
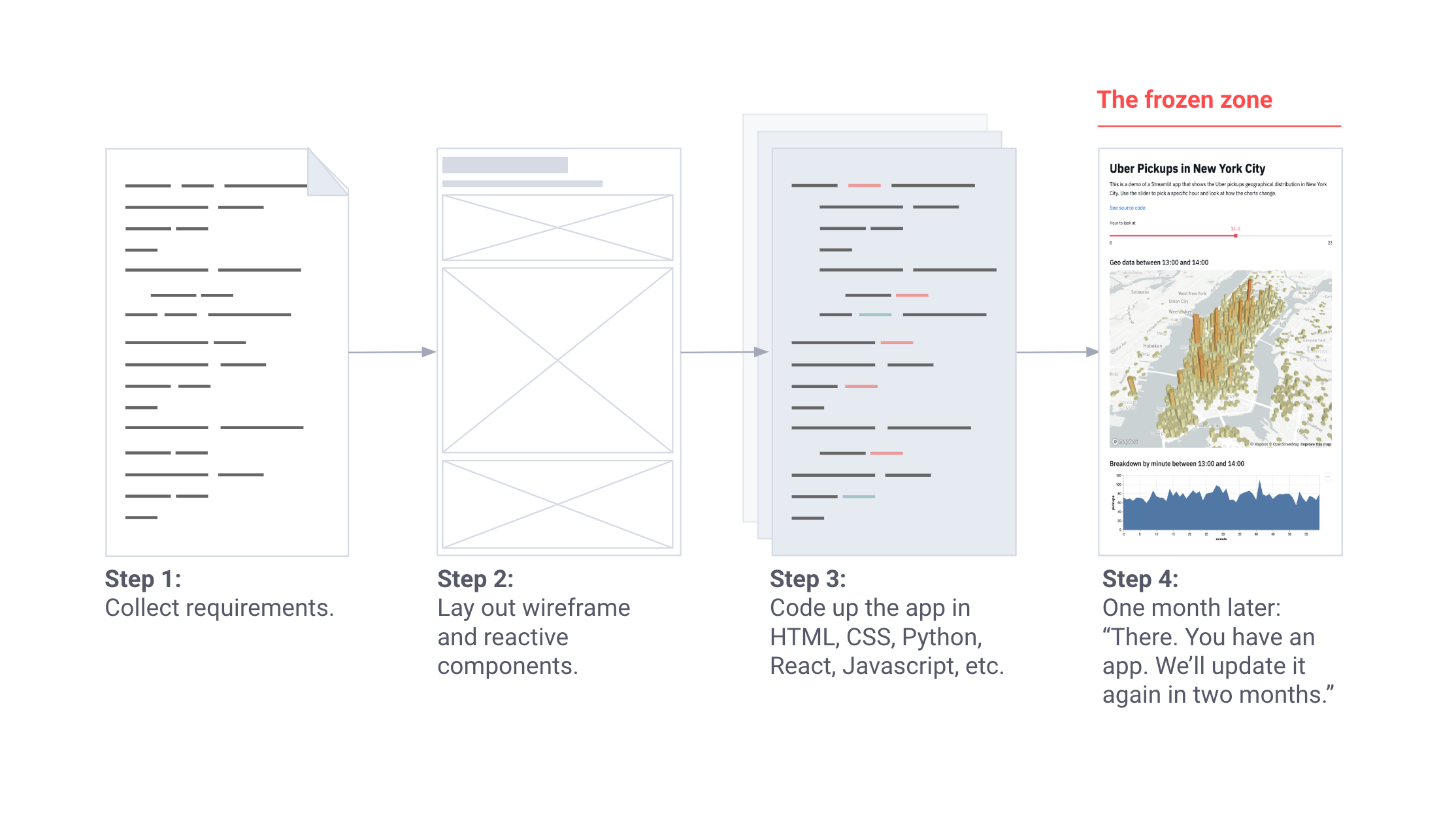
В конечном счете в каждом нетривиальном проекте машинного обучения появляется масса ошибок и внутренними инструментами, которые невозможно сопровождать. Эти инструменты — обычно patchwork из Jupyter Notebooks и приложения Flask — сложны в развертывании, требуют логики архитектуры «клиент-сервер» и плохо интегрируются с конструкциями МО, такими как сессии Tensorflow GPU.
Впервые я заметил это в Carnegie Mellon, затем в Berkeley, Google X и во время создания автономных роботов в Zoox. Эти инструменты обычно создавались в качестве небольших Jupyter notebooks: инструмент калибровки сенсора, приложение сравнения симуляции, приложение выравнивания лидара, инструмент воспроизведения сценария и так далее.
По мере роста важности инструментов, к работе приступили руководители проектов. Процессы развивались. Требования увеличивались. Сольные проекты превращались в сценарии, а затем перерастали в кошмары для поддержки.
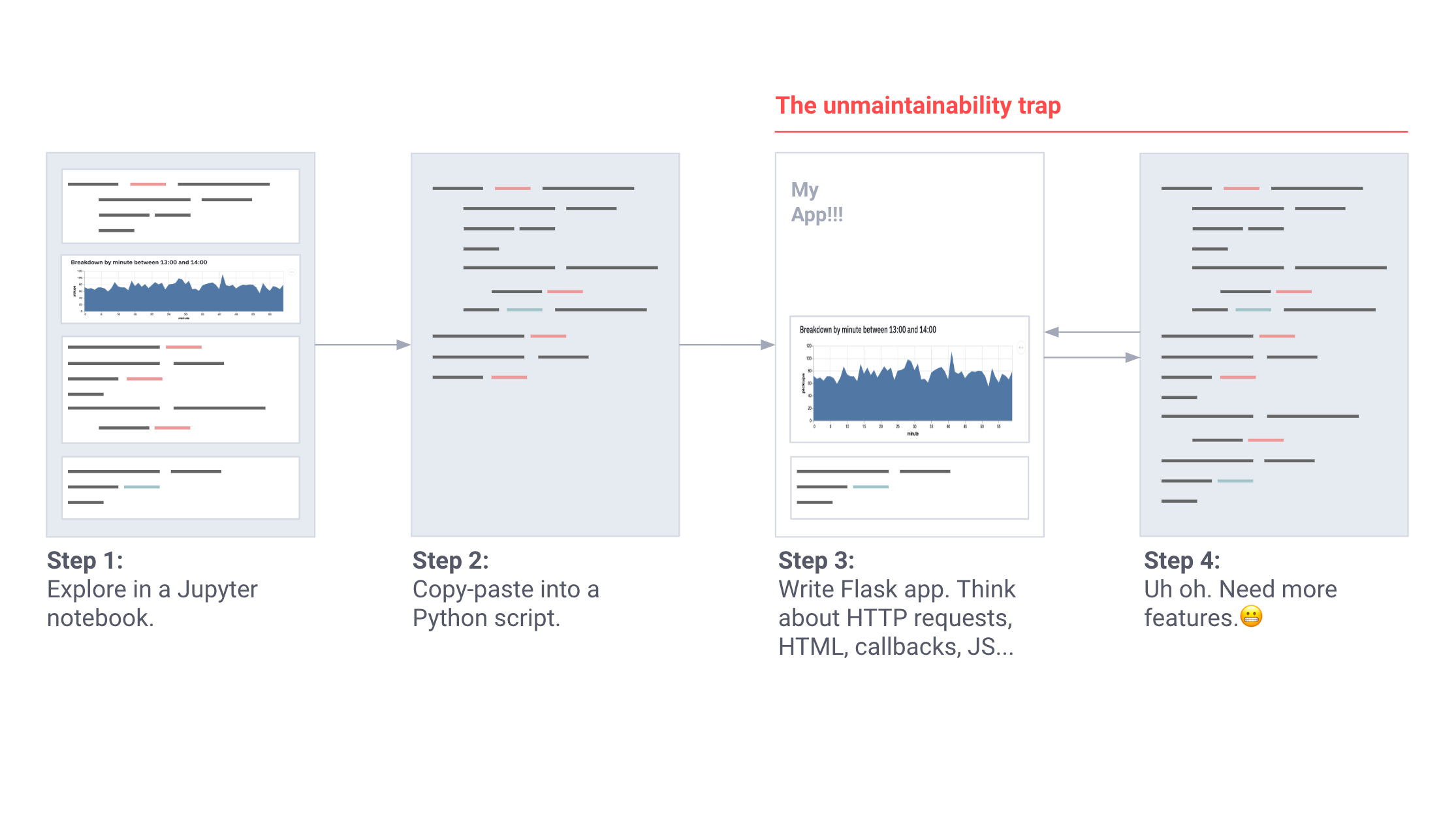
Когда инструменты приобрели критически важную роль, к работе подключилась команда разработчиков. Процесс проектирования выглядел следующим образом:
Он был потрясающим, но все эти инструменты нуждались в новых функциях, а команда разработчиков поддерживала еще десять других проектов.
