
Мы постоянно делимся информацией в интернете: статьями, видео, продуктами. Веб-адреса, или URL-адреса, являются воротами для доступа к этому контенту. Но длинными URL-адресами обмениваться неудобно, особенно в соцсетях или мессенджерах с их ограничениями по количеству символов. И тогда приходятся кстати сайты вроде bit.ly и TinyURL, где длинные ссылки становятся короче и удобнее, благодаря чему обмен контентом на различных платформах упрощается.
Как же быть с колоссальной нагрузкой на базовую инфраструктуру, создаваемой ежедневным применением этих сервисов миллионами пользователей по всему миру? Проектировать высокоуровневые системы.
Наша цель ― разобрать функциональность, архитектуру, проблемы, масштабируемость, системные API-интерфейсы, производительность и оценку ресурсов для каждой системы, представить необходимые данные для аналогичных проектов в реальных сценариях. Точно так же, как создание кода ― нечто большее, чем просто написание строк кода, проектирование подразумевает создание интуитивного, структурированного мыслительного процесса. Нельзя написать по-настоящему хороший код без четкого представления о его проектировании.
Понадобится знание:
- Генератора последовательностей.
- Типов кодировки: Base 58, Base 64.
- Глобальной балансировки нагрузки серверов.
- Рукописных математических расчетов по оценке ресурсов.
Что изучим о проектировании систем?
Мы разделили это на семь модулей:
1. Функциональные и нефункциональные требования.
2. Оценка ресурсов — серверов, пропускной способности, хранилища.
3. Подробно о строительных блоках.
4. Системные API-интерфейсы.
5. Компоненты и схема рабочего процесса.
6. Схемы кодирования и вычисления.
7. Соответствие нефункциональным требованиям.
Почему сокращенный URL-адрес удобнее?
- Легко запоминается/вводится: использование ссылок на различных устройствах оптимизируется благодаря их повышенной доступности и защите от вымирания.
- Выглядит профессионально, привлекательно, упрощает обмен информацией.
- Требует меньшего объема памяти на стороне пользователя.
Модуль 1. Требования
Функциональные требования
Рассмотрим фактическую функциональность этой системы, без требований начинать проектирование нельзя:
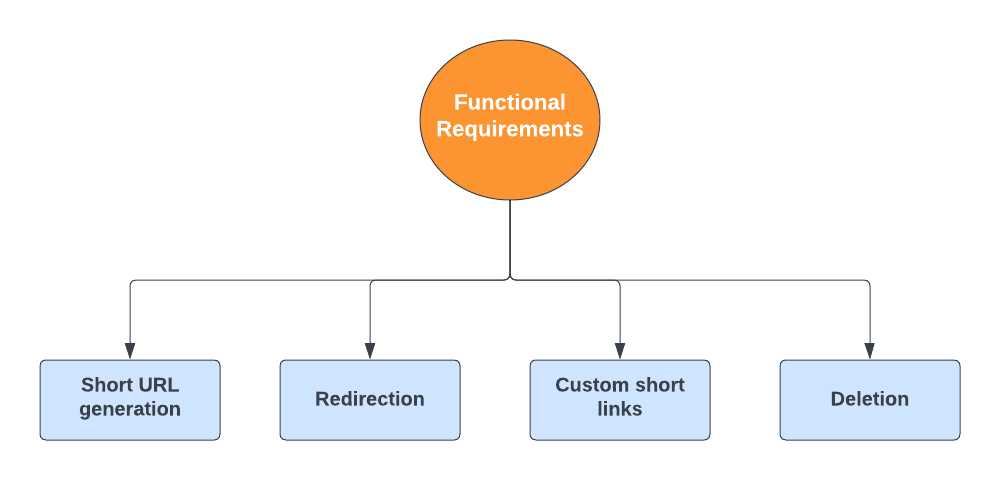
- Короткий URL-адрес: сервисом генерируется уникальный короткий псевдоним данного URL-адреса.
- Перенаправление: по короткой ссылке пользователь перенаправляется системой на исходный URL-адрес.
- Пользовательские короткие ссылки: генерируются в системе пользователями для своих URL-адресов.
- Удаление: пользователи удаляют сгенерированную системой короткую ссылку.
