
TL;DR
- WASM (WebAssembly) отлично подходит как для фронтенда, так и для бэкенда, а не только для ускорения JavaScript в браузере.
- WASM на бэкенде работает иначе, чем FFI (Foreign Function Interface — интерфейс внешних функций). WASM обеспечивает более быструю и эффективную работу.
- Скорость работы WASM обусловлена его низкоуровневым двоичным форматом, простой моделью памяти и опережающей компиляцией. Это минимизирует накладные расходы, обеспечивая производительность, близкую к производительности нативного кода.
- Результат использования Rust и WASM для оптимизации генерации ULID в wa-ulid — 40-кратное ускорение по сравнению с JavaScript-версией.
- В настоящее время файлы WASM больше, чем JavaScript, что может быть проблематично. Но по мере совершенствования инструментальных цепочек и методов оптимизации WASM будет становиться более полезным как для бэкенд-, так и для фронтенд-приложений.
Введение
Обычно я осваиваю новые технологии в области разработки, проходя этапы, аналогичные стадиям цикла зрелости технологии, определенным исследователями Gartner. Данный цикл демонстрирует типичный путь каждой новой технологии — от запуска к принятию. В этой статье я расскажу, как при использовании технологии WASM перешел от скепсиса к восторгу, особенно впечатлившись повышением производительности бэкенд-систем.
WASM — это низкоуровневый формат инструкций. Он разработан как целевая платформа компиляции для таких языков, как C, C++ и Rust. Основное его назначение — обеспечение высокопроизводительными веб-приложениями. При этом он все чаще используется на стороне сервера, когда производительность имеет решающее значение.
В моем исследовании WASM были взлеты и падения. Оно началось с завышенных ожиданий, сменившихся разочарованием, но закончилось прочным пониманием и практическим применением.
Первоначальные заблуждения
Едва ознакомившись с WASM, я возлагал на него большие надежды. Мне казалось, что WASM позволит плавно интегрировать сложные вычисления в веб-браузеры подобно тому, как FFI позволяет высокоуровневым языкам выполнять машинный код.
Что такое FFI?
FFI — это механизм, с помощью которого код, написанный на одном языке, напрямую вызывает код, написанный на другом языке. FFI используется, когда производительность имеет решающее значение и определенная логика реализована на низкоуровневом языке, таком как C или Rust. Затем этот низкоуровневый код вызывается из языков более высокого уровня, таких как Python или JavaScript.
Я думал, что WASM, подобно FFI, просто запускает код машинного уровня в браузере. Это имело смысл, поскольку WASM компилирует высокоуровневые языки в низкоуровневый двоичный формат. Но я упустил из виду уникальную архитектуру и ограничения WASM.
Сравнение WASM с FFI
Рассматривая WASM как FFI, я упустил то, что отличает WASM от традиционного машинного кода. В FFI часто возникают большие накладные расходы при переключении между основным языком и внешней функцией. Перемещение данных между различными схемами памяти также требует больших затрат.
Проверка реальных возможностей WASM
По мере изучения WASM я начал замечать разрыв между своими первоначальными ожиданиями и результатами его реального применения.
Первые шаги с WASM и Rust
Я начал экспериментировать с WASM, используя wasm-bindgen — инструмент, который помогает модулям WASM и JavaScript работать вместе. Мой первый опыт был прост:
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub fn add(a: u32, b: u32) -> u32 {
a + b
}
При использовании wasm-pack с LTO (link-time optimization — оптимизацией времени соединения) базовая соединяющая функция add скомпилировалась в крошечный 214-байтный WASM-модуль. Изначально это казалось подтверждением того, что WASM может обеспечить компактный и эффективный код.
Ознакомление с WAT-форматом
Чтобы лучше понять, как работает такой маленький фрагмент кода, я обратился к версии WAT (WebAssembly Text Format — текстовой формат WebAssembly). WAT — это читаемая версия двоичных форматов WASM. Она необходима для отладки и оптимизации WASM-приложений. Вот WAT для функции add:
(module
(type (;0;) (func (param i32 i32) (result i32)))
(func (;0;) (type 0) (param i32 i32) (result i32)
local.get 0
local.get 1
i32.add)
(memory (;0;) 17)
(export "memory" (memory 0))
(export "add" (func 0)))
Такой лаконичный формат показывает эффективность WASM для решения простых вычислительных задач — никаких лишних накладных расходов, только основные операции для выполнения функции.
