
Я смотрю на «тормозящую» группу потребителей, которая отстает уже три часа. В канале для обсуждения координации управления тихо, но метрики отставания просто зашкаливают.
Обычно именно в этот момент ты понимаешь, что твоя «простая» архитектура pub-sub на самом деле — бомба замедленного действия, полная необработанных пограничных случаев.
Последние пять лет я провел, мечась между Go и Java и сражаясь с высоконагруженными системами. Если я что-то и усвоил, так это то, что Kafka — это не база данных и уж точно не просто «быстрая очередь». Это распределенная система, которая приносит с собой сложность.
Вот пять шаблонов, которые обеспечили мне спокойный сон.
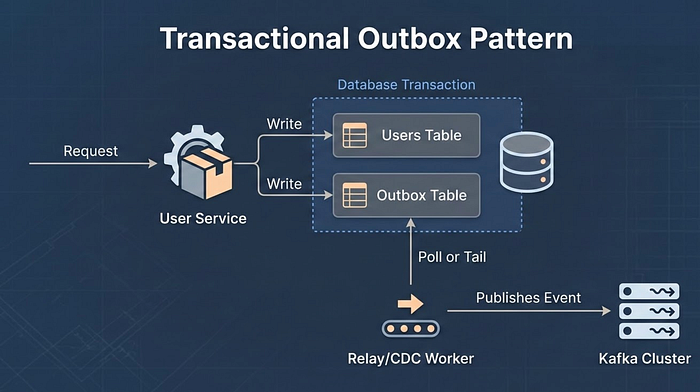
1. Шаблон Outbox: Согласованность без распределенных транзакций
Все мы через это проходили: вы обновляете баланс пользователя в Postgres, но сеть дает сбой до того, как вы можете отправить событие payment_processed в Kafka. Происходит рассинхронизация базы данных и аналитики.
Шаблон Outbox — единственный способ, который спасает рассудок в такой ситуации. Вместо того чтобы обращаться к Kafka напрямую из сервиса, вы записываете событие в выделенную таблицу outbox в локальной БД в рамках той же транзакции, что и ваша бизнес-логика.
- Подход с Go: Используйте паттерн Sidecar или простой фоновый рабочий процесс с
pglogreplдля отслеживания WAL (журнала упреждающей записи) и отправки в Kafka. - Подход с Java: Здесь стандартом де-факто является Debezium, но простой способ polled outbox подойдет, если вам не нужна задержка менее секунды.
2. Перенаправление «мертвых» сообщений (топик повторных попыток)
Блокировать раздел (партицию) из-за одного «битого» сообщения — ошибка новичка. Если сообщение не обрабатывается, не стоит просто крутить его в цикле повторных попыток — так вы только увеличите задержки обработки.
Обычно я реализую многоуровневую систему повторных попыток:
- Топик А: Основная обработка.
- Топик А_Retry_5m: Если сообщение не обработалось, оно отправляется сюда с задержкой в 5 минут.
- Топик A_DLQ (Dead Letter Queue): Место для «вмешательства человека».
В одном из недавних проектов на Go перенаправление неудавшихся задач в топик повторных попыток сократило время обработки на уровне p99 примерно на 40% во время пиковых нагрузок. Это произошло потому, что одно проблемное сообщение больше не могло блокировать всего потребителя.
3. «Умное» уплотнение логов для хранения состояния
Большинство инженеров считают Kafka потоком событий, но я предпочитаю рассматривать этот инструмент как распределенную хеш-таблицу, которая ничего не забывает.
Если вы создаете микросервис, которому нужен локальный кеш «цен на товары», не вызывайте REST API 10 000 раз в секунду.
Используйте топик с уплотнением (Compacted Topic). Kafka будет хранить только последнее значение для каждого конкретного ключа. Когда ваш сервис запускается, он читает топик с самого начала, чтобы наполнить локальный SyncMap (в Go) или кеш Caffeine (в Java).
