
Посмотрим правде в глаза.
Большинство специалистов в области инжиниринга данных могут перечислить модные инструменты вроде Airflow, Snowflake, dbt, Kafka, но теряют дар речи, когда требуется объяснить, почему подготовленное ими PySpark-задание вызвало сбой в кластере.
Если вы не хотите относиться к их числу, освойте 5 ключевых понятий инжиниринга данных.
Понимание этих пяти архитектурных концепций (именно понимание, а не запоминание) позволит вам быть на голову выше многих своих коллег. И неважно, являетесь ли вы начинающим разработчиком, уставшим от неработающих пайплайнов дата-сайентистом или руководителем, пытающимся понять, почему счет за облачные услуги так высок.
Итак, начнем.
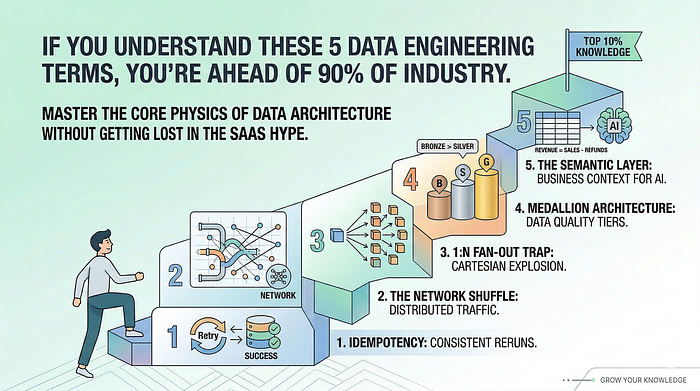
1. Идемпотентность (idempotency)
Первое, что необходимо усвоить: пайплайны обработки данных дают сбои. Причем постоянно: то API недоступен, то в кластере заканчивается память, то исходные данные поступают с задержкой.
Что происходит, когда пайплайн выходит из строя на полпути и его приходится запускать заново?
Понять причину отказа помогает понятие идемпотентности.
Идемпотентным считается пайплайн, который можно запустить один, два или пятьдесят раз подряд, и конечное состояние базы данных останется точно таким же, как если бы он был запущен всего один раз.
Если пайплайн использует команду INSERT (вставка), двойной запуск приведет к дублированию всех данных. Дэшборды начнут показывать удвоенную выручку, и генеральный директор запаникует. Идемпотентный пайплайн, использующий команды типа MERGE (объединение) или Upsert (обновление или вставка), безопасно удаляет и заменяет конкретные разделы. Он обращается к базе данных, придерживаясь следующей логики: «При наличии строки — выполнить обновление, при отсутствии — вставку«.
Почему это важно?
Младшие инженеры разрабатывают пайплайны, предполагая, что все пойдет правильно. Старшие инженеры создают идемпотентные пайплайны, зная, что все может пойти неправильно. Усвоив понятие идемпотентности, вы перестанете просыпаться в холодном поту в три часа ночи в панике, что повредили рабочую базу данных, нажав «retry» («повторить») на DAG (Directed Acyclic Graph — направленный ациклический граф) в Airflow.
2. Сетевая перетасовка (network shuffle)
Представьте, что вы управляете коммерческой кухней. У вас есть десять поваров (исполнителей), которые нарезают овощи на своих рабочих местах. Это невероятно быстро.
Но внезапно вы приказываете поварам сгруппировать весь нарезанный лук на одном столе, всю морковь — на другом, а весь сельдерей — на третьем. Начинается хаос. Повара бегают по кухне, сталкиваются друг с другом, переносят миски с овощами и выстраиваются в очереди. Никто уже не нарезает — все только перемещают продукты.
Подобная перетасовка (shuffle) может происходить в пайплайне.
В распределенных вычислениях (например, в Apache Spark или Databricks) ваши данные распределены между несколькими вычислительными узлами. Если вы выполняете команду типа .filter() (фильтрация), узлы обрабатывают данные там, где они находятся. Это происходит молниеносно. Но если вы выполняете команду типа .groupBy() (группировка) или .join() (соединение), движок вынужден физически перемещать огромные объемы данных по сети, чтобы сгруппировать совпадающие ключи.
Почему это важно?
Перетасовка — самая дорогая и самая медленная операция в инжиниринге данных с точки зрения потребления ресурсов. Именно из-за нее пайплайн выполняется четыре часа вместо четырех минут.
Понимая механизм перетасовки, вы перестанете пытаться ускорить медленный код простым добавлением памяти в кластер. Вместо этого, меняете логику: фильтруете данные перед соединением, транслируете таблицы меньшего размера, оптимизируете физику данных, а не только аппаратное обеспечение.
3. Ловушка размножения «один ко многим» (1:N Fan-Out)
Это мой любимый пример для объяснения, поскольку речь идет о «тихом убийце» бюджетов, выделенных на облачные вычисления.
Соединяя две таблицы с помощью SQL, вы сопоставляете строки на основе ключа.
Если в таблице A 1000 строк и вы выполняете LEFT JOIN (левое внешнее соединение) с таблицей B, то ожидаете, что в результате по-прежнему будет 1000 строк, так?
