
Недавно я присоединился к Bazaar Technologies — пакистанскому стартапу с большими планами и суперталантливой командой, способной реализовать эти планы.
Многие люди ежедневно полагаются на данные Bazaar при выполнении своей работы. Всего за 15 месяцев платформа добавила 6+ приложений для поддержки бизнеса с десятками микросервисов в бэкенде. Они обслуживают 200+ брендов и 750 000+ коммерсантов в Пакистане. Каждый день генерируются тонны данных. Несмотря на уже имеющиеся решения по анализу данных, Bazaar продолжает развиваться.
На данном этапе мы приступили к переосмыслению нашей платформы данных. Стремясь добиться большей экономии, мы создали команду профессионалов, в которую вошли:
- инженеры по данным;
- инженеры МО и специалисты по обработке данных;
- аналитики данных.
После глубоких мозговых штурмов, недолгого периода колебаний и сомнений мы, наконец, разработали проект обновленной платформы данных. В Bazaar он получил название “Buraq”, что означает “скоростной и многоаспектный путь”.
В исламской традиции Burāq— это существо, служившее средством передвижения некоторым пророкам.
Buraq основан на дельта-архитектуре и сочетании нашего уникального подхода Data-Lakehouse и философии Data-Mesh.
Buraq предоставляется на двух различных типах кластеров:
- Kubernetes, который в основном используется для размещения вспомогательных инструментов и приложений (Airflow, Hue, Superset, Prometheus и т. д.);
- Map Reduce, выделенный для решения сложных задач обработки данных и машинного обучения.
Платформу Buraq можно разбить на следующие слои:
- внедрения/интеграции;
- обработки;
- API сервисов;
- запросов.
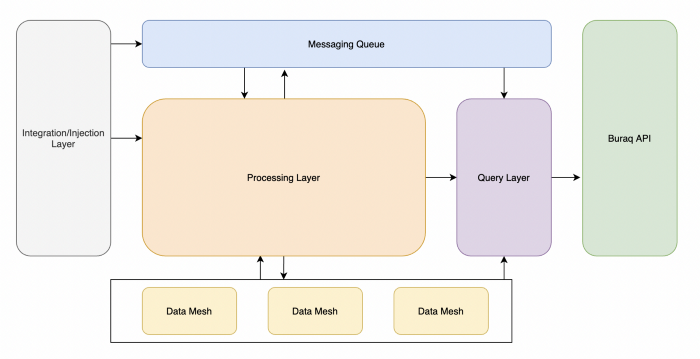
Слой внедрения/интеграции
В Bazaar введена практика data mesh (конечно-элементной сетки данных) для децентрализованного владения данными. Команды могут приходить на Bazaar со своими собственными корзинами (объектными хранилищами) с данными в форматах parquet, avro, csv и json и интегрироваться с Buraq по принципу Plug’n’Play. Такой подход позволяет центральной команде по работе с данными сосредоточиться на дальнейшем развитии и совершенствовании Buraq.
Интегрированные корзины с данными проходят многоуровневый процесс очистки и управления, созданный с помощью Apache Hudi. Вот 4 уровня этого процесса:
- Сырьевой — уровень немодифицированных данных, которые отражают фактическое состояние источника данных.
- Бронзовый — уровень управления и качества, который обеспечивает необходимое соответствие и предоставляет возможность очистки, преобразования и фильтрации данных.
- Серебряный — уровень, на котором используются методы моделирования на основе Data Vault для создания де-нормализованных данных.
- Золотой — уровень, отражающий конечное состояние жизненного цикла данных, на котором создаются данные, потребляемые конечными пользователями.
Слой обработки
Этот уровень является суперабстрактным. В большинстве случаев люди, выполняющие конвейерную обработку, не знают, будут ли данные с бэкэнда обрабатываться в режиме реального времени или пакетно. Это достигается за счет использования постоянно работающего стримера HUDI, который считывает данные как из корзин, так и из тематических разделов Kafka и поддерживает таблицы MOR (merge-on-read). Наша основная среда обработки — Apache Spark — работает действительно эффективно.
Слой API сервиса
С самого начала мы планировали, что Buraq будет платформой DaaS (данные как сервис), чтобы мы могли использовать аналитику и машинное обучение в наших основных приложениях. Buraq API Layer — это набор API, которые предназначены для таких случаев использования.
Слой запросов
Поскольку все наши данные хранятся в корзинах, нам нужен был какой-то механизм запросов для их получения. Trino оказался простым решением, поскольку у нас уже были практические навыки по использованию этого проекта. Некоторые из нас уже внесли свой вклад в него, что было официально отмечено на сайте Trino.

Направления дальнейшего развития платформы
1. Автоматизированное качество данных
Аналитики и специалисты по обработке данных компании Bazaar должны полагаться на данные, поступающие и обрабатываемые на Buraq. Решение проблемы качества данных является насущной необходимостью. У нас есть несколько готовых решений.
2. Клиентоориентированная аналитика
Будучи организацией, предоставляющей данные как услугу, мы планируем обеспечить нашим клиентам возможность использовать некоторые виды аналитики.
3. Магазин функций
Наука о данных может принести конкурентное преимущество любому стартапу. Поэтому мы работаем над тем, чтобы сократить время и усилия для внедрения моделей в производство. Создание магазина функций является одним из шагов в этом направлении.
4. Минимизация вычислительных затрат
Мы постоянно ищем способы снизить стоимость владения Buraq. В данный момент пытаемся использовать эффективные экземпляры ARM наряду с некоторыми оптимизациями кластера Kubernetes.
Читайте также:
- BERT - коротко о главном
- Тематическое моделирование с помощью BERT
- Время управлять версиями проектов МО по-новому
Читайте нас в Telegram, VK и Дзен
Перевод статьи Umair Abro: Building Bazaar’s Data Platform





