
Введение
В поисковой инфраструктуре Flipkart — базовом сервисе этой компании — индекс SOLR управляется с помощью Mustang. Сейчас мы работаем над различными сегментами для подразделений Flipkart: Grocery, Hyperlocal, Shopsy. В каждом сегменте размещаются реплики, количество которых определяется объемом данных и запросов, направляемых сегменту.
В каждой реплике содержится два основных компонента данных: 1) сохраняемые на диске данные продукта, обслуживаемые в SOLR, и 2) сохраняемые в памяти данные листингов продавцов для быстро меняющихся атрибутов, называемых данными в почти реальном времени. Когда запускается приложение, структуры данных в памяти создаются извлечением данных из централизованного кластера Redis. Чтобы оставаться синхронизированными с Redis, эти структуры данных в памяти также обновляются конвейером Kafka.
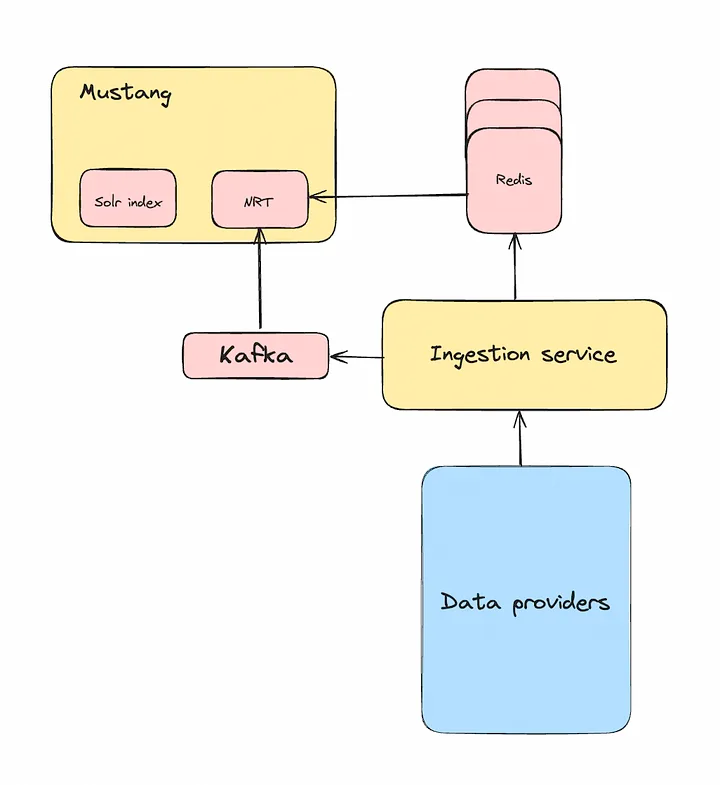
В каждой реплике содержатся данные примерно на 15 млн листингов. Эти структуры данных в памяти во время запуска создаются 30–40 минут. Главное узкое место в этом процессе — Redis, который с трудом справляется с наплывом одновременных запросов при развертывании, ведь размер этого кластера близок к 400 виртуальным машинам в каждом контроллере домена.
В итоге развертывание сильно замедляется и продлевается минимум на два дня. Это не только сказывается на продуктивности разработчика, но и чревато проблемами своевременного устранения багов.
Расскажем, как мы оптимизировали время начальной загрузки Mustang с помощью RocksDB.
Анализ проблемы
Кластер Redis зависал при каждом перезапуске серверов Mustang. Даже при коэффициенте развертывания 10 % к Redis подключалось около 40 серверов Mustang с более чем 300 000 одновременных вызовов. Причинами такого огромного количества одновременных запросов стали количество потоков-опрашивателей и размер пакета на каждом сервере.
Кроме того, получение из Redis данных для листинга не было простой GET-операцией. Мы написали библиотеку, которой обобщается логика создания POJO листинга из Redis. Ею выполняются параллельные вызовы к Redis, получаемые таким образом для различных атрибутов данные затем объединяются в единый POJO.
