
Визуализация данных является неотъемлемой частью любых проектов в науке о данных или в проектах машинного обучения. Для того, чтобы получить некоторое представление об определенных данных, сперва проводится разведочный анализ данных (EDA). А визуализация помогает упростить и ускорить восприятие информации, особенно при наличии больших наборов данных высокой размерности. К концу проекта важно представить конечный результат в кратком и наглядном формате, чтобы аудитория, которая, скорее всего, не имеет технических знаний, все понимала.
Тепловая карта
Тепловая карта — это матричное представление данных, в котором каждое значение отображается при помощи определенного цвета. Каждой величине соответствует свой цвет, а матрица индексов сопоставляет 2 элемента или их характеристики. Тепловые карты показывают связи нескольких переменных между собой, отображая их величины в виде определенных цветов. Также, посмотрев на другие точки на тепловой карте, можно увидеть, как в наборе данных одна связь сравнивается со всеми другими. Именно цвета позволяют легко и быстро проанализировать данные, так как такое обозначение является интуитивно-понятным.
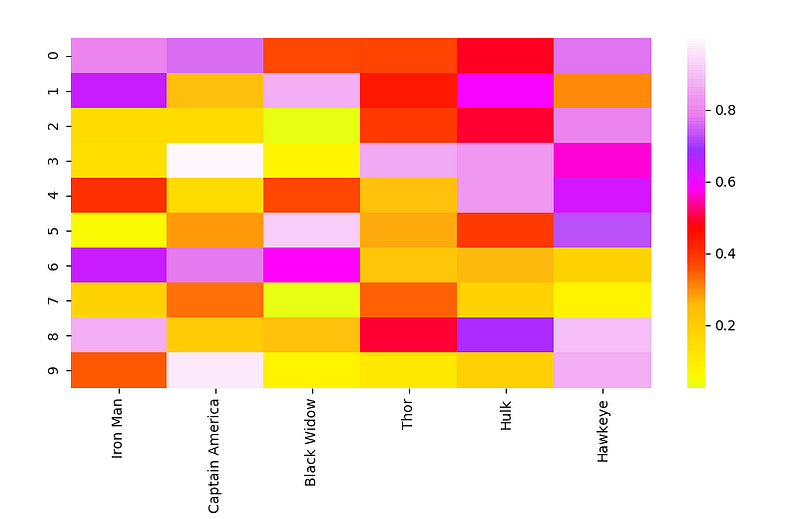
Теперь поговорим о коде. Библиотеку seaborn, в отличие от matplotlib, можно использовать для построения более сложных диаграмм, в которые входит большое количество компонентов, таких как цвета, графики и переменные. matplotlib используется для отображения графика, numpy— для генерации данных и pandas — для их обработки! Построение диаграмм является лишь одной простой функцией seaborn. Также в этой библиотеке можно найти функцию colour mapping (преобразование цвета).
# Importing libs import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt # Create a random dataset data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"]) print(data) # Plot the heatmap heatmap_plot = sns.heatmap(data, center=0, cmap='gist_ncar') plt.show()
Двумерная диаграмма плотности
Двумерная диаграмма плотности является расширением одномерной версии, которая позволяет видеть распределение вероятностей по двум переменным. Посмотрите на диаграмму ниже. На шкале справа с помощью цвета показана вероятность в каждой точке. Самая высокая вероятность, соответственно и точка максимального сосредоточения наших данных, имеет значение размера 0.5, а скорости — около 1.4. Как видите, для того, чтобы найти по двум переменным точку, в которой сосредоточено больше всего данных, лучше использовать двумерную диаграмму плотности, чем одномерную. Особенно она будет эффективна при наличии двух важных для результата переменных, а также, если необходимо посмотреть, как эти переменные вместевлияют на выходное распределение.
