
Для начала рассмотрим некоторые руководящие принципы, которые используются при создании моделей:
- Сбор данных (обычно в больших количествах).
- Установление цели, гипотезы для проверки и сроков для достижения.
- Проверка на наличие аномалий или выбросов.
- Поиск недостающих данных.
- Очистка данных на основе ограничений, целей и тестирования гипотез.
- Выполнение статистического анализа и начальной визуализации.
- Масштабирование, регуляризация, нормализация, разработка функций, случайная выборка и проверка данных для подготовки модели.
- Обучение и тестирование данных.
- Создание моделей на основе показателей классификации/регрессии для обучения с учителем или без него.
- Установление базовой точности и проверка точности текущей модели на данных для обучения и тестирования.
- Повторная проверка решения проблемы и полученных результатов.
- Подготовка модели для развертывания и поставки продукта (AWS, Docker, Buckets, App, веб-сайт, ПО, Flask и т. д.).

Задачи машинного обучения подразделяются на обучение с учителем, без учителя, с частичным привлечением учителя и с подкреплением.
В процессе обучения с частичным привлечением учителя используются немаркированные данные для улучшения понимания структуры в целом. Другими словами, мы изучаем особенности только на основе небольшого набора для обучения, потому что он маркирован! Мы не используем преимущества тестового набора, содержащего множество ценной информации, из-за отсутствия маркировки. В результате нам необходимо найти способ обучения на основе большого количества немаркированных данных.
Обучение с подкреплением — это принятие подходящих мер для максимизации выгоды в определенной ситуации. Машина или робот обучаются, пробуя все возможные пути, а затем выбирают тот, который дает наибольшую выгоду с наименьшими трудностями.
Подходы
Ниже приведены подходы к выбору модели для решения задач машинного обучения/глубокого обучения:
- Несбалансированные данные достаточно распространены.
Обработку несбалансированных данных можно осуществить с помощью ресамплинга — использования выборки данных для повышения точности и подсчета погрешностей параметра совокупности. Методы ресамплинга используют технику вложенного ресамплинга.
Мы разделяем исходные данные на наборы для обучения и тестирования. После нахождения подходящих коэффициентов для модели с помощью первого набора мы применяем эту модель ко второму набору, чтобы обнаружить точность модели. Эта финальная точность, полученная перед применением ее к неизвестным данным, также называется набором для проверки и обеспечивает возможность получения более точных результатов.
Однако при дополнительном разделении набора для обучения на поднаборы и расчете их финальной точности, а затем многократного повторения этого процесса для множества поднаборов, можно добиться максимальной точности! Ресамплинг выполняется для повышения точности модели и разделяется на несколько способов, таких как начальная загрузка, перекрестная проверка, многократная перекрестная проверка и т. д.
2. Мы можем создавать новые функции с помощью метода главных компонент.
Этот метод также известен как PCA и помогает уменьшить размерность. Методы кластеризации очень распространены при обучении без учителя.
3. Мы можем предотвратить переобучение, недостаточное обучение, выбросы и шум с помощью методов регуляризации.
4. Нам необходимо устранить проблему «черного ящика».
Для решения этой проблемы стоит рассмотреть стратегии для построения интерпретируемых моделей. Системы ИИ «черного ящика» для автоматического принятия решений в большинстве случаев основаны на машинном обучении на больших данных, отображающих функции пользователя в класс, который предсказывает поведенческие черты личности без объяснения причин.
Проблема заключается не только в отсутствии прозрачности, но и в возможном возникновении погрешностей, унаследованных алгоритмами от человеческих предрассудков, и сборе артефактов, скрытых в данных обучения, которые могут привести к неправильным решениям и неправильному анализу.
5. Понимание алгоритмов, не восприимчивых к выбросам.
Чтобы преодолеть отклонение от нормы, можно использовать произвольность в моделях или случайные леса.
Модели машинного обучения
- Первый подход к предсказанию постоянных значений: линейная регрессия — наиболее распространенный выбор, например, при предсказании стоимости жилья.
- Подходы бинарной классификации обычно схожи с моделями логистической регрессии. При возникновении проблемы классификации с двумя классами методы опорных векторов (SVM) — отличный способ получения наилучшего результата!
- Мультиклассовая классификация: случайные леса — предпочтительный выбор, однако SVM обладают схожими преимуществами. Случайные леса больше предназначены для мультикласса!
