
Через несколько месяцев мне придется съехать из съемной квартиры и искать новую. Как бы это ни было тяжело, особенно учитывая замаячивший на горизонте ценовой пузырь на рынке недвижимости, я решил использовать переезд, как ещё одну возможность улучшить свои навыки владения Python! В результате своей работы я хочу сделать две вещи:
· Собрать все поисковые результаты с одного из ведущих сайтов недвижимости в Португалии (где я живу) и создать базу данных;
· При помощи этой базы данных и использования САПР попытаться найти недооцененное жильё.
Для веб-скрапинга я буду использовать портал о недвижимости Sapo, один из старейших и самых посещаемых сайтов в Португалии. Возможно, вы используете другой сайт, но вы сможете легко адаптировать код.
Перед тем, как представлять фрагменты кода, я хочу обрисовать вам, что я собираюсь делать. Я буду использовать страницы результатов поиска на сайте Sapo, где я смогу заранее установить некоторые параметры (например, локацию, ценовые фильтры, количество комнат и т.д.), чтобы сократить время выполнения задачи или просто запросить список всех результатов в Лиссабоне.
Затем нам нужно использовать команду запроса на сайт. В результате мы получим html код, который потом будем использовать, чтобы получить нужные нам элементы в финальной таблице. После того, как решим, что собирать из каждого поискового результата, нужно создать цикл for, чтобы открыть каждую поисковую страницу и собрать нужные данные.
Звучит довольно просто, с чего начинать?
Как и в большинстве проектов, нужно импортировать необходимые модули. Я буду использовать Beautiful Soup, чтобы работать с html, который мы будем получать. Всегда удостоверяйтесь, что с сайта, к которому вы хотите получить доступ, можно собирать данные. Это легко сделать, если к имени сайта вы прибавите “/robots.txt”. В этом файле вы увидите, есть ли какие-то рекомендации о том, что можно скрапить.
from bs4 import BeautifulSoup from requests import get import pandas as pd import itertools import matplotlib.pyplot as plt import seaborn as sns sns.set()
Некоторые сайты автоматически блокируют любой скрапинг, именно поэтому я задал шапку, чтобы наши запросы выглядели так, будто они исходят из реального браузера. При создании программы я также использовал команду паузы между страницами, чтобы имитировать более “человеческое” поведение и не перегружать сайт несколькими запросами в секунду. Если вы будете скрапить слишком агрессивно, вас заблокируют, поэтому нужно делать это вежливо.
headers = ({'User-Agent':
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36'})
Затем задаем основной адрес, который будем использовать для запросов. Для этого я ограничу поиск Лиссабоном и отсортирую по дате создания. Адресная строка быстро обновится и даст мне параметры sa=11 для Лиссабона и or=10для сортировки, которые я использую в качестве переменных sapo.
sapo = "https://casa.sapo.pt/Venda/Apartamentos/?sa=11&or=10" response = get(sapo, headers=headers)
Теперь мы проверим, можем ли мы связаться с сайтом. Для этой команды есть несколько кодов, но если вы получите “200”, это обычно означает, что всё в порядке. Список и значение результатов можно увидеть здесь.
Мы можем распечатать ответ и первые 1000 символов текста.
