
Продолжая эту статью, добавим нереляционную MongoDB в кластер Kubernetes и в приложение Spring Boot.
Приступим
При разработке службы Kubernetes начинаем с локального Kind-кластера Kubernetes. В репозитории GitHub имеются файлы конфигурации для настройки, клонируем его:
git clone git@github.com:MartinHodges/aquarium-with-mongo-db.git
Почему MongoDB?
Доля рынка MongoDB вдвое больше, чем у ближайших конкурентов. Эта база данных совершенно нетривиальна, имеется две версии: версия сообщества и корпоративная. Когда говорят о нереляционных базах данных, MongoDB вспоминается одной из первых.
Техническое сравнение с другими отложим в сторону, MongoDB выбрана нами из-за ее популярности — и способности «выполнять работу».
Установка MongoDB
MongoDB устанавливается в кластер Kubernetes аналогично другим приложениям — посредством оператора.
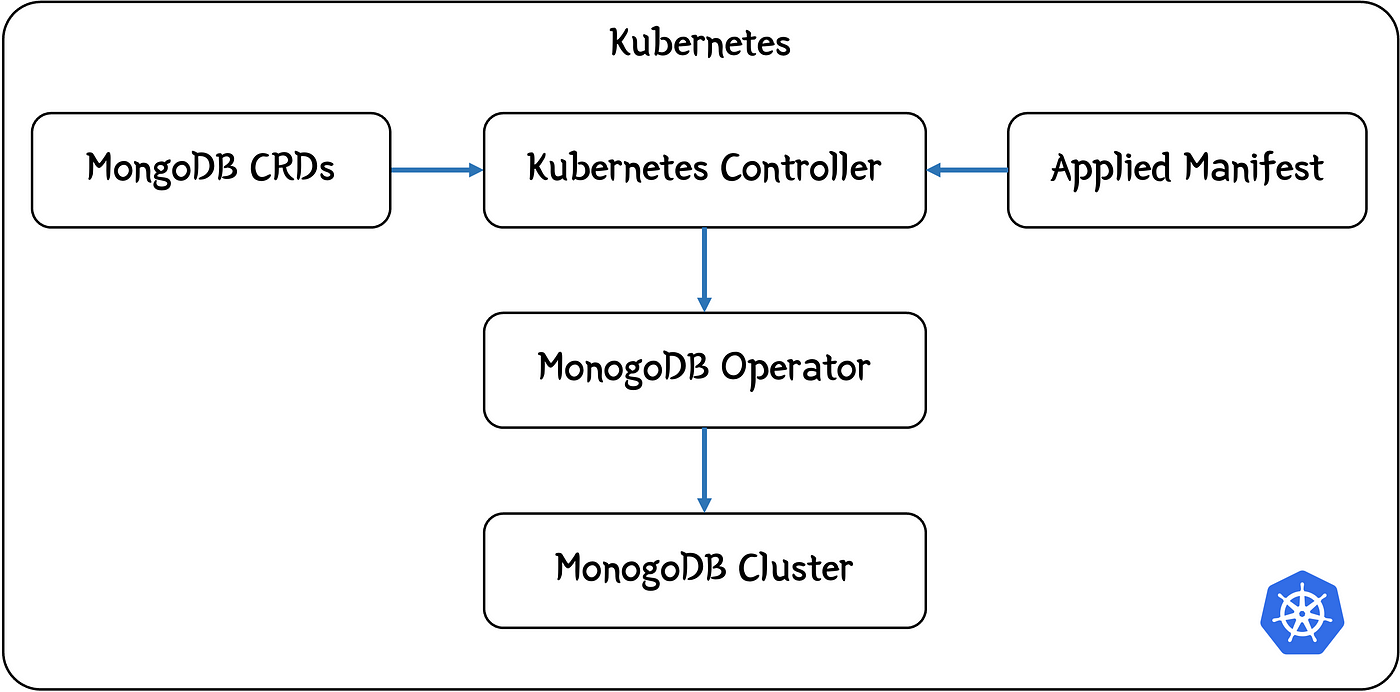
Оператором Kubernetes устанавливается, контролируется и отслеживается жизненный цикл приложения, при необходимости выполняются действия.
В случае с базой данных это создание ее кластера, масштабирование, резервное копирование и т. д. Обычно оператором устанавливаются определения специальных ресурсов с собственным «языком конфигурирования Kubernetes», им прослушиваются запросы на добавление этих специальных ресурсов в кластер, а затем от вашего имени осуществляются действия.