Таким образом, мы вернулись к созданию собственных инструментов, развертыванию приложений Flask, написанию HTML, CSS и JavaScript, а также к попыткам контролировать все версии, начиная от notebooks и заканчивая таблицами стилей. Затем я и мой старый друг из Google X, Тиаго Тейшейра, задумались: можно ли сделать процесс создания инструментов таким же простым, как написание сценариев Python?
Мы хотели предоставить инженерам машинного обучения возможность создавать приложения без помощи команды разработчиков. Эти внутренние инструменты должны возникать естественным образом в рабочем процессе МО. Их написание должно походить на обучение нейронной сети или проведение специального анализа в Jupyter! В то же время мы хотели сохранить гибкость фреймворка приложений. В целом и общем мы пытались добиться следующего:

Шаг 1: Добавьте несколько вызовов API в существующий сценарий Python.
Шаг 2: Продемонстрируйте свой инструмент с отличной производительностью
Совместно с бета-сообществом, включающим инженеров из Uber, Twitter, Stitch Fix и Dropbox, в течение целого года мы работали над созданием Streamlit — бесплатного open-source фреймворка приложений для инженеров МО. Основные принципы Streamlit:
#1: Использование сценариев Python. Приложения Streamlit — это простые сценарии, которые запускаются сверху вниз и не содержат скрытого состояния. Анализировать код можно с помощью вызовов функций. Если вы знакомы с написанием сценариев Python, то сможете написать приложения Streamlit. Например, вывод информации на экран выглядит следующим образом:
import streamlit as st
st.write('Hello, world!')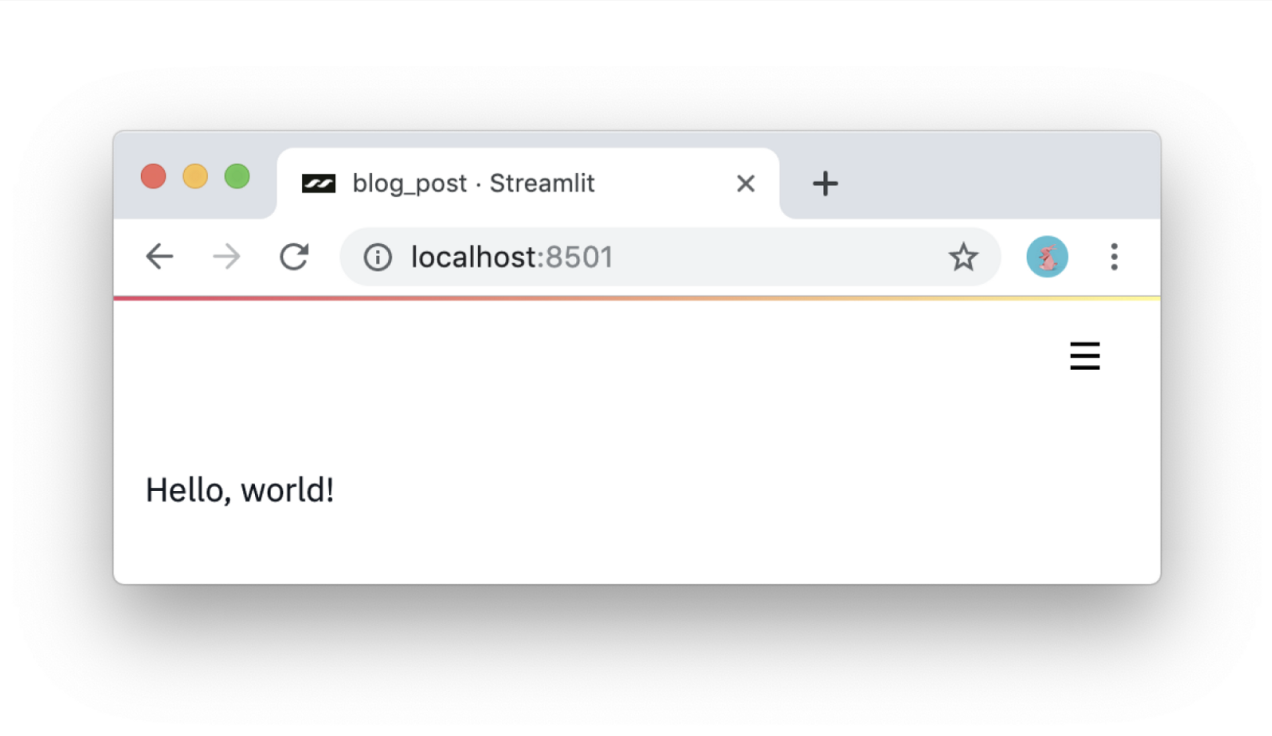
#2: Обработка виджетов в качестве переменных. В Streamlit нет обратных вызовов! Каждое взаимодействие просто перезапускает сценарий сверху вниз. В результате такого подхода получаем действительно чистый код:
import streamlit as st
x = st.slider('x')
st.write(x, 'squared is', x * x)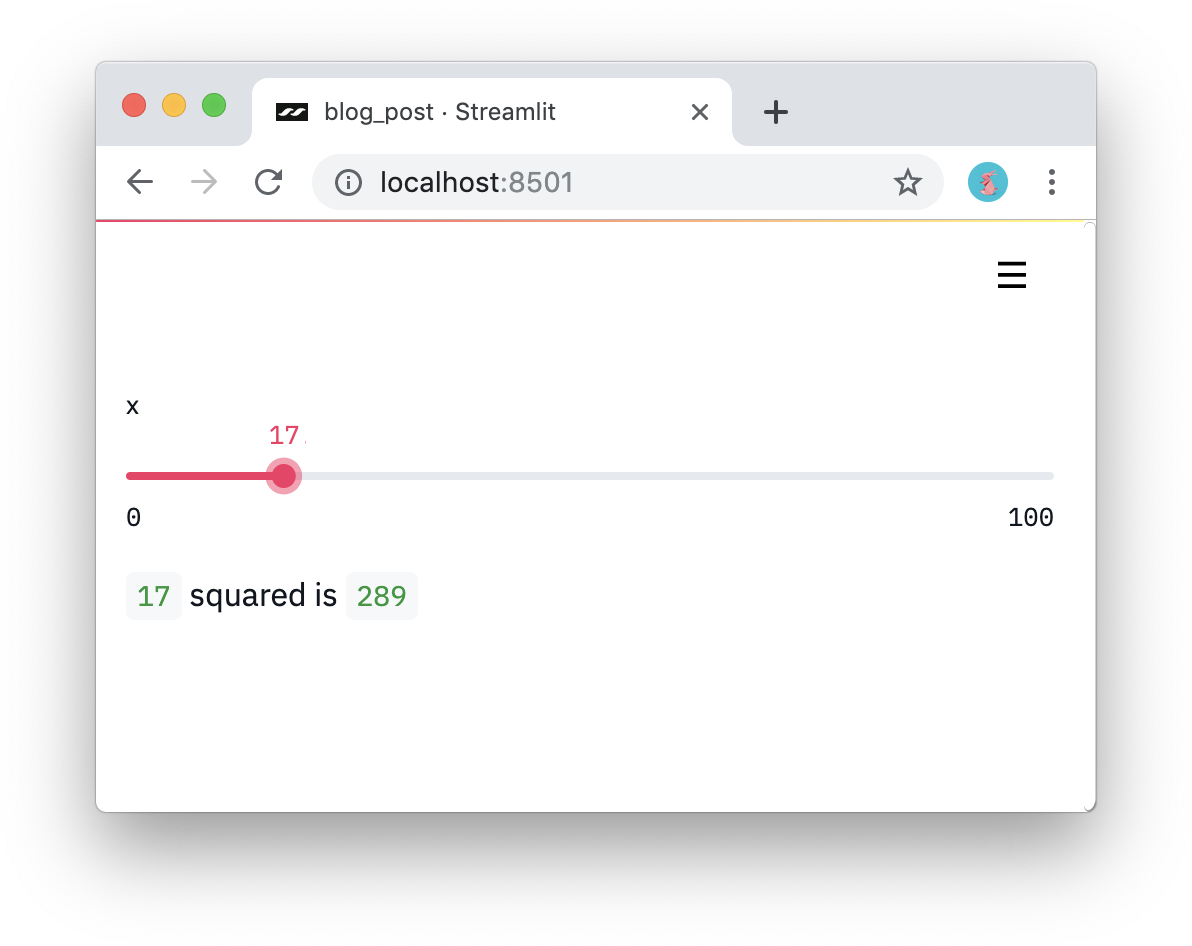
