
Данных становится всё больше
Некоторые массивы данных слишком велики, чтобы поместиться в основной памяти обычного компьютера, не говоря уже о ноутбуке. Тем не менее, все хотят работать с большими данными, но при этом не тратить время на изучение инфраструктуры Hadoop или Spark только для того, чтобы поэкспериментировать с Big Data.
Наша мечта

Было бы здорово, вот так просто взять и мгновенно загрузить терабайт данных, читая только те части, которые нам нужны, с оптимизацией, на которую умные программисты потратили десятилетия. И раз уж мы решили помечтать, хотелось бы иметь API, который немного похож на библиотеку pandas, которую мы все используем. И чтобы не требовалось слишком много памяти, потому что я работаю на своём MacBook Air 2013 года. Сегодня мы все пользуемся Jupyter notebook, поэтому нам нужна совместимость с этим инструментом. Ещё я хотел бы, чтобы все мои открытые notebook’и могли иметь совместный доступ к памяти, в которую загружен массив данных.
Вот так просто взять и мгновенно загрузить терабайт данных.
Воплощение мечты
Всё это возможно, благодаря отображению памяти (memory mapping) — это техника, при которой ОС синхронизирует части памяти с данными на диске. Технически это похоже на работу файла подкачки. Если часть памяти не изменяется или не используется некоторое время, ядро ОС очищает её, чтобы можно было повторно использовать ОЗУ. Кроме того, все процессы, которые используют один и тот же открытый файл ― используют одну и ту же физическую память.
Отображение памяти — это отличное решение, вы можете мгновенно отобразить 1TB файл в память, а ядро примет решение какие данные считывать, а какие отклонить. Теперь представьте, что вам нужно отфильтровать строки, которые содержат нерелевантные данные. В pandas мы можем сделать следующее f_filtered = df[df.x > 0]. Так мы сделаем копию всех данных (1 TB), что потребует ещё 0.8 TB… но это всё равно приведёт к MemoryError.
Встречайте Vaex
Vaex — это библиотека для Python, которая позволяет с лёгкостью работать с большими массивами данных. В дополнение к отображению памяти, Vaex позволяет не обращаться и не копировать данные, пока не поступит явный запрос к ним. Это позволяет работать с объёмом данных, сопоставимым с размером жёсткого диска. Кроме того, Vaex умеет выполнять «ленивые» вычисления, работать с виртуальными столбцами, эффективно очищать данные, быстро вычислять N-мерную статистику, создавать интерактивную визуализацию и многое другое.
Опять появится новый формат файла? Нет, мы используем старый добрый hdf5, который поддерживается любым уважающим себя языком. На самом деле, Vaex нет дела до формата файла, так как вы можете отображать данные в память ?.
Apache Arrow

Если для вас hdf5 недостаточно крутой и модный, то Vaex поддерживает Apache Arrow, который так же предлагает отображение памяти и совместимость с другими языками.
А как же pandas ??
С pandas есть некоторые проблемы, которые Уэс Маккинни (автор pandas) описывает в своём проницательном блоге: «Apache Arrow и «10 вещей, которые я ненавижу в pandas». Многие из этих проблем будут решаться в следующей версии pandas (pandas 2?), построенной поверх Apache Arrow и других библиотек. А Vaex — это начало с чистого листа, у него знакомым API, и он готов к использованию уже сегодня.
Vaex — «ленивые» вычисления

Vaex ― это не просто замена pandas. Да, у них схожий API для доступа к столбцам при выполнении выражений. Например в этом выражении: np.sqrt(ds.x**2 + ds.y**2) ― вычислений не происходит. Вместо этого создаётся объект выражения Vaex, и на выводе мы получаем превью значений.

С помощью системы выражений, Vaex выполняет вычисления только когда это нужно. Кроме того, данные не обязательно хранить локально, выражения можно отправлять по сети, а статистика будет вычисляться удалённо, благодаря пакету vaex-server.
Виртуальные столбцы
C Vaex мы можем добавлять выражения в DataFrame, которые приводят к созданию виртуальных столбцов. Виртуальный столбец ведёт себя как обычный столбец, но не занимает память. Vaex не делает различий между реальными и виртуальными столбцами, они рассматриваются на равных условиях.