Предложения, связанные с листингом, например, сохранены в Redis как SET, а данные о доступности для различных зон обслуживания — как BITFIELD. Извлечение данных для обоих требуемых отдельных запросов к Redis и парсинг ответов соответственно отличались.
Изучить узкое место решили снизу вверх, поэтому начали с Redis.
Настройка Redis
Мы экспериментировали с настройкой размера пакета и количества потоков-опрашивателей на каждом сервере приложения, но повышения общей производительности не заметили. Хотя задержка для каждого пакета немного снизилась, в итоге пакетов для обработки стало больше, отчего обнулился положительный эффект этих манипуляций.
Мы также обнаружили неиспользуемые атрибуты листинга, которые тем не менее оставались частью POJO листинга. Удалив их из POJO, получили небольшую прибавку производительности, но этого все равно было недостаточно.
А еще для совершенствования балансировки нагрузки увеличили количество реплик в каждом сегменте кластера Redis, но так кластер простаивает и задействуется только во время развертывания Mustang — это не практично. Добавлять ресурсы здесь посчитали нецелесообразным.
Поскольку дальнейшая оптимизация Redis была затруднительна, обратились к серверной части приложения.
Генерирование файлового кэша
Идея заключалась в том, чтобы для создания структуры данных в памяти единственный раз извлечь их из Redis, а затем локально кэшировать для будущих развертываний.
Чтобы сериализовать все структуры данных в памяти в отдельные файлы на локальном диске, мы написали обработчик завершения работы. При запуске приложения локально сохраненные данные десериализуются, и структуры данных в памяти загружаются.
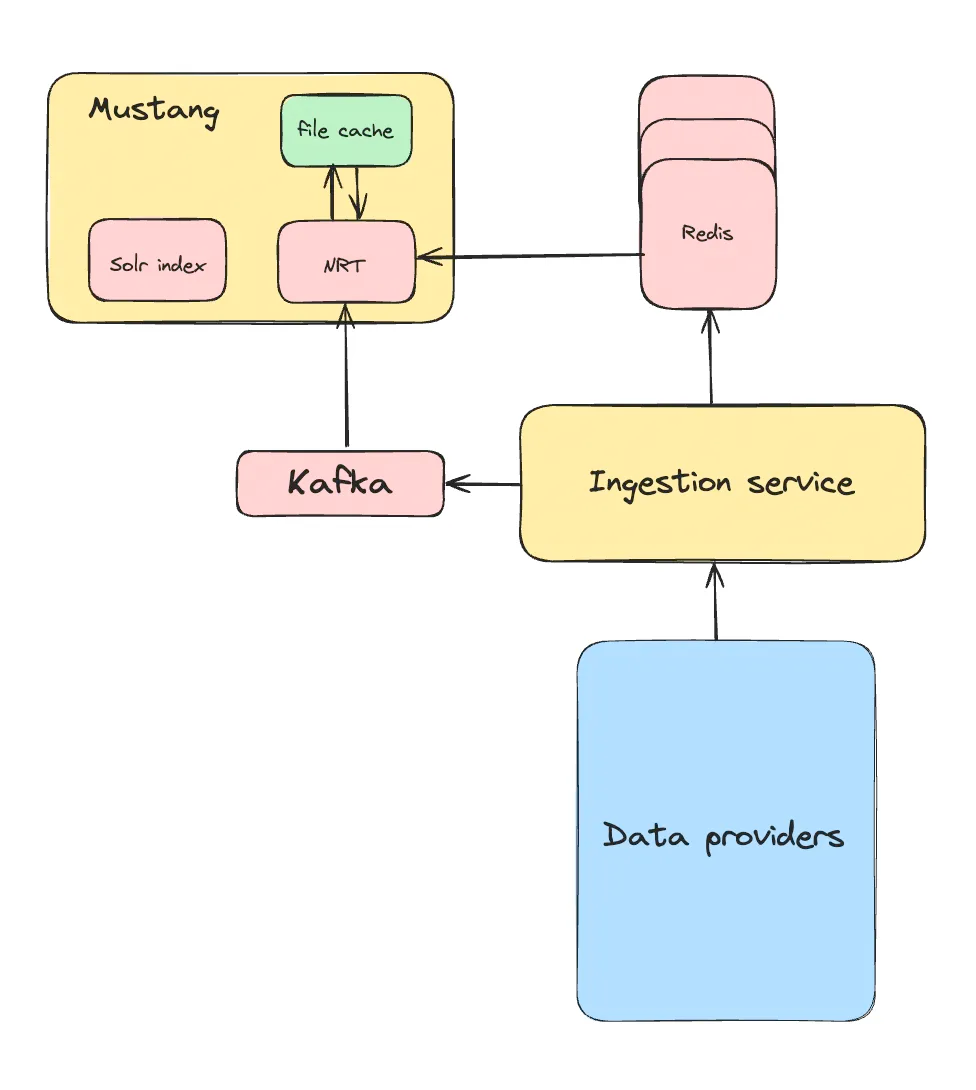
Идея казалась перспективной, но потом появились проблемы:
- Фактически структуры данных в памяти — это разные сегменты в коде и памяти, но все они определяются данными листинга. Если при сериализации хотя бы одного сегмента что-то пойдет не так, перезагрузить этот сегмент без предварительной перезагрузки всех данных листинга не получится. То есть, даже если поврежден только один файл, все сериализованные данные выбрасываются, и данные снова целиком загружаются из Redis.
