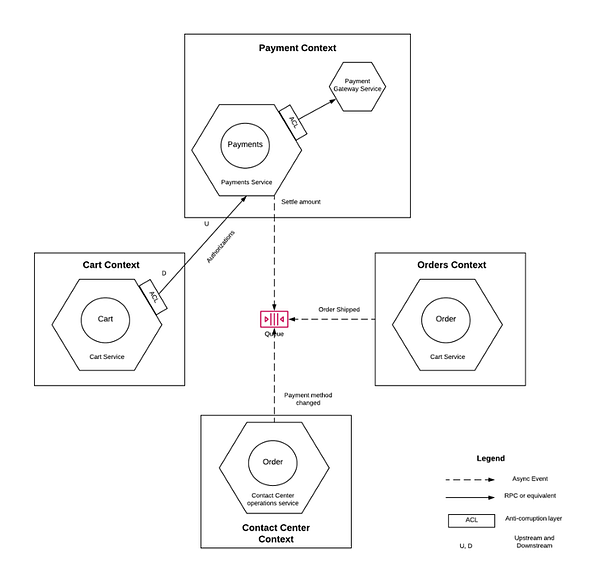
Полное объяснение карт контекстов выходит за рамки текущей статьи, но мы продемонстрируем их на примере. Диаграмма снизу представляет различные приложения, обрабатывающие платежи для электронного заказа.
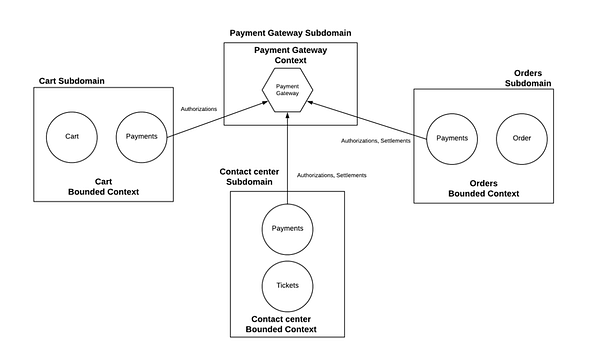
- Контекст Cart (корзина) отвечает за онлайн-авторизацию заказа. Контекст Order обрабатывает платёжные процессы после выполнения, например Settlements (расчёты). Contact center (контактный центр) обрабатывает любые исключения вроде повторных платежей и изменения способа оплаты заказа.
- Для простоты давайте предположим, что все эти контексты реализованы в виде раздельных сервисов.
- Все эти контексты заключают в себе одну модель.
- Обратите внимание, что логически эти модели одинаковы, т.е. все они следуют единому языку области — payment methods (способы оплаты), autorizations (авторизации) и settlements (расчёты). Просто они являются частью разных контекстов.
Ещё одним показателем того, что в нескольких контекстах задействована одна и та же модель является то, что все они интегрируются напрямую с единым payment gateway (платёжным шлюзом) и выполняют одинаковые операции.
Переопределение границ сервисов — отображение агрегатов в правильные контексты
В вышеприведённом дизайне присутствует несколько весьма очевидных недочётов (Рис. 4). Агрегат Payments является частью нескольких контекстов. Нельзя обеспечить соблюдение инвариантов и согласованности между разными сервисами, не говоря уже о проблемах конкурентности между ними. Например, что произойдёт, если контактный центр изменит способ оплаты, связанный с заказом, в то же время, когда служба заказов (Orders) будет пытаться произвести расчёт по способу оплаты, представленному ранее? Кроме того, обратите внимание, что любые изменения в платёжном шлюзе вызовут изменения в нескольких сервисах и возможно во многих командах, поскольку эти контексты могут принадлежать разным группам.
С помощью некоторых подстроек и присоединения агрегатов к правильным контекстам, мы получаем лучшее представление этих подобластей — Рис. 5. Давайте рассмотрим изменения:
- Агрегат Payments теперь размещается в новом месте — сервисе Payments. Этот сервис также абстрагирует Payment gateway (платёжный шлюз) от других сервисов, требующих платёжные сервисы. Поскольку агрегат теперь располагается в одном ограниченном контексте, инвариантами проще управлять. Все транзакции происходят внутри одной и той же границы сервиса, что позволяет избежать проблем с конкурентностью.