Влияние дополнительной сложности на размер WASM-модуля
Затем я усложнил эксперимент, добавив строковые операции, чтобы посмотреть, как это повлияет на размер модуля:
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub fn add(a: u32, b: u32) -> u32 {
let a = a.to_string().parse::<u32>().unwrap();
let b = b.to_string().parse::<u32>().unwrap();
return a + b;
}
Несмотря на те же вычисления, эта версия создала гораздо больший модуль WASM размером 14,5 КБ. Файл WAT вырос до более чем 7 126 строк, что отражает дополнительную сложность и накладные расходы, связанные с обработкой строк.

Конструктор WebAssembly.Instance может синхронно компилировать только модули размером менее 4 КБ. Модули большего размера должны компилироваться асинхронно. Но мне показалось невозможным сохранить WASM-файлы, чтобы они не превышали такого лимита.
Разочарование
Основной проблемой стало резкое увеличение размера модуля WASM при добавлении таких функций, как манипуляции со строками. Увеличение размера файла противоречило представлению о WASM как о легком и эффективном формате.
Оптимизация размера модуля WASM
Чтобы решить эти проблемы, я изучил способы оптимизации размера модуля WASM. Вот несколько стратегий, позволяющих минимизировать занимаемый WASM-приложениями объем.
- Избегание паник. Обработка паники (panic) в Rust приводит к дополнительным накладным расходам. Использование типов Option и Result эффективно справляется с ошибками и позволяет избежать раздувания паники.
- Ограничение использования строк. Динамические операции со строками значительно увеличивают размер модуля WASM. Использование целочисленных типов или типов данных фиксированного размера позволяет сохранить компактность модулей.
- Оптимизация времени соединения (LTO). Включение LTO в компиляторе Rust уменьшает размер скомпилированного WASM за счет удаления неиспользуемого кода и оптимизации по границам ячеек.
- Ручная встряска дерева. В то время как автоматическая встряска дерева в конвейере Rust → WASM ограничена, ручное включение только необходимых функций и зависимостей уменьшает раздутость.
Несмотря на все эти усилия, порой возникали непреодолимые трудности, особенно при работе со сложными типами данных и операциями, характерными для задач программирования более высокого уровня.
Динамические языки в WASM
Трудности с WASM характерны не только для Rust. Другие языки, особенно динамические, такие как Python, сталкиваются с еще большими проблемами. Чтобы понять причины этого, рассмотрим компиляцию динамического языка в WASM.
- Компиляция интерпретатора: для Python необходимо скомпилировать в WASM не только пользовательский код, но весь интерпретатор — все встроенные функции и библиотеки, которые поддерживает язык.
- Выполнение кода: выполнение кода Python, скомпилированного в WASM, означает запуск интерпретатора внутри интерпретатора, что создает значительные накладные расходы и может привести к появлению больших двоичных файлов WASM.
Даже для Go, статически типизированного компилируемого языка, минимальный размер WASM-файла составляет 2 МБ, согласно Go Programming Language Wiki.
Проблемы, общие для всего комьюнити
В своем разочаровании я не был одинок. Его разделяло все сообщество разработчиков. Во многих статьях обсуждались похожие проблемы.
- Анализ причин неудачи Zaplib: подробное описание того, как стартап Zaplib пришел к решению отказаться от WASM из-за отсутствия повышения производительности и сложности разработки.
- Встряска дерева — ошибочный алгоритм с точки зрения программиста: статья о несовершенстве встряски дерева в инструментарии WASM — важнейшего процесса уменьшения конечного размера бинарного файла за счет удаления неиспользуемого кода.
Опыт сообщества, подчеркивающий трудности использования WASM в его текущем состоянии, многих разработчиков “отрезвил” от первоначального воодушевления.
Переломный момент
Стараясь преодолеть разочарование в WASM, я обнаружил библиотеку h3, разработанную компанией Uber. Это и стало переломным моментом в моем отношении к WASM. Библиотека h3, включающая реализации на нескольких языках (C, Python, Java, JavaScript) и h3-js, использует Emscripten для соединения JavaScript и WASM, скомпилированного из C.
Что такое h3?
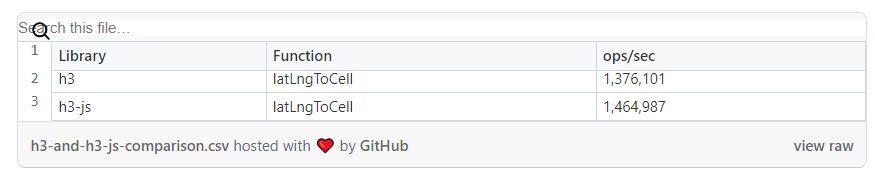
Библиотека h3 предназначена для геопространственного индексирования. Она позволяет индексировать координаты в гексагональной сетке. Эта система особенно полезна для приложений с большими наборами геопространственных данных. Одна из часто используемых мной функций — latLngToCell — преобразует координаты широты и долготы в идентификатор ячейки гексагональной сетки.
