
Предположим, вы на вечеринке беседуете с милой девушкой. Вас атакует множество звуков: разговоры людей по всему дому, громко играющая на фоне музыка. Тем не менее ничто из этого не мешает вам сосредоточиться на том, что говорит девушка, потому что люди обладают врожденной способностью различать звуки.
Однако, если бы происходящее было сценой фильма, микрофон, который использовался бы для записи разговора, не обязательно обладал бы способностью различать все звуки в комнате. И вот здесь в игру вступает анализ независимых компонент, АНК.
АНК — это вычислительный метод, разделяющий многомерный сигнал на компоненты. Используя АНК, можно выделить нужный компонент (беседа с девушкой, например) из комплекса сигналов.
Алгоритм анализа независимых компонент
АНК можно разбить на следующие шаги:
- Центрирование массива x вычитанием среднего значения.
- Избавление от корреляции.
- Выбор случайного начального значения для демикширования матрицы w.
- Расчет нового значения w.
- Нормализация w.
- Проверка сходимости алгоритма. Если сходимости нет — возврат к шагу 4.
- Вычисление скалярного произведения w и x для получения независимых источников сигналов.
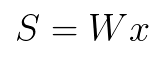
Избавление от корреляции
Прежде чем применять алгоритм АНК, необходимо избавиться от корреляции. Это означает, что мы преобразовываем сигнал таким образом, чтобы потенциальные корреляции между его компонентами исчезли (ковариация стала равна 0), а дисперсия каждого компонента стала равна 1. Также можно сказать, что ковариационная матрица будет равна единичной матрице.
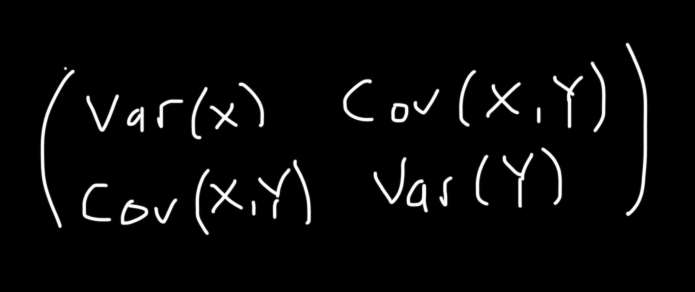
Фактический способ, которым мы избавляемся от корреляции, включает в себя разложение по собственным значениям его ковариационной матрицы. Соответствующее математическое уравнение может быть описано так:
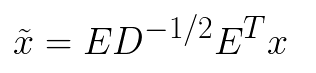
Где D — это диагональная матрица собственных значений (каждая лямбда является собственным значением ковариационной матрицы),
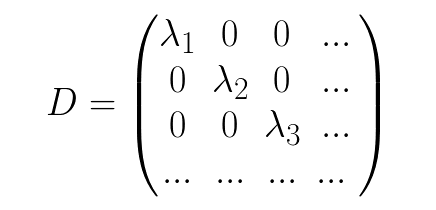
а E — ортогональная матрица собственных значений.
Завершив предварительную обработку сигнала, для каждого компонента обновляем значения демикшированной матрицы w до тех пор, пока алгоритм не сойдется или не будет достигнуто максимальное количество итераций. Когда скалярное произведение w и ее транспонированной матрицы примерно равно 1, сходимость считается достигнутой.

где
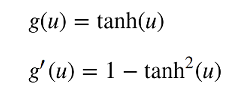
Код Python
Давайте посмотрим, как реализовать АНК в Python, используя Numpy.