Создание кластера Kubernetes для разработки
Kind — легковесное приложение с поддержкой узлов, его проще настроить для локального кластера.
Вот инструкции по установке для разных ОС.
Воспользуемся командами среды macOS, понадобятся homebrew и Docker.
Устанавливаем Kind:
brew install kind
Проверяем версию:
kind version
Например, такая:
kind v0.22.0 go1.21.7 darwin/arm64
Установка завершена.
Создаем кластер Kind с такой конфигурацией:
kind/kind-config.yml
apiVersion: kind.x-k8s.io/v1alpha4
kind: Cluster
nodes:
- role: control-plane
extraPortMappings:
# API-интерфейсы
- containerPort: 30080
hostPort: 30080
- role: worker
- role: worker
- role: worker
Так получается четырехузловой кластер: один узел-контроллер, три рабочих, а порт 30080 становится доступным на машине разработки. Используя все это, создаем локальный кластер Kubernetes:
kind create cluster --config kind/kind-config.yml
Установка оператора
Устанавливаем поддерживаемый сообществом оператор, добавляя в локальный репозиторий ссылку Helm:
helm repo add mongodb https://mongodb.github.io/helm-charts
Смотрим, какие чарты добавились:
helm search repo mongo
В списке содержится оператор сообщества, помещаем его вместе с базой данных в отдельное пространство имен mongo:
kubectl create namespace mongo
Устанавливаем оператор:
helm install community-operator mongodb/community-operator -n mongo
Чтобы создаваемые ресурсы отслеживались оператором в другом пространстве имен, добавляем в эту команду
--set operator.watchNamespace="<other namespace>".
Проверяем состояние готовности 1/1 Running:
kubectl get pods -n mongo
Оператор запущен, определения специальных ресурсов установлены:
kubectl get crds
kubectl describe crd mongodbcommunity.mongodbcommunity.mongodb.com
Создание кластера
Установленным оператором прослушивается любой запрос на создание базы данных MongoDB. Сделаем запрос, применив манифест MonogDB к кластеру Kubernetes с помощью загруженных оператором определений специальных ресурсов.
Но прежде зададим пароль пользователя базы данных. Для этого создаем секрет Kubernetes, меняя <…> на задаваемый пароль:
kubectl create secret generic my-user-password -n mongo --from-literal="password=<your password>"
Проверяем так:
kubectl get secrets -n mongo my-user-password -o jsonpath={.data.password} | base64 -d; echo
Все секреты Kubernetes кодируются в base 64, поэтому декодируем пароль с помощью base64 -d. Командой create secret пароль автоматически кодирован в base 64 из-за использования --from-literal.
Для создания кластера MongoDB и базы данных с пользователем-администратором, у которого имеется этот пароль, делаем файл манифеста:
k8s/my-mongo-db.yml
apiVersion: mongodbcommunity.mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: my-mongo-db
namespace: mongo
spec:
members: 3
type: ReplicaSet
version: "7.0.11"
security:
authentication:
modes: ["SCRAM"]
users:
- name: my-user
db: admin
passwordSecretRef: # ссылка на секрет, из которого сгенерируется пароль пользователя
name: my-user-password
key: password
roles:
- name: clusterAdmin
db: admin
- name: userAdminAnyDatabase
db: admin
scramCredentialsSecretName: my-user-scram
additionalMongodConfig:
storage.wiredTiger.engineConfig.journalCompressor: zlib
Обратите внимание: в стандартном
storageClassсоздаются запросы на выделение постоянных томов. Следует убедиться, что постоянный том для этого запрашиваемого класса создается оператором постоянных томов корректно. Это касается Kind, другим понадобится что-то вродеnfs-client. Если эти постоянные тома недоступны, кластер не запустится.
Применяем это так:
kubectl apply -f k8s/my-mongo-db.yml
И проверяем ход выполнения:
kubectl get pods -n mongo
Ожидаем создания трех экземпляров. На моем MacBook Pro M2 Max Apple silicon с четырехузловым кластером Kind все три запустились примерно за пять минут.
После запуска проверяем работоспособность службы:
kubectl get svc -n mongo
И получаем:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-mongo-db-svc ClusterIP None <none> 27017/TCP 6m
Тестирование базы данных
С приложением мы подключимся к базе данных прямо из Kubernetes, используя для службы DNS-имя. Однако в целях тестирования нужно подключиться из машины локальной разработки.