#3: Повторное использование данных и вычислений. Streamlit представляет примитивный тип кеша, который ведет себя как постоянное, неизменяемое по умолчанию хранилище данных, предоставляя приложениям Streamlit возможность повторно использовать информацию. Например, следующий код загружает данные только один раз из проекта Udacity Self-Driving Car, в результате чего получается простое и быстрое приложение:
import streamlit as st
import pandas as pd
# Reuse this data across runs!
read_and_cache_csv = st.cache(pd.read_csv)
BUCKET = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/"
data = read_and_cache_csv(BUCKET + "labels.csv.gz", nrows=1000)
desired_label = st.selectbox('Filter to:', ['car', 'truck'])
st.write(data[data.label == desired_label])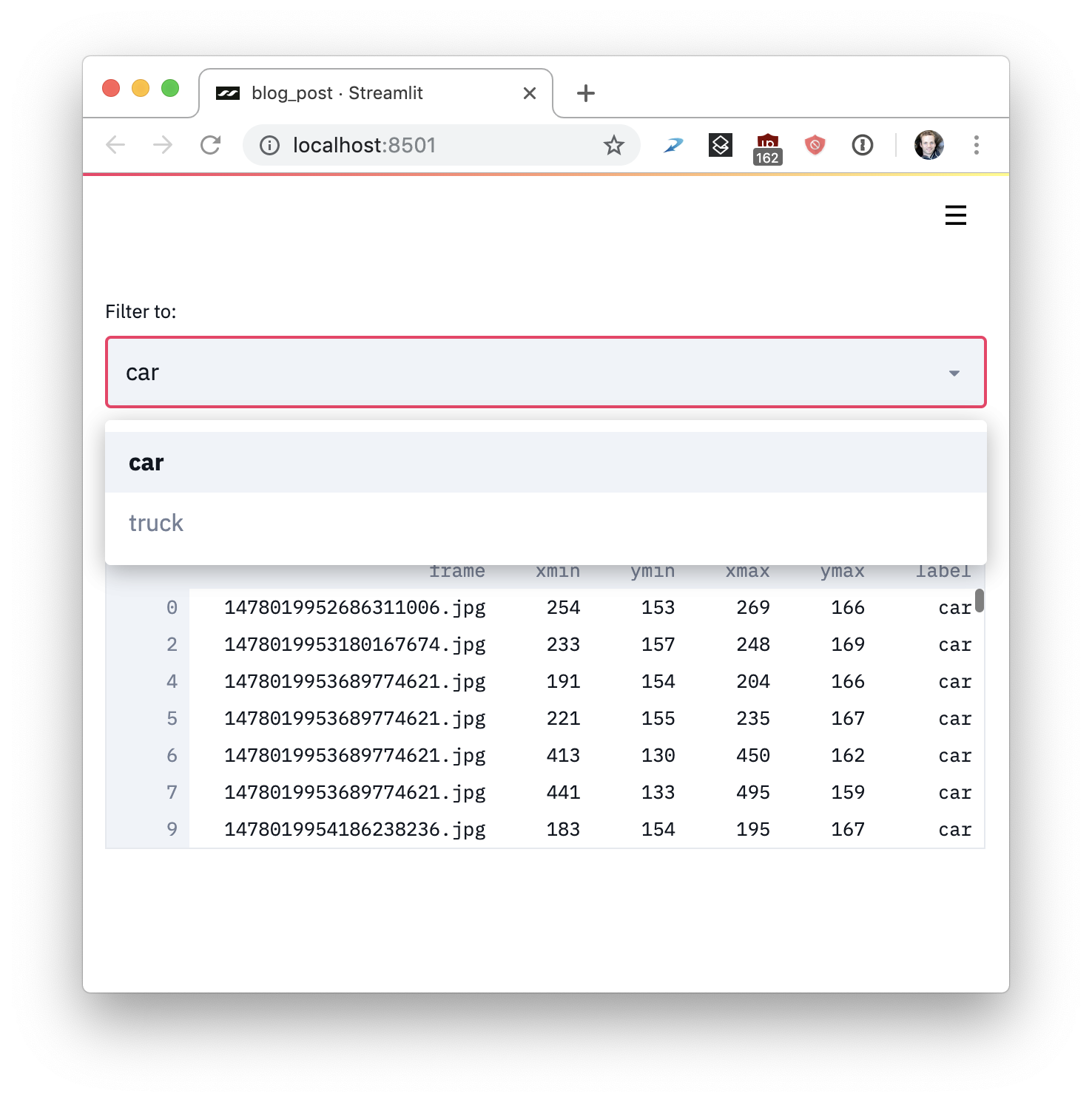
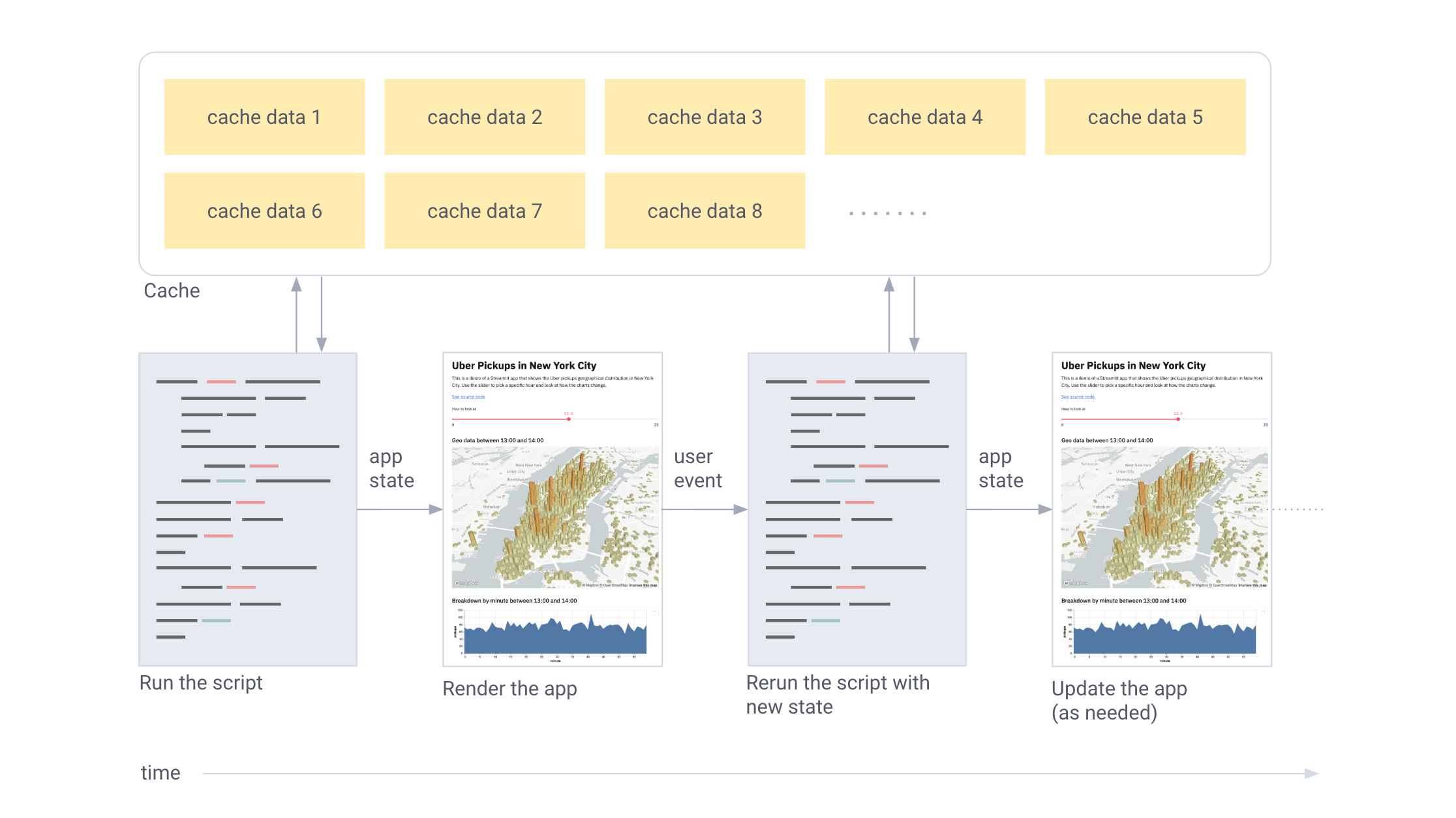
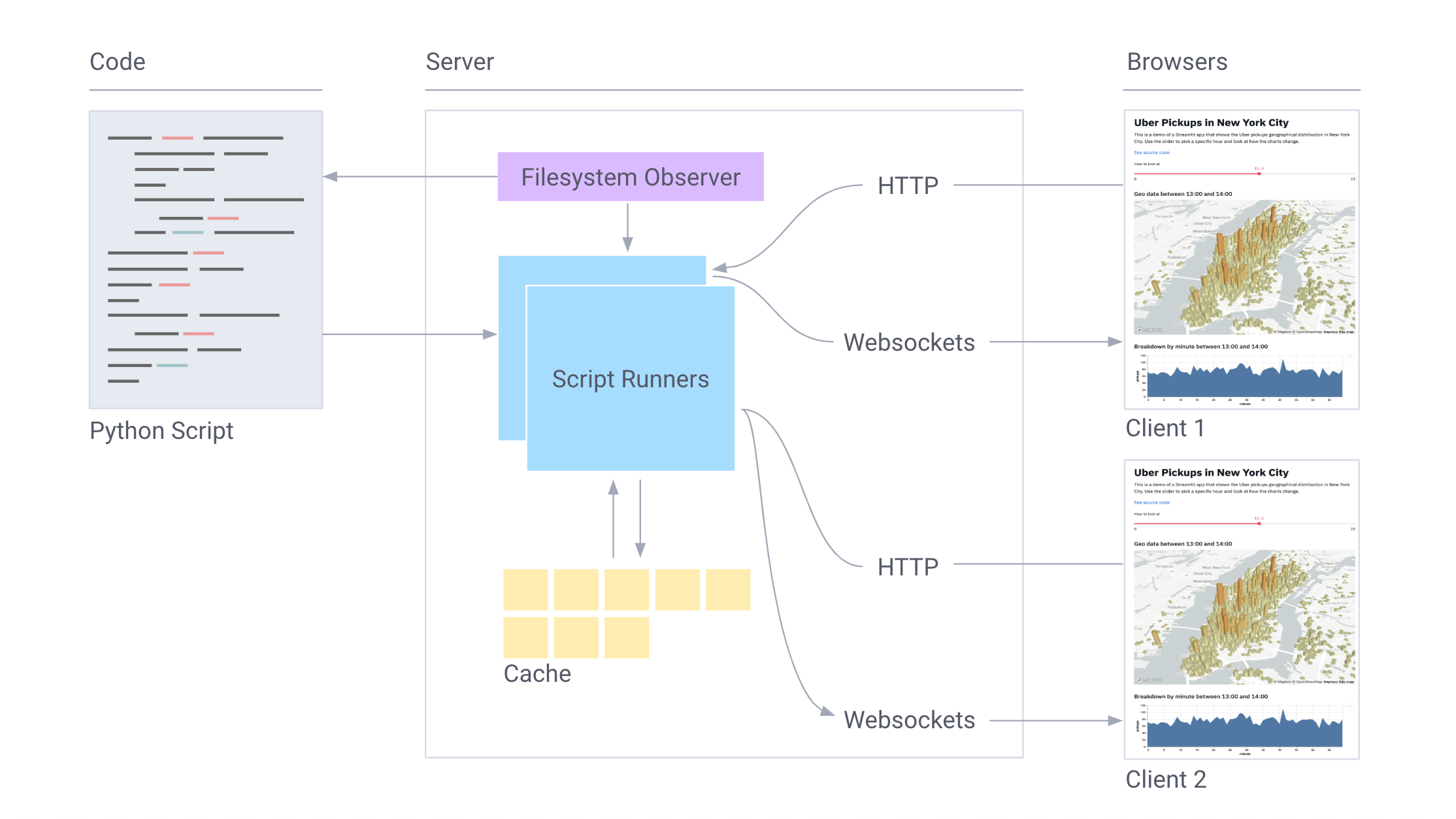
Streamlit работает следующим образом:
- Весь сценарий запускается с нуля для каждого взаимодействия с пользователем.