Для начала импортируем следующие библиотеки:
import numpy as np
np.random.seed(0)
from scipy import signal
from scipy.io import wavfile
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(rc={'figure.figsize':(11.7,8.27)})Теперь задаем g и g’, которые будем использовать для определения нового значения w:
def g(x):
return np.tanh(x)
def g_der(x):
return 1 - g(x) * g(x)
Создаем функцию, чтобы центрировать сигнал вычитанием среднего:
def center(X):
X = np.array(X)
mean = X.mean(axis=1, keepdims=True)
return X- meanОпределяем функцию для избавления от корреляции методом, описанным выше:
def whitening(X):
cov = np.cov(X)
d, E = np.linalg.eigh(cov)
D = np.diag(d)
D_inv = np.sqrt(np.linalg.inv(D))
X_whiten = np.dot(E, np.dot(D_inv, np.dot(E.T, X)))
return X_whitenОпределяем функцию для обновления демикшированной матрицы w:
def calculate_new_w(w, X):
w_new = (X * g(np.dot(w.T, X))).mean(axis=1) - g_der(np.dot(w.T, X)).mean() * w
w_new /= np.sqrt((w_new ** 2).sum())
return w_newНаконец, определяем основной метод, вызывающий функции предварительной обработки, инициализирующий w случайным набором значений и итерационно обновляющий w. На сходимость указывает тот факт, что идеальная w будет ортогональной, следовательно, произведение w и ее транспонированной матрицы будет примерно равно 1. После расчета оптимального значения w для каждого компонента возьмем скалярное произведение полученной матрицы и сигнала x, чтобы получить источники:
def ica(X, iterations, tolerance=1e-5):
X = center(X)
X = whitening(X)
components_nr = X.shape[0]
W = np.zeros((components_nr, components_nr), dtype=X.dtype)
for i in range(components_nr):
w = np.random.rand(components_nr)
for j in range(iterations):
w_new = calculate_new_w(w, X)
if i >= 1:
w_new -= np.dot(np.dot(w_new, W[:i].T), W[:i])
distance = np.abs(np.abs((w * w_new).sum()) - 1)
w = w_new
if distance < tolerance:
break
W[i, :] = w
S = np.dot(W, X)
return S
Определяем функцию для построения и сравнения оригинальных, смешанных и предсказанных сигналов:
def plot_mixture_sources_predictions(X, original_sources, S):
fig = plt.figure()
plt.subplot(3, 1, 1)
for x in X:
plt.plot(x)
plt.title("mixtures")
plt.subplot(3, 1, 2)
for s in original_sources:
plt.plot(s)
plt.title("real sources")
plt.subplot(3,1,3)
for s in S:
plt.plot(s)
plt.title("predicted sources")
fig.tight_layout()
plt.show()
Дальше для примера создадим метод для искусственного смешивания сигналов из различных источников:
def mix_sources(mixtures, apply_noise=False):
for i in range(len(mixtures)):
max_val = np.max(mixtures[i])
if max_val > 1 or np.min(mixtures[i]) < 1:
mixtures[i] = mixtures[i] / (max_val / 2) - 0.5
X = np.c_[[mix for mix in mixtures]]
if apply_noise:
X += 0.02 * np.random.normal(size=X.shape)
return XЗатем создадим три сигнала, каждый из которых имеет собственный шаблон:
n_samples = 2000
time = np.linspace(0, 8, n_samples)
s1 = np.sin(2 * time) # синусоидальная волна
s2 = np.sign(np.sin(3 * time)) # меандр
s3 = signal.sawtooth(2 * np.pi * time) # пилообразная волнаВ следующем примере вычисляем скалярное произведение матрицы A и сигналов для получения комбинации всех трех. Затем используем АНК, чтобы разделить смешанный сигнал на исходные:
X = np.c_[s1, s2, s3]
A = np.array(([[1, 1, 1], [0.5, 2, 1.0], [1.5, 1.0, 2.0]]))
X = np.dot(X, A.T)
X = X.T
S = ica(X, iterations=1000)
plot_mixture_sources_predictions(X, [s1, s2, s3], S)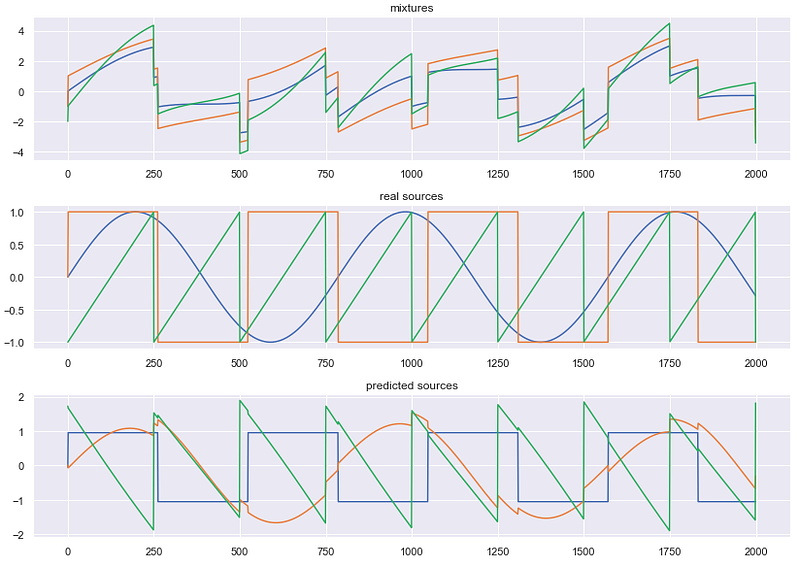
Теперь используем АНК для разложения смеси реальных аудиодорожек и отображения результата. Если вы хотите попробовать сделать это сами, можете найти аудиодорожки здесь.