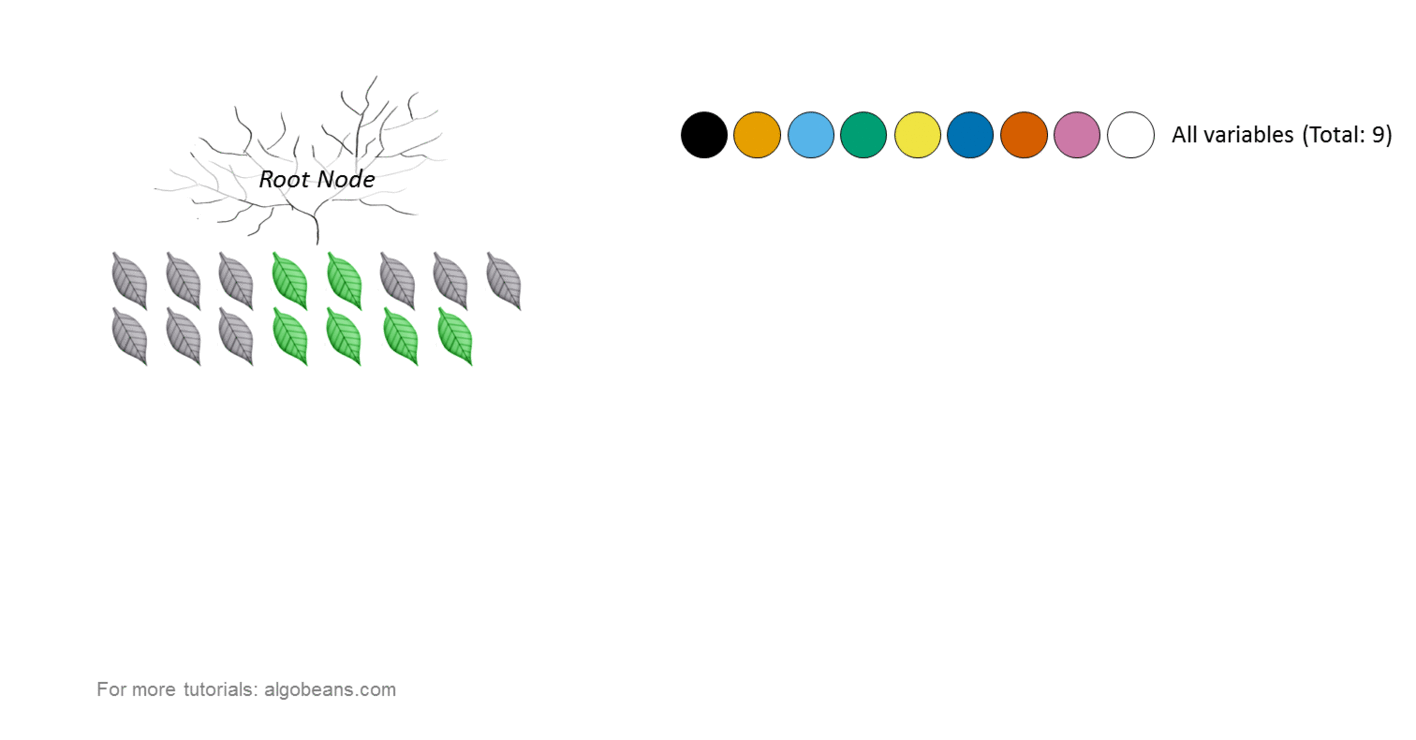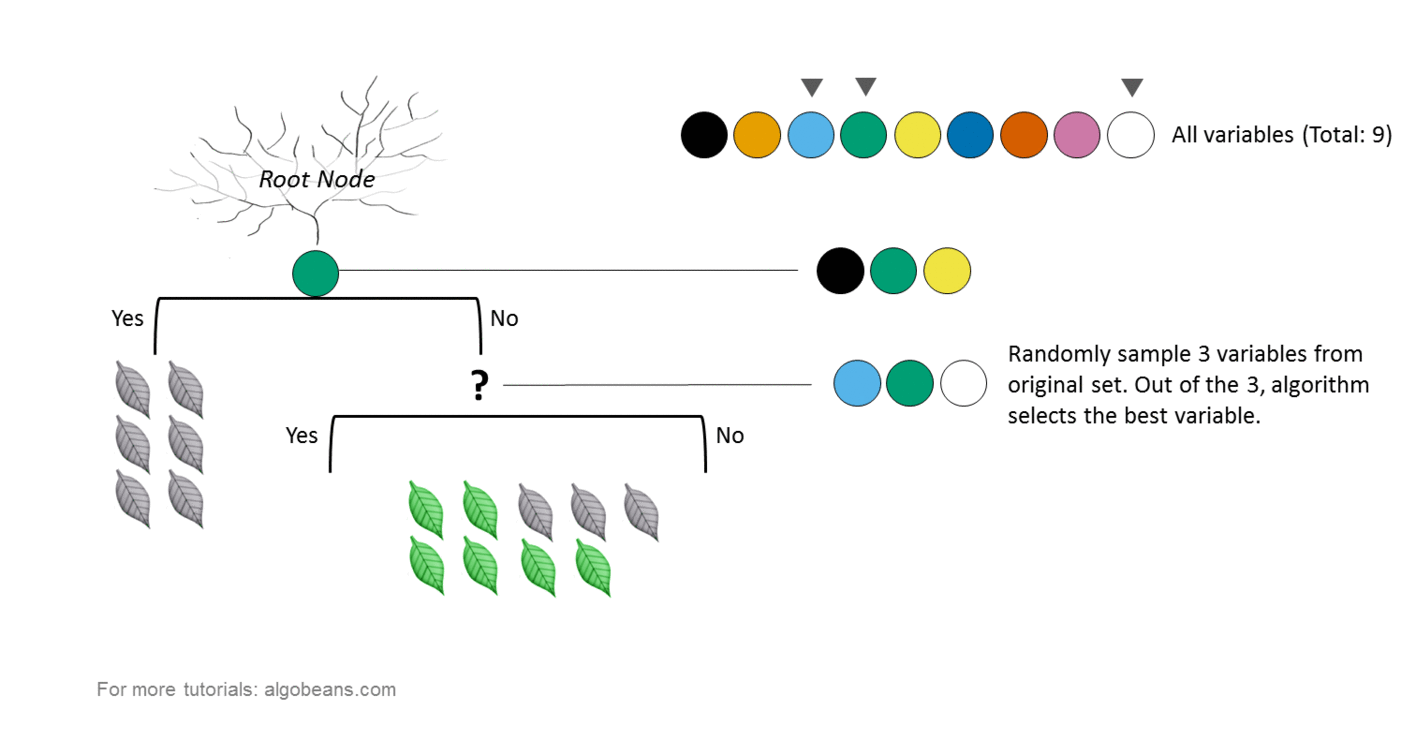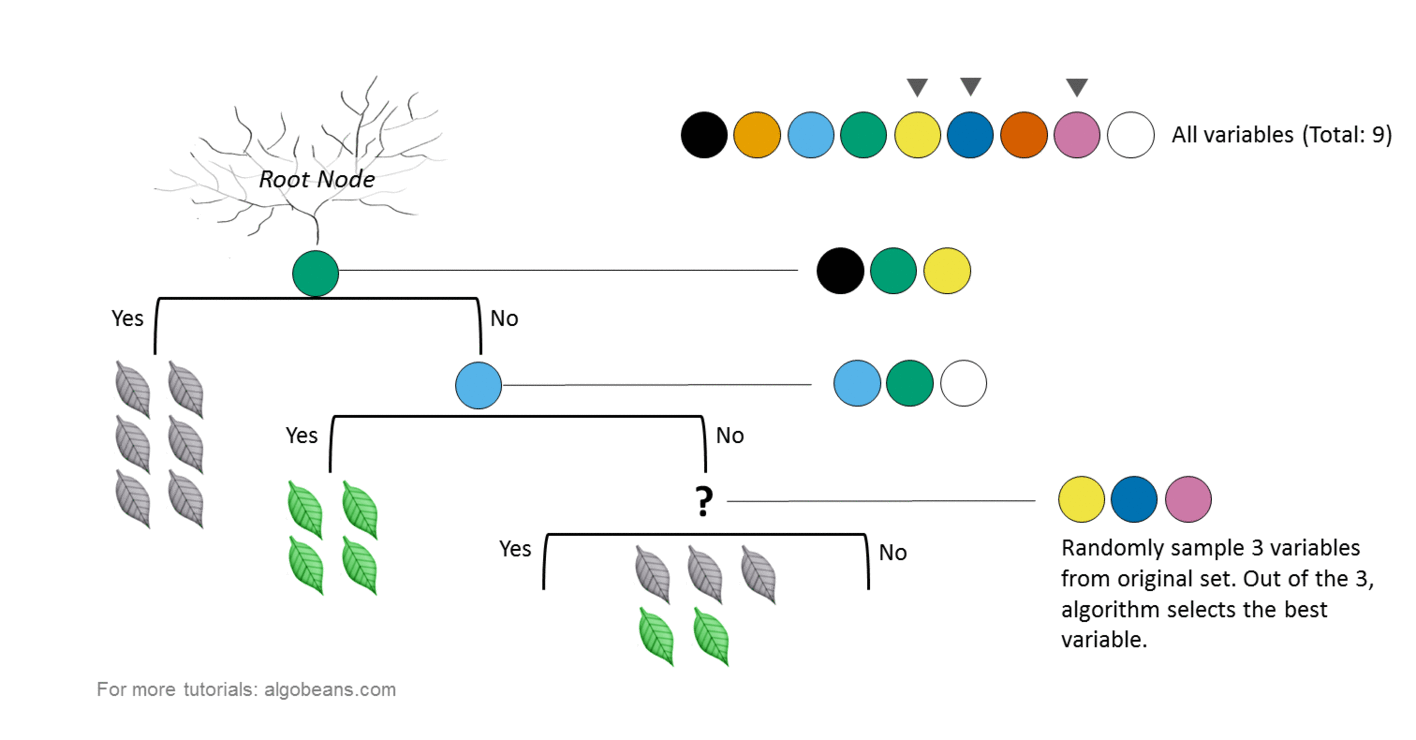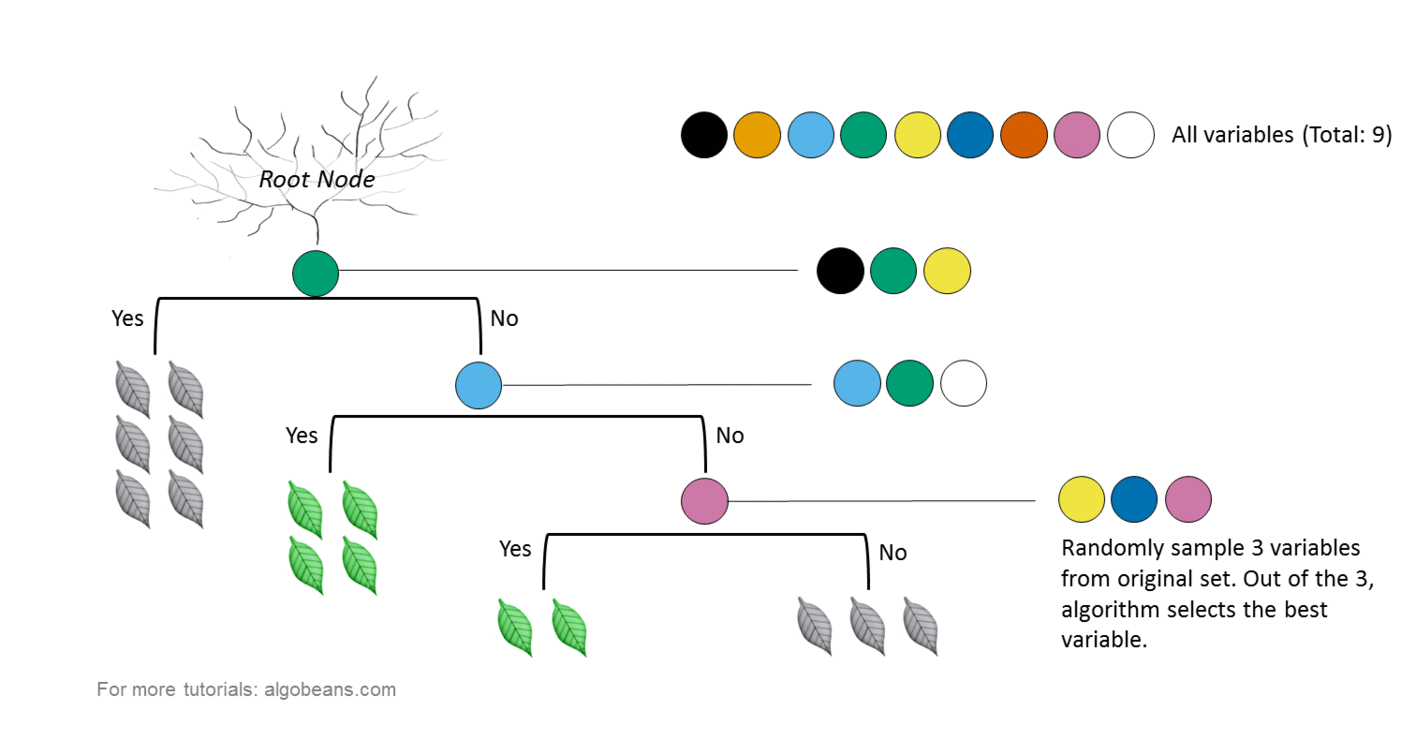
Для мультикласса нужно разбить данные на несколько задач бинарной классификации. Случайные леса отлично подходят для работы с несколькими числовыми и категориальными признаками, даже если они обладают различными масштабами. Это означает, что вы можете работать с исходными данными. SVM максимизируют отступ и основываются на концепции расстояния между различными точками. Остается только решить, действительно ли расстояние имеет значение!