- Streamlit присваивает каждой переменной актуальное значение с учетом состояний виджета.
- Благодаря кэшированию Streamlit пропускает избыточные выборки данных и вычисления.
Процесс в картинках:
Звучит интригующе? Тогда попробуйте Streamlit прямо сейчас! Просто запустите:
$ pip install --upgrade streamlit
$ streamlit hello
Теперь Streamlit доступен в браузере.
Local URL: http://localhost:8501
Network URL: http://10.0.1.29:8501Веб-браузер с указанием на локальное приложение Streamlit откроется автоматически. Если этого не произошло, просто нажмите на ссылку.
Во время работы в Zoox и Google X я наблюдал, как проекты беспилотных автомобилей разрастались в гигабайты визуальных данных, которые нужно было искать и понимать, а так же необходимо было запускать модели на изображениях для сравнения производительности. Над каждым проектом беспилотных автомобилей работали целые команды.
В Streamlit можно с легкостью создать подобный инструмент. В этой демонстрации Streamlit можно выполнять семантический поиск по всему набору фото-данных беспилотного автомобиля Udacity, визуализировать метки наземной истины и запускать нейронную сеть (YOLO) в реальном времени из приложения [1].
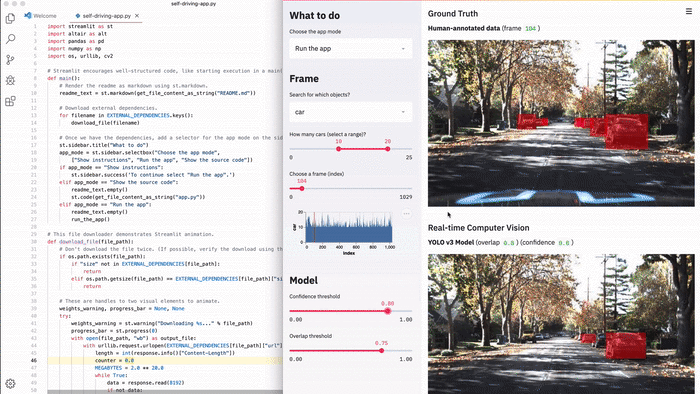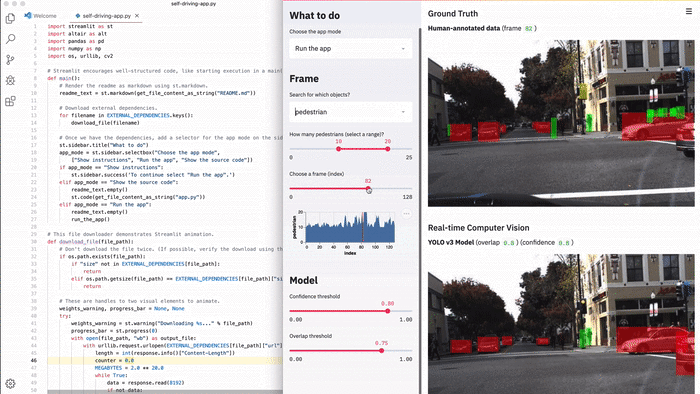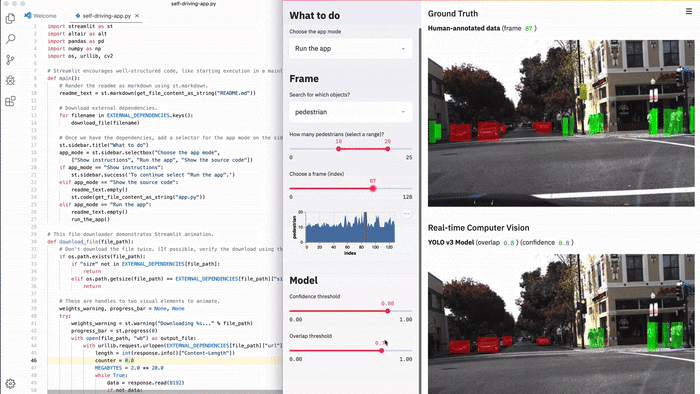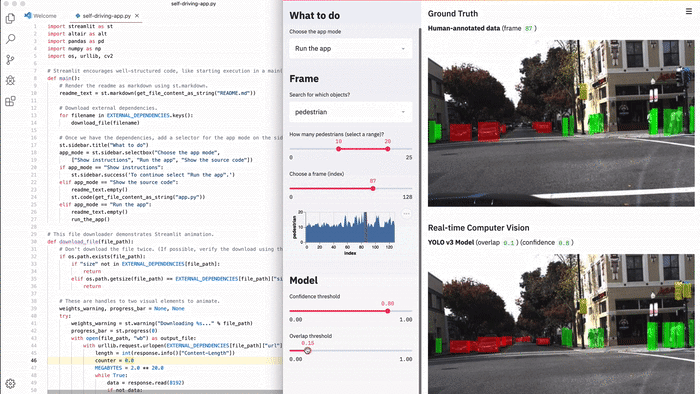
Все приложение — это полностью автономный 300-строчный сценарий Python, большая часть которого представлена кодом машинного обучения. Оно содержит лишь 23 вызова Streamlit. Вы можете запустить его прямо сейчас!
