
На каждой новой работе я сталкиваюсь с новым инструментом наблюдаемости, без которого не могу обойтись. Для нас в incident.io это суперспособность: мы часто обнаруживаем ошибки быстрее, чем наши клиенты успевают сообщить о них.
Пару лет назад это был Prometheus. На моей предыдущей работе мы сохраняли все логи в течение 30 дней и предоставляли доступ для поиска с помощью стека Elastic. Тогда это был ELK — Elasticsearch, Logstash и Kibana.
В incident.io я открыл для себя возможности трассировок и стал использовать их для отладки в наших системах — особенно локально. Хочу поделиться радостью от просмотра и запроса трассировок и сегментов, а также рассказать о том, как мы создаём их в нашей кодовой базе.
Что такое трассировка?
Трассировка представляет собой маршрут, по которому запрос проходит через ваше приложение. Не думайте, что это просто HTTP-запрос к API: это может быть любая единица работы, например запланированное задание или обработка события.
Трассировка состоит из сегментов, каждый из которых представляет собой единицу работы. Есть один «корневой» сегмент, а у каждого другого сегмента есть родительский сегмент. Хотя в разных реализациях может быть по-разному, сегменты обычно имеют идентификатор, название, некоторые атрибуты, а также время начала и окончания [единицы работы]. Самое важное — дочерние сегменты ссылаются на идентификатор родительского сегмента.
Мы используем OpenTelemetry, поэтому в этой статье основное внимание уделяется ей, но методы должны быть применимы к любому формату трассировки или библиотеке, которые вы используете.
Чем полезна трассировка?
В качестве примера возьмём HTTP-запрос /incidents/:id к нашему API. Запрос поступает, и мы что-то с ним делаем. Мы выполняем аутентификацию и авторизацию, а затем ищем этот идентификатор в нашей базе данных.
В результате каждая из этих единиц работы превращается в конкретный промежуток работы. Поскольку у промежутков есть родительские элементы и продолжительность, представить их можно в виде дерева, которое в итоге будет выглядеть примерно так:

Не волнуйтесь, это всего лишь пример — получение одного инцидента по идентификатору из Postgres происходит гораздо быстрее.
Посмотрим, что мне здесь нравится:
- Я вижу, что и в каком порядке произошло, сколько времени это заняло.
- Я сразу вижу, какие части оказались медленными.
- Можно легко обнаружить неэффективность вроде таких вещей, как N+1 запросов или дублирующиеся вызовы для одних и тех же данных в разных частях кода.
Погружаясь в промежутки
Имена — одна из самых важных частей, ведь большинство инструментов в обзоре всей трассировки отображают их. Старайтесь придерживаться соглашения, чтобы имена были привычными: например, в запросах к базе данных всегда указывается имя таблицы, а промежутки для других вызовов имеют формат package.FunctionName.
Метаданные промежутков также невероятно полезны. Рассмотрим несколько примеров:
- Наш HTTP-промежуток всегда получает путь запроса и код ответа: я могу увидеть, был ли запрос успешным. Мы также указываем
Referrer, чтобы я мог понять, из какой части приложения поступил запрос. - Все наши запросы к базе данных содержат атрибуты для таблицы, к которой был выполнен запрос, и количество затронутых строк. Это позволяет легко увидеть запросы
SELECT, вернувшие большой объём данных, или запросыUPDATE, которые ни на что не повлияли. Также включается уникальный идентификатор (отпечаток) запроса. При локальной разработке включается и SQL-запрос. - У всех наших HTTP-клиентов есть трассировки каждого исходящего запроса. У каждой трассировки есть атрибут с путём запроса и полученным ответом. Для трассировки можно установить статус «сбой» — и эти трассировки будут по-другому отображаться в UI, если мы получим ответ с ошибкой.
Как это выглядит в коде?
Как видите, наша кодовая база предоставляет множество промежутков «из коробки» просто так — и это действительно здорово. Но что, если мы захотим добавить несколько промежутков в пределах кода приложения?
Например, мы знаем, что у нас есть всего три секунды, чтобы ответить на сообщение в Slack, поэтому важно, чтобы этот код работал быстро. Также важно, чтобы можно было отлаживать всё, что работает медленно.