- Данные листинга остаются неизменными для каждого сегмента, но на разных серверах приложений эти структуры данных в памяти варьируются, даже внутри одного сегмента. Эта вариативность обусловлена случайным характером порядковых чисел, которыми идентифицируются листинги в этих структурах данных. Эти порядковые числа листингов генерируются в ходе асинхронного процесса загрузки индексных файлов SOLR по принципу «первым пришел — первым обслужен», то есть они не детерминированны. Следовательно, с другими репликами того же сегмента сериализованные файлы не разделяются.
- Код казался неаккуратным из-за применения для сериализации и десериализации Jackson, которому для корректного функционирования требуются геттеры и сеттеры в коде. В итоге появились сложности, особенно при работе с наследованием или когда у нас уже были геттеры с пользовательской логикой вместо простого возвращения атрибута.
При этих ограничениях требовалось решение понадежнее и элегантнее. Интересным показался подход со встроенной базой данных и пилотными версиями, и в итоге мы выбрали RocksDB.
RocksDB в помощь
Почему RocksDB?
- Это встроенная база данных: она запускается не на централизованном сервере, а прямо в коде как библиотека. Идеально, ведь мы старались избегать централизованных решений.
- Ею предоставляются параметры конфигурации для настройки под конкретные потребности.
- При тестировали с разными рабочими нагрузками обнаружились интересные результаты, и мы уверились в ее производительности.
- Это популярная база данных, широко применяемая в отрасли: в X для решения аналогичной задачи, в Cloudflare и при интеграции с MySQL как подсистемы хранилища и т. д.
- У нее активная поддержка сообщества.
Приняв во внимание все эти преимущества, мы остановили выбор хорошей встроенной базы данных на RocksDB.
Схема хранения данных RocksDB
Теперь предстояло интегрировать ее в код. Задача несложная: единственный раз извлечь данные из Redis и сохранить их в RocksDB, чтобы задействовать эти локально сохраненные данные в последующих развертываниях.
