
Я работаю над проектом, в котором сообщения из Kafka объединяются и записываются в Google Cloud Storage. Когда сравнил его с имеющимся решением в той же среде — тема с 50+ миллионами сообщений, он был не слишком хорош. Он завершается на час позже коннектора. Пытаясь выяснить, откуда такая задержка, я обнаружил проблемы сборщика мусора в приложении. Хотелось бы поделиться своим опытом и реализацией. В итоге отставание устранили и финишировали на 10 минут раньше.
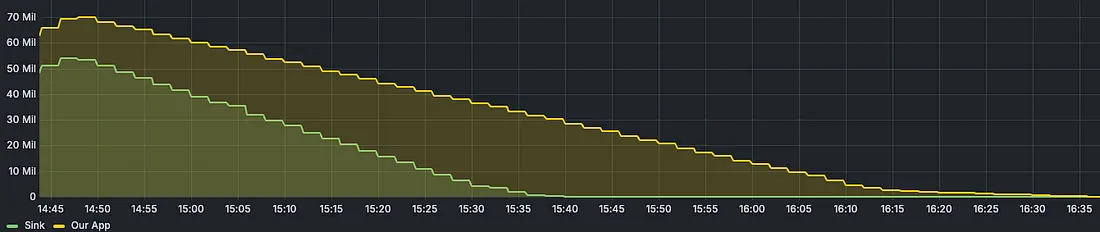
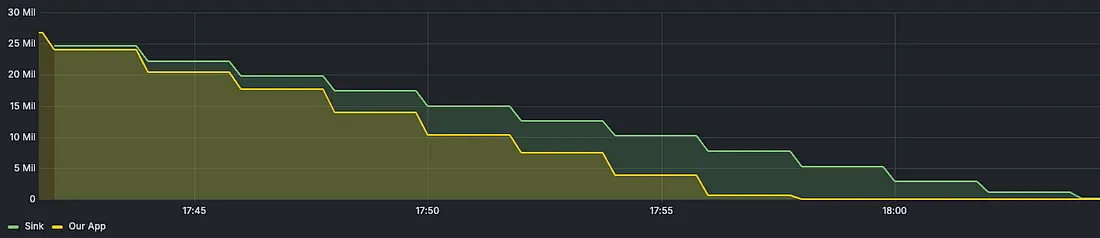
В процессе важно писать тесты производительности и читать результаты pprof, ведь «преждевременная оптимизация — корень всех зол».
Немного памяти, выделенной в стеке и куче
На Go выделение памяти осуществляется либо в стеке, либо в куче. У каждой горутины имеется собственный стек, этот непрерывный блок памяти. Куча же — это большая область общей памяти, доступная всем горутинам. Проиллюстрируем это схемой:
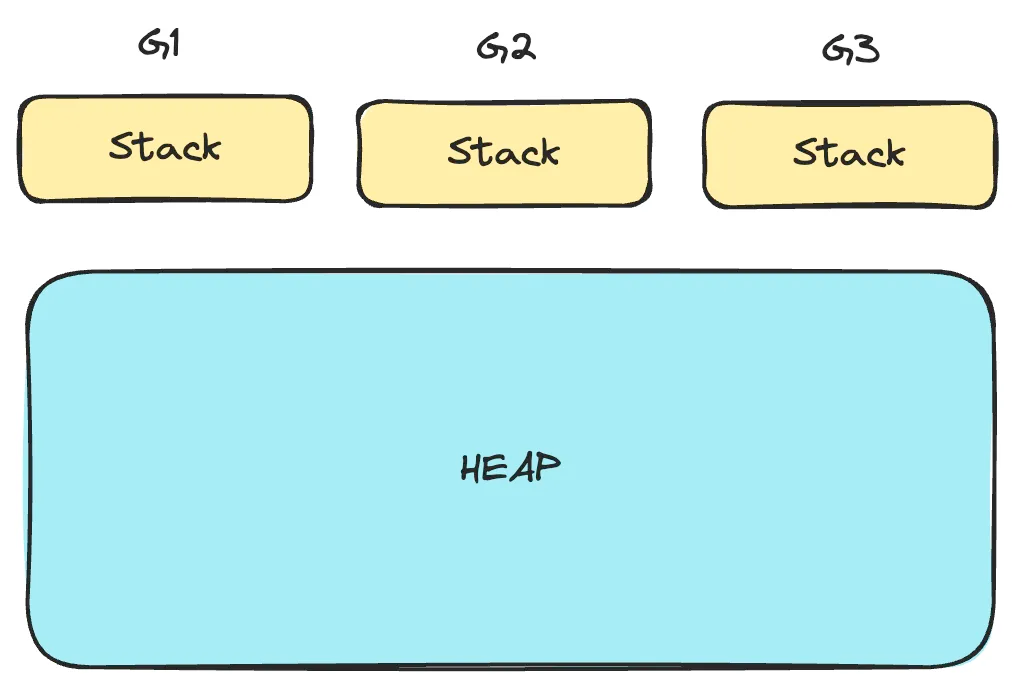
Стек самоуправляем и используется только одной горутиной. Куча же при очистке полагается на сборщик мусора. Когда в куче выделяется больше памяти, давление на сборщик мусора увеличивается. При запуске сборщика мусора им потребляется 25 % доступных ресурсов процессора, что чревато задержкой «остановки мира», во время которой приложение мгновенно приостанавливается на миллисекунды.