Сравнение производительности h3 и h3-js
Чтобы оценить производительность h3-js, я сравнил реализацию на C с выполнением JavaScript-версии с помощью WASM. К счастью, в их репозиториях уже есть программы для бенчмаркинга. Вот результаты, полученные на моем локальном M2 MacBookPro:
Изучение возможностей WASM
Воодушевленный неожиданными результатами h3-js, я решил продолжить изучение возможностей WASM. Я начал сравнивать его производительность с JavaScript и FFI с помощью вычислительной задачи — гипотезы Коллатца.
Что такое гипотеза Коллатца?
Гипотеза Коллатца (также известная как “проблема 3n + 1”) — это математическая гипотеза о последовательности, определяемой следующим образом.
- Начните с любого положительного целого числа n.
- Если n четное, разделите его на 2.
- Если n нечетное, умножьте его на 3 и добавьте 1.
- Повторяйте этот процесс до тех пор, пока n не станет равным 1.
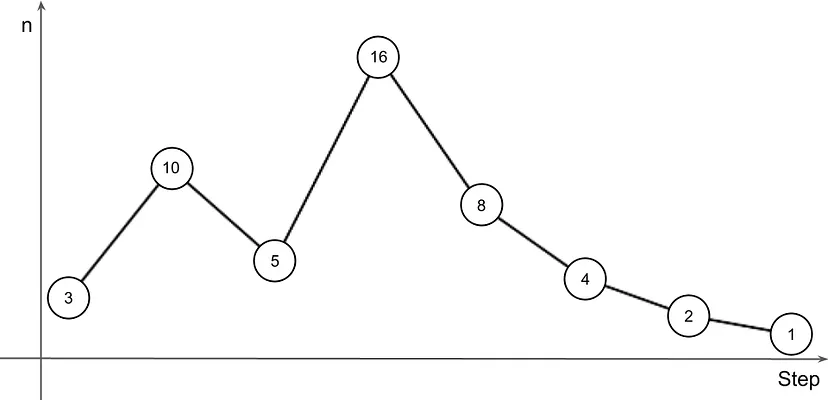
Эта гипотеза утверждает, что независимо от начального значения n, последовательность всегда в конечном итоге достигнет 1.
Гипотеза Коллатца в отношении JS, FFI и WASM
Для сравнения производительности я реализовал гипотезу на обычном JavaScript, используя FFI для вызова функции Rust, и непосредственно в WASM. В качестве входных данных передал n = 670617279, что требует 986 шагов для достижения 1.
- JavaScript:
function collatzSteps(n) {
let counter = 0;
while (n !== 1) {
if (n % 2 === 0) {
n /= 2;
} else {
n = 3 * n + 1;
}
counter++;
}
return counter;
}
- Rust (FFI) и Rust (WASM):
pub fn collatz_steps(mut n: u64) -> u64 {
let mut counter = 0;
while n != 1 {
if n % 2 == 0 {
n /= 2;
} else {
n = 3 * n + 1;
}
counter += 1;
}
return counter;
}
Для получения более подробной информации, можете заглянуть в репозиторий. Вот бенчмарки с M2 MacBookPro:
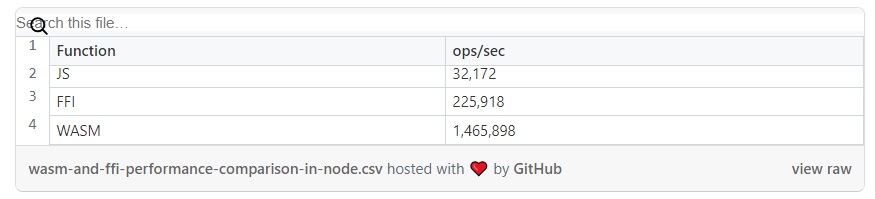
Эти результаты показали, что WASM может превзойти как нативный JavaScript, так и FFI, особенно в задачах с интенсивными вычислениями.
Дальнейшее исследование производительности WASM
Впечатляющие результаты работы WASM в h3-js и в гипотезе Коллатца ясно показали, что потенциал WASM гораздо больше, чем я предполагал вначале.
Чем WASM отличается от FFI
Ключ к пониманию эффективности WASM лежит в его конструкции как низкоуровневого формата двоичных инструкций. Он не только не зависит от платформы, но и оптимизирован для скорости выполнения и компактности в отличие от FFI, где большие накладные расходы могут возникать из-за маршалинга данных между контекстами выполнения и работы с различными моделями памяти. Эта установка минимизирует типичные накладные расходы FFI, обеспечивая:
- линейное и унифицированное управление памятью: WASM использует один непрерывный блок памяти, что упрощает интерфейс с хост-средой, снижая затраты, связанные с управлением памятью в традиционных установках FFI;
- двоичный формат, оптимизированный для выполнения: двоичный формат WASM разработан для эффективного декодирования и выполнения современными компиляторами JIT (Just-In-Time), что позволяет достичь производительности, близкой к скорости нативного машинного кода, без типичных штрафов, связанных с интерпретацией во время выполнения.
