
Как и почему работает случайный лес? Разбираемся
Важная часть машинного обучения — это классификация. Мы хотим знать, к какому классу (или группе) принадлежит значение. Возможность точно классифицировать значения чрезвычайно ценна для бизнес-приложений, таких как прогнозирование покупки продукта конкретным пользователем или прогнозирование платёжеспособности по кредиту.
Наука о данных предоставляет множество алгоритмов классификации, таких как логистическая регрессия, машина опорных векторов, наивный байесовский классификатор и деревья решений. Но на вершине иерархии классификаторов находится классификатор случайного леса.
Дерево решений
Давайте быстро перейдем к деревьям решений, поскольку они — строительные блоки случайного леса. К счастью, они довольно интуитивны. Готов спорить, что большинство людей использовали дерево решений — сознательно или нет — в какой-то момент своей жизни.
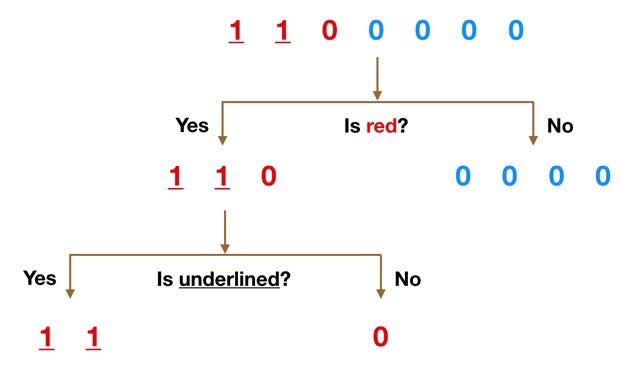
Представьте себе, что набор данных состоит из чисел в верхней части рисунка выше. У нас есть две единицы и пять нулей (1 и 0 — это наши классы) и мы хотим разделить классы, используя их признаки. Объекты имеют красный и синий цвета независимо от того, подчеркнуто ли значение.
Цвет кажется довольно очевидным признаком для разделения, поскольку все нули, кроме одного, синие. Поэтому мы можем использовать вопрос: “это красный?”, чтобы разделить наш первый узел. Вы можете представить себе узел в дереве как точку, в которой путь разделяется на два: значения, соответствующие критериям, идут вниз по ветке Yes, а не соответствующие критерию идут по ветке No.
У ветви No теперь все 0, но ветвь Yes все еще можно разделить. Теперь мы можем использовать вторую функцию и спросить: “это подчеркнуто?” для второго разделения.
Две подчёркнутые единицы идут вниз по стороне Yes, а неподчёркнутый 0 идет по правой стороне — и это всё. Наше дерево решений использовало эти два признака, чтобы идеально разделить данные.
Очевидно, что в реальной жизни наши данные не будут такими чистыми, но логика дерева решений остается прежней. На каждом узле оно будет спрашивать:
Какой признак позволит разделить значения таким образом, что результирующие группы будут максимально отличаться друг от друга, а члены каждой результирующей подгруппы будут максимально похожи друг на друга?
Классификатор случайного леса
Случайный лес, как и следует из его названия, состоит из большого количества отдельных деревьев решений, которые работают как ансамбль методов. Каждое дерево в случайном лесу возвращает прогноз класса, и класс с наибольшим количеством голосов становится прогнозом леса:
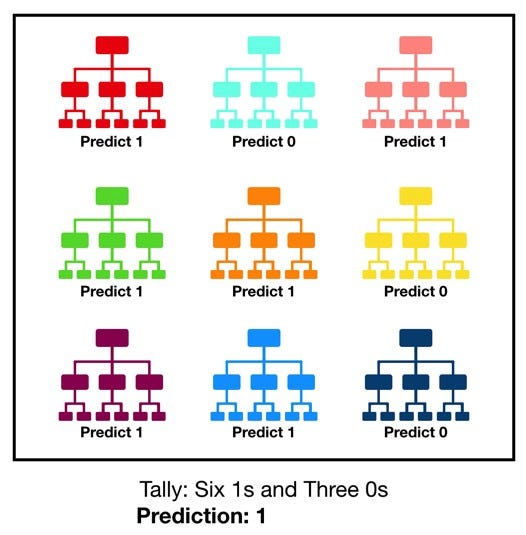
Фундаментальная концепция в основе случайного леса проста, но сильна — это мудрость толпы. Причина, по которой модель случайного леса работает так хорошо, заключается в том, что:
Большое число относительно некоррелированных деревьев, работающих совместно, будет превосходить любую из их отдельных составляющих.