Нефункциональные требования
Этими критериями определяется поведение системы, а не действия:
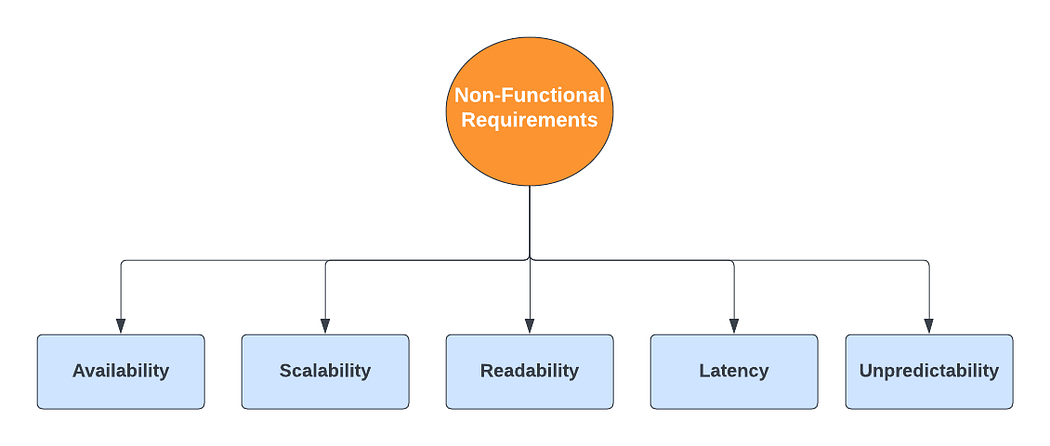
- Доступность: система высокодоступна, даже доля секунды простоя чревата сбоями перенаправления URL-адресов. Предметная область системы находится в URL-адресах, поэтому возможности простоя нет, при проектировании закладываются условия отказоустойчивости.
- Масштабируемость: система горизонтально масштабируется с учетом растущей потребности.
- Удобство восприятия: короткие ссылки, генерируемые системой, удобны для восприятия, различимы, пригодны для ввода.
- Задержка: система функционирует с низкой задержкой, чем обеспечивается хорошее пользовательское взаимодействие.
- Непредсказуемость: с точки зрения безопасности короткие ссылки, генерируемые системой, в высшей степени непредсказуемы. Этим гарантируется, что следующий в строке короткий URL-адрес не выдается в серийной последовательности, то есть угадать все короткие URL-адреса, которые когда-либо выдавались или будут выдаваться системой, невозможно.
Модуль 2. Оценка ресурсов
В этой части рассчитаем необходимые системе ресурсы. Важно знать, насколько большой она станет, и заранее планировать хранилище, пропускную способность, серверы и т. д.

Допущения
- Соотношение запросов на сокращение/перенаправление — 1:100. То есть, если сокращается 1000 URL-адресов, то перенаправлений на эти сокращенные URL-адреса ~100 000.
- Новых, уникальных запросов от пользователей на сокращение URL-адресов — 200 млн в месяц.
- На запись сокращения каждого URL-адреса требуется 500 байт в базе данных, включая всю необходимую информацию для перенаправления пользователей на исходный URL-адрес.
- Каждая запись URL-адреса в базе данных хранится и остается активной максимум пять лет с момента создания, если не удаляется явно. По истечении этого срока она удаляется из базы данных автоматически.
- Активных пользователей ежедневно — 100 млн: столько людей активно используют сервис каждый день, создают сокращенные URL-адреса и/или переходят по сокращенным ссылкам.