В целом стоимость сборки мусора прямо пропорциональна объему памяти, выделяемой программой в куче.
Вот рекомендации по уменьшению кучи:
- Применяйте sync.Pool, чтобы не инициализировать каждый раз объекты, а переиспользовать их. Будьте осторожны: некорректная реализация приносит больше вреда, чем пользы.
- Предпочитайте strings.Builder, нежели концентрироваться на
+. - Попробуйте распределять срезы и ассоциативные массивы заранее, если их размер известен.
- Сократите использование указателей.
- Старайтесь избегать больших локальных переменных в функции.
- Следите за решениями компилятора посредством вывода
go build -gcflag="-m" ./.... Обратите внимание на оптимизации встраивания — те, что с флагом -l. - Структурируйте метод выравнивания данных, используя средство контроля качества кода fieldalignment.
Вот дополнительные материалы:
- О профилировщике Go.
- Как узнать, выделена память для переменной в куче или стеке?
- Как создать поток с ограничением ЦП ядер, а не узлов?
Изменение библиотеки json
- Вместо encoding/json воспользовались библиотекой bytedance/sonic для сериализации и десериализации объектов размером ~1,50 Кб. Локальный нагрузочный тест на 100 тыс. сообщений Kafka, результаты pprof от 2,55 сек. до 0,68 сек.:
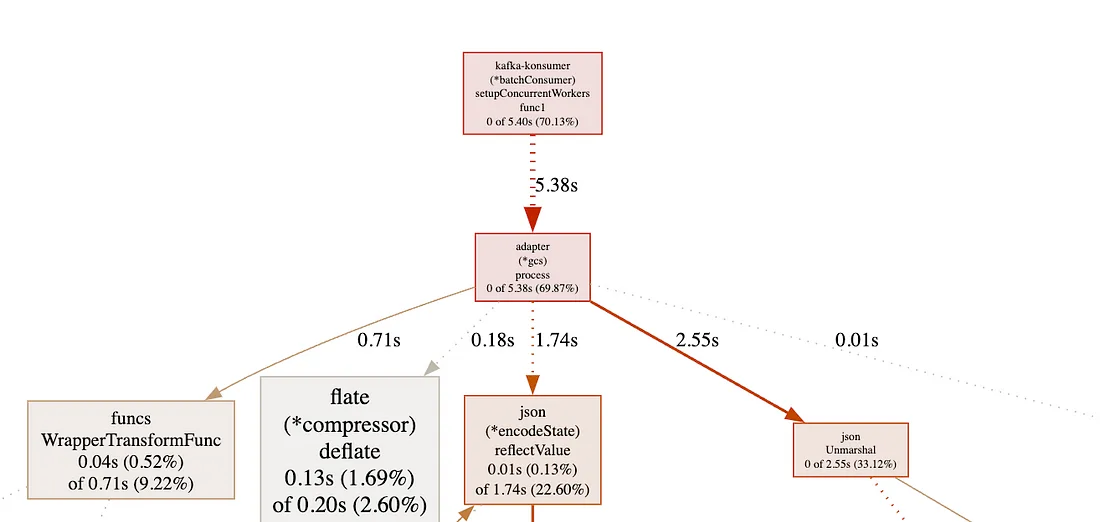
Сменой библиотеки json добиваемся роста скорости и производительности, но жертвуем стабильностью — такой вот компромисс. encoding/json оптимальнее других.