А что, если вычислять выражение на лету выходит очень дорого? Используя Pythran или Numba, мы можем оптимизировать вычисления, с помощью ручной Just-In-Time (JIT) компиляции.

Также JIT компиляция выражений поддерживается для удалённых DataFrame’ов (компиляция происходит на сервере).
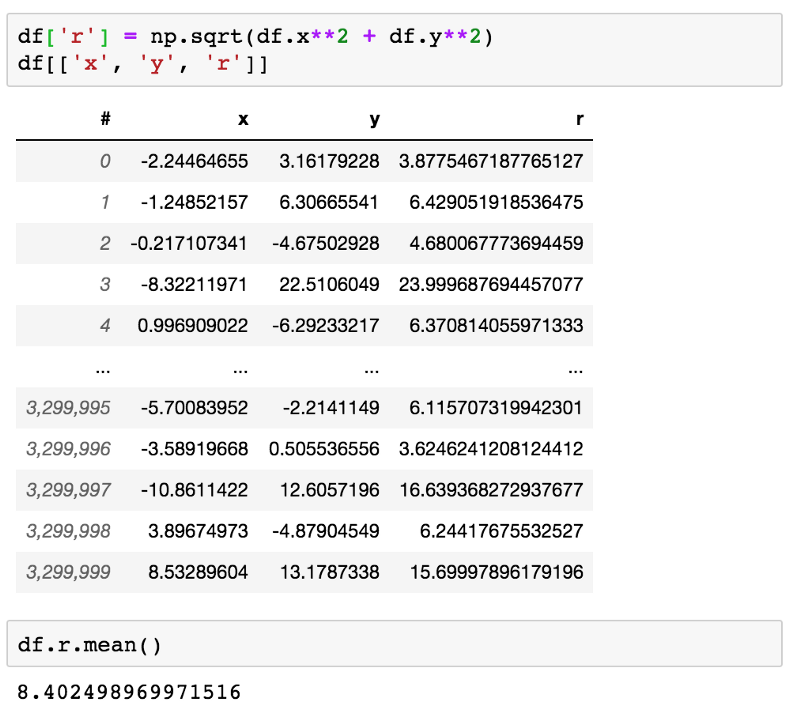
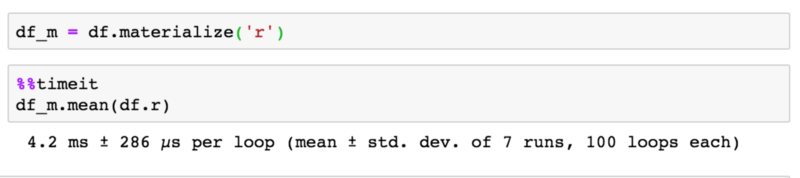
Если у вас достаточно оперативной памяти, вы можете материализовать столбец, тем самым получив дополнительную производительность за счёт RAM.
Очистка данных

Фильтрация DataFrame, например с помощью ds_filtered = ds[ds.x >0], почти не требует использования и копирования памяти, для этого просто создаётся ссылка на существующие данные плюс логическая маска, отслеживающая, какие строки выбраны, а какие нет.

Память почти не используется и не копируется.
Помимо фильтрации DataFrame, выборка может определять подмножества данных. С помощью выборок можно рассчитать статистику для нескольких подмножеств за один проход по данным. Это отлично подходит для DataFrame’ов, которые не помещаются в память (Out-of-core ― вычисления вне памяти).

Потерянные значения могут стать настоящей головной болью, а решить, что с ними делать, не всегда просто. С помощью Vaex можно легко заполнить или удалить строки пропущенных значений. Но вот в чём дело: оба метода dropna и fillna реализуются с помощью фильтрации и выражений. Это означает, что, например, можно попробовать несколько раз заполнить строки разными значениями, без дополнительных затрат памяти, независимо от размера данных.

Binned статистика
Vaex действительно силён в статистике. Поскольку мы имеем дело с Big Data, нам нужно что-то получше groupby, что-то, что работает намного быстрее. Например, можно вычислять статистику на регулярной N-мерной сетке, что намного быстрее. Например, вычисление среднего значения столбца в обычных ячейках занимает около секунды, даже если массив данных содержит миллиард строк (да, 1 миллиард строк в секунду!).