При первом тестировании с пробросом порта для перенаправления одного из подов MongoDB на машину локальной разработки, когда я попытался внести изменения, получил такое сообщение об ошибке:
MongoServerError[NotWriteablePrimary]: not primary
То есть для проброса порта выбран не основной для кластера под. Второстепенные поды — это копии только для чтения, поэтому все записи выполняются через основной.
Проблема решается подключением к основному поду.
Находясь вне кластера и используя такой клиент MongoDB, как Compass, найти основной под по названиям подов Kubernetes, например
my-mongo-db-1.my-mongo-db-svc.mongo.svc.cluster.local, не получится: извне они недоступны.
Основной узел определяется по логам любого из узлов:
kubectl logs my-mongo-db-0 -n mongo -c mongod | grep "\"primary\":"
Если результатов нет, попался основной.
Если результат получен, даже если всего несколько строк, они очень длинные и трудные для восприятия. При наличии средства структурированного вывода JSON, такого как jq, воспользуйтесь этим:
kubectl logs my-mongo-db-0 -n mongo -c mongod | grep "\"primary\":" | jq
Появится такая строка:
...
"primary": "my-mongo-db-1.my-mongo-db-svc.mongo.svc.cluster.local:27017",
...
Из нее понятно, к какому поду подключаться, в моем случае это my-mongo-db-1. Теперь пробрасываем порт для этого пода:
kubectl port-forward my-mongo-db-1 -n mongo 27017:27017
Обратите внимание: при подключении через другие поды доступны команды только для чтения, а основной может измениться.
Как только этот проброс порта задействуется, подключаемся к базе данных, устанавливая клиент MongoDB Compass. При подключении к базе данных появится строка подключения mongodb://localhost:27017.
Меняем настройки. В Advanced Connection Options нажимаем Direct connection, иначе получим ненайденный адрес, потому что клиентом используется внутренний адрес Kubernetes.
Во вкладке Authentication выбираем Username/Password и вводим имя пользователя my-user и выбранный ранее пароль. Как базу данных добавляем Admin, затем выбираем механизм аутентификации SCRAM-SHA-256, при необходимости прокручивая вниз.
Нажимаем Save and Connect, называем подключение и оказываемся на консоли Compass, подключенной к базе данных.
В кластере появятся созданные базы данных admin, config и local.
Значит, кластер MongoDB запущен.
Создание пользователя приложения
Но, чтобы воспользоваться созданным my-user, приложению мало подключиться к MongoDB. Этим пользователем база данных сопровождается.
Чтобы разрешить приложению задействовать кластер базы данных, создадим базу данных и пользователя для доступа к ней.
Внизу окна Сompass нажимаем >_MONGOSH и попадаем в командную строку.
Создаем пользователя:
use aquarium
db.createUser( { user: "my-app-user",
pwd: "<password>",
roles: [ {db: "aquarium", role: "dbOwner"} ] } )
На что здесь обратить внимание?
Во-первых, переход к несуществующей базе данных aquarium, то есть до ее создания. Это согласуется с принципом отсутствия необходимости что-либо определять перед использованием. База данных и любые коллекции создаются при первом добавлении документа.
Во-вторых, присваиваемая новой базе данных роль. В MongoDB пользователям предоставляется небольшой набор встроенных ролей. В случае с dbOwner пользователю разрешены чтение, запись, администрирование базы данных. В продакшене пользователь соответствующим образом ограничивается.
Получается длинный ответ, в верхней части которого:
...
ok: 1,
...
Чтобы проверить этого пользователя, открываем новое подключение Compass через меню или комбинацией Cmd + N на Mac. Нажимаем только раз, наберитесь терпения — подключение появится спустя секунды.
При появлении окна нового подключения проще скопировать подключение, сохраненное ранее, с помощью меню … рядом с подключением.
Меняем имя пользователя и пароль, поменяем также Authentication Database на aquarium. Подключаемся.
Теперь перед нами новая база данных aquarium. Протестируем ее, нажав + рядом с названием базы данных и создав коллекцию fishes. Затем добавляем в базу данных данные в виде документа:
{
"_id": 123,
"fish": "Guppy"
}
Теперь MongoDB готова добавиться в приложение Spring Boot.