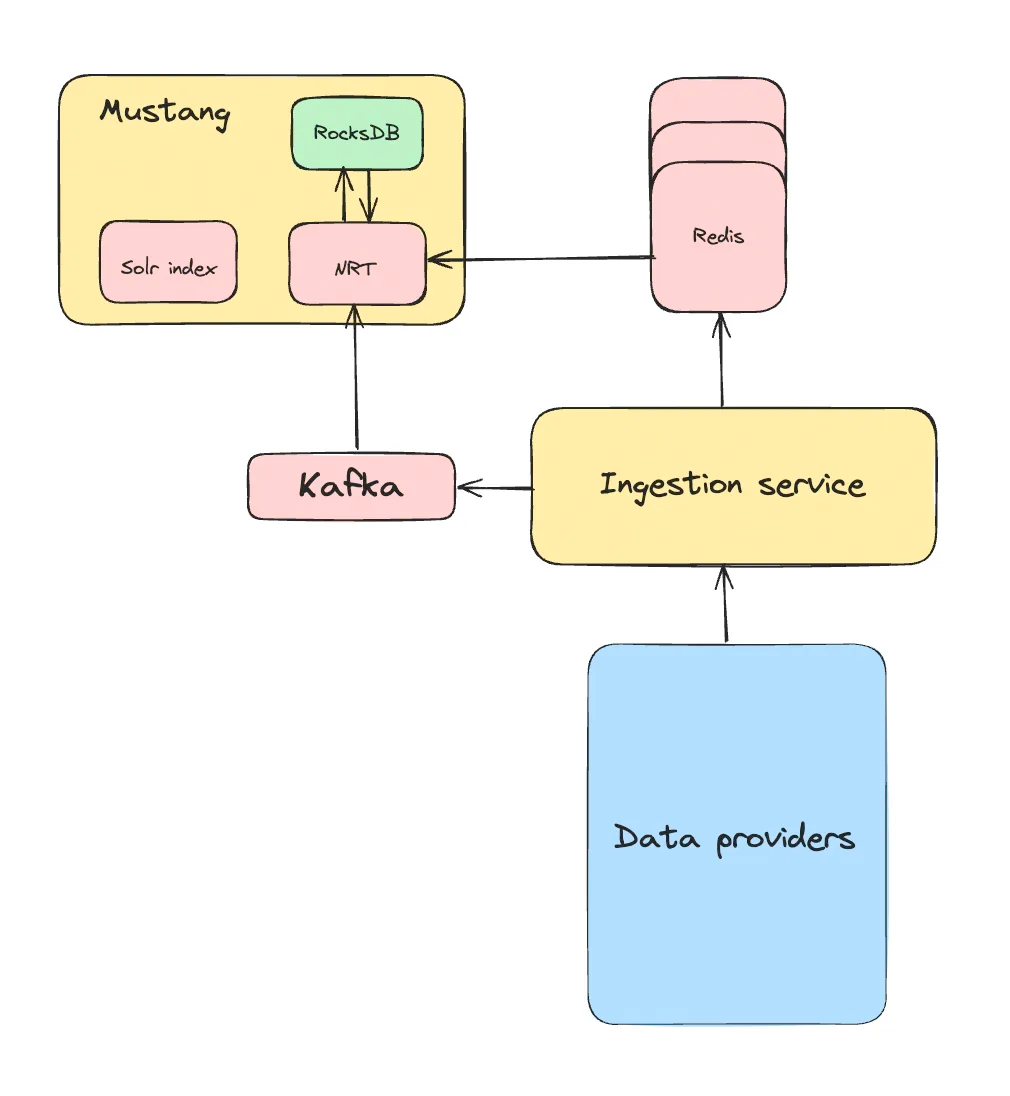
Мы сделали простую схему хранения данных. В каждой строке RocksDB содержались данные для одного листинга. Его идентификатор был для строки ключом, а сериализованный POJO — значением:
“LISTING_1”: “{\”attribute_1\”: \”value_1\”, \”attribute_2\”: \”value_2\”}”
Помимо простоты, другой важной причиной выбора этой схемы была детализация операций. Здесь можно обновить, вставить или извлечь один листинг или их группу. Если в RocksDB нет данных для листингов, просто извлекаем эти недостающие записи из Redis на следующем этапе начальной загрузки и дополняем ими RocksDB. Система самовосстанавливается.
Это стало основой нашего решения, но много с чем еще предстояло разобраться.
Решение проблемы устаревших данных
Однократного извлечения данных из Redis и их локального сохранения было недостаточно из-за быстро меняющегося характера нашего бизнеса. Большинству бизнес-требований Flipkart требуются изменения в атрибутах листингов и аналогичные изменения схемы для структур данных в памяти. Когда это случается, сохраняемые в RocksDB данные становятся несовместимыми со схемой приложения.