Ключевым фактором является слабая корреляция между деревьями. Точно так же, как инвестиции с низкими корреляциями (например, акции и облигации) объединяются, чтобы сформировать портфель больший, чем сумма его частей, некоррелированные модели могут пргнозировать точнее, чем любой индивидуальный прогнозов. Причина такого чудесного эффекта: деревья защищают друг друга от своих индивидуальных ошибок, по крайней мере до тех пор, пока они не будут постоянно ошибаться в одном и том же направлении.
Некоторые деревья могут быть неправильными, но многие другие будут правильными, а значит, группа деревьев способна двигаться в верном направлении. Таким образом, предпосылками успешного прогнозирования являются:
- Некий осмысленный сигнал в признаках, чтобы модели были лучше случайного угадывания.
- Прогнозы (а значит и ошибки) отдельных деревьев должны слабо коррелировать между собой.
Почему это работает?
Эффект многих некоррелированных моделей так важен, что я хочу показать вам пример, который поможет понять это. Представьте себе, что мы играем в такую игру: у меня есть равномерно распределенный генератор случайных чисел для получения числа. Если число, которое я генерирую, больше или равно 40, вы выигрываете, то есть у вас 60% шанс на победу, и я плачу вам деньги. Если число меньше 40, я выигрываю — вы платите мне ту же сумму. Я предлагаю варианты. Мы играем так:
- 100 раз, ставка по $1 каждый раз.
- 10 раз со ставкой $10 каждый раз.
- 1 раз, но ставим $100.
Что бы вы выбрали? Ожидаемая ценность каждой игры одинакова:
1 = (0.60*1 + 0.40*-1)*100 = 20
2 = (0.60*10 + 0.40*-10)*10 = 20
3 = 0.60*100 + 0.40*-100 = 20А как насчет распределений? Визуализируем результаты с помощью моделирования Монте-Карло: запустим 10 000 симуляций каждого типа игры. Например, имитируем 100 игр по первым условиям 10 000 раз. Взгляните на график ниже. Каков ваш выбор теперь?
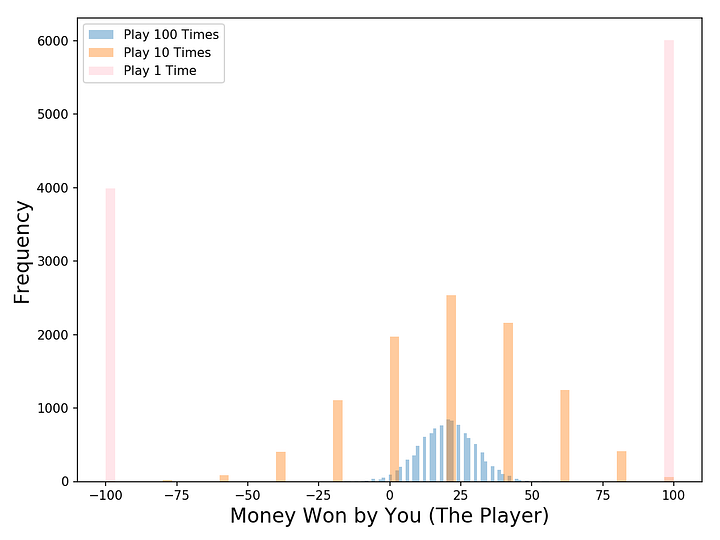
Первый вариант, где мы играем 100 раз, предлагает лучший шанс заработать немного денег. На 10 000 симуляций вы зарабатываете деньги в 97% случаев!Во второй игре, где мы играем 10 раз, вы зарабатываете деньги в 63% симуляций. В третьей вы зарабатываете в 60% случаев, как и ожидалось.
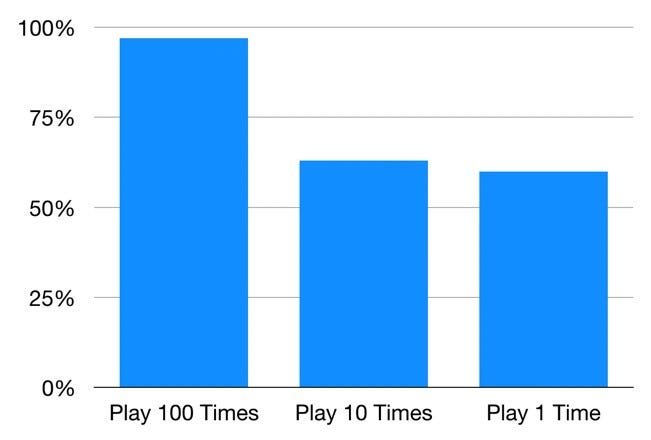
Таким образом, хотя игры имеют одинаковое ожидаемое значение, распределение результатов совершенно различно. Чем больше мы делим нашу ставку в 100 долларов, тем больше мы можем быть уверены, что заработаем деньги. Как уже упоминалось, это работает, потому что каждая игра независима от других.