Оценка хранилища
Поскольку записи хранятся пять лет и каждый месяц их по 200 млн, всего будет ~12 млрд записей:
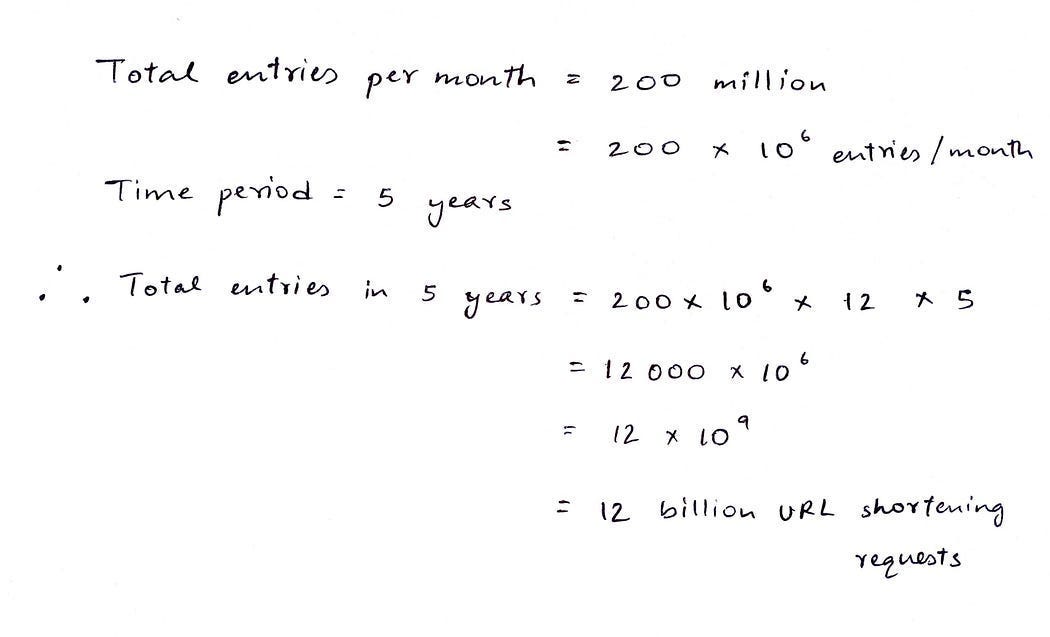
Поскольку каждая запись — 500 байт, общая оценка хранилища — 6 Тбайт:

Частота запросов
Попробуем прикинуть количество получаемых URL-адресов в секунду, потом пригодится в расчете пропускной способности.
Исходя из приведенных выше оценок, для 200 млн запросов на сокращение URL-адресов ожидается 20 млрд запросов на перенаправление в месяц:

У нас 200 млн запросов на сокращение URL-адресов и 20 млрд запросов на перенаправление в месяц.
Посчитаем теперь для системы количество запросов в секунду, взяв полученное только что значение, количество секунд и в среднем 30 дней в месяце:

С учетом соотношения сокращения к перенаправлению 1:100 рассчитаем скорость перенаправления URL-адресов в секунду:

Оценка пропускной способности
Пропускная способность = трафик × средний размер ответа.
- Трафик — это количество запросов в единицу времени, например запросов в секунду.
- Средний размер ответа считается в байтах.
Запросы на сокращение: известна ожидаемая частота поступления 77 новых URL-адресов в секунду.

Всего поступающих данных 308 Kбит в секунду.
Запросы на перенаправление: ожидаемая частота перенаправления 7,7 тыс. URL-адресов в секунду, поэтому всего исходящих данных 30,8 Мбит/с:

Входящая пропускная способность = 308 Кбит/с.
Исходящая пропускная способность = 30,8 Мбит/с.
Оценка сервера
Прежде чем считать приблизительное количество серверов для этой системы, рассмотрим небольшой пример.
Допущения
- Активных пользователей ежедневно — 500 млн.
- В среднем один пользователь делает 20 запросов в день.
- На одном сервере обрабатывается 8000 запросов в секунду.

Для 500 миллионов пользователей 15 серверов явно не достаточно, в крупных сервисах их намного больше. Значит, что-то не так с вычислениями, простой подсчет количества запросов в секунду не дает полной картины потребностей в серверах.
Кроме того, в вычислениях предполагается, что каждый запрос обслуживается одним сервером, хотя в действительности может проходить через различные типы серверов: веба, приложений, хранения.
Поэтому, чтобы рассчитать необходимое количество серверов, учтем два фактора:
- ежедневное количество активных пользователей;
- ежедневный лимит обработки пользователей сервером.

Эта цифра реалистичнее — 12 500 серверов.
Кэш: оценка памяти
Чтобы кэшировать частотные запросы на перенаправление URL-адресов, нужны оценки памяти. Допустим, входящие запросы распределяются в соотношении 80:20. 20% запросов на перенаправление генерируется 80% трафика.