В результате для категориальных признаков необходимо использовать единый код. Кроме того, в качестве предварительной обработки рекомендуется применять min-max или другое масштабирование. Для наиболее распространенных задач классификации случайные леса предоставляют вероятность принадлежности к этому классу, в то время как SVM предоставляют расстояние до границы, которую все же нужно преобразовать при необходимости в вероятность. SVM предоставляют опорные вектора — точки в каждом ближайшем к границе классе.
4. Деревья решений просты в использовании и понимании. Они реализуются с помощью таких моделей, как случайные леса или градиентный бустинг.

5. Для соревнований Kaggle предпочтительны случайный лес и XGBoost!

Модели глубокого обучения
Глубокое обучение — это функция ИИ, которая имитирует работу человеческого мозга при обработке данных и создании шаблонов для использования в принятии решений.

Мы можем использовать многослойные персептроны, чтобы сосредоточиться на сложных в определении признаках, которые содержат большое количество маркированных данных!
Многослойный персептрон (MLP) — это искусственная нейронная сеть с прямой связью, которая генерирует набор выходных данных из набора входных. MLP характеризуется несколькими слоями входных узлов, связанных как ориентированный граф между входным и выходным слоями.

Для машинного обучения на основе зрения, такого как классификация изображений, обнаружение объектов, сегментация или распознавание изображений, используется сверточная нейронная сеть (CNN). CNN используются в распознавании и обработке изображений, которые предназначены для обработки пиксельных данных.

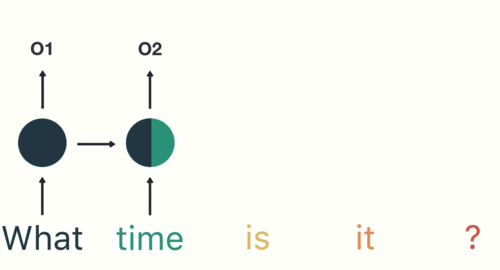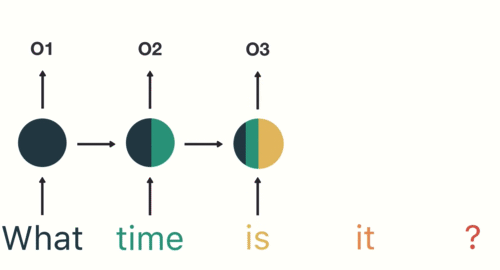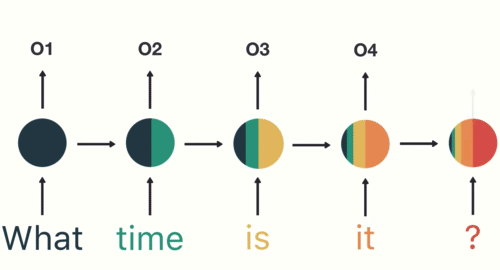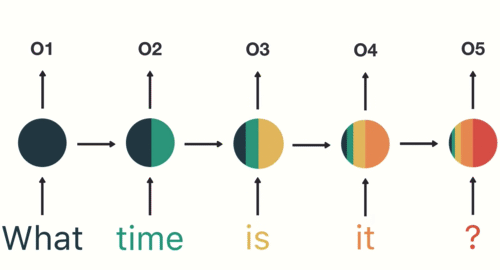
Для задач моделирования последовательности, таких как языковой перевод или классификация текста, предпочтительны рекуррентные нейронные сети (RNN).
RNN созданы для моделей, которые нуждаются в контексте, чтобы предоставить выходные данные на основе входных. В некоторых случаях контекст играет решающую роль для предсказания наиболее подходящего результата. В других нейронных сетях все входные данные независимы друг от друга.
Читайте также:
- Создание Docker контейнера с вашей моделью машинного обучения
- Python-библиотеки интерпретации моделей ML
- 5 лучших библиотек машинного обучения
Перевод статьи Aakash Sharma: Choosing a Machine Learning Model