- Агрегат Payments использует уровень защиты от повреждений (Anti-corruption Layer [ALC]) для изолирования модели корневой области от модели данных платёжного шлюза, который, как правило, предоставляется сторонним провайдером и, скорее всего, будет изменяться. Слой ACL обычно содержит адаптеры, трансформирующие модель данных платёжного шлюза в модель данных агрегата Payments.
- Сервис Cart вызывает сервис Payments через прямые вызовы API, поскольку сервису Cart может потребоваться завершить авторизацию платежа, пока клиент ещё находится на сайте.
- Обратите внимание на взаимодействие между сервисами Orders и Payments. Первый отправляет событие области (подробнее о нём будет рассказано далее). Второй же прослушивает это событие и завершает расчёты заказа.
- Сервис контактного центра может иметь много агрегатов, но нас в данном случае интересует только агрегат Orders. При изменении способа оплаты этот сервис отправляет событие, и сервис Payments реагирует на него, сменяя ранее использованную кредитную карту на новую и обрабатывая уже её.
Обычно монолитное или устаревшее приложение содержит множество агрегатов с зачастую перехлёстывающимися границами. Создание карты контекстов этих агрегатов и их зависимостей помогает понять контуры любых новых микросервисов, которые мы будем вычленять из этих монолитов. Помните, что успех или провал архитектуры микросервисов основывается на низком зацеплении между агрегатами и высокой связности внутри них самих.
Важно также отметить, что ограниченные контексты сами по себе являются подходящими связными единицами. Даже если у контекста есть несколько агрегатов, весь контекст наряду с его агрегатами может быть объединён в один микросервис. Мы находим эту эвристику конкретно применимой для несколько размытых областей — в качестве примера можно представить новое направление бизнеса, которое начинает развивать организация. Вы можете не иметь достаточного представления о правильном разделении границ, и любая незрелая композиция агрегатов может привести к дорогостоящему рефакторингу. Представьте необходимость слияния двух баз данных наряду с переносом данных по причине обнаружения взаимной принадлежности двух агрегатов. Но при этом нужно обеспечить достаточную изоляцию этих агрегатов через интерфейсы, чтобы они не знали запутанных деталей друг друга.
Штурм событий — ещё одна техника для выявления границ сервисов
Штурм событий (Event Storming)— это ещё одна существенная техника для выявления агрегатов (и тем самым микросервисов) в системе. Это полезный инструмент как для разбивки монолитов, так и для проектирования сложных экосистем микросервисов. Мы использовали эту технику для разбивки одного из наших сложных приложений.
Если говорить кратко, то штурм событий — это коллективное обсуждение между командами, работающими над приложением (в нашем случае над монолитом). Целью этого обсуждения ставится выявление различных событий области и происходящих внутри системы процессов. Команды определяют агрегаты или модели, на которые влияют эти события, а также любые последующие воздействия. Помимо перечисленного в процессе обсуждения также выявляются различные принципы наложения, двусмысленный язык области и конфликтующие бизнес-процессы. Команды группируют связанные модели, переопределяют агрегаты и выявляют повторяющиеся процессы. К завершению обсуждения ограниченные контексты, к которым принадлежат эти агрегаты, становятся ясны. Митинги по штурму событий полезны, когда все команды собираются в одном пространстве — физическом или виртуальном — и начинают отображать события, команды и процессы на лекционной доске в стиле scrum. В завершении этого мероприятия, как правило, получаются следующие итоги:
- Переопределённый список агрегатов, которые потенциально становятся новыми микросервисами.
- Выясняются события области, которые должны циркулировать между этими микросервисами.
- Определяются команды, которые являются прямыми вызовами от других приложений или пользователей.
Ниже приведён пример лекционной доски в завершении митинга по штурму событий. Это отличное упражнение по сотрудничеству для команд, в котором они приходят к согласию по поводу правильных агрегатов и ограниченных контекстов. Помимо отличного сплачивающего эффекта такие семинары позволяют сформировать общее понимание предметной области, единого языка и точных границ сервисов.