Представим функцию, которая обрабатывает взаимодействия со Slack:
func (svc *Service) HandleInteraction(ctx context.Context, cb slack.InteractionCallback) error {
ctx, span := md.StartSpan(ctx, md.SpanName(), md.Metadata{
"callback_type": cb.Type,
})
defer span.End()
if _, err := svc.handleInteraction(ctx, cb); err != nil {
md.SpanRecordError(span, err)
return err
}
return nil
}Здесь вы можете увидеть нашу внутреннюю библиотеку md (метаданных), которую мы используем как для трассировки, так и для логирования. Она выполняет несколько задач:
- Запуск span, использование
StartSpanи передача атрибута с типом обратного вызова. - Использование
md.SpanName(), имя которого определяет промежуток в зависимости от вызывающего пакета и функции. - Вызов
defer span.End(), чтобы убедиться, что диапазон завершен независимо ни от чего. - Запись ошибки с помощью
SpanRecordError, если ошибка возникает.
Шаг вперед
Если вы хотите перейти на один уровень глубже, можно использовать defer с именованными возвращаемыми параметрами (у которых тоже есть подводные камни), чтобы сделать что-то вроде такого:
func HandleAlert(ctx context.Context, alert *domain.Alert) (err error) {
ctx, span := md.StartSpan(ctx, md.SpanName(), md.Metadata{
"alert": alert.ID,
})
defer func() {
if err != nil {
md.SpanRecordError(span, err)
}
span.End()
}()
// ...остальная часть функции
}Преимущество в том, что вам не нужно беспокоиться о вызове SpanRecordError в остальной части функции, когда бы ни возникла ошибка. Вы можете использовать тот же шаблон для установки других атрибутов, и мы также используем этот шаблон для записи значений в гистограммах Prometheus.
Как помогает инструментарий?
Теперь, когда мы поняли, как помогают трассировки, поговорим о том, где они сохраняются. У каждого из нас есть проект Google Cloud Platform для локальной разработки, и трассировки сохраняются в Cloud Trace. Это действительно полезно для локальной разработки, особенно когда в локальном логе рядом с записями лога отображаются URL-адреса трассировок:
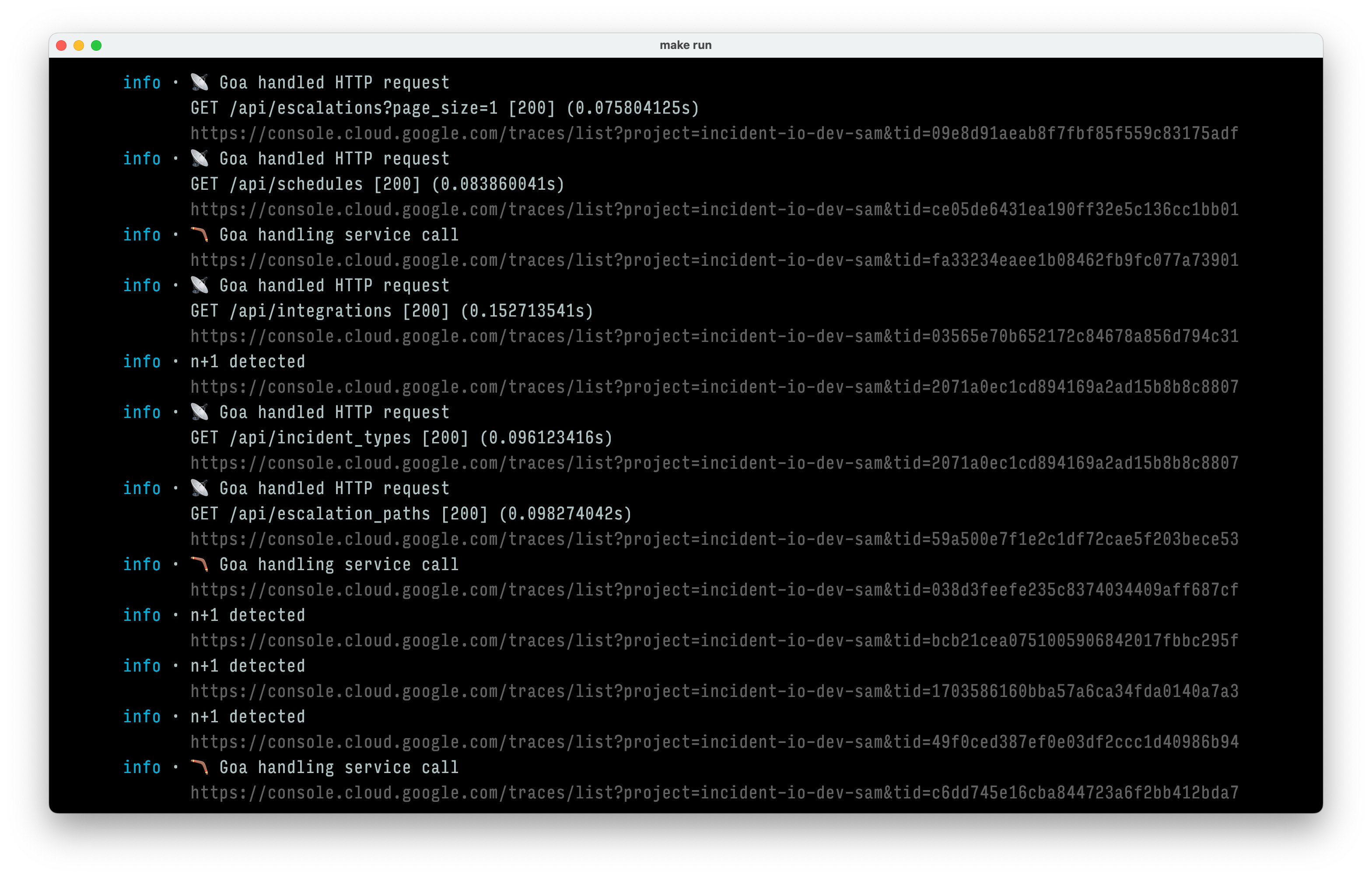
На продакшне наши трассировки также попадают в Grafana с помощью Tempo. И Grafana, и Google Trace позволяют запрашивать промежутки и трассировки, но мы обнаружили, что TraceQL в Grafana гораздо более гибкий и выразительный.
Мы помечаем многие наши сегменты идентификатором пользователя или организации, отправляющей запрос, что позволяет мне:
- Найти все записи, где мы запрашивали таблицу инцидентов для конкретной организации.
- Показать трассировку, где мы обрабатывали оповещение для данного идентификатора оповещения.