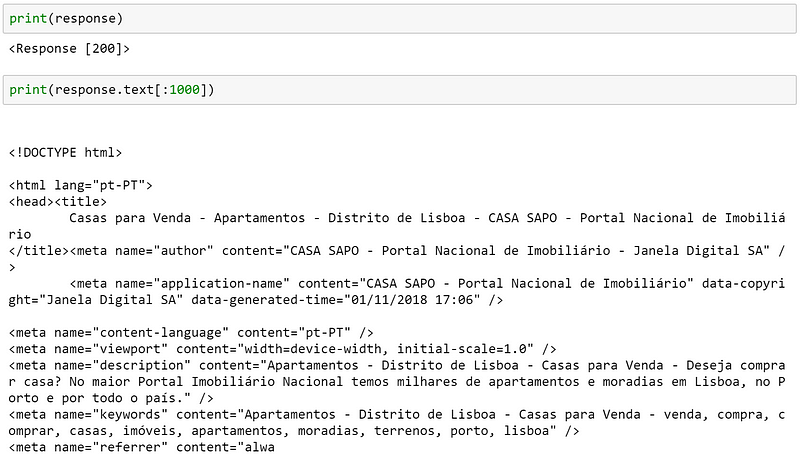
Хорошо, мы готовы начать исследование всего, что мы можем получить на сайте. Нужно задать объект Beautiful Soup, который поможет нам читать этот html. Как он работает: берет текст из ответа и интерпретирует информацию так, чтобы вам было легче разобраться в её структуре и получить её содержимое.
Пора приготовить немного Супа!
html_soup = BeautifulSoup(response.text, 'html.parser')
Большую часть работы по созданию инструмента для веб-скрапинга составляет перемещение по программному коду страницы, которую мы скрапим. Кусок текста выше — это всего лишь часть целой страницы. Вы можете убедиться в этом, если кликните на странице правой кнопкой мыши и выберете Посмотреть код элемента (я знаю, что эта опция есть в Chrome, думаю, и в других современных браузерах она тоже есть). Вы также можете найти позицию определенного объекта в html-коде.
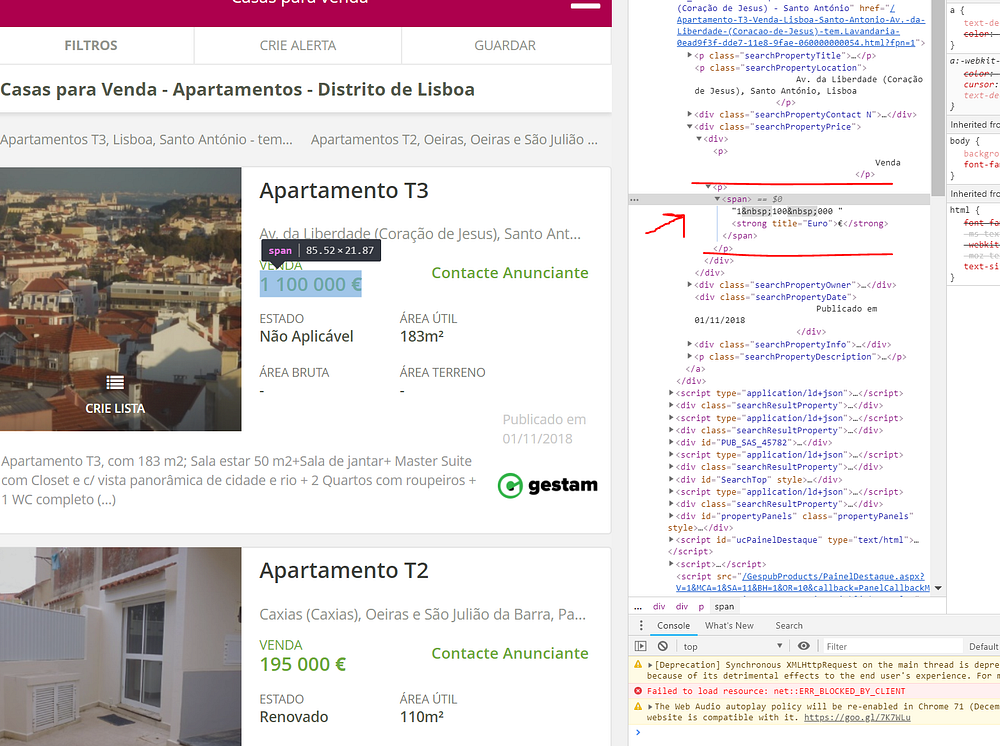
Если вы ничего не знаете о html-коде, не переживайте. Знать некоторые основы полезно, но не обязательно! Проще говоря, всё, что вам нужно понимать: на html построена каждая веб-страница, и этот язык основан на блоках. В каждом блоке есть свои теги, чтобы браузер понимал, как его читать. Только благодаря этому браузер показывает вам таблицу именно в виде таблицы, или абзац текста в особенном виде, или картинку. Если вы представляете html, как водопад тегов, которые вам нужно расшифровать, чтобы получить нужную информацию, всё отлично!