Взаимосвязь микросервисов
Коротко говоря, монолит вмещает в себя множество агрегатов в рамках границ одного процесса. Благодаря этому становится возможным согласованное управление этими агрегатами. Например, если Customer (клиент) оформляет Order (заказ), мы можем уменьшить Inventory (учётное количество) предметов и отправить письмо клиенту в одной транзакции. Операции либо все завершатся успехом, либо все провалятся. Но поскольку мы разбиваем монолит и распространяем агрегаты по разным контекстам, то у нас получатся десятки или даже сотни микросервисов. Процессы, которые до этого существовали внутри одной границы монолита теперь распространены по нескольким распределённым системам. Добиться транзакционной целостности и согласованности между всеми этими распределёнными системами весьма непросто, и у этого есть своя цена, а именно — доступность систем.
Микросервисы также являются распределёнными системами. Поэтому теорема CAP применяется и к ним: “распределённая система может предоставить только две из трёх желаемых характеристик: согласованность, доступность и устойчивость к разделению”. В реальных системах устойчивость к разделению не обсуждается — сеть ненадёжна, виртуальные машины могут выйти из строя, задержка между областями может увеличиться и так далее.
В итоге мы остаёмся перед выбором между доступностью и согласованностью. Как мы знаем, пожертвовать доступностью в любом современном приложении тоже будет явно плохой идеей.
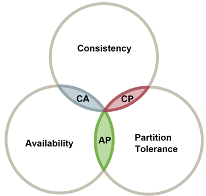
Проектирование приложений вокруг согласованности в конечном счёте
Если вы попытаетесь наладить транзакции между несколькими распределёнными системами, то в итоге снова получите монолит. Только на этот раз это будет его наихудший вариант — распределённый монолит. Если любая из систем станет недоступна, то и весь процесс станет недоступен, что зачастую приведёт к неприятному пользовательскому опыту, нарушенным обещаниям и так далее. Кроме того, изменения в одном сервисе, как правило, могут повлечь за собой изменения в другом, что приведёт к сложным и дорогостоящим процессам развёртывания. Поэтому нам лучше проектировать приложения, соответствующие нашим случаям использования, так, чтобы они допускали небольшую долю несогласованности в угоду широкой доступности. Что касается примера выше, то мы можем сделать все процессы асинхронными и тем самым согласованными. Мы можем отправлять электронные письма асинхронно и независимо от других процессов. Если обещанного предмета позже не окажется на складе, то заказ по нему может быть отменён или же мы можем установить ограничение на количество принимаемых на него заказов.
Иногда вы можете столкнуться со сценарием, требующим строгих транзакций по правилам ACID между двух агрегатов в разных границах процесса. Это отличный признак того, что нужно рассмотреть эти агрегаты и, вероятно, объединить их в один. Штурм событий и карты контекстов помогут выявить эти зависимости до того, как мы начнём разбивать агрегаты в разные границы процесса. Слияние двух микросервисов в один — достаточно дорогостоящий процесс, и его лучше избегать.
Оценка событийно-ориентированной архитектуры
Микросервисы могут отправлять происходящие с их агрегатами важные изменения, называемые событиями области. Благодаря этому любые заинтересованные сервисы могут прослушивать эти события, производя соответствующие действия внутри собственных областей. Этот метод избегает как любого поведенческого зацепления — одна область не предписывает действия для других, так и любого случайного зацепления — успешное завершение процесса не требует единовременной доступности всех систем. Это, конечно же, означает, что системы будут согласованы в конечном счёте.
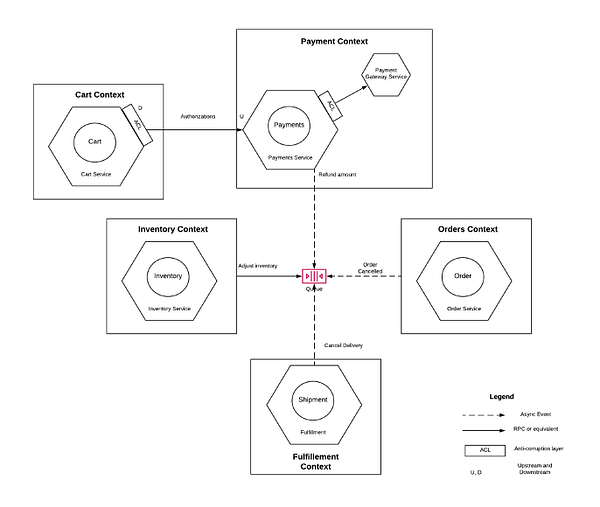
В примере выше сервис Orders публикует событие — Order Cancelled (заказ отменён). Другие сервисы, подписавшиеся на событие, обрабатывают свои соответствующие функции области: сервис Payment возвращает деньги, сервис Inventory исправляет учётное число предметов и так далее. Чтобы убедиться в надёжности и отказоустойчивости этой интеграции следует учесть следующее:
- Отправители событий должны обеспечить генерацию события по меньшей мере один раз. Если в этом процессе происходят сбои, они должны обеспечить механизм отката для повторной активации события.