Чтобы решить эту проблему, мы сохранили вместе с данными листинга в RocksDB хэш схемы структуры данных в памяти. Когда осуществляется развертывание, эта схема сравнивается с последней сохраненной в коде схемой. При несоответствии схем данные RocksDB просто выбрасываются и заменяются последними данными из Redis.
Этот подход оказался рабочим, но 60 % развертываний Mustang были связаны с изменением структуры данных. А значит, для большинства развертываний по-прежнему задействовался Redis, это не идеально.
Поэтому мы придумали план получше. Во всех репликах внутри одного сегмента содержались одинаковые данные листинга. Так почему бы не создать данные RocksDB из одной случайной реплики каждого сегмента, сохранить их в GCS, а затем использовать для других реплик в этом сегменте?
Логика реализовывалась легко. Мы написали в коде слой валидации, в котором во время запуска Mustang сравниваются хэши схем. Если они совпадают, приложением загружаются данные из RocksDB; если нет, в приложении удаляются локальные данные RocksDB и извлекаются последние данные из GCS, после чего продолжается загрузка данных из RocksDB.
Если в GCS данных нет, для начальной загрузки данных приложение возвращается к Redis. Для обработки этого типа развертывания были изменены и соответствующие конвейеры. При каждом изменении схемы из каждого сегмента конвейером непрерывной интеграции выбиралась случайная реплика, на ней развертывался последний код, выполнялась начальная загрузка из Redis, после чего локальные данные RocksDB подгружались в GCS. Затем, когда локальные данные оставшихся реплик становились недействительными, последними автоматически выбирались данные из GCS.
Работа с обновлениями Kafka
Для соответствия данных в RocksDB и в Redis, прежде чем изменения отражались в структурах данных в памяти, обновления Kafka специальным классом перехватывались и добавлялись в RocksDB.
Весь POJO сохранялся в RocksDB, и для обновления данных выполнялась операция чтения/изменения/обновления. Основная техническая трудность заключалась в устранении возможных сбоев обновления в RocksDB, чтобы при следующем перезапуске Mustang из RocksDB извлекались новейшие данные.
Для этого мы внедрили обработку ошибок в блоке try-catch. Если по какой-либо причине обновление не выполнялось, соответствующий листинг из RocksDB удалялся. В редких случаях неудачного удаления, даже после повторных попыток, по завершении работы весь набор данных RocksDB очищался. Но и при необновлении RocksDB структура данных в памяти все равно обновлялась — во избежание расхождения данных у пользователя.
Оставалась еще одна проблема. После того как выполнена начальная загрузка из RocksDB, в Mustang начинается считывание событий Kafka с последнего смещения, которое в имеющейся системе было стандартного типа. Это чревато потерей данных, ведь при перезагрузке Mustang обновления в RocksDB не добавляются. Раньше это не было проблемой: Mustang загружался из Redis — источника истины, поэтому дальше начиналось безопасное считывание с последнего смещения Kafka.
Чтобы решить эту проблему, мы начали сохранять смещения Kafka всех разделов в RocksDB во время завершения работы. Затем при запуске в Mustang выполнялся обратный поиск сохраненных смещений соответствующих разделов. Если по какой-то причине — например, сбой приложения — смещения в RocksDB не обнаруживались, мы удаляли локальный дамп. Делали это и при значительном расхождении текущих и сохраненных смещений, понимая, что на устранение такого большого разрыва в данных потребуется много времени. Пороговое значение этого расхождения определяется количеством обновлений, обрабатываемых в Mustang за пять минут.
Настройка RocksDB для нашего сценария
Интегрировав RocksDB в кодовую базу, мы сократили время Mustang на начальную загрузку структур данных в памяти с 30 до 15 минут. И раскрутили бы RocksDB дальше, если бы знали изнутри эту базу данных и понимали схемы доступа.
Наша рабочая нагрузка — и запись, и считывание. Хотя начальная загрузка данных из Redis и вставка их в RocksDB связаны исключительно с интенсивной записью данных, для последующих развертываний это всегда интенсивное считывание. Имея возможность оптимизировать только одну схему доступа, мы по очевидным причинам остановились на считывании.