1 миллиард строк в секунду!
Визуализации
Лучший способ понять данные — это содержательные диаграммы и визуализация. Но когда DataFrame содержит миллиард строк, генерация стандартных точечных диаграмм занимает много времени, а в результате выдаёт бессмысленную и непонятную визуализацию. Чтобы структура данных предстала в более понятном и осмысленном виде, следует сосредоточится на совокупности свойств (например: подсчёт, сумма, среднее, медиана, стандартное отклонение и т. д.) одного или нескольких столбцов. Вычисляя статистические данные в ячейках, мы получим лучшее представление о том, как распределяются данные. Vaex хорошо себя показывает в таких вычислениях, а их результаты легко визуализируются.
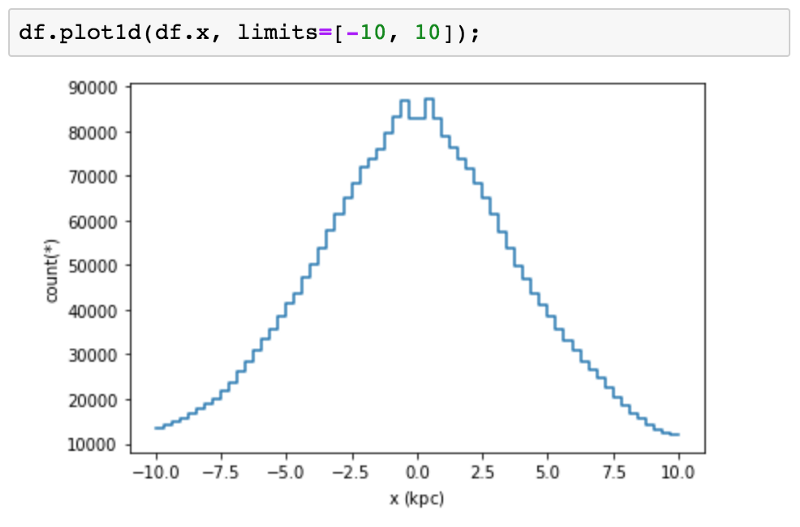
Давайте посмотрим, как эти идеи применяются на практике. Мы можем использовать гистограмму для визуализации данных одного столбца.
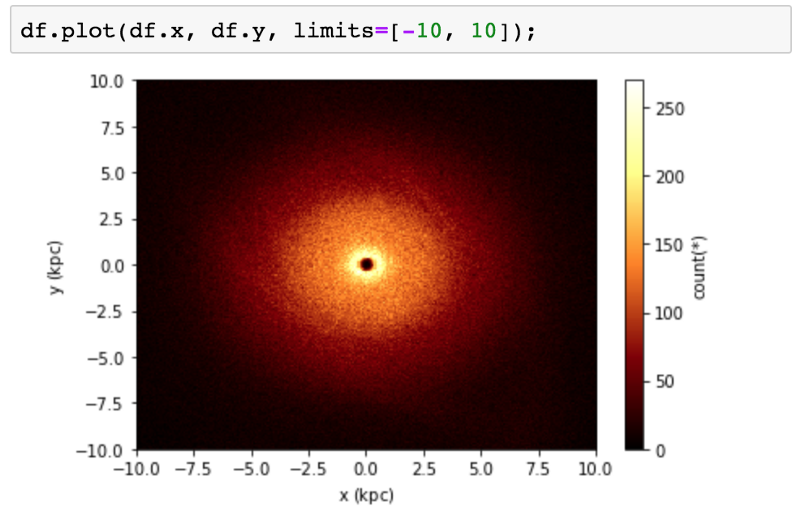
Мы можем представить это в двух измерениях, создав тепловую карту. Вместо того, чтобы просто подсчитывать количество семплов, попадающих в каждую ячейку, как это делается в типичной тепловой карте, мы можем вычислить среднее значение, логарифм суммы или любую нужную статистику.
С помощью библиотеки ipyvolume можно создать 3d визуализацию.