Настройка GOGC и GOMEMLIMIT
- GOGC — это переменная окружения на Go, ею задается целевой темп роста кучи и таким образом контролируется агрессивность сборщика мусора. Например, если GOGC равно 100, то перед запуском сборки мусора куча увеличивается на 100 %. Меньшие значения чреваты учащением сборки, зато памяти расходуется меньше.
- Переменной окружения GOMEMLIMIT, которая появилась в Go 1.19, задается мягкое ограничение на использование памяти для среды выполнения Go. Когда общий объём используемой программой памяти приближается к этому пределу, сборщик мусора более агрессивно старается остаться в рамках установленного бюджета. Так и управляется память в средах, где она ограничена.
Подробнее — здесь.
Мы задали GOGC=off и GOMEMLIMIT=90% лимита памяти cgroup, использовав библиотеку automemlimit. Параметром GOGC=off отключается регулярная сборка мусора, определяемая темпом роста кучи. Так что сборка мусора запускается, только когда расход памяти приближается к GOMEMLIMIT — мягкому ограничению для кучи.
Вот память и процессор нашего приложения:
resources:
limits:
cpu: '2'
memory: 4Gi
requests:
cpu: '1'
memory: 2Gi
Результаты
- Частотность пауз, вызванных работой сборщика мусора, уменьшилась с 350 до 30 вызовов в минуту:
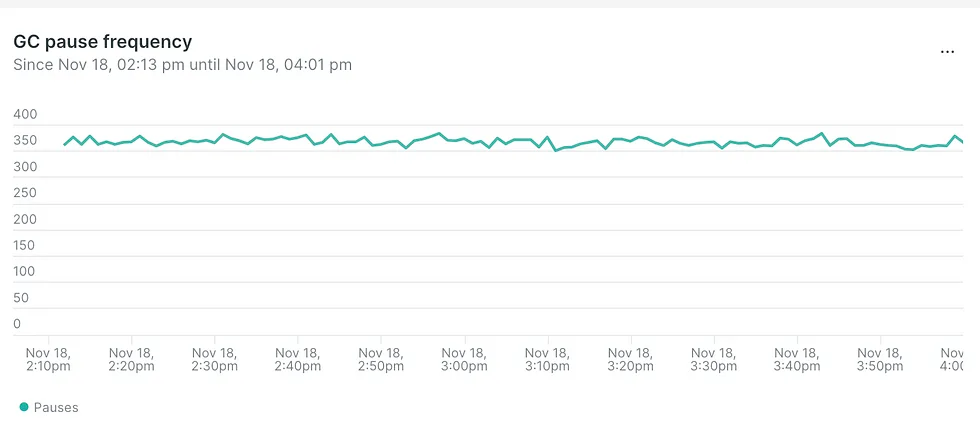
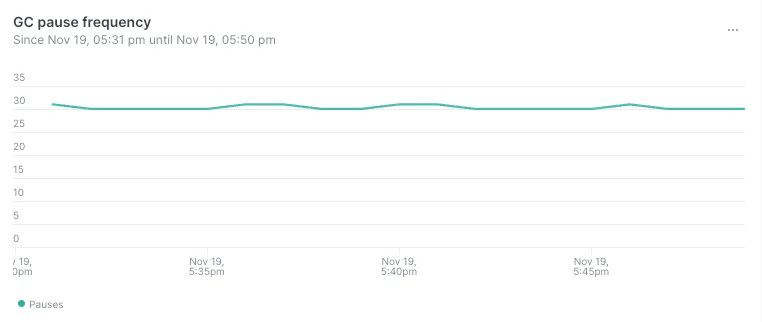
- Продолжительность пауз, вызванных работой сборщика мусора, уменьшилась с 40 мс до 400 мкс на пике:
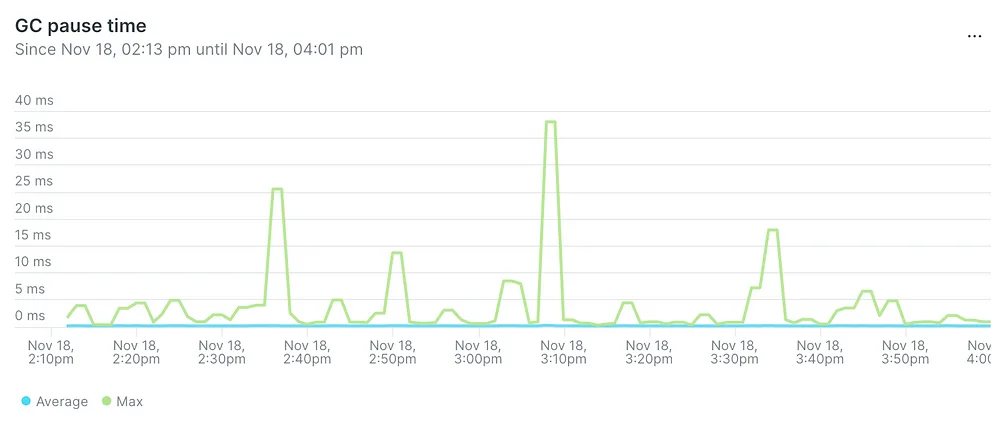
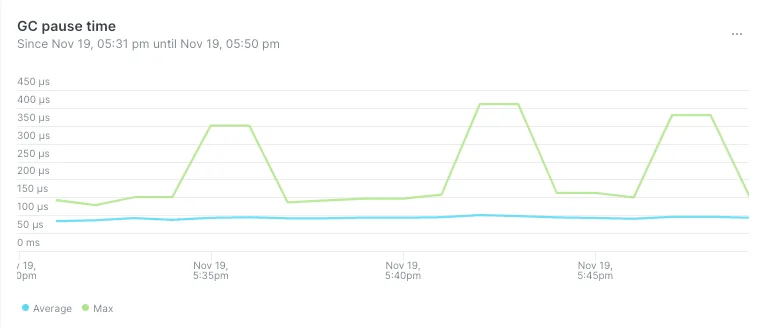
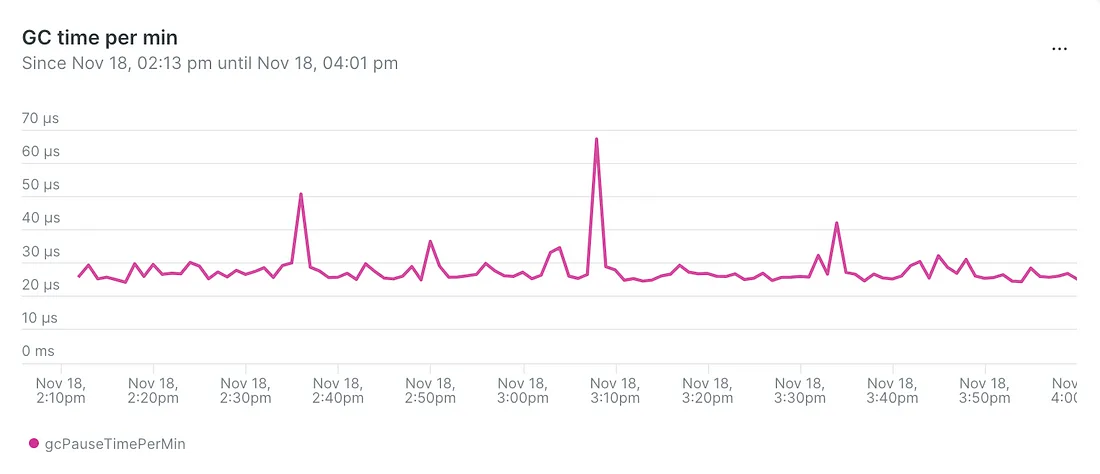
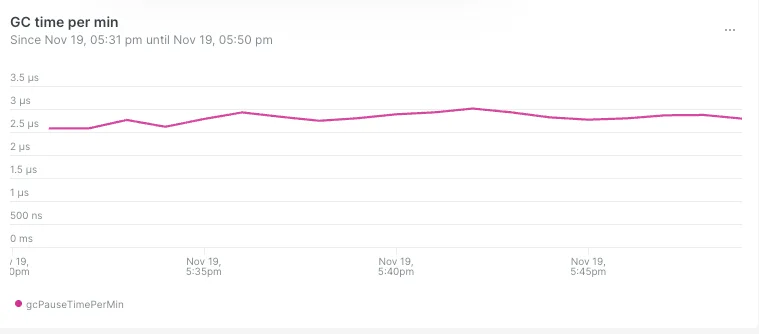