Перед тем, как выделять цену, нам нужно определить каждый результат на странице. Чтобы понять, какой тег нам нужно вызывать, мы можем искать их от тега цены наверх, пока не увидим что-то похожее на основной контейнер для каждого результата. Это можно увидеть ниже:
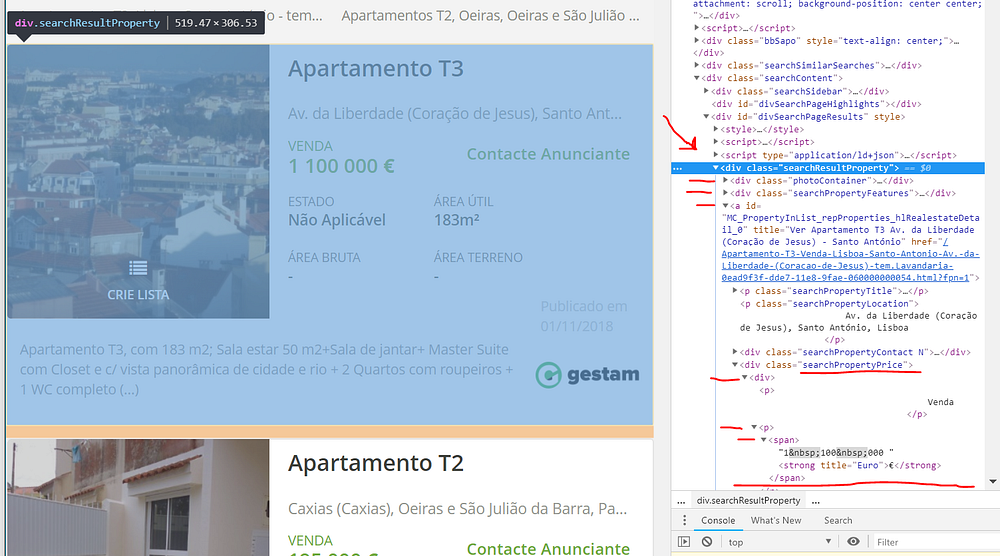
house_containers = html_soup.find_all('div', class_="searchResultProperty")
Теперь у нас есть объект, который повторяется на каждой поисковой странице во время скрапинга. Давайте попробуем получить цену, которую мы увидели чуть раньше. Я задам переменную first, которая будет структурой для нашего первого дома (взятого из переменной house_containers).
first = house_containers[0]
first.find_all('span')

Цену получить довольно просто, но в тексте есть некоторые специальные символы. Проще всего решить эту проблему, заменив эти символы пробелом. Я детально покажу это ниже, где я трансформирую символьную строку (String) в целое число (Integer).
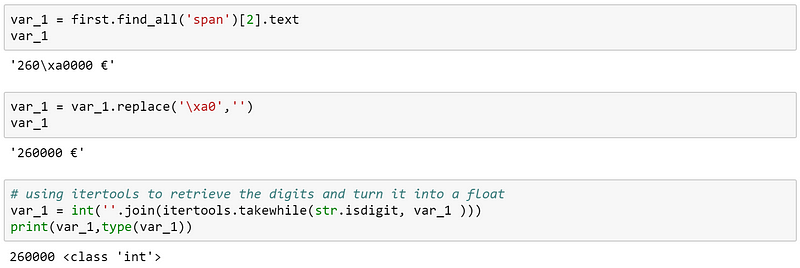
В последнем шаге itertools помог мне выделить только цифры из второго шага. Так мы собрали первые данные о цене! Другие параметры, которые мы хотим получить: название, размер, дата создания объявления, локация, состояние, краткое описание, ссылка на собственность и ссылка на прикрепленное изображение.