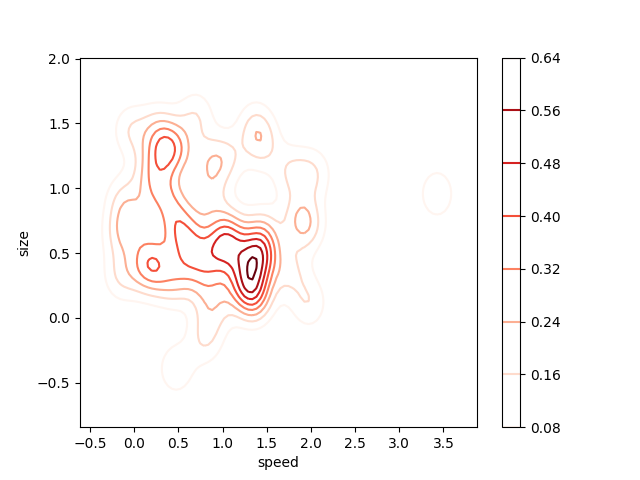
С использованием seaborn код получается очень простым. Чтобы разнообразить работу, создавайте асимметричные распределения. Большинство дополнительных аргументов служат для того, чтобы создать более понятную визуализацию с помощью различных цветов и/или теней.
# Importing libs import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import skewnorm # Create the data speed = skewnorm.rvs(4, size=50) size = skewnorm.rvs(4, size=50) # Create and shor the 2D Density plot ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True) ax.set(xlabel='speed', ylabel='size') plt.show()
Лепестковая диаграмма
Лепестковую диаграмму лучше всего использовать для отображения связи «один-ко-многим». Например, составив такую диаграмму можно увидеть значения нескольких переменных по отношению к другой одной переменной или целой категории. На лепестковой диаграмме сразу видно возвышение одной переменной над другой, так как площадь и длина увеличиваются в этом конкретном направлении. Укажите несколько категорий рядом друг с другом для того, чтобы посмотреть, как они связаны по отношению к тем переменным. На приведенных ниже диаграммах можно легко сравнить умения мстителей и увидеть, по каким критериям каждый из них лучше другого. (Обратите внимание, что эти характеристики были выставлены случайно. Я не отношусь предвзято ни к одному из мстителей 😉 )
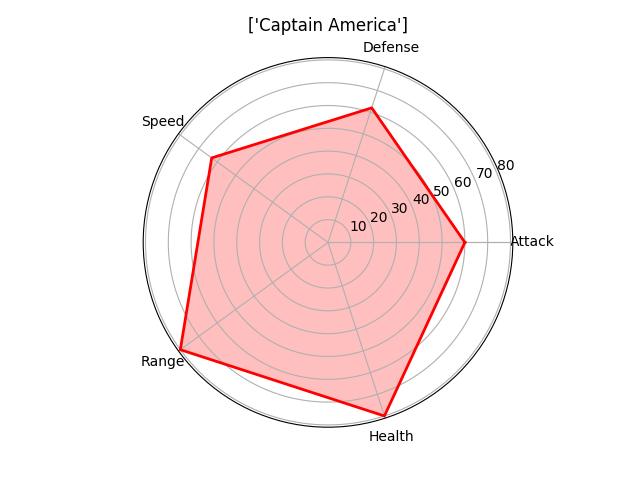
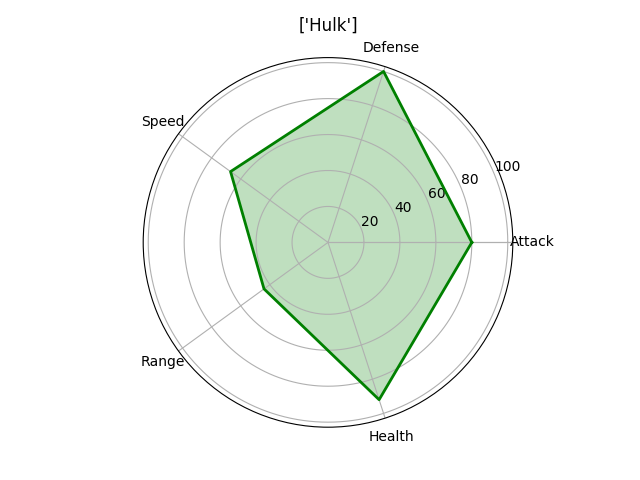
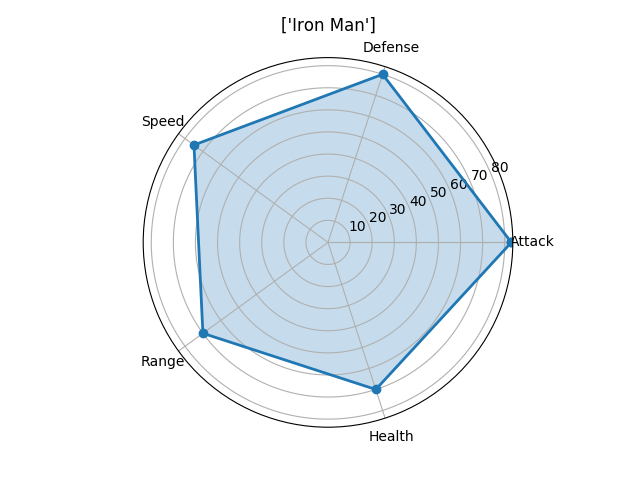
На этот раз для создания нашей визуализации лучше использовать matplotlib, а не seaborn. Нам нужно вычислить угол, под которым будет находиться каждое умение, так как мы хотим, чтобы они были равномерно распределены по всей окружности. Разместим названия умений под каждым вычисленным углом, а затем каждое значение отметим точкой. Расстояние точки от центра зависит от ее значения/величины. Наконец, соединив все точки, для наглядности зальем получившуюся фигуру прозрачным цветом.