Случайный лес работает так же: каждое дерево похоже на одну игру. Мы только что видели, как наши шансы заработать деньги увеличивались в зависимости от количества игр. Аналогично при использовании модели случайного леса наши шансы на получение правильных прогнозов возрастают с увеличением числа некоррелированных деревьев. Если вы хотите запустить код для моделирования игры самостоятельно, вы можете найти его на моём GitHub.
Разнообразие моделей
Как случайный лес гарантирует, что поведение каждого отдельного дерева не слишком коррелирует с поведением любого другого дерева? Он использует два метода:
- Бэггинг. Деревья решений очень чувствительны к данным, на которых обучаются: небольшие изменения в наборе могут привести к значительно отличающимся древовидным структурам. Случайный лес использует это преимущество, позволяя каждому отдельному дереву произвольно выбирать данные с заменой, что приводит к различным деревьям. Этот процесс известен как беггинг.
Обратите внимание, что при разбиении на пакеты мы не разбиваем обучающие данные на более мелкие фрагменты и не обучаем каждое дерево на другом фрагменте. Скорее, если у нас есть выборка размера N, мы подаём на вход каждого дерева обучающий набор размера N, если не указано иное.
Но вместо исходных обучающих данных мы берем случайную выборку размера N с заменой. Например, если бы наши обучающие данные были [1, 2, 3, 4, 5, 6], мы могли бы дать одному из наших деревьев список [1, 2, 2, 3, 6, 6]. Обратите внимание: оба списка имеют длину шесть, числа “2” и “6” повторяются случайно.
Разбиение узлов в модели основано на случайном подмножестве объектов для каждого дерева.
- Случайность признака. Вобычном дереве решений, когда нужно разделить узел, мы рассматриваем каждый возможный признак и выбираем тот, который сильнее делит значения в узлах. Напротив, каждое дерево в случайном лесу может выбирать только из случайного подмножества объектов. Это приводит к еще большей вариации между деревьями в модели и в конечном итоге к более слабой корреляции между деревьями и большему разнообразию.
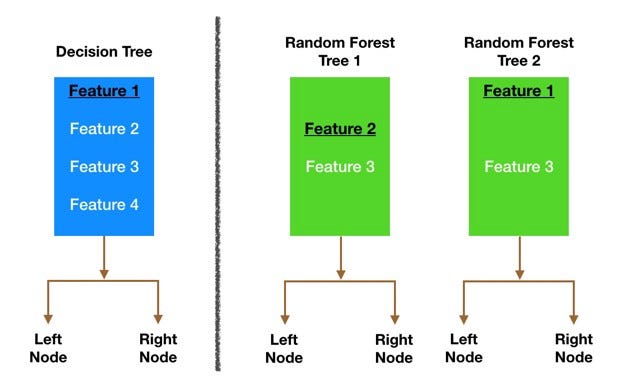
Наглядный пример: на рисунке выше традиционное дерево решений синего цвета может выбрать из всех четырех признаков, принимая решение о разделении узла. Дерево решает использовать 1, черную и подчеркнутую, поскольку она разбивает данные на максимально разделённые группы.
Посмотрим на два дерева леса из примера. Когда мы проверяем первое дерево, то обнаруживаем, что оно может рассматривать только признаки 2 и 3, выбранные случайным образом. Мы знаем из нашего традиционного дерева решений, что признак 1 лучший для разбиения, но дерево 1 не может видеть его, поэтому оно вынуждено работать с признаком 2. Второе дерево, с другой стороны, может видеть только признаки 1 и 3, поэтому может выбрать признак 1.
Таким образом, в нашем случайном лесу мы получаем деревья, которые не только обучаются на разных наборах данных благодаря пакету, но и используют разные признаки для принятия решений.
И это создает некоррелированные деревья, которые и защищают друг друга от своих ошибок.
Вывод
Итак, случайный лес — это алгоритм классификации, состоящий из многих деревьев решений. Он использует бэггинг и случайность признаков при построении каждого отдельного дерева, чтобы попытаться создать некоррелированный лес, прогноз которого точнее, чем у любого отдельного дерева.
Что нам нужно, чтобы случайный лес прогнозировал точнее?
- Признаки, обладающие некоторой предсказательной силой. В конце концов, что посеешь, то и пожнёшь.
- Деревья леса и, что более важно, их прогнозы должны быть некоррелированными. Или, по крайней мере, они должны слабо коррелировать друг с другом. В то время как сам алгоритм с помощью случайности признаков пытается построить эти слабые корреляции, выбранные нами признаки и гиперпараметры также повлияют на результат.
Читайте также:
- Значение Data Science в современном мире
- Как составить Data Science портфолио? Часть 1
- Настройка Data Science окружения на вашем компьютере
Перевод статьи Tony Yiu: Understanding Random Forest