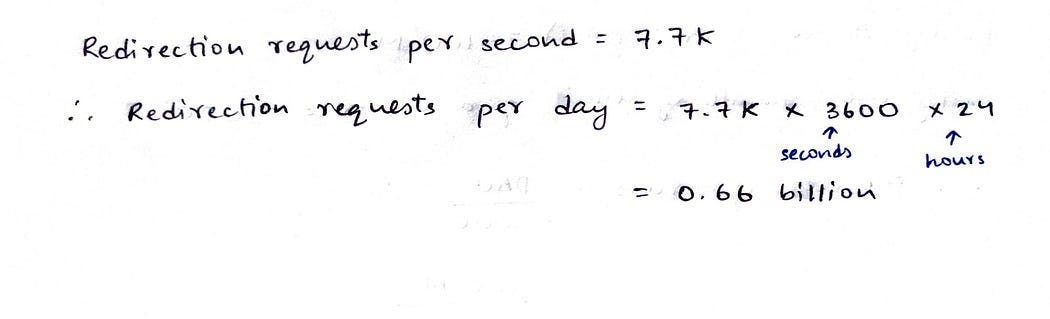
Кэшируя только 20% этих ежедневных запросов на перенаправление, получим общую оценку требуемой памяти 66 ГБ.
То есть 66 ГБ кэша вполне достаточно.
Модуль 3. Строительные блоки
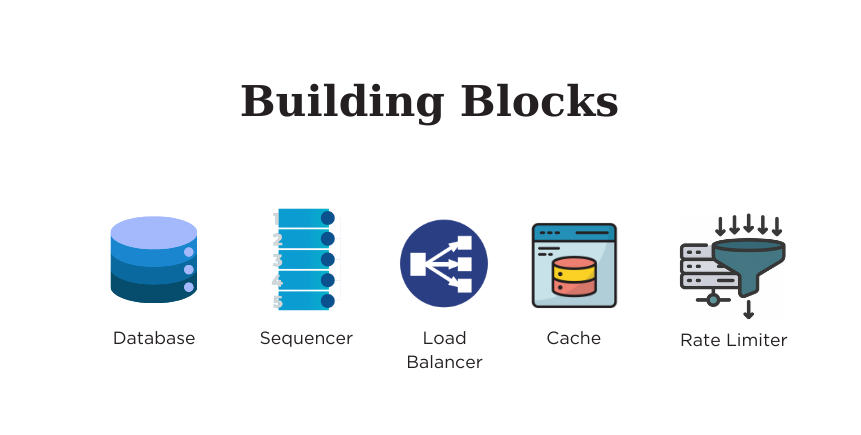
Выполнив расчеты, определим ключевые строительные блоки проектирования.
- База данных: для хранения сопоставлений длинных URL-адресов с короткими.
- Генератор последовательностей: с уникальными идентификаторами — отправной точкой для создания каждого короткого URL-адреса.
- Балансировщик нагрузки: для равномерного распределение запросов между доступными серверами на различных уровнях.
- Кэш: для хранения частотных запросов, связанных с короткими URL-адресами.
- Ограничитель скорости: для предотвращения злонамеренного использования системы.
- Серверы: для обработки запросов сервисов вместе с запуском логики приложения.
- Кодировщик Base-58: для преобразования цифровых выходных данных генератора последовательностей в более удобную буквенно-цифровую форму.
Модуль 4. Системные API-интерфейсы
Для функциональности сервиса снабдим REST API-интерфейсами:
- сокращение URL-адреса;
- перенаправление короткого URL-адреса;
- удаление короткого URL-адреса.
Сокращение URL-адреса
Создадим новые короткие URL-адреса с таким определением:

При успешной вставке пользователю возвращается сокращенный URL-адрес, в противном случае ― соответствующий код ошибки.
Перенаправление короткого URL-адреса
Вот определение REST API для перенаправления короткого URL-адреса:

При успешном перенаправлении пользователь оказывается в исходном URL-адресе, связанном с url_key.
Удаление короткого URL-адреса
Вот аналогичное определение REST API для удаления короткого URL-адреса:

При успешном удалении возвращается системное сообщение URL Removed Successfully (URL-адрес удален).
Проектирование базы данных
Посмотрим на данные для сохранения:
Данные пользователя
- UserID: специальный идентификатор или API-ключ для однозначной идентификации пользователей по всему миру.
- Name: имя пользователя.
- Email: адрес электронной почты пользователя.
- Creation Date: дата, когда пользователь зарегистрировался для создания короткого URL-адреса.
Данные короткого URL-адреса
- Короткий URL-адрес: уникальный короткий URL-адрес длиной обычно в семь символов.
- Исходный URL-адрес: исходный длинный URL-адрес.
- UserID: уникальный идентификатор или API-ключ пользователя, создавшего короткий URL-адрес.
Модуль 5. Компоненты и рабочий процесс подробно
- База данных: для сервисов сокращения URL-адресов объем сохраняемых данных минимален, но хранилище горизонтально масштабируется. Какие данные сохраняются:
- сведения о пользователе;
- сопоставления URL-адресов: длинных с короткими.