- Вывести все трассировки для конечной точки API «список инцидентов», где более двух секунд, чтобы получить ответ.
Наличие трассировок в веб-интерфейсе означает, что я также могу делиться ими с другими инженерами в каналах для сообщений об инцидентах в рамках нашего процесса реагирования: почти каждое сообщение об инциденте в той или иной форме содержит фразу «Привет, эта трассировка выглядит подозрительно».
Как только инженер из incident.io находит трассировку чего-либо, он, как правило, всегда знает, что именно произошло. Это значительно упрощает быстрое исправление багов.
В чем заключается суперспособность?
Надеюсь, вы понимаете, что трассировка может показать нам, как именно работает наша система, с высокой степенью детализации. Мы объединили её с логированием и отчётами об ошибках — так что у каждого лога есть атрибут trace_url, и у всего, что попадает в Sentry (который мы используем для обработки ошибок), тоже есть такой атрибут.
Это означает, что часто происходит следующее: вы получаете уведомление, открываете Sentry в канале инцидентов, переходите по ссылке на трассировку и видите, что именно произошло.
Лучшие советы
Если вы подумываете о внедрении (или улучшении) трассировки, у меня есть несколько советов:
- Сделайте всё возможное, чтобы включить трассировку «бесплатно». Cоздание интервалов запуска клиента базы данных и HTTP-клиентов даёт нам много полезной информации.
- Сохраните эти трассировки в таком месте, где их можно будет запросить, и убедитесь, что все знают, как выполнять простые запросы.
- Сделайте трассировки по-настоящему доступными: добавьте их в метаданные лога, в ошибки, в HTTP-заголовки (каждый из наших запросов возвращает идентификатор трассировки). Используйте их везде, где они могут быть полезны.
- Постарайтесь, чтобы ваши локальные настройки предельно соответствовали настройкам на продакшне. Наличие трассировки на локальном уровне действительно помогает всем натренировать навыки трассировки: когда вы используете её ежедневно, вы по умолчанию будете думать: «Эй, здесь было бы полезно добавить промежуток».
Конечно, есть и вредные советы: убедитесь, что вы понимаете, во сколько обойдётся хранение большого количества трассировок, а также как количество сегментов (и атрибутов) влияет на стоимость. Имена и значения атрибутов часто также имеют ограничения.
Читайте также:
- StreamForge: настраиваемый дашборд мониторинга метрик Kafka
- Лучшие практики и инструменты для микрофронтендов
- Создание платформы обработки и анализа данных Bazaar
Читайте нас в Telegram, VK и Дзен
Перевод статьи Sam Starling: Observability as a superpower