Создание приложения Spring Boot
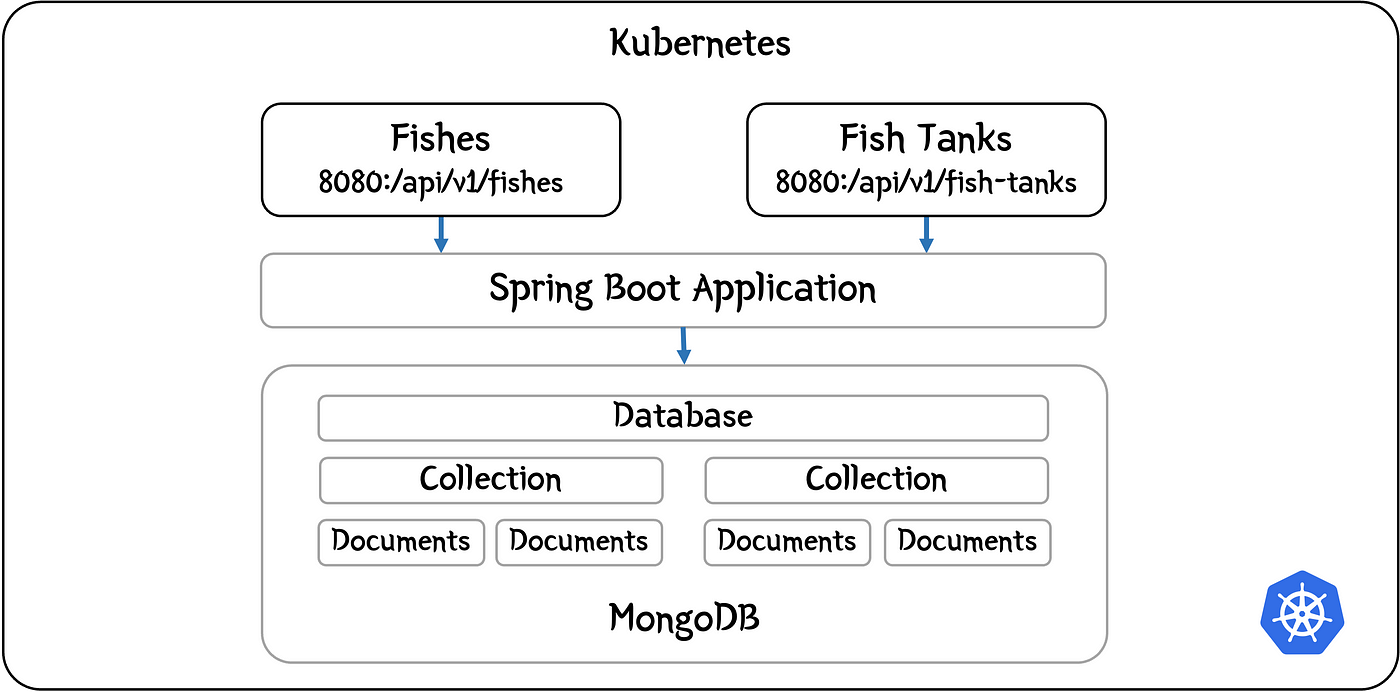
Простой пример с базой данных начинаем приложением aquarium. Рыбы и аквариумы создаются и управляются REST API-интерфейсами. Затем рыбы добавляются в один из аквариумов.
Функционал добавления рыбы в аквариум и их взаимосвязи мы не рассматриваем.
Код
Доступен в репозитории GitHub.
Зависимости
Запускать приложение Spring Boot всегда проще со Spring Initializr.
Добавляем Spring Web и Spring Data MongoDB в качестве зависимостей и создаем проект.
Чтобы не писать шаблонный код, включаем также Lombok.
Структура пакетов
В зависимости от приложения пакеты структурируются по типу компонентов, например controllers, services и repositories, или по предметной области.
Создаваемое приложение небольшое, поэтому основываем этот проект на двух предметных областях — рыбах и аквариумах:
fishes
FishController
FishService
FishRepository
fishtanks
FishTankController
FishTankService
FishTankRepository
Придерживаемся стандартного многоуровневого подхода с уровнями контроллеров, служб и репозиториев.
Конечные точки API
Контроллерами предоставляются конечные точки CRUD-операций для соответствующих API.