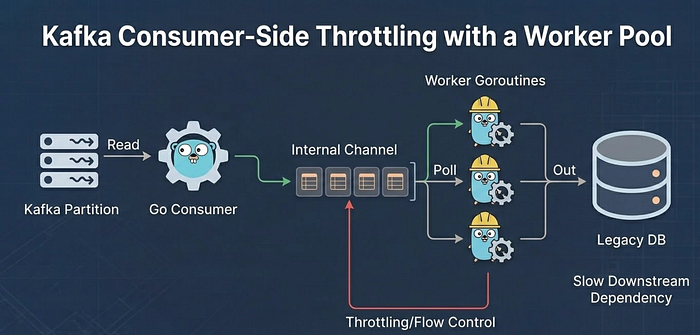
4. Троттлинг на стороне потребителя с контролем конкурентности
В Go велик соблазн просто запускать горутину под каждое сообщение Kafka. Не делайте так. Вы перегрузите свою БД или внешние API.
Я понял, что здесь необходимо использование паттерна «пул воркеров» (worker pool).
Как это работает: Отправляется пакет сообщений, они распределяются между N воркерами с помощью хеширования по ключу (чтобы сохранить порядок для конкретного ID), а смещения (offsets) фиксируются только после завершения обработки всего пакета.
5. Паттерн Saga («оркестрация» против «хореографии»)
В распределенной системе невозможно откатить транзакцию, затронувшую три микросервиса. Вместо этого нужно выполнить «компенсирующее» действие.
Я предпочитаю паттерн «хореография» для простых потоков (Сервис А отправляет событие, Сервис Б слушает). Но как быть в случае сложных сценариев, например, оформления заказа? Используйте паттерн «оркестрация».
Создайте сервис «Координатор» на Go, который управляет машиной состояния и отправляет команды в Kafka, ожидая события «Успех» или «Неудача», чтобы инициировать компенсирующие транзакции.
Проверка реальностью (бенчмарки)
В прошлом месяце я проводил тест, сравнивая стандартную модель «Один потребитель на раздел (партицию)» с моделью «Параллельные воркеры» в Go.

В результате всегда повышается сложность. Параллельные воркеры сильно усложняют управление смещениями. Если вы потеряете воркер, можно начать обрабатывать сообщения не по порядку, если не продумать стратегию разделения (партиционирования).
Математика: Во что это вам обойдется?
Давайте посмотрим на счета за инфраструктуру. Если вы используете Managed Kafka (например, Confluent или MSK), вы платите не только за брокеры — вы платите за пропускную способность и хранение.
- Сценарий: 1 ТБ данных в месяц, хранение в течение 7 дней.
- Стандартное хранилище: ~$0.10/ГБ = $100.
- Передача данных между зонами доступности (Inter-AZ): Это «тихий убийца». Если ваши продюсеры (producers) находятся в
us-east-1a, а брокеры — в1b, вы платите ~$0.01 за ГБ.
- Математика «Упс!»: Если вы случайно дублируете отправку данных или у вас возникают «шумные» повторные попытки, счет за хранилище в $100 может легко вырасти до $800+ после учета сетевых расходов между регионами и PIOPS.
Профессиональный совет: Включите сжатие zstd. Оно нагружает процессор чуть сильнее, чем snappy, но я замечал, что это снижает расходы на хранение JSON-данных на 30-50%.
Окончательное решение
Kafka — это зверь, но его поведение можно предсказать, если относиться к нему с уважением.
- Используйте Outbox, если для вас важна целостность данных.
- Используйте Уплотнение (Compaction), чтобы не стучаться в базу данных за «read-only» конфигурационными данными.
- Используйте Топики повторных попыток (Retry Topics), чтобы поток обработки не останавливался.
Если вы только начинаете проект с низким трафиком, просто используйте очередь на базе Postgres или RabbitMQ. Но если вы выходите на 10 000+ событий в секунду, эти паттерны — не просто рекомендация, а руководство к выживанию.
Я собираюсь идти спать. Оповещения об отставании не срабатывали уже двадцать минут, так что, думаю, пул воркеров справляется с работой.
Читайте также:
- ClickHouse + Kafka =
- Почему Java продолжит управлять крупномасштабными бэкенд-системами в 2026 году
- Рынок бэкенд-разработки в 2026 году: что на самом деле нужно менеджерам по найму
Читайте нас в Telegram, VK и Дзен
Перевод статьи Abhinav: 5 Kafka Design Patterns Every Backend Engineer Should Know