$ pip install --upgrade streamlit opencv-python
$ streamlit run
https://raw.githubusercontent.com/streamlit/demo-self-driving/master/app.pyЭти простые идеи предоставляют ряд важных преимуществ:
Приложения Streamlit — это чистые файлы Python. Таким образом, со Streamlit можно использовать любой редактор и отладчик.
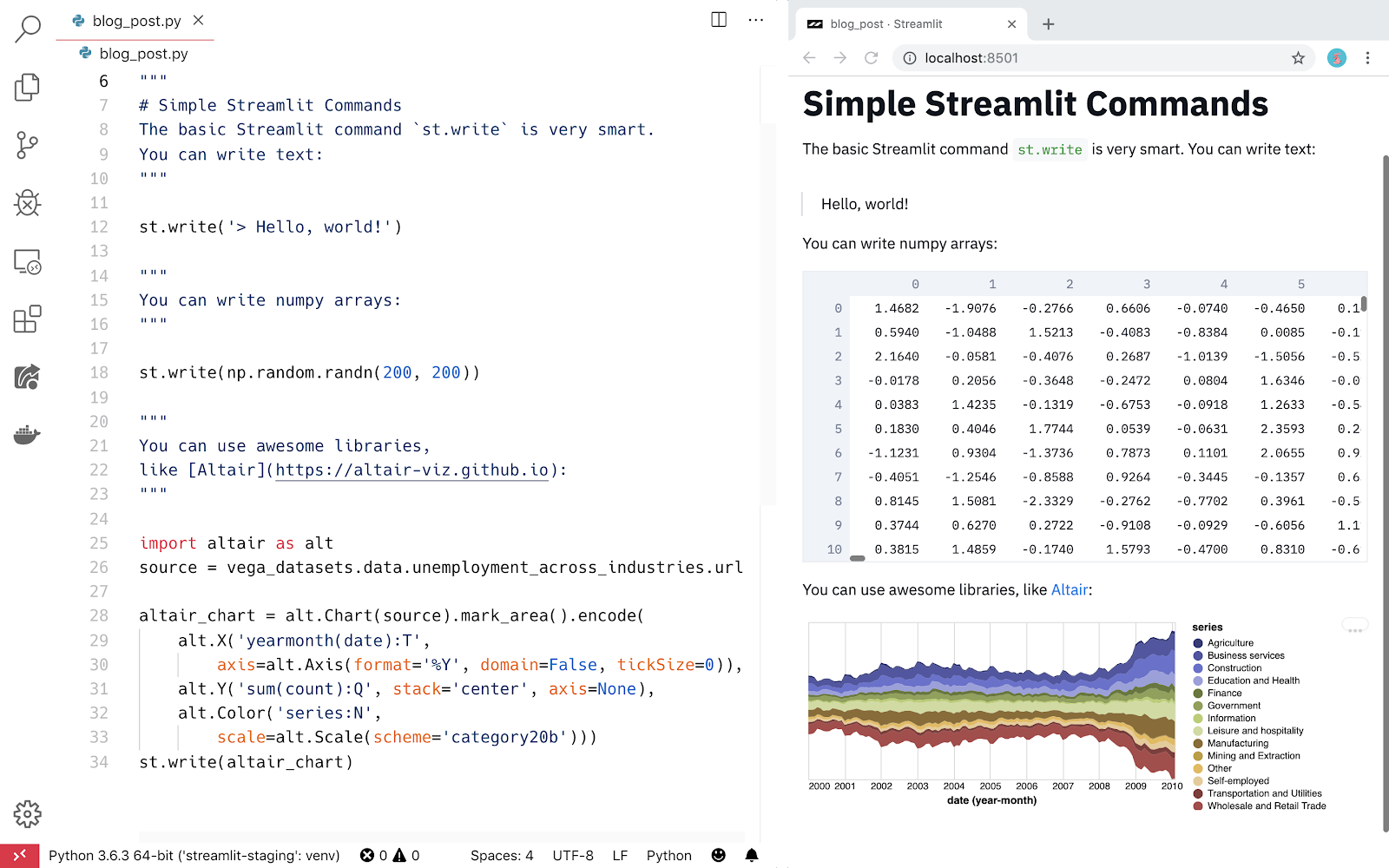
Сценарии на чистом Python с легкостью работают с Git и другими системами контроля версий, включая коммиты, pull requests, проблемы и комментарии. Поскольку основным языком Streamlit является Python, все преимущества этих инструментов предоставляются бесплатно ?.
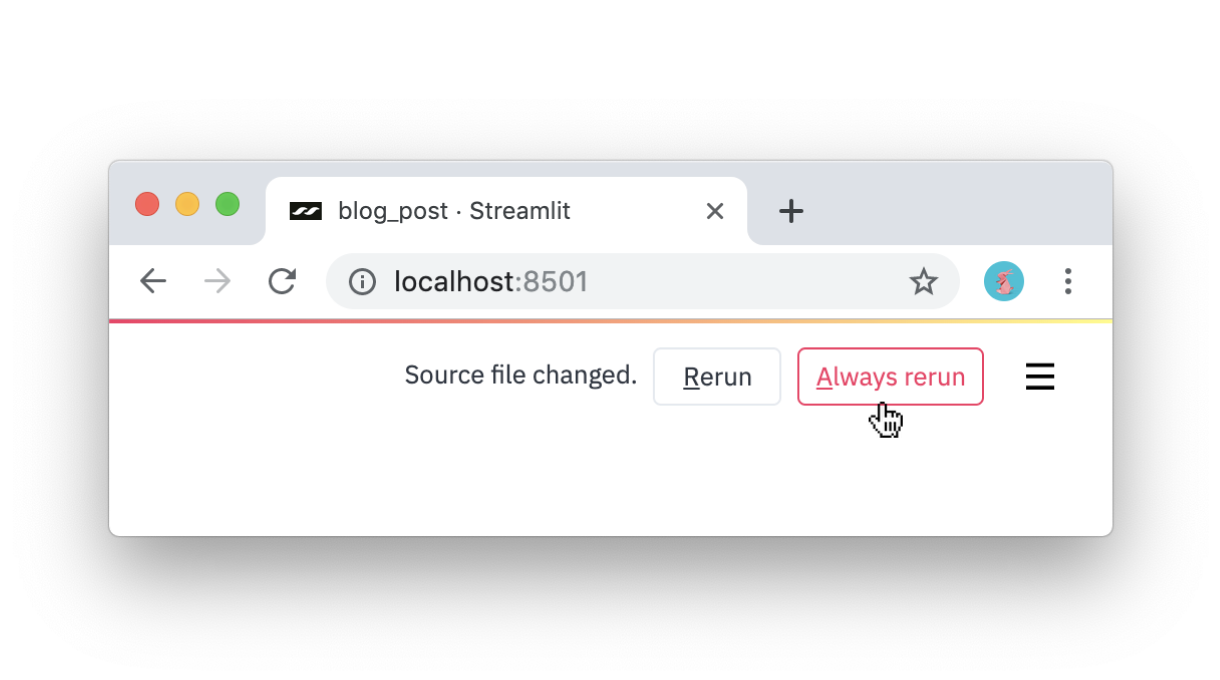
Streamlit предоставляет среду программирования в режиме реального времени. Просто нажмите Always rerun (Постоянный перезапуск) при обнаружении Streamlit изменений исходного файла.