Сущности и документы
Знакомы с JPA и базами данных SQL вроде Postgres? Тогда будете как рыба в воде среди сущностей и репозиториев.
В нереляционной базе данных таблицы заменяются коллекциями, а строки таблицы — документами.
То есть репозитории для нереляционных баз данных немного отличаются от того, чем они являются для реляционных баз данных.
Нереляционная база данных работает с любой структурой, поэтому сущности или документы становятся простыми Java-объектами POJO. В примере нашего приложения объекты создаются так:
aquarium/fishes/Fish.java
...
@Setter
@Getter
@Document("fishes")
@NoArgsConstructor
public class Fish {
@Id
public UUID id;
public String type;
public Fish(String type) {
this.id = UUID.randomUUID();
this.type = type;
}
...
}
Обратите внимание:
- Вместо
@Entityтеперь определяется@Document, которым принимается название коллекции. - Вместо
@mongoIdприменяется@Id. Если не указать, в MongoDB добавится свой, а так мы сможем управлять собственными идентификаторами UUID. - Lombok, например
@Getter, используется для удаления части шаблонного кода.
Таким же образом создаем аквариумы:
aquarium/fishtanks/FishTank.java
@Setter
@Getter
@Document("fish tanks")
@NoArgsConstructor
public class FishTank {
@Id
public UUID id;
public String name;
public FishTank(String name) {
this.id = UUID.randomUUID();
this.name = name;
}
@Override
public String toString() {
return String.format(
"FishTank[id=%s, type='%s']",
id.toString(), name);
}
}
Репозитории
Итак, документы имеются, но как получить к ним доступ?
Покажем изменения в репозиториях, например, рыб:
...
public interface FishRepository extends MongoRepository<Fish, UUID> {
public List<Fish> findAll();
public Optional<Fish> findFirstById(UUID id);
public Optional<Fish> findFirstByType(String type);
}
...
Этот репозиторий почти тот же, что и в реляционной базе данных. Единственное отличие — интерфейсом расширяется не CrudRepository, а MongoRespository.
Оставим тему сопоставлений «один ко многим» и т. д. другим статьям, ограничимся созданием и управлением рыб и аквариумов.
Свойства приложения
При работе с любой базой данных приложению указывается, как к ней подключаться. Делается это при помощи свойств приложения так же, как и в реляционной базе данных.
Для файла свойств Spring Boot используем файлы YAML, заменяем поля < > собственными значениями и получаем такую конфигурацию:
resources/application.yml
spring:
application:
name: aquarium-with-mongo-db
data:
mongodb:
host: localhost
port: 27017
database: aquarium
username: my-app-user
password: <password>
Вернемся к ней, когда поговорим о профилях.
Контроллеры и службы
Теперь добавим контроллеры и службы так же, как это было бы с реляционной базой данных. Они доступны в репозитории GitHub.
Тестирование приложения
Завершайте код или клонируйте мой репозиторий, затем запускайте приложение в интегрированной среде разработки. Если продолжаете проброс порта в основной под, приложение должно запуститься.
Тестируем его этими командами curl:
curl localhost:8080/api/v1/fishes -H "Content-Type: application/json" -d '{"type": "guppy2"}'
curl localhost:8080/api/v1/fish-tanks -H "Content-Type: application/json" -d '{"name": "big one"}'
curl localhost:8080/api/v1/fishes
curl localhost:8080/api/v1/fish-tanks
Теперь в клиенте Compass перезагружаем базу данных aquarium, должны появиться две коллекции: fishes и fish tanks. Внутри этих коллекций — созданные рыбы и аквариумы.
Финальный этап
Мы подключили приложение Spring Boot к MongoDB, запускаемой в кластере Kubernetes. Теперь загрузим приложение Spring Boot в этот кластер.
Для этого:
- Создаем «жирный» jar-файл, в который включены все зависимости.
- Создаем из него образ Docker.
- Подгружаем образ в репозиторий Docker.
- Создаем файл манифеста Deployment.
- Применяем манифест Deployment к кластеру Kubernetes.
Поскольку используем Kind, 3-й пункт заменяется простой загрузкой без репозитория Docker.
Профили
Прежде чем создавать jar-файл, чтобы приложение запускалось в подключенном режиме — как это было до сих пор — и в кластере Kubernetes, сделаем два профиля Spring Boot:
connected… для запуска вне кластера;local-cluster… для запуска внутри кластера.