Почему система/хранилище горизонтально масштабируется?
Благодаря горизонтальной масштабируемости растущие объемы трафика и данных обрабатываются в сервисах сокращения URL-адресов без перегрузки системы.
Нереляционная база данных хороша для системы с многочисленными считываниями. Кроме того, сохраненные записи отделены и лишены связей, за исключением сведений о пользователе, создавшем URL-адрес.
MongoDB ― хороший вариант, потому что:
- им применяются реплики для интенсивного считывания;
- без проблем справляется с одновременными операциями записи.
Нереляционная база данных идеальна для нашей системы, в которой обрабатывается много считываний без замедления. Это гибкая БД для работы с разнообразными данными, при необходимости она легко увеличивается. Кроме того, в ней быстро находится нужная информация, даже если ею одновременно пользуется много людей.
2. Генератор коротких URL-адресов, он состоит из двух частей:
- генератора последовательностей для создания уникальных идентификаторов;
- кодировщика Base-58 для удобства восприятия коротких URL-адресов.
Генератор последовательностей:
В сервисе сокращения URL-адресов уникальные сокращенные URL-адреса создаются генерированием уникальных идентификаторов — обычно посредством увеличения счетчика или использования распределенного алгоритма для генерирования идентификаторов на нескольких серверах без коллизий. Так гарантируется, что каждым сокращенным URL-адресом — даже при высокой конкурентности и быстрых запросах на сокращение URL-адресов — получается уникальный идентификатор, чем предотвращаются конфликты и обеспечивается целостность сервиса.
Кодировщик Base-58:
Так же, как генерирование уникальных идентификаторов, для пользовательского взаимодействия важно создание сокращенных URL-адресов, удобных для человеческого восприятия и совместного использования. Здесь приходится кстати кодировщик Base-58, который отличается от Base-64 исключением символов 0, O, I и l — нуля, заглавных букв o, i и строчной L соответственно. Так удается избежать путаницы, сделать кодировку удобнее.
3. Балансировка нагрузки
Для высокой доступности применим:
- глобальную балансировку нагрузки на серверы, когда запросы распределяются между различными глобальными серверами, особенно во время сбоев на местах, чем обеспечивается эффективная обработка трафика;
- локальную балансировку нагрузки.
Почему нужны обе балансировки?
Глобальная балансировка нагрузки на серверы необходима для распределения входящего трафика между несколькими географически отдаленными дата-центрами или регионами. В условиях увеличения глобализации онлайн-сервисов и спроса на пользовательское взаимодействие при низкой задержке глобальная балансировка нагрузки важна для обеспечения стабильной производительности в различных регионах. Благодаря этому компании эффективно обслуживают клиентов независимо от их географического местонахождения и обеспечивает высокую доступность, перенаправляя трафик из регионов, где наблюдаются проблемы или сбои.
Локальной балансировкой нагрузки трафик распределяется в пределах одного дата-центра или сети. Так оптимизируется расходование ресурсов, убыстряется отклик, предотвращаются перегрузки отдельных серверов.
4. Кэш: идеальный инструмент кэширования для приложений интенсивного считывания — Memcached. В каждом дата-центре для обработки ближайших запросов реализуется слой кэширования, ранее также обсуждались требования по хранилищу кэша.
5. Ограничитель скорости: для ограничения задач сокращения и перенаправления, выполняемых за определенное время, у каждого пользователя имеется уникальный ключ api_dev_key.