Ниже я покажу несколько примеров, перед тем, как мы зададим цикл for,который достанет нам каждый результат с каждой страницы.
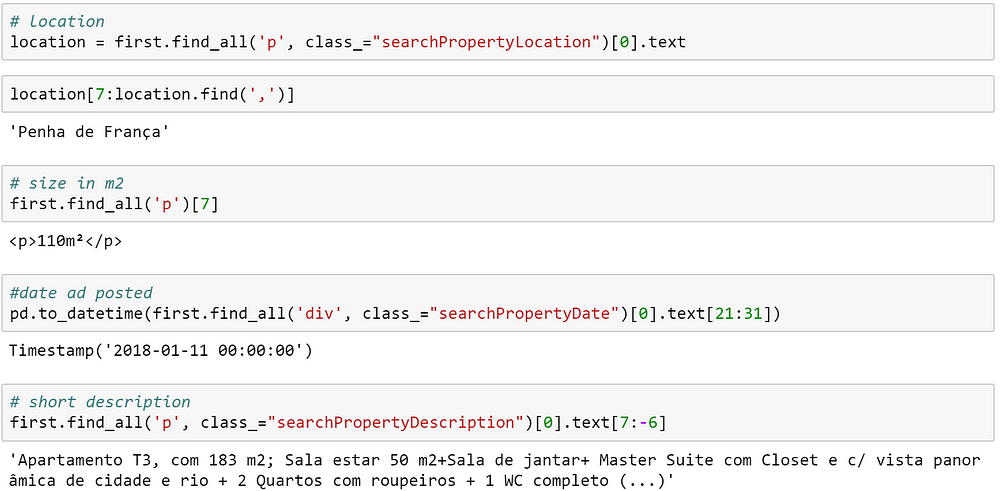
Этих примеров должно хватить вам, чтобы провести свое исследование. Я многому научился, просто балуясь с html-структурой и управляя значениями, которые возвращали мои запросы, пока я не получил то, что хотел.
Попробуйте скопировать код, представленный выше, в обратном порядке (удалите части [xx:xx] и [0]), изучите результаты и то, как я получил итоговый код. Я уверен, что есть десяток других путей, которые привели бы меня к тем же результатам, но я не хотел всё слишком усложнять.

Последние два параметра абсолютно по вашему желанию, но я хотел сохранить ссылки на собственность и на изображение, потому что думал о создании системы предупреждения или отслеживания для отдельных вариантов.
Хватит тегов, давай уже проскрапим несколько страниц!
Когда вы определились с параметрами, которые вы хотите собрать и способом сбора этих параметров из каждого контейнера, пора создать базу для нашего поискового робота. Следующие списки будут созданы, чтобы упорядочить наши данные
# setting up the lists that will form our dataframe with all the results titles = [] created = [] prices = [] areas = [] zone = [] condition = [] descriptions = [] urls = [] thumbnails = []
Быстро заглянув на оригинальную страницу, я увидел, что мы получили 871 страниц результатов. Мы можем предоставить роботу немного больше пространства, задав 900 повторений цикла. Также добавим что-то, чтобы приостановить цикл, если он обнаружит страницу без информации о доме. Команда страницы — &pn=x в конце адреса, где х — это номер страницы результата.
Код состоит из двух циклов for, которые проходят по каждому дому на каждой странице.
Если вы за всем уследили, вы смогли заметить, что эти циклы позволяют нам просто собирать данные, которые мы уже обнаружили выше. Поле priceоказалось более сложным, потому что в некоторых случаях в нем была указана цена продажи и цена аренды, разделенные “/”. В некоторых результатах индекс 2 вернул “Свяжитесь с продавцом”, поэтому мне пришлось добавить в код оператор if, чтобы искать цену в следующей позиции.