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()
Древовидная диаграмма
Древовидные диаграммы мы используем с начальной школы! Они естественные и интуитивно-понятные. Соединенные напрямую узлы тесно связаны друг с другом. А узлы, которые расположены друг от друга на расстоянии многих других соединений, отличаются между собой. В приведенной ниже визуализации я указал небольшую часть набора данных о покемонах (Pokemon with stats от Kaggle) с учетом следующих критериев:
Здоровье, нападение, защита, особое нападение, особая защита, скорость
Таким образом, получается, что покемоны, данные которых не сильно отличаются друг от друга, будут иметь более прямую связь. Например, как мы видим, на самом верху покемоны Арбок и Фироу соединены напрямую, и если проверить данные, у Арбока общее значение всех умений составляет 438 баллов, а у Фироу — 442. Очень близко. Но если посмотреть на Ратикейта, то у него общее значение составляет 413. То есть оно уже довольно сильно отличается от Арбока и Фироу, и поэтому они разделены. Если посмотреть на более высокие значения, то можно увидеть, что покемоны начинают группироваться на основе сходств. Покемоны в зеленой группе имеют больше общего между собой, чем с покемонами из красной группы.
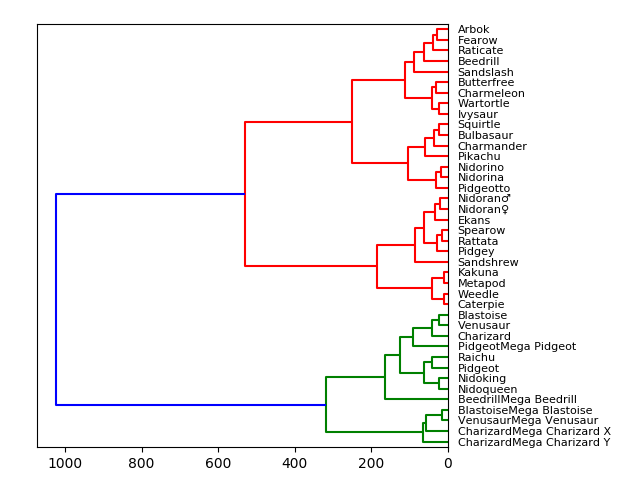
Для древовидной диаграммы используется Scipy. Ознакомившись с набором данных, мы избавляемся от обычной таблицы. Это необходимо для того, чтобы визуализировать данные. На практике лучше преобразовывать строки в категориальные переменные для более точного сравнения. Нужно также добавить индексный кадр для того, чтобы мы могли использовать его в качестве столбца и ссылаться на каждый узел. И наконец, Scipy исполнит простой код в одну строку для вычисления и создания древовидной диаграммы.
# Import libs
import pandas as pd
from matplotlib import pyplot as plt
from scipy.cluster import hierarchy
import numpy as np
# Read in the dataset
# Drop any fields that are strings
# Only get the first 40 because this dataset is big
df = pd.read_csv('Pokemon.csv')
df = df.set_index('Name')
del df.index.name
df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1)
df = df.head(n=40)
# Calculate the distance between each sample
Z = hierarchy.linkage(df, 'ward')
# Orientation our tree
hierarchy.dendrogram(Z, orientation="left", labels=df.index)
plt.show()
Перевод статьи George Seif: 4 More Quick and Easy Data Visualizations in Python with Code