Так, если только в таблице B нет дубликатов.
Если же вы соединяете таблицу users с таблицей purchases и у одного пользователя есть пять покупок, то одна строка этого пользователя будет продублирована пять раз в вашем выводе. Это отношение «один ко многим» (1:N — one-to-many).
Представьте, что вы случайно делаете это с таблицей, содержащей 100 миллионов строк, соединяя ее с журнальной таблицей, содержащей миллиарды событий (кликов).
Почему это важно?
Вы только что вызвали декартов взрыв (экспоненциальное разрастание данных). Ваша таблица на 100 миллионов строк за несколько секунд «размножилась» в монстра размером в 50 миллиардов строк. Ваш кластер Spark исчерпывает оперативную память, начинает сбрасывать данные на диск и в конечном итоге выходит из строя, сжигая при этом сотни долларов за облачные вычисления.
Понимание ловушки размножения означает, что вы никогда не напишете соединение JOIN без тщательной проверки степени детализации (уникальности) соединяемых таблиц.
4. Медальонная архитектура (medallion architecture)
Эту концепцию используют все, но далеко не все правильно реализуют.
Если вы выгружаете необработанные JSON-файлы из приложения непосредственно на дэшборд для бизнес-пользователей, вас ждут серьезные проблемы. Данные неструктурированы, содержат вложенные элементы и полны ошибок.
Медальонная архитектура — способ навести порядок в озере данных (Data Lakehouse). Это концепция организации данных по трем уровням качества:
- Бронза (Bronze): Необработанные, нефильтрованные данные точно в том виде, в котором они поступили. Если исходная система выйдет из строя, у вас всегда останутся исходные данные уровня «бронза» для повторного воспроизведения.
- Серебро (Silver): Очищенные, отфильтрованные и типизированные данные (с приведенными к нужным типам полями). Устранены дубликаты и проведена стандартизация.
- Золото (Gold): Агрегированные на бизнес-уровне данные. Это высокоуровневая схема «звезда» (Star Schema), где данные предварительно соединены и готовы для выполнения запросов руководства.
Почему это важно?
Если бизнес-заказчик жалуется, что метрика рассчитана неверно, медальонная архитектура точно подскажет, как проводить отладку. Вам не придется распутывать SQL-запрос из 500 строк. Вы проверяете таблицу уровня «золото». Если логика неверна там, вы исправляете ее. Если таблица уровня «золото» в порядке, проверяете таблицу уровня «серебро» на наличие пропущенных данных. Этот подход превращает хаотичное болото данных в управляемую и проверяемую цепочку.
5. Семантический слой (semantic layer)
Эта концепция — самая неверно понимаемая из всех пяти, особенно сегодня, когда в игру вступил искусственный интеллект
Прямо сейчас каждый генеральный директор хочет иметь чат-бота, который преобразует текст в SQL и мгновенно выдает ответ на промпт: «Какова была наша выручка за прошлый месяц?«.
Если направить LLM (большую языковую модель) напрямую в необработанную базу данных, она начнет галлюцинировать. Модель не знает, означает ли «выручка» столбец gross_sales (валовая выручка) или столбец net_arr (чистая выручка на основе годовых контрактов). Она не знает, что необходимо отфильтровать возвращенные транзакции.
Вот тут-то и нужен семантический слой.
Семантический слой (с использованием таких инструментов, как dbt) — место определения бизнес-метрик в коде. Здесь пишется точно сформулированное определение: «Выручка = валовая выручка минус возвраты, где статус = «активный»
Почему это важно?
Семантический слой не позволяет искусственному интеллекту угадывать соединения (JOIN) в SQL. Вы направляете ИИ делать запросы к семантическому слою. ИИ запрашивает метрику «выручка», а семантический слой переводит этот запрос в безупречно точный, утвержденный человеком SQL-код.
Чтобы создавать корпоративных ИИ-агентов, можно обойтись без продвинутого промпт-инжиниринга. Достаточно прописать семантический слой.
Добро пожаловать в топ-10% специалистов
Разница между программистами, умеющими только писать Python-скрипты, и специалистами, знающими, как на самом деле работают распределенные системы, огромна.
Вам не стоит запоминать каждый инструмент, появившийся на ProductHunt. Гораздо важнее освоить 5 ключевых концепций инжиниринга данных. Идемпотентность обеспечит вашим конвейерам долгую жизнь. Перетасовка и ловушка размножения позволят вашей компании сэкономить тысячи долларов на облачных вычислениях. Медальонная архитектура сделает ваши данные по-настоящему управляемыми, а семантический слой поможет создать инфраструктуру искусственного интеллекта завтрашнего дня.
Вот и все. Всего лишь пять концепций из реального инжиниринга.
Добро пожаловать в топ-10% инженеров данных.
Читайте также:
- Инженерия данных — не только для инженеров!
- Как создать первый проект по инженерии данных: инкрементный подход. Часть 1
- 3 распространенные ошибки при поиске работы в области науки о данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи B V Sarath Chandra: If You Understand These 5 Data Engineering Terms, You’re Ahead of 90% of the Industry