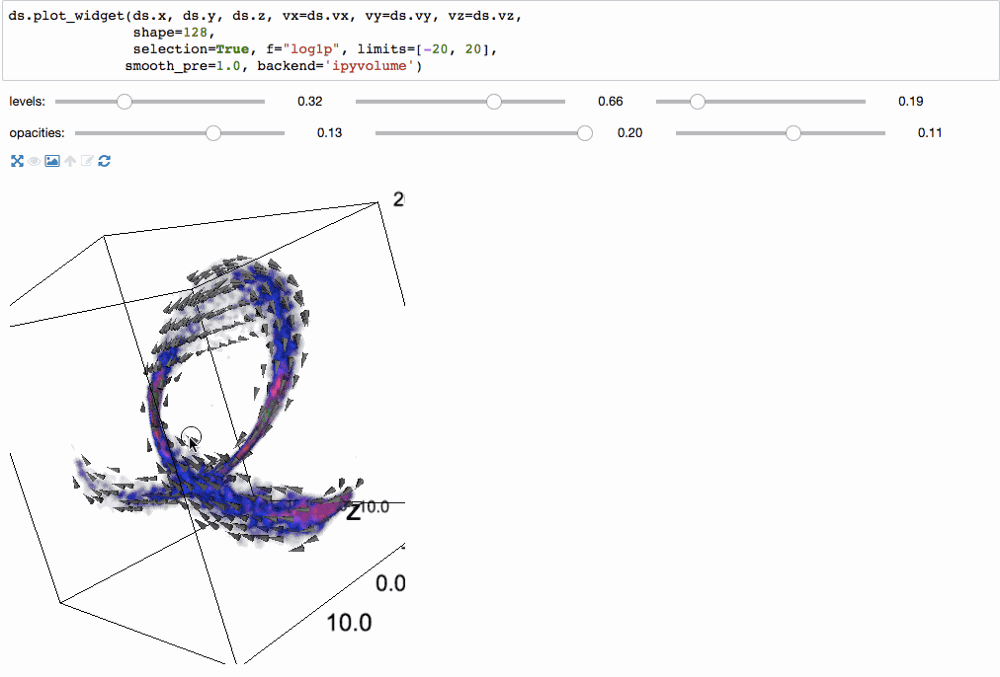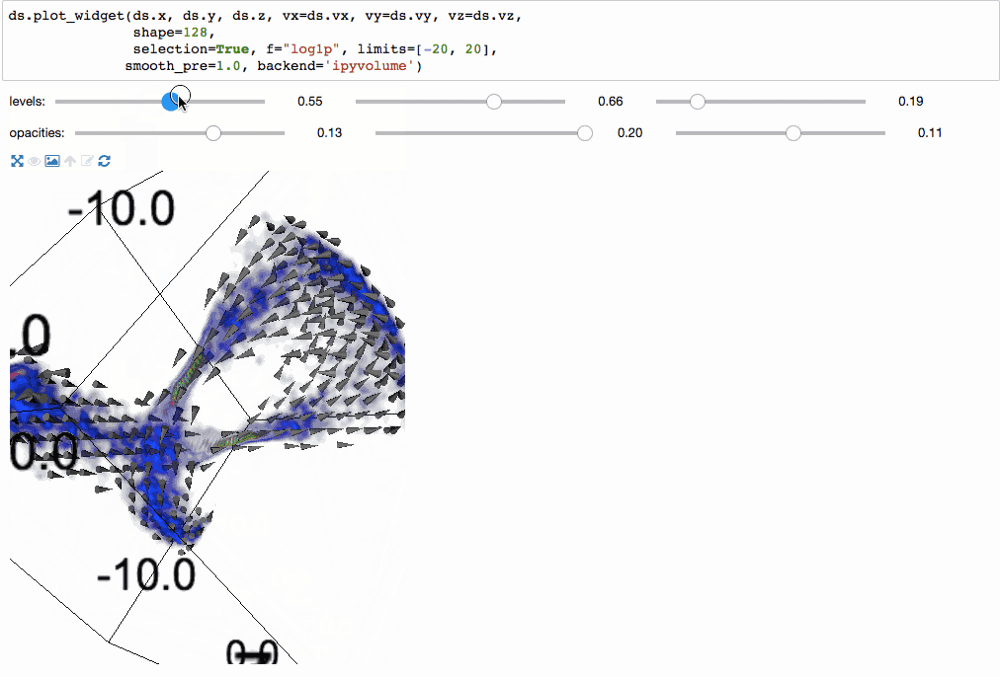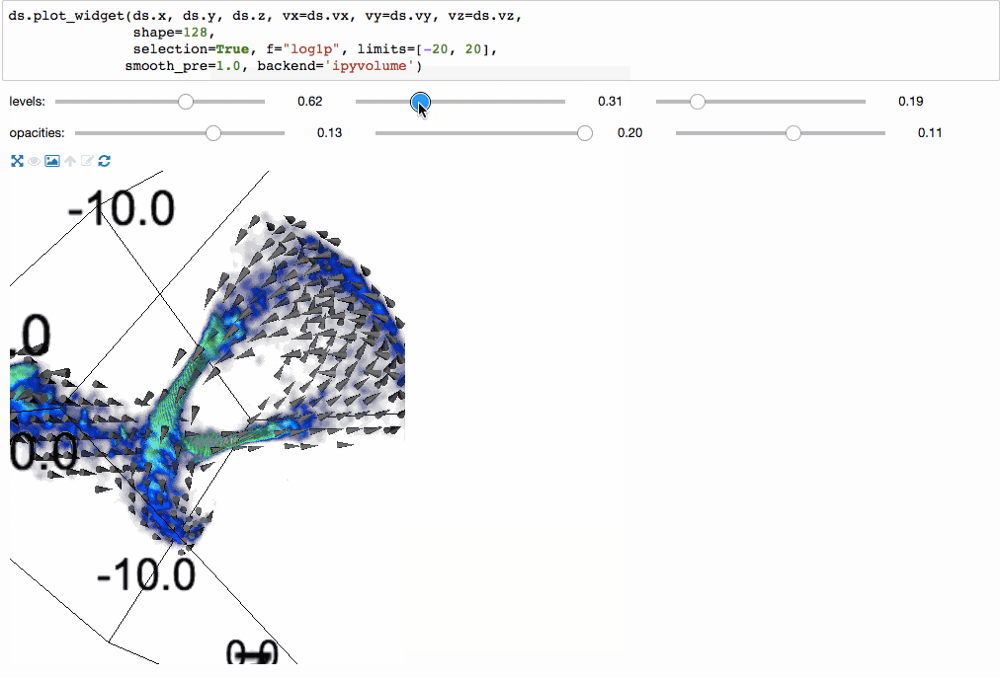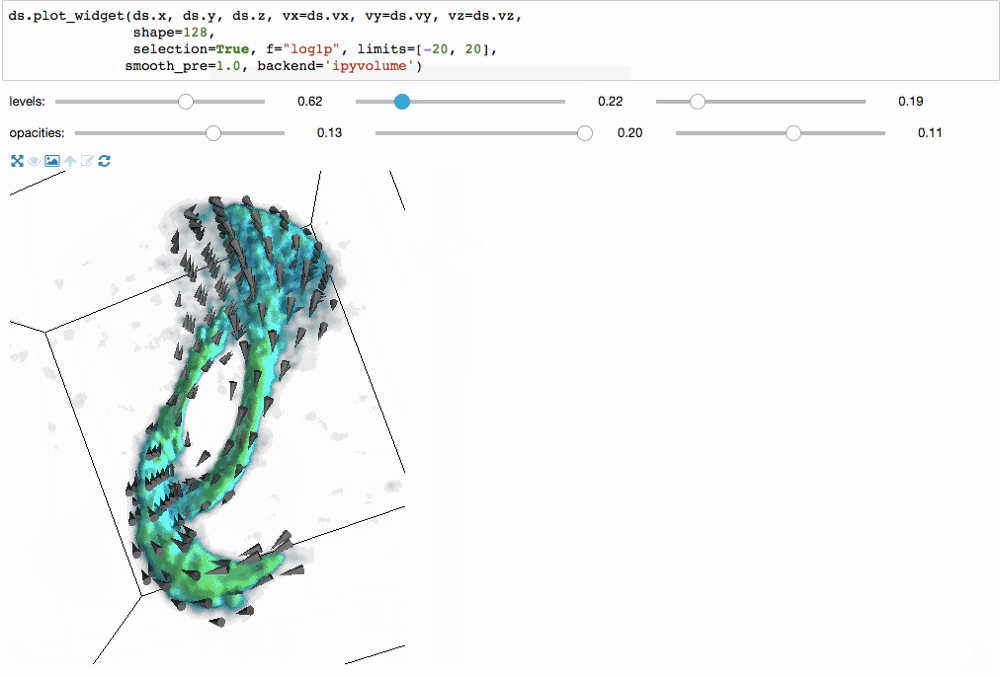
Так как вычисления на основе N-мерной сетки работают очень быстро, мы можем на лету делать интерактивные визуализации (с помощью bqplot).