sampling_rate, mix1 = wavfile.read('mix1.wav')
sampling_rate, mix2 = wavfile.read('mix2.wav')
sampling_rate, source1 = wavfile.read('source1.wav')
sampling_rate, source2 = wavfile.read('source2.wav')
X = mix_sources([mix1, mix2])
S = ica(X, iterations=1000)
plot_mixture_sources_predictions(X, [source1, source2], S)
wavfile.write('out1.wav', sampling_rate, S[0])
wavfile.write('out2.wav', sampling_rate, S[1])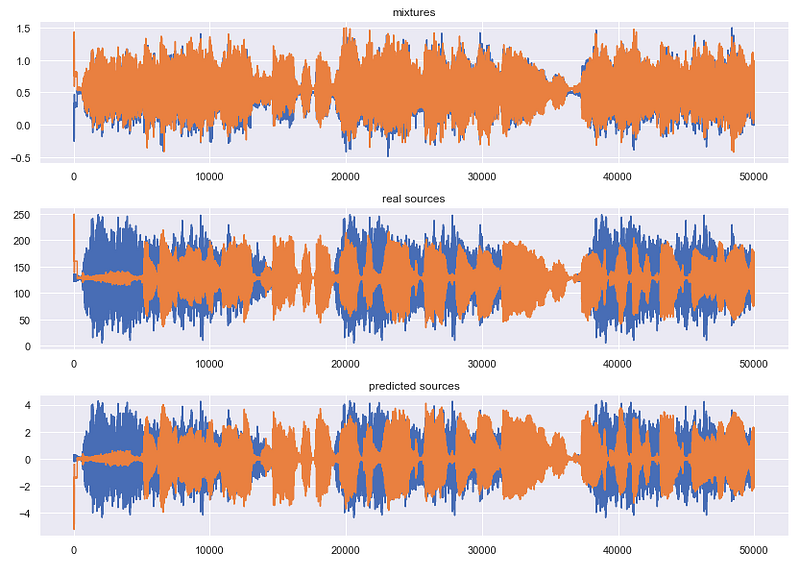
Sklearn
Наконец, посмотрим, как можно получить тот же результат, используя scikit-learn.
from sklearn.decomposition import FastICA
np.random.seed(0)
n_samples = 2000
time = np.linspace(0, 8, n_samples)
s1 = np.sin(2 * time)
s2 = np.sign(np.sin(3 * time))
s3 = signal.sawtooth(2 * np.pi * time)
S = np.c_[s1, s2, s3]
S += 0.2 * np.random.normal(size=S.shape)
S /= S.std(axis=0)
A = np.array([[1, 1, 1], [0.5, 2, 1.0], [1.5, 1.0, 2.0]])
X = np.dot(S, A.T)
ica = FastICA(n_components=3)
S_ = ica.fit_transform(X)
fig = plt.figure()
models = [X, S, S_]
names = ['mixtures', 'real sources', 'predicted sources']
colors = ['red', 'blue', 'orange']
for i, (name, model) in enumerate(zip(names, models)):
plt.subplot(4, 1, i+1)
plt.title(name)
for sig, color in zip (model.T, colors):
plt.plot(sig, color=color)
fig.tight_layout()
plt.show()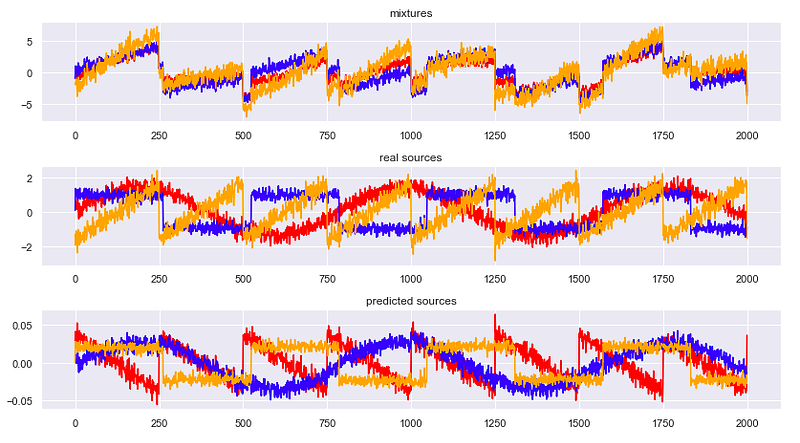
Читайте также:
- 5 задач для Python
- Значение Data Science в современном мире
- Шесть рекомендаций для начинающих специалистов по Data Science
Перевод статьи Cory Maklin: Independent Component Analysis (ICA) In Python




