
В этой статье я расскажу о том, как использовать Node.js, чтобы выполнить быстрый и эффективный веб-скрапинг для одностраничных приложений. С помощью веб-скрапинга можно собирать и использовать ценные данные, которые не всегда доступны через API. Приступим.
Что такое веб-скрапинг?
Веб-скрапинг — это метод, используемый для извлечения данных с веб-сайтов с помощью скрипта. Он помогает автоматизировать трудоемкую работу по копированию данных с различных веб-сайтов.
Обычно его используют в тех случаях, когда нужные веб-сайты не предоставляют API для извлечения данных. Рассмотрим несколько общих сценариев использования инструментов веб-скрапинга:
- Скрапинг почтовых ящиков (emails)потенциальных клиентов с различных веб-сайтов.
- Скрапинг новостей с новостных сайтов.
- Скрапинг данных о товарах с коммерческих веб-сайтов.
Зачем нужен веб-скрапинг, когда коммерческие веб-сайты предоставляют API для извлечения/сбора данных о товарах?
Коммерческие веб-сайты предоставляют лишь некоторую часть данных о своих товарах для извлечения через API, поэтому веб-скрапинг намного эффективнее в сборе максимального количества данных о товарах.
Сайты, которые занимаются сравнением различной продукции, обычно пользуются веб-скрапингом. Даже поисковая система Google использует автоматическое сканирование и скрапинг, чтобы индексировать результаты поиска.
Что нам понадобится?
Начать скрапить данные не так уж и сложно. Весь процесс разделен на два простых этапа:
- Выборка данных с помощью HTTP-запроса
- Извлечение важных данных с помощью парсинга HTML DOM
Для веб-скрапинга мы будем использовать Node.JS.
Также нам понадобятся два модуля npm с открытым исходным кодом:
- axios — библиотека с поддержкой промисов, работающая на HTTP-клиенте для браузера и node.js.
- cheerio — это аналог jQuery для работы с Node.js. Cheerio позволяет легко выбирать, редактировать и просматривать элементы DOM.
Установка
Установка довольно проста. Нужно создать новую папку и запустить команду внутри этой папки, чтобы создать файл package.json. Будем следовать простой рецептуре, чтобы в итоге наше блюдо получилось восхитительным.
npm init -y
Прежде чем начать приготовление, нужно собрать ингредиенты для нашего рецепта. Добавьте Axios и Cheerio из npm в качестве зависимостей.
npm install axios cheerio
Теперь включите их в файле `index.js`
const axios = require('axios');
const cheerio = require('cheerio');
Делаем запрос
Ингредиенты для нашего блюда готовы, приступим к приготовлению. Будем извлекать данные с сайта HackerNews. Для этого потребуется сделать HTTP-запрос, чтобы получить содержимое веб-сайта. Для этого будем использовать axios.
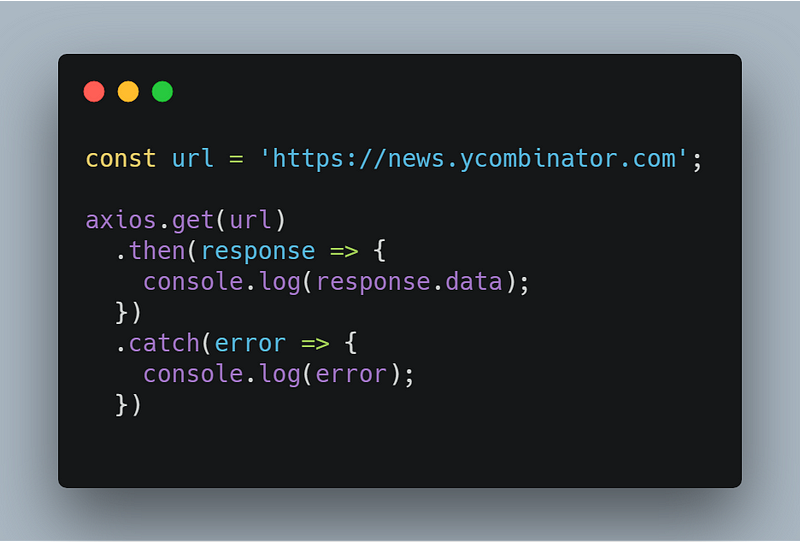
Ответ будет выглядеть таким образом:
<html op="news">
<head>
<meta name="referrer" content="origin">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" type="text/css" href="news.css?oq5SsJ3ZDmp6sivPZMMb">
<link rel="shortcut icon" href="favicon.ico">
<link rel="alternate" type="application/rss+xml" title="RSS" href="rss">
<title>Hacker News</title>
</head>
<body>
<center>
<table id="hnmain" border="0" cellpadding="0" cellspacing="0" width="85%" bgcolor="#f6f6ef">
.
.
.