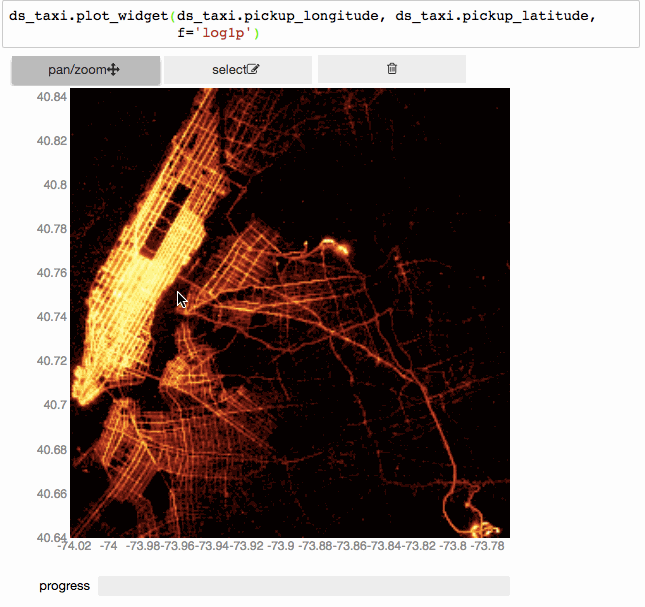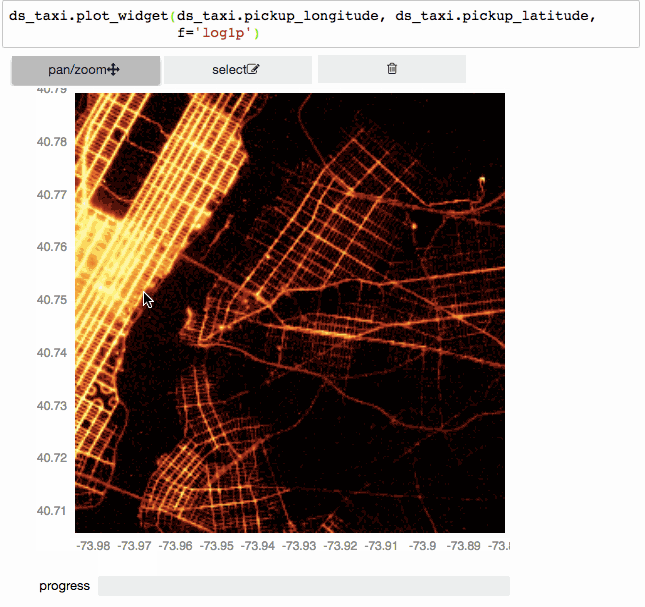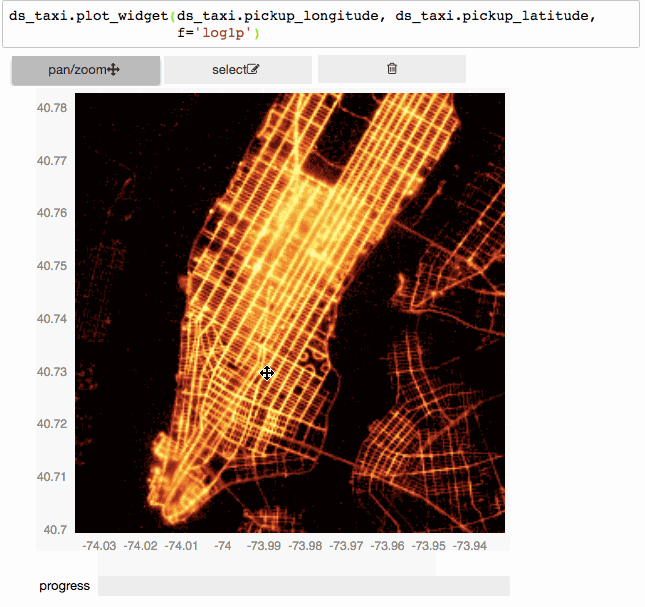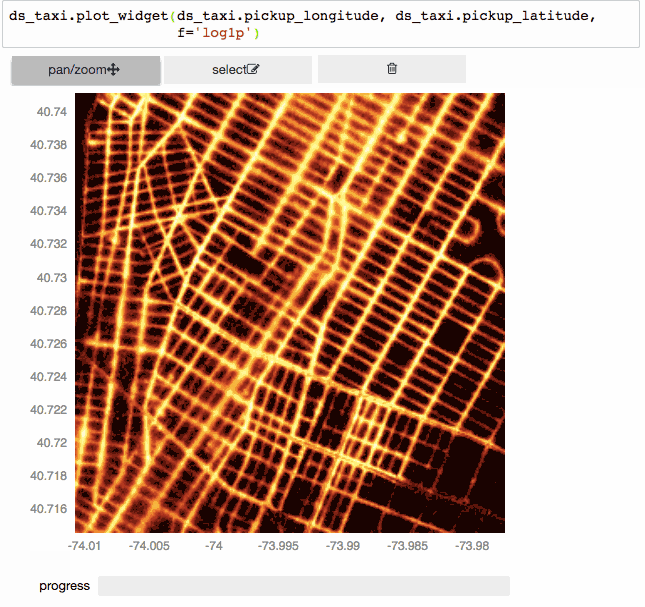
Ещё?
Да, Vaex включает целый набор инструментов — модулей. Эта библиотека является мета-пакетом, который устанавливает все Python пакеты из семейства Vaex. Вот список этих пакетов:
vaex-core: DataFrame и основные алгоритмы. В качестве входящих столбцов принимает numpy массивы.vaex-hdf5: предоставляет отображённые в память numpy массивы для DataFrame Vaex.vaex-arrow: то же самое, но с использованием Apache Arrow.vaex-viz: визуализация на основе matplotlib.vaex-jupyter: интерактивная визуализация на основе виджетов Jupyter ― ipywidgets, bqplot, ipyvolume и ipyleaflet.vaex-astro: для работы с астрологическими данными. Есть поддержка файлов FITS.vaex-server: предоставляет сервер для удалённого доступа к DataFramevaex-distributed: (для проверки концепций) для распределённых вычислений на нескольких серверах/кластерах.vaex-ui: интерактивное автономное приложение с GUI на основе Qt.
Хотите ещё?
Мы продолжаем работать над улучшением Vaex. Но это ещё не всё. Мы также много работаем над vaex-ml, это пакет, который даёт Vaex способность машинного обучения. Вскоре мы представим много интересного, следите за новостями. А пока, у вас есть возможность попробовать демо и увидеть возможности Vaex и vaex-ml в живую.
Вы можете протестировать примеры из этой статьи в Jupyter notebook с помощью mybinder:

Заключение
Вы готовы к Большим Табличным Данным? Мы готовы! Никакого копирования памяти, memory mapping, API-интерфейс (схожий с pandas) и супербыстрые вычисления статистики по N-мерным сеткам. Всё это делает библиотеку Vaex привлекательной для исследований и анализа Big Data. Всё это, возможно на вашем ноутбуке или ПК. Vaex является open source (MIT) проектом и доступен на GitHub. У нас есть своя страничка, на которой можно ознакомиться с документацией.
Перевод статьи Maarten Breddels: Vaex: Out of Core Dataframes for Python and Fast Visualization