- Продолжительность сборки мусора в минуту уменьшилась с 60 мкс до 2,5 мкс:
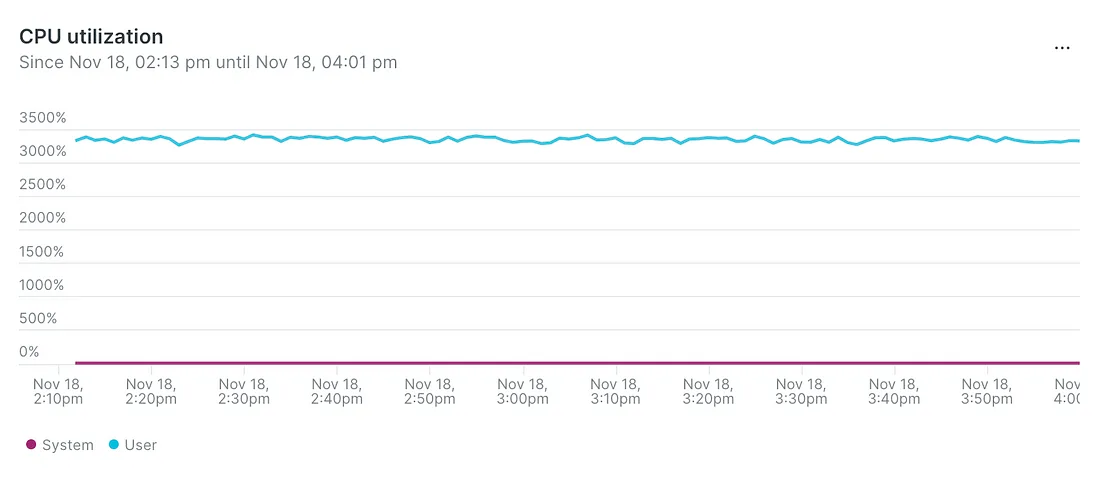
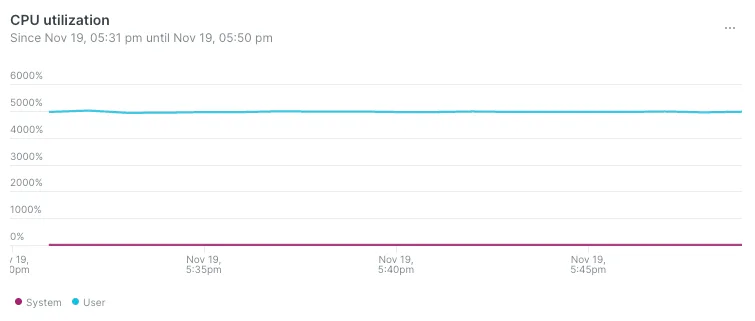
- Загрузка процессора увеличилась с 3000 до 5000 %:
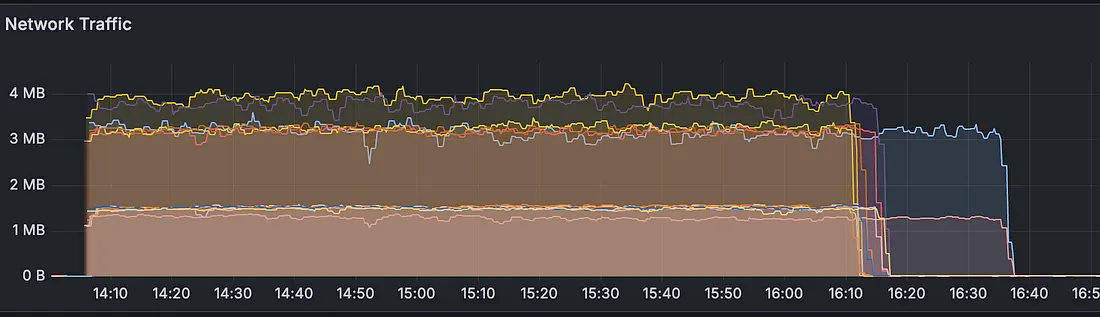
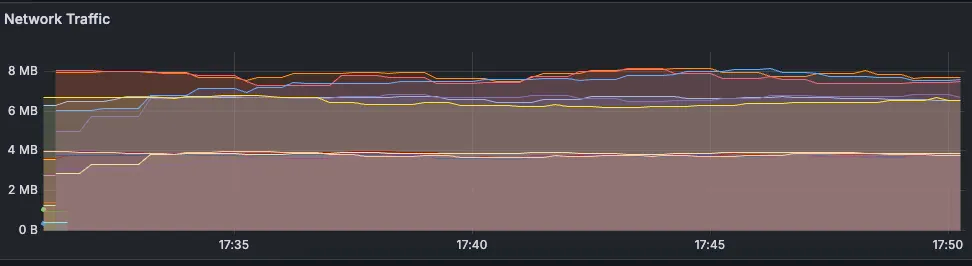
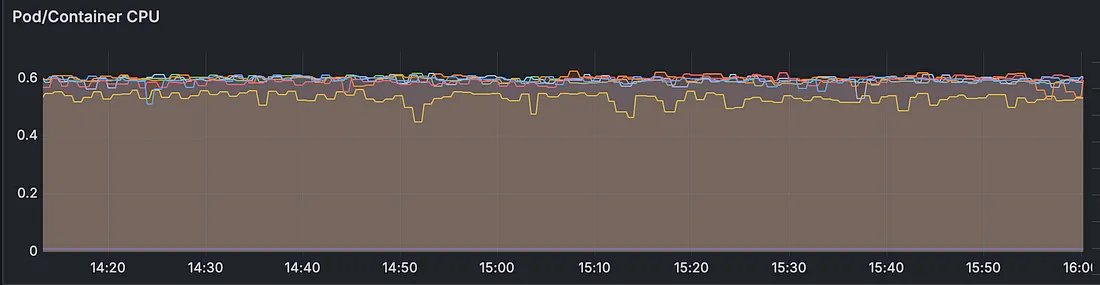
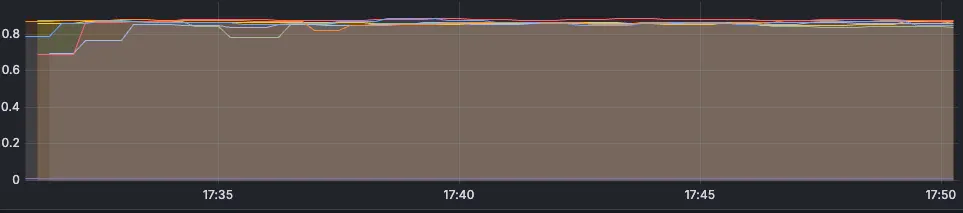
- Общий объем используемой памяти увеличился, это допустили для давления на неагрессивный сборщик мусора:
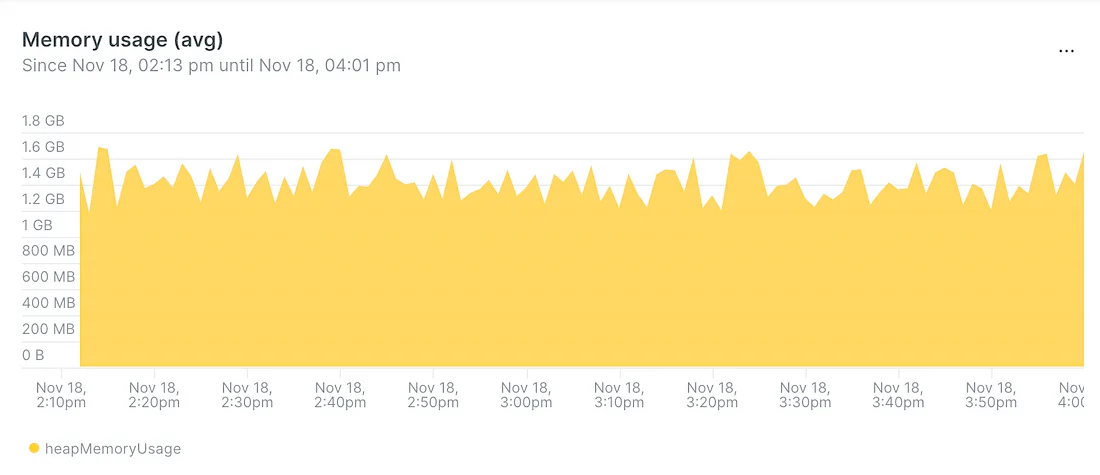