Вот наши оптимизации:
- Отключение кэша. В любом сценарии с RocksDB рекомендуется кэш блоков на основе LRU, недостатком которого, однако, является серьезный конфликт при блокировках. Наш сценарий — считывание листингов в основном на этапе начальной загрузки, то есть это схема с однократным считыванием, поэтому кэш для блоков данных мы отключили.
- Уплотнение уровнями. По сравнению со стратегией уплотнения по размеру, называемой также универсальной, уплотнением уровнями обеспечиваются совершенствование считывания и увеличение пространства.
- Уменьшение уровней в LSM-дереве. Количество уровней — важное свойство LSM-дерева в RocksDB. Много уровней целесообразно, если по крайней мере значительный объем извлекаемых данных «горячий». В противном случае это сказывается на задержках считывания. Наша схема доступа случайная, поэтому увеличивать уровни не целесообразно — мы уменьшили их с семи по умолчанию до трех.
- Запуск периодического полного уплотнения. Производительность считывания RocksDB максимизируется минимальным увеличением считывания. Чтобы сократить увеличение считывания и пространства из-за обновлений Kafka, запускается полное уплотнение вручную. Так достигается оптимальный результат. Мы написали асинхронный поток, которым раз в сутки — в нерабочее время — запускается полное уплотнение.
- Отключение журнала предзаписи WAL. По умолчанию в RocksDB все записи сохраняются в журнале предзаписи WAL вместе с memtable. Сценарий самовосстанавливается, потеря данных исключена, поэтому WAL мы отключили.
- Считывание данных из БД командой MultiGet(). В RocksDB это эффективнее, чем несколько вызовов get() в цикле. Причины: меньше конкуренция потоков в кэше фильтров/индексов, меньше внутренних вызовов методов и оптимальнее распараллеливание ввода-вывода для разных блоков данных.
- Сортировка и пакетная обработка листингов. Прежде чем извлекать данные из RocksDB, весь набор листингов отсортировали, затем создали из него пакеты поменьше. Так мы уменьшили случайный ввод-вывод с диска, ведь отсортированные листинги размещаются на диске вместе, отчего увеличивается вероятность их нахождения на одних и смежных страницах диска.
После всех этих оптимизаций начальная загрузка сократилась с 15 до примерно шести минут, а это значительный рост эффективности.
Подробнее — в руководстве по настройке.
Перевод RocksDB на продакшен
Все подготовив, мы рвались перевести RocksDB в продакшен. Однако с появлением в инструментарии новой технологии нужно было тщательно предотвращать любые сбои. Чтобы отслеживать взаимодействие Mustang с RocksDB и минимизировать риски, мы внедрили соответствующие метрики. Затем на ограниченном количестве реплик каждого сегмента инициировали развертывания.
Небольшая загвоздка
Вскоре после того как на серверах Mustang развернули последний код, обнаружилось замедление отклика. Оказалось, что вся память виртуальной машины потихоньку расходовалась в течение нескольких дней. Из-за избыточного расхода памяти затруднялось кэширование индексных файлов в Solr, нагрузка на диск во время выполнения становилась чрезмерной, в итоге увеличились задержки. Очевидно, эта утечка памяти не вызвана приложением Java в одиночку, ведь во время запуска ему выделен фиксированный объем памяти — в виде динамической памяти, — и используется лишь немного дополнительной неуправляемой памяти для работы JVM. Вот руководство по обнаружению неуправляемой памяти, используемой в JVM.
Мы заподозрили RocksDB: это встроенная база данных, но не просто библиотека Java, в ней имеется компонент C++ для взаимодействия с приложениями Java через JNI. С какими бы связанными с RocksDB классами мы в Java ни взаимодействовали, в RocksDB ими вызывается их аналог на C++. Управление памятью в C++ затруднено из-за отсутствия системы автоматической сборки мусора. Сначала мы подумали, что наверняка это баг RocksDB.
Тогда мы стали изучать варианты по устранению утечки неуправляемой памяти. Об этом можно было бы написать отдельную статью, но ради простоты ограничимся самым главным.