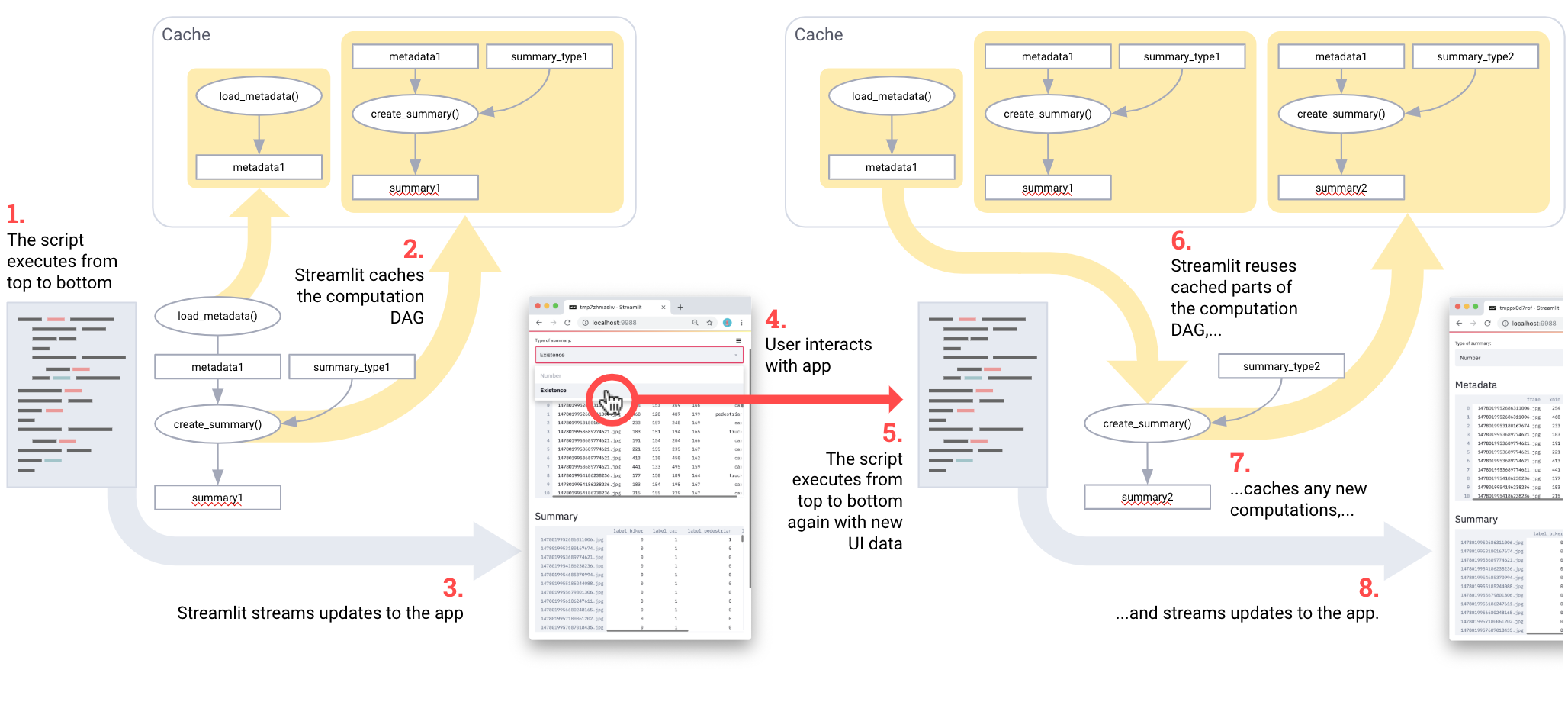
Кэширование упрощает настройку вычислительных конвейеров. Удивительно, но связывание кэшированных функций автоматически создает эффективные вычислительные конвейеры! Рассмотрим этот код, адаптированный из демонстрации Udacity:
import streamlit as st
import pandas as pd
@st.cache
def load_metadata():
DATA_URL = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/labels.csv.gz"
return pd.read_csv(DATA_URL, nrows=1000)
@st.cache
def create_summary(metadata, summary_type):
one_hot_encoded = pd.get_dummies(metadata[["frame", "label"]], columns=["label"])
return getattr(one_hot_encoded.groupby(["frame"]), summary_type)()
# Piping one st.cache function into another forms a computation DAG.
summary_type = st.selectbox("Type of summary:", ["sum", "any"])
metadata = load_metadata()
summary = create_summary(metadata, summary_type)
st.write('## Metadata', metadata, '## Summary', summary)Конвейер выглядит следующим образом: load_metadata → create_summary. При каждом запуске сценария Streamlit пересчитывает только то подмножество конвейера, которое требуется для получения правильного ответа.
Streamlit разработан для графических процессоров. Streamlit обеспечивает прямой доступ к примитивам машинного уровня, таким как TensorFlow и PyTorch, и дополняет эти библиотеки. Например, в этой демонстрации в кэше Streamlit хранится весь NVIDIA celebrity face GAN [2]. Благодаря этому подходу выводы выполняются практически мгновенно при передвижении ползунка пользователем.