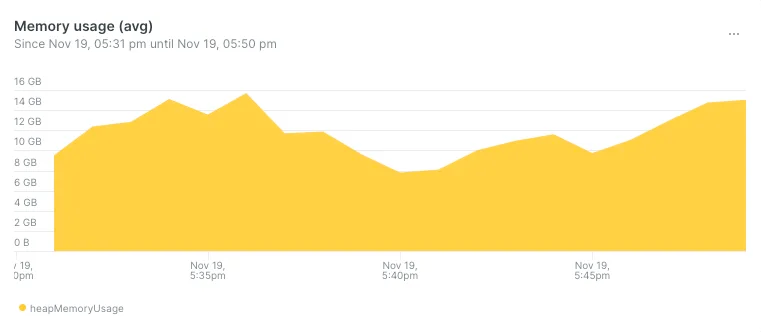
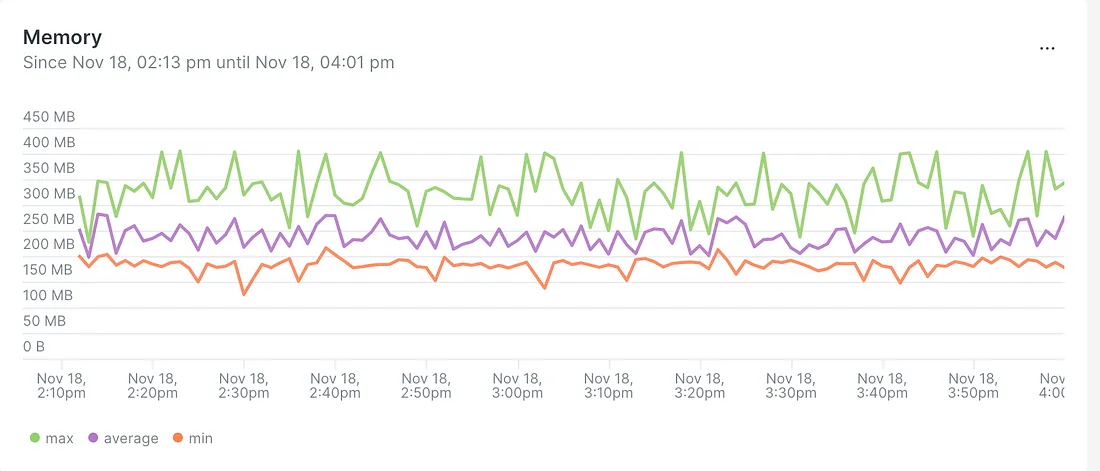
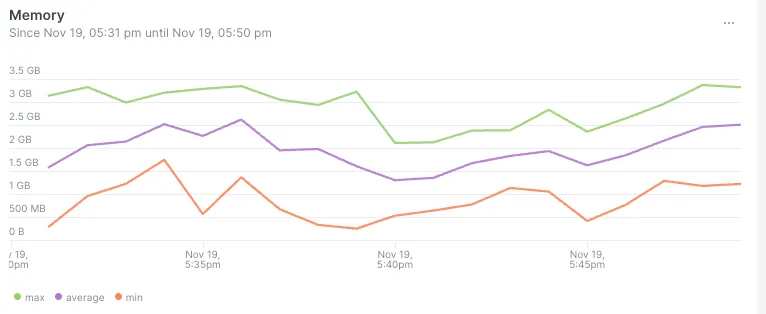
Да, памяти выделили больше, зато сократили общее время сборки мусора и использования процессора.

Читайте также:
- Контейнеризация проекта GO с Envoy
- Защита бэкенда на Go: шифрование, предотвращение уязвимостей и не только
- Как писать безопасный код на Go
Читайте нас в Telegram, VK и Дзен
Перевод статьи Abdulsamet İLERİ: Tuning Go Application, which has GC issues with a few steps