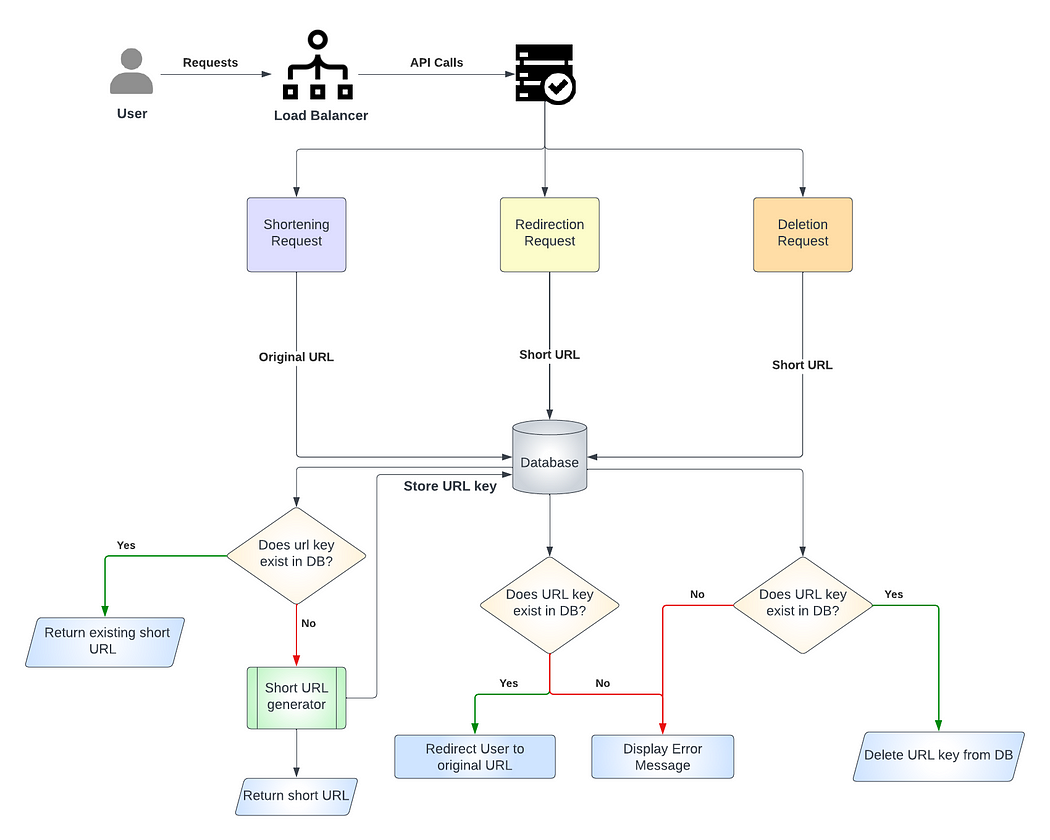
Рабочий процесс
Рассмотрим, как реализуется функциональность системы при взаимодействии всех ее частей.
- Сокращение: когда пользователь запрашивает короткую ссылку, сервером приложений его запрос перенаправляется генератору коротких URL-адресов. Как только короткая ссылка сгенерирована, одна копия отправляется пользователю, а
url_keyсохраняется в базе данных для дальнейшего использования. - Перенаправление: когда пользователь запрашивает перенаправление, система кэширования и база данных проверяются сервером приложения на наличие требуемой записи. Если она найдена, пользователь перенаправляется в соответствующий длинный URL-адрес. В противном случае отображается сообщение об ошибке.
- Удаление: запись удаляется посредством запрашивания сервера приложения, которым затем на наличие требуемой записи проверяются система кэширования и база данных. Если она найдена, удаляется вместе с ее
url_key. В противном случае отображается сообщение об ошибке. - Пользовательские короткие ссылки: системой проверяется соответствие запрашиваемого короткого URL-адреса критериям, максимальная длина — 11 буквенно-цифровых символов. В случае соответствия системой проверяется его наличие в базе данных. При наличии пользователь получает сообщение о генерировании короткого URL-адреса, в противном случае — сообщение об ошибке.
Вот схема рабочего процесса:
Модуль 6. Кодирование
Кодированием при сокращении URL-адресов такие данные, как буквы и символы, преобразуются в специальный формат для отправки через интернет. Так гарантируется, что созданные короткие ссылки безопасны для URL-адресов и не обернутся проблемами при их использовании или распространении.
Имеются такие кодировки:
- Base 64: применяется 64 символа (A-Z, a-z, 0–9, +, /) для представления двоичных данных.
- Base 62: отличается от Base-64 исключением символов, небезопасных для URL-адресов, например +, /. Применяется 62 символа (A-Z, a-z, 0–9).
- Base 58: отличается от Base 62 дополнительным исключением похожих символов 0, O, I и l — нуля, заглавных букв o, i и строчной L соответственно. Так повышается удобство восприятия.