</body>
<script type='text/javascript' src='hn.js?oq5SsJ3ZDmp6sivPZMMb'></script>
</html>
Мы получаем аналогичный HTML-контент, который отображается при запросе из Chrome или любого другого браузера. Теперь нам понадобятся Chrome Developer Tools для поиска по HTML-странице и выбора необходимых данных.
Извлекаем новостные заголовки и связанные с ними ссылки. Можно просмотреть HTML-страницы, нажав правой кнопкой мыши в любом месте веб-страницы и выбрав “Inspect”.
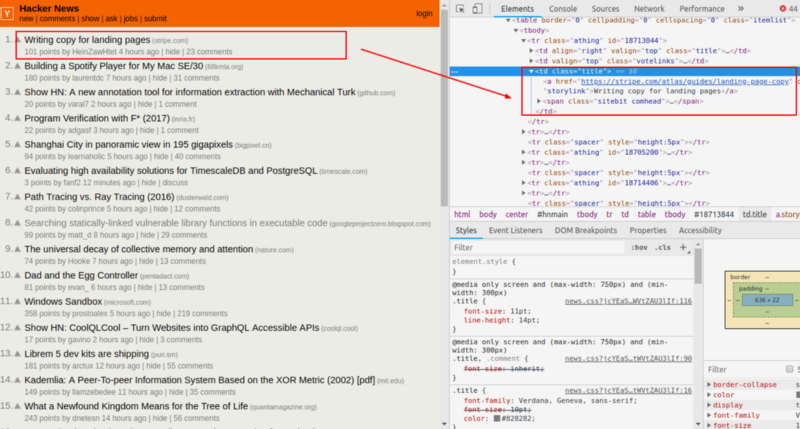
Парсинг HTML с помощью Cheerio.js
Cheerio представляет собой аналог jQuery для работы с Node.js, для выбора тегов HTML-документа используются селекторы. Синтаксис селектора был заимствован из jQuery. Ищем селектор заголовков новостей и ссылку на него с помощью Chrome DevTools. Добавим немного специй в наше блюдо.
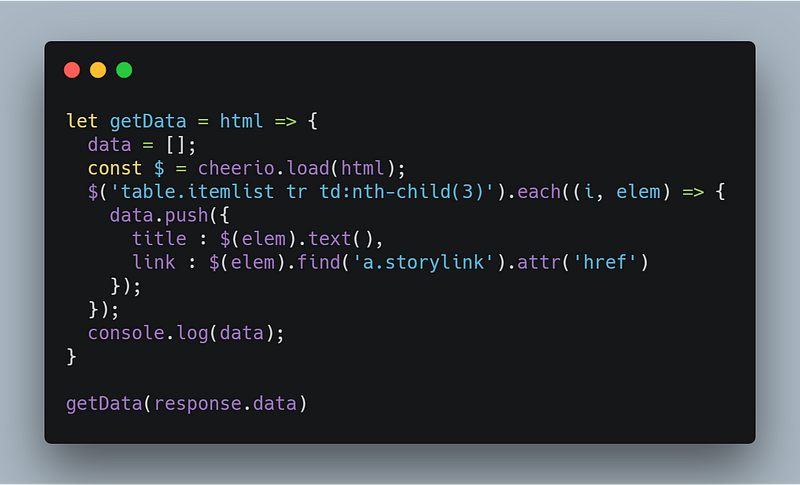
В первую очередь нужно подгрузить нужный HTML. Этот шаг в jQuery является скрытым, поскольку jQuery работает на одной встроенной DOM. Теперь в Cheerio нужно передать HTML-документ. После загрузки HTML, нужно повторить все строки таблицы <tr>, чтобы извлечь каждую новость на странице.
Выходные данные будут выглядеть следующим образом:
[
{
title: 'Malaysia seeks $7.5B in reparations from Goldman Sachs (reuters.com)',
link: 'https://www.reuters.com/article/us-malaysia-politics-1mdb-goldman/malaysia-seeks-7-5-billion-in-reparations-from-goldman-sachs-ft-idUSKCN1OK0GU'
},
{
title: 'The World Through the Eyes of the US (pudding.cool)',
link: 'https://pudding.cool/2018/12/countries/'
},
.
.
.
]
Мы получили массив объекта JavaScript, содержащий название и ссылки на новости с сайта HackerNews. Таким способом можно извлекать данные с большого количества различных веб-сайтов. А тем временем наше блюдо готово и выглядит очень аппетитно.
Заключение
Мы разобрались в том, что такое веб-скрапинг и как использовать его для автоматизации операций по сбору данных с различных сайтов.
Многие веб-сайты используют архитектуру одностраничных приложений (SPA) для динамического создания контента на своих веб-сайтах с помощью JavaScript. Мы можем получить ответ от первоначального HTTP-запроса и не можем запустить javascript для визуализации динамического содержимого с помощью axios и других подобных пакетов npm, таких как request. Следовательно, извлекать данные можно только из статических веб-сайтов.
Перевод статьи Ankit Jain: How to Perform Web-Scraping using Node.js