В первом режиме мы запускаемся сейчас. То есть просто копируем файл application.yml или application.properties в application-connected.yml, затем в командную строку JVM добавляем JVM-аргумент:
-Dspring.profiles.active=connected
То же самое проделываем для файла local-cluster, но с одним изменением:
...
data:
mongodb:
host: my-mongo-db-svc.mongo.svc.cluster.local
port: 27017
...
Используя DNS-имя, подключаемся к корректному поду. Благодаря тому, как в поде настроены правила поиска DNS, часть имени опускается, например my-mongo-db-svc.mongo.svc. Поэтому при развертывании в разных кластерах приложение остается рабочим.
Создание образа
Перейдем к созданию образа. Поскольку мы разместили на GitHub проект Gradle, создаем jar-файл из корневой папки проекта так:
gradle build
Чтобы манифестом указывалось на основной файл приложения, в gradle.build добавили следующее:
gradle.build
jar {
manifest {
attributes "Main-Class": "com.requillion_solutions.aquarium.AquariumWithMongoDbApplication"
}
}
Так создается jar-файл build/libs/aquarium-with-mongo-db-0.0.1-SNAPSHOT.jar.
Для образа Docker создаем Dockerfile:
FROM openjdk:17.0.2-slim-buster
RUN addgroup --system spring && useradd --system spring -g spring
USER spring:spring
ARG JAR_FILE=build/libs/*.jar
COPY ${JAR_FILE} app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
EXPOSE 8080
Во избежание проблем с Lombok начинаем с базового образа Java 17. Чтобы не запускаться как root, добавляем нового пользователя spring. Затем jar-файл копируется в образ, и для запуска приложения создается entrypoint.
Образ Docker создается так:
docker build -t aquarium .
И с Kind он загружается прямо в кластер Kubernetes:
kind load docker-image aquarium
Дальше запустим образ с помощью манифеста Deployment.
Манифест Deployment
Чтобы запустить загруженный в кластере образ, создадим файл манифеста Deployment:
k8s/deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: aquarium
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: aquarium
template:
metadata:
labels:
app: aquarium
spec:
containers:
- name: aquarium
image: aquarium
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
env:
# Следующая переменная окружения при считывании в Spring преобразуется в
# свойство «override», называемое «spring.profiles.active»
- name: SPRING_PROFILES_ACTIVE
value: local-cluster
---
apiVersion: v1
kind: Service
metadata:
name: aquarium
namespace: default
spec:
selector:
app: aquarium
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 30080
На что обратить внимание здесь?
- Приложение развертывается в пространстве имен
default, то есть пространство имен не задано. - Имеется только одна реплика.
- Образ добавляется, только если его нет. А он есть, загружен ранее.
- Профилю задано значение
local-cluster. - Чтобы сопоставлять порт «8080» приложения и пробрасывать через порт «30080» на машину разработки, создается служба.
Теперь развертываемся так:
kubectl apply -f k8s/deployment.yml
Проверяем успешность запуска:
kubectl get pods
После развертывания тестируем API теми же curl-командами, но с портом «30080»:
curl localhost:30080/api/v1/fishes -H "Content-Type: application/json" -d '{"type": "guppy2"}'
curl localhost:30080/api/v1/fish-tanks -H "Content-Type: application/json" -d '{"name": "big one"}'
curl localhost:30080/api/v1/fishes
curl localhost:30080/api/v1/fish-tanks
Новые документы просматриваем в пользовательском интерфейсе Compass, не забывая задействовать проброс порта.
Заключение
Мы изучили, как MongoDB устанавливается в Kind-кластер Kubernetes и интегрируется в приложение Spring Boot, продемонстрировали, что нереляционную базу данных использовать с Kubernetes и Spring Boot довольно просто.
Но на практике придется поработать над безопасностью, резервным копированием и отказоустойчивостью.
Читайте также:
- Реализация захвата изменения данных с Docker, PostgreSQL, MongoDB, Kafka и Debezium: подробное руководство
- Типы операций обновления в MongoDB с использованием Spring Boot
- Как создать сетевой API с помощью Express.js, Bun и MongoDB
Читайте нас в Telegram, VK и Дзен
Перевод статьи Martin Hodges: My experience adding a MongoDB No-SQL database to my Kubernetes cluster, Using Kind to develop and test your Kubernetes deployments