Для удобства восприятия и во избежание путаницы между внешне похожими символами в системе применяется кодировка Base 58:
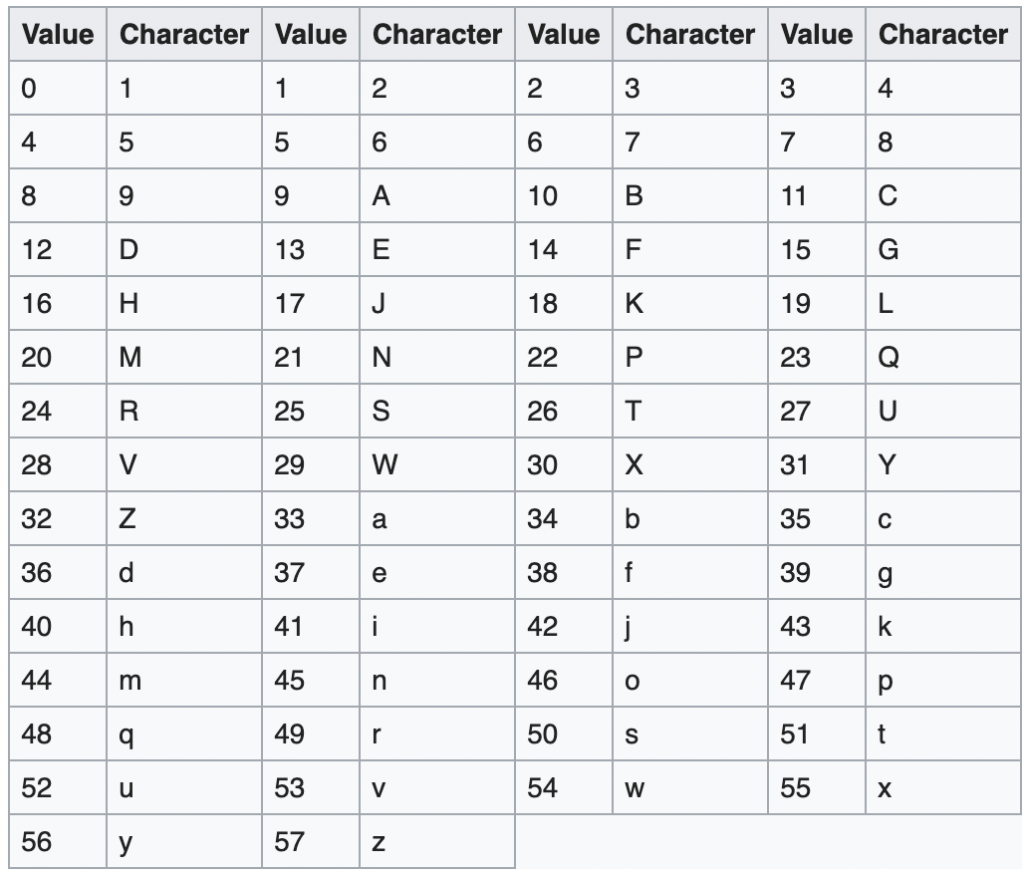
Преобразуем число из Base 58 в Base 10, и наоборот.
Преобразование из Base 58 в Base 10:
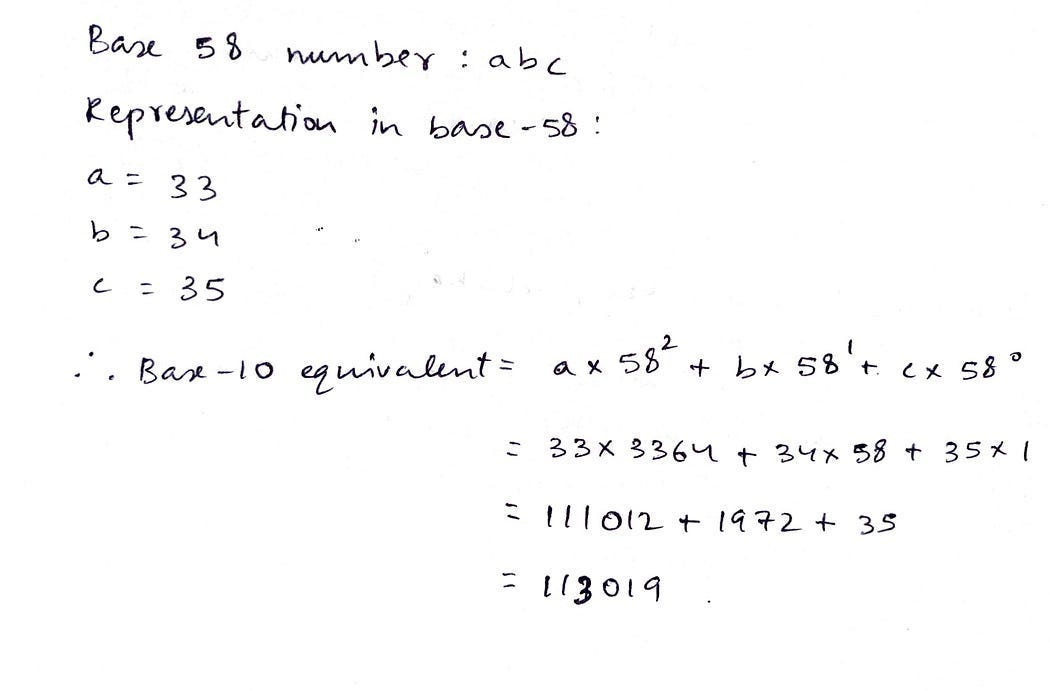
Преобразование из Base 10 в Base 58:

Определим оптимальное количество символов для сокращенного URL-адреса:
Для URL-адреса длиной 5 получим 58⁵, то есть ~656 млн URL-адресов.