В стремлении разобраться с этим типом утечки памяти мы наткнулись на Jeprof, инструмент для отслеживания неуправляемой памяти, выделяемой, например, при вызовах JNI. Мы настроили Jeprof так, чтобы каждые несколько минут им получались дампы выделяемой приложением неуправляемой памяти. Затем, чтобы посмотреть, какие объекты увеличивались в размерах, сравнили два случайных, сгенерированых с интервалом в несколько часов дампа. Вот усеченный результат:

Обнаружилось интенсивное выделение объектов RocksDB ReadOptions() и WriteOptions().
При проверке кода выявлено только одно место, где для этих двух классов выделялись новые объекты. Для обработки в коде связанных с RocksDB конфигураций мы создали класс с объектами вроде ReadOptions() и WriteOptions(), сопоставляемыми в карте с различными названиями семейств столбцов. Эти объекты обычно предоставляются во время запуска Mustang и никогда не создаются повторно.
На всякий случай мы сделали решение для сценариев, в которых при выполнении запросов в семейство столбцов эти объекты еще не доступны. Методом getOrDefault() во время выполнения для конкретного семейства столбцов извлекался предварительно настроенный объект либо генерировался новый. Вот код Java для этой реализации:
...
public ReadOptions getReadOptionsByColumnFamily(String columnFamilyName) {
return this.readOptions.getOrDefault(columnFamilyName, new ReadOptions());
}
public WriteOptions getWriteOptionsByColumnFamily(String columnFamilyName) {
return this.writeOptions.getOrDefault(columnFamilyName, new WriteOptions());
}
...
Но откуда взялась утечка памяти?
В документации об управлении памятью написано, что каждым классом RocksDB прямо или косвенно реализуется Autocloseable. Чтобы высвободить занимаемую объектами RocksDB на C++ фактическую память, в Java-объектах RocksDB по завершении их использования явно вызывается close() или применяется try-with-resources. Если этого не делать, случаются утечки памяти.
Реализуя логику в приведенных выше фрагментах кода, мы не обратили внимания, что при каждом вызове этого метода в getOrDefault() инстанцировались новые объекты — независимо от того, имелся ли преднастроенный объект для конкретного семейства столбцов или нет. На этих вновь созданных объектах не вызвали close(), поэтому и случилась утечка памяти.
Поняв первопричину, мы легко справились с проблемой: при инстанцировании этого класса конфигурации создали объекты по умолчанию ReadOptions и WriteOptions и использовали их вместо создания новых в getOrDefault().
Мы быстро распространиили это решение на серверы Mustang и, чтобы убедиться в стабильности памяти, немного понаблюдали за ними.
Развертывание продолжается
Все запускалось гладко и без эксцессов со стороны RocksDB, и мы приступили к развертыванию остальных серверов Mustang, уделяя особое внимание системным ресурсам. Таким последовательным подходом мы обеспечили плавный переход и поддержание стабильности в эксплуатационной среде.
Заключение
С RocksDB процесс развертывания для Mustang значительно усовершенствовался.
Перейдя от Redis к локальному хранению данных, мы прилично сократили время на начальную загрузку структур данных в памяти: с 30–40 минут до в среднем всего шести. Это обнаружилось при обстоятельном тестировании на различных сегментах.
Прогресс достигнут не только во времени начальной загрузки каждого сервера. Потенциально выше теперь и коэффициент развертывания: зависимость от Redis минимальна, параллельно развертывается больше серверов.
В результате весь процесс развертывания Mustang на всех сегментах теперь занимает менее трех часов. А значит, благодаря применению RocksDB эффективность повысилась. Будем и дальше привержены постоянному совершенствованию и оптимизации имеющейся инфраструктуры.
Читайте также:
- SCDB: простая Open Source БД типа «ключ — значение»
- Отчего «паникует» даже камнеукладчик: инцидент с удалением строк
- Обработка дублированных сообщений в Kafka
Читайте нас в Telegram, VK и Дзен
Перевод статьи Rahul Arora: Server bootstrap optimization using RocksDB