- Получатели, в свою очередь, должны обеспечить получение событий идемпотентным способом. Если одно и то же событие повторится, на стороне получателя не должно возникнуть побочных эффектов. События могут также поступать не по порядку, поэтому получатели могут использовать поля временных меток или нумерации версий, чтобы гарантировать уникальность поступающих событий.
Не всегда представляется возможным использование основанной на событиях интеграции по причине внутренней сути некоторых случаев. Взгляните на интеграцию между сервисами Cart и Payment. Это асинхронная интеграция, и поэтому в ней есть кое-что, за чем стоит понаблюдать. Это пример двух вариантов зацепления: поведенческого, в котором Cart вызывает REST API из сервиса Payment и просит его авторизовать платёж по заказу, и случайного — сервис Payment должен быть доступен для того, чтобы сервис Cart принял заказ. Такой вид зацепления снижает автономность этих контекстов и может оказаться нежелательной зависимостью. Такого зацепления можно избежать несколькими способами, но при любом их них мы утратим способность предоставлять получателям мгновенную обратную связь.
- Преобразовать REST API в событийно-ориентированную интеграцию. Однако этот вариант может быть недоступен, если сервис Payment представляет только REST API.
- Сделать так, чтобы сервис Cart принимал заказ мгновенно, а пакетное задание собирало заказы и вызывало API сервиса Payment.
- Сделать так, чтобы сервис Cart генерировал локальное событие, которое затем вызывало бы API сервиса Payment.
В случае сбоев и недоступности восходящей зависимости (сервиса Payment) комбинация перечисленных вариантов может послужить основой более отказоустойчивого дизайна. Например, синхронную интеграцию между сервисами Cart и Payment на случай сбоев можно подстраховать событием или повторными попытками, выполняемыми пакетным заданием. Такой подход окажет дополнительное воздействие на UX, например клиенты могут ввести ошибочные платёжные данные, а при дальнейшей обработке платежа офлайн этого клиента уже может не быть в сети. Коротко говоря, приходится идти на компромиссы между UX, отказоустойчивостью и эксплуатационными расходами. При этом важно, чтобы в системах проектирования эти компромиссы были учтены.
Избегайте оркестрации между сервисами, снабжающими потребителей данными
Один из главных антишаблонов в любой сервис-ориентированной архитектуре — ситуация, когда сервисы обслуживают конкретные шаблоны доступа потребителей. Обычно это происходит, когда команды клиентской стороны тесно раюотают с командами сервисов. Если команда работала над монолитным приложением, то могла создать единый API, пресекающий границы различных агрегатов, тем самым тесно сцепляя их. Предположим, что странице Order Details (детали заказа) в веб- и мобильных приложениях нужно показать детали как самого Order, так и детали процесса возврата средств по нему на одной странице. В монолитном приложении Order GET API (предположим, что это REST API) запрашивает Orders и Refunds вместе, консолидирует оба агрегата и отправляет составной ответ вызывающему. Это можно сделать без лишней траты ресурсов, поскольку агрегаты находятся в одной и той же границе процесса. Таким образом, получателям может быть передана вся необходимая информация в одном вызове.
Если Orders и Refunds относятся к разным контекстам, то данные больше не будут присутствовать в одном микросервисе или границах агрегата. Одним из способов сохранить ту же самую функциональность для клиентов будет сделать сервис Order ответственным за вызов сервиса Refunds и создать составной ответ. Такой подход вызывает ряд проблем:
- Сервис Order теперь интегрируется с другим сервисом только для поддержки клиентов, нуждающихся в данных о Refunds наряду с данными их заказа. Сервис Order теперь менее автономен, поскольку любые изменения в агрегате Refunds приведут к изменениям агрегата Order.