Для URL-адреса длиной 6 получим 58⁶, то есть ~38 млрд URL-адресов.
Поскольку системой за счет использования хранилища генерируется 12 млрд URL-адресов, для шести символов в base58 получаем приблизительно 38 миллиардов URL-адресов. Следовательно, каждый сгенерированный короткий URL-адрес состоит из шести символов.
С чего начинается расчет генератора последовательностей для шести символов в коротком URL-адресе?
Давайте разберемся. Длинный URL-адрес сокращается с помощью генератора коротких URL-адресов, который состоит из двух частей: генератора последовательностей и кодировщика Base-58.
Получая длинный URL-адрес, мы начинаем с генерирования первой частью последовательности чисел, которые затем преобразуются в кодировку Base 58, и мы получаем короткий URL-адрес с шестью символами. Но вот в чем нюанс: с чего начинать подсчет генератором последовательностей, чтобы получить эти шесть символов? На этот вопрос требуется ответ.
Выполнив обратные вычисления, мы определили: чтобы достигнуть минимум шести символов в base-58, требуемое количество в base-10 — приблизительно миллиард.
Число Base 10: 1 000 000 000
1000000000 % 58 = 18
17241379 % 58 = 9
297265 % 58 = 15
5125 % 58 = 21
88 % 58 = 30
1 % 58 = 1
Эквивалент Base 58: [1][30][21][15][9][18]
: 2XNGAK
Итак, минимальное число base 10 для последовательности base 58 длиной шесть равно одному миллиарду. Короткие URL-адреса для любого случайного пользователя начинают генерироваться генератором последовательностей с одного миллиарда.
Модуль 7. Обзор нефункциональных требований
Итак, исходя из уже спроектированного, мы обнаруживаем соответствие всем функциональным требованиям.
Как насчет нефункциональных?
Обсудим и подведем итоги.
Доступность
- В строительных блоках имеется встроенная репликация, чем обеспечиваются доступность и отказоустойчивость.
- Глобальной балансировкой нагрузки на серверы обрабатывается трафик системы, запросы распределяются.
- Ограничителями скорости ограничивается распределение ресурсов каждого пользователя, предотвращаются DDOS-атаки.
Масштабируемость
- Используются горизонтально сегментированные базы данных.
- MongoDB — как нереляционная БД.
Удобство восприятия
- Внедрение кодировщика base-58 для генерирования коротких URL-адресов.
- Удаление не буквенно-цифровых символов.
- Удаление похожих символов.
Задержка
MongoDB, благодаря низкой задержке и высокой пропускной способности в задачах считывания.
Непредсказуемость
Из выделенного каждому серверу пула случайно выбирается неиспользуемый уникальный идентификатор. Этот подход отличается от последовательного присвоения идентификаторов, из-за чего риск предсказуемости последующих коротких URL-адресов снижается.
Кроме того, чтобы хешировать исходный URL-адрес и далее кодировать получаемый хеш в представление покороче, неплохо использовать криптографические хеш-функции, такие как SHA-256.
Вот и все.
Читайте также:
- Зачем нужен CORS: просто о сложном
- Почему стоит использовать AVIF вместо JPEG, WebP, PNG и GIF в 2024 году
- PurePWA — радикальный поворот в веб-разработке
Читайте нас в Telegram, VK и Дзен
Перевод статьи Varsha Das: How does URL shortening for TinyUrl, Bit.ly work?