%%time
n_pages = 0
for page in range(0,900):
n_pages += 1
sapo_url = 'https://casa.sapo.pt/Venda/Apartamentos/?sa=11&lp=10000&or=10'+'&pn='+str(page)
r = get(sapo_url, headers=headers)
page_html = BeautifulSoup(r.text, 'html.parser')
house_containers = page_html.find_all('div', class_="searchResultProperty")
if house_containers != []:
for container in house_containers:
# Price
price = container.find_all('span')[2].text
if price == 'Contacte Anunciante':
price = container.find_all('span')[3].text
if price.find('/') != -1:
price = price[0:price.find('/')-1]
if price.find('/') != -1:
price = price[0:price.find('/')-1]
price_ = [int(price[s]) for s in range(0,len(price)) if price[s].isdigit()]
price = ''
for x in price_:
price = price+str(x)
prices.append(int(price))
# Zone
location = container.find_all('p', class_="searchPropertyLocation")[0].text
location = location[7:location.find(',')]
zone.append(location)
# Title
name = container.find_all('span')[0].text
titles.append(name)
# Status
status = container.find_all('p')[5].text
condition.append(status)
# Area
m2 = container.find_all('p')[9].text
if m2 != '-':
m2 = m2.replace('\xa0','')
m2 = float("".join(itertools.takewhile(str.isdigit, m2)))
areas.append(m2)
else:
m2 = container.find_all('p')[7].text
if m2 != '-':
m2 = m2.replace('\xa0','')
m2 = float("".join(itertools.takewhile(str.isdigit, m2)))
areas.append(m2)
else:
areas.append(m2)
# Creation date
date = pd.to_datetime(container.find_all('div', class_="searchPropertyDate")[0].text[21:31])
created.append(date)
# Description
desc = container.find_all('p', class_="searchPropertyDescription")[0].text[7:-6]
descriptions.append(desc)
# url
link = 'https://casa.sapo.pt/' + container.find_all('a')[0].get('href')[1:-6]
urls.append(link)
# image
img = str(container.find_all('img')[0])
img = img[img.find('data-original_2x=')+18:img.find('id=')-2]
thumbnails.append(img)
else:
break
sleep(randint(1,2))
print('You scraped {} pages containing {} properties.'.format(n_pages, len(titles)))
В конце я добавил команду паузы, чтобы робот ждал 1–2 секунды между страницами.

Помните, вам не нужно скрапить все 871 страницу. Вы можете менять переменную sapo_url в цикле, чтобы включать определенные фильтры. Просто включите фильтры, которые вам нужны, в браузере и поиске. Адресная строка обновится, и в ней появятся новые фильтры. В представленном выше цикле я ограничил результаты ценой от 10.000 евро (&lp=10000).
Последнее преобразование
Теперь нужно сохранить все переменные в одном объекте dataframe, чтобы мы могли сохранить их как csv или файл Excel и позже использовать этот файл, не повторяя весь показанный выше процесс.
Я задам названия каждой колонке и смешаю всё в один объект. Я добавил [cols] в конце, чтобы колонки шли в этом порядке.
cols = ['Title', 'Zone', 'Price', 'Size (m²)', 'Status', 'Description', 'Date', 'URL', 'Image']
lisboa = pd.DataFrame({'Title': titles,
'Price': prices,
'Size (m²)': areas,
'Zone': zone,
'Date': created,
'Status': condition,
'Description': descriptions,
'URL': urls,
'Image': thumbnails})[cols]
lisboa.to_excel('lisboa_raw.xls')
# lisboa = pd.read_excel('lisboa_raw.xls')
Позже мы сможем использовать последнюю строчку, чтобы читать данные. Так как я не хочу перегружать эту статью, оставлю поисковый анализ для следующей статьи. Мы собрали данные по более чем 20.000 домов, и теперь у нас есть оригинальный набор данных! Ещё нужно провести чистку и предварительную обработку данных, но мы уже справились с достаточно сложной частью.
Перевод статьи Fábio Neves: I was looking for a house, so I built a web scraper in Python!