- Сервис Order имеет ещё одну интеграцию, и поэтому ещё одну точку сбоя, которую нужно брать в расчёт — если сервис Refunds упадёт, то сможет ли сервис Order продолжать посылать частичные данные и могут ли получатели спокойно терпеть сбои?
- Если получателям нужно изменение для получения большего количества данных из агрегата Refunds, то внесением этого изменения будут заниматься две команды.
- Использование этого шаблона по всей платформе может привести к запутанной сети зависимостей между разными сервисами области, и всё потому, что эти сервисы обслуживают специфичные шаблоны доступа вызывающих.
Бэкенд для фронтендов (BFF)
Для уменьшения этих рисков можно позволить клиентским командам управлять оркестрацией между различными сервисами области. В конце концов, вызывающие лучше знают шаблоны и могут иметь полный контроль над изменениями в этих шаблонах. Такой подход отделяет сервисы области от слоя представления, позволяя им сфокусироваться на ключевом бизнес-процессе. Но если веб- и мобильные приложения начинают вызывать разные сервисы напрямую вместо использования одного составного API из монолита, тогда в этих приложениях может возникнуть перегрузка, а именно множественные вызовы через сети с низкой пропускной способностью, обработка и слияние данных от разных API и т.д.
Вместо этого можно использовать другой шаблон под названием “Бэкенд для фронтендов”. В этом шаблоне проектирования бэкенд сервис, созданный и управляемый получателями (в данном случае веб- и мобильными командами) берёт на себя интеграцию в нескольких сервисах области только для отображения получателям фронтенда. Теперь веб- и мобильные команды могут проектировать контракты о данных на основе случаев использования, которые они обслуживают. Они могут даже использовать GreaphQL вместо REST API, чтобы гибко запрашивать и получать именно то, что им нужно. Важно отметить, что этот сервис принадлежит клиентским командам и обслуживается ими же, а не командами, которым принадлежат сервисы предметной области. Фронтенд-команды теперь могут производить оптимизации по своим потребностям — мобильное приложение может запрашивать меньшую полезную нагрузку, снижать число своих вызовов и т.д. Взгляните на пересмотренный вид оркестровки ниже. Сервис BFF теперь для своих случаев использования вызывает и сервисы Orders, и сервисы области Refunds.
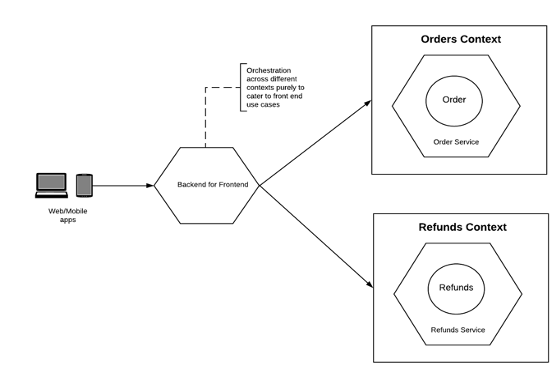
Также полезно создавать сервис BFF на ранних стадиях до момента разбивки монолита на множество сервисов. В противном случае либо сервисы области будут иметь доступ к поддержке оркестровки внутри области, либо веб- и мобильные приложения будут вынуждены вызывать несколько сервисов напрямую из фронтенда. Оба этих варианта приведут к перегрузке, бесполезной работе и недостатку автономности между командами.
Заключение
В этой статье мы затронули различные концепции, стратегии и эвристику проектирования, которые стоит учитывать при погружении в мир микросервисов, а именно при задаче разбивки монолита на несколько предметно-ориентированных микросервисов. Многие из этих тем велики сами по себе, и я думаю, что мы уделили их деталям слишком малое количество времени, но нашей задачей было ознакомиться с некоторыми критическими темами и способами их применения.
Читайте также:
- Создаём расширение для Chrome
- Великолепная десятка библиотек SVG иконок
- Пять алиасов Git, без которых мне не прожить
Перевод статьи Chandra Ramalingam: Building Domain Driven Microservices