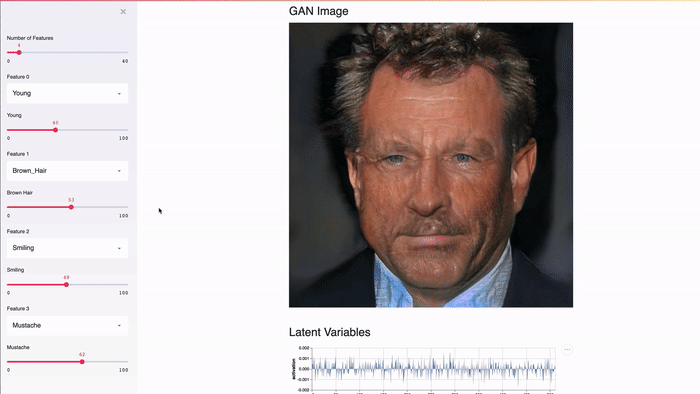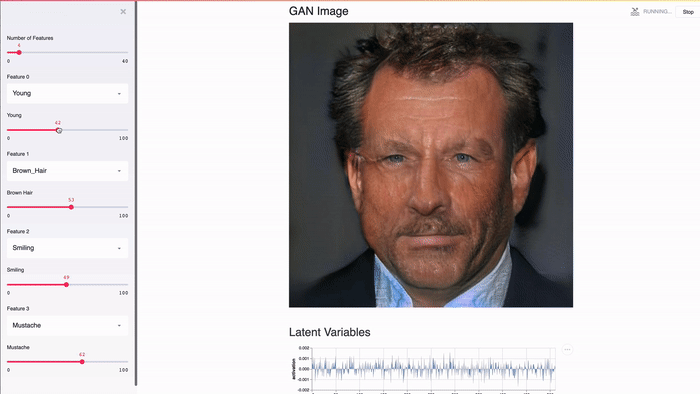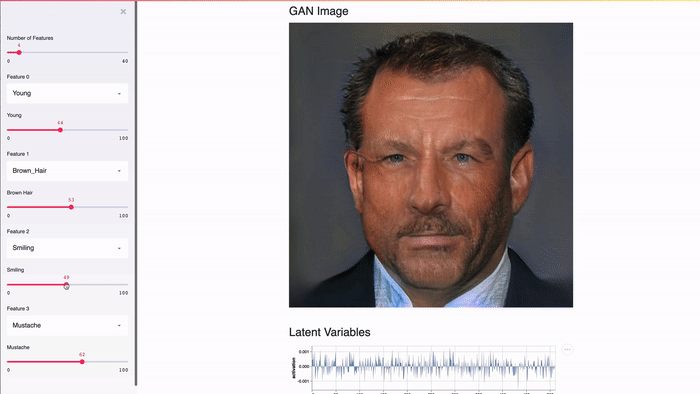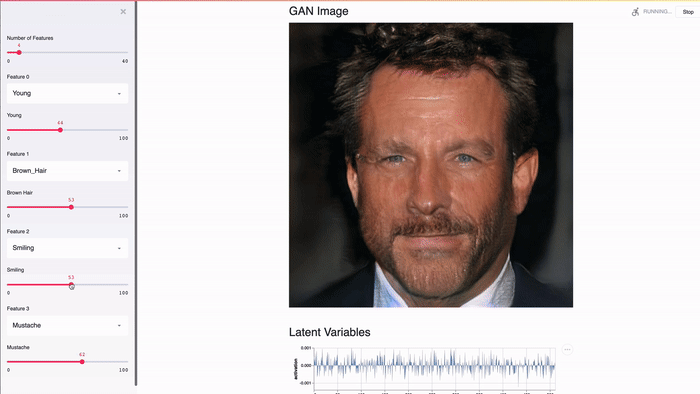
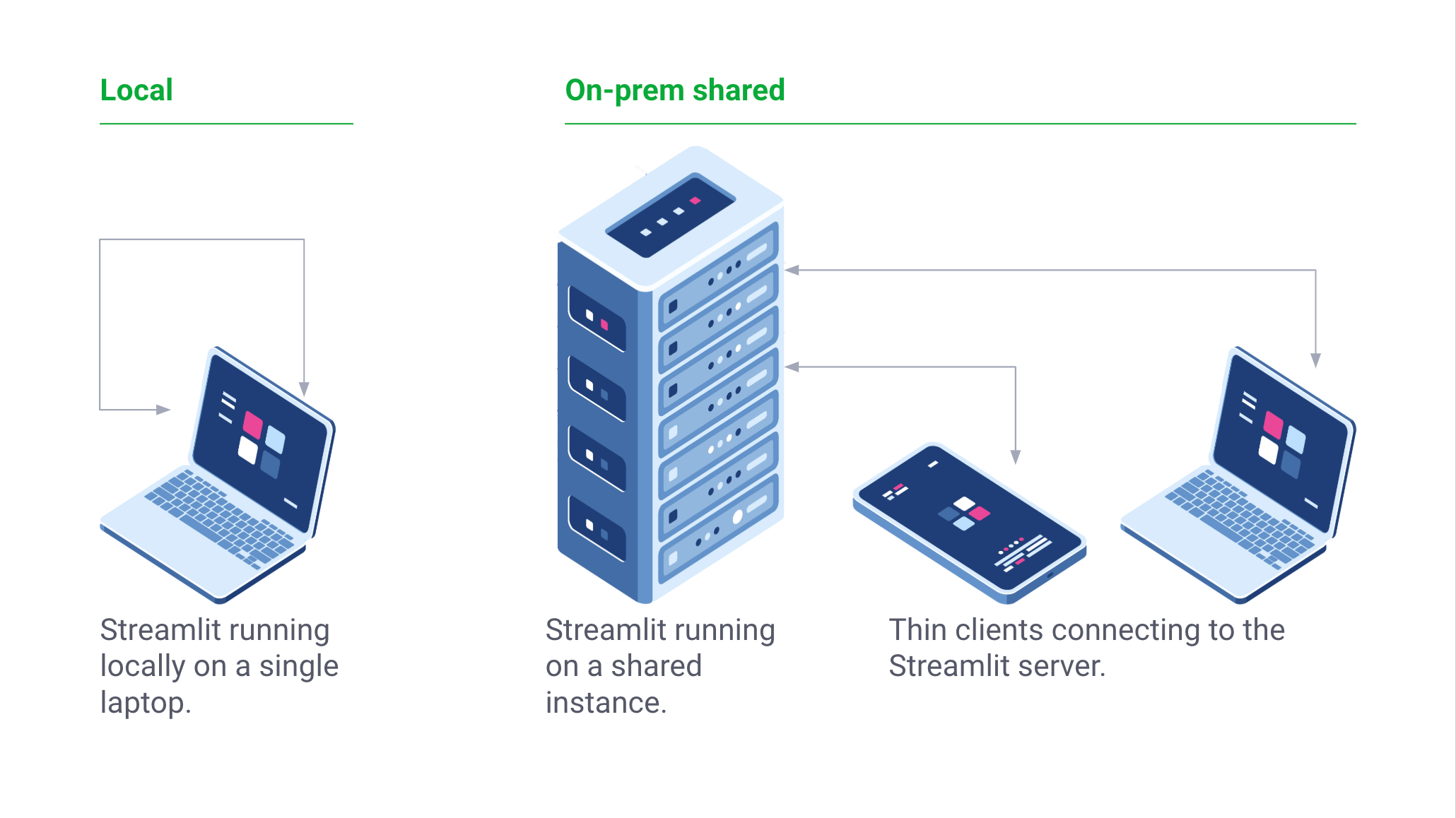
Streamlit — это бесплатная open-source библиотека, а не проприетарное веб-приложение. Приложения Streamlit можно обслуживать локально. Streamlit также можно запустить локально на ноутбуке без подключения к интернету! Более того, существующие проекты могут постепенно принимать Streamlit.
Мы рассмотрели лишь некоторые из возможностей Streamlit. Одним из наиболее интересных его аспектов является легкость объединения примитивов в сложные приложения, похожие на сценарии.
Читайте также:
- Создаем чат-бот в Python с помощью nltk
- Введение в модульное тестирование на Python
- Альтернатива switch в Python
Перевод статьи Adrien Treuille: Turn Python Scripts into Beautiful ML Tools