Применение WASM в бэкенде
Результаты использования библиотеки h3-js и эксперименты с гипотезой Коллатца изменили мое представление о ландшафте WASM-приложений.
- Потенциал бэкенда превосходит возможности фронтенда. Хотя изначально WASM превозносили как потенциал для веб-приложений, его сильные стороны особенно ярко проявляются в бэкенде и других небраузерных средах с общими интенсивными вычислительными процессами, такими как обработка данных, научные вычисления и кодирование/декодирование мультимедиа в реальном времени.
- Пограничные вычисления. WASM идеально подходит для приложений периферийных вычислений, где выполнение кода ближе к источнику данных может значительно улучшить время отклика и сократить использование полосы пропускания.
Оптимизация генерации ULID с помощью WASM
Одним из практических случаев применения производительности WASM стала генерация ULID (universally unique lexicographically sortable identifiers — универсальные уникальные лексикографически сортируемые идентификаторы). Идентификаторы ULID служат для тех же целей, что и UUID (universally unique identifier — универсальные уникальные идентификаторы), но ULID являются сортируемыми идентификаторами. Они состоят из временной метки и компонента случайности, закодированных для обеспечения уникальности и лексической сортируемости. Это делает их особенно полезными для распределенных систем, где порядок сортировки и уникальность имеют решающее значение.
40-кратное увеличение производительности
Переведя существующую реализацию генерации ULID на JavaScript в Rust, скомпилированный в WASM, я добился значительного увеличения производительности — примерно в 40 раз по сравнению с исходной JavaScript-версией.
Этот первоначальный перевод был простым, но за ним последовал более тонкий подход к дальнейшей оптимизации производительности.
Последующая оптимизация
Изначально производительность была выше примерно в 10 раз. Однако благодаря нескольким оптимизациям в реализации Rust я увеличил этот показатель до 40. Вот ключевые приемы, которые способствовали такому значительному росту производительности, хотя они не являются специфическими для WASM.
1. Использование эффективных структур данных
Оптимизация используемых в реализации структур данных, например векторов с заранее выделенной емкостью вместо динамического изменения их размера, позволила свести к минимуму выделение памяти и не снижать производительность за счет частых операций с памятью.
// До String::new(); // После String::with_capacity(len);
2. Избегание ненужных преобразований и выделений памяти
Первоначальная реализация Rust включала ненужные преобразования строк и символов, которые требовали больших вычислительных затрат. Оптимизация работы с данными и сокращение выделения памяти позволили значительно повысить производительность. Например, использование байтовых массивов напрямую вместо преобразования их в строки или символы при любой возможности помогло снизить накладные расходы.
// До
const ENCODING: &str = "0123456789ABCDEFGHJKMNPQRSTVWXYZ";
...
let mut chars = Vec::with_capacity(len);
for index in 0..len {
chars.push(ENCODING.chars().nth(index).unwrap());
}
// После
const ENCODING: &str = "0123456789ABCDEFGHJKMNPQRSTVWXYZ";
const ENCODING_BYTES: &[u8] = ENCODING.as_bytes();
...
let mut chars = Vec::with_capacity(len);
for index in 0..len {
chars.push(ENCODING_BYTES[index] as char);
}
3. Предварительные вычисления и их кэширование
Предварительное вычисление значений, которые будут использоваться многократно при различных вызовах функций, таких как значения длины кодировки, и их кэширование значительно снижали вычислительную нагрузку. Это было особенно эффективно для таких функций, как decode_time, где операции повторяются и предсказуемы.
// До
const ENCODING_LEN: usize = 32;
const TIME_LEN: usize = 10;
...
for i in 0..TIME_LEN {
time += i as f64 * (ENCODING_LEN as u64).pow(index as u32) as f64;
}
// После
const ENCODING_LEN: usize = 32;
const POWERS: [f64; 10] = [1.0, 32.0, ..., 35184372088832.0];
...
for i in 0..TIME_LEN {
time += i as f64 * POWERS[index];
}
Заключение
Оптимизация генерации ULID с помощью WASM демонстрирует, как понимание реальных возможностей WASM приводит к существенному повышению производительности в практических приложениях. Это лишь один из примеров того, что WASM не только может быть успешно использован в бэкенд-системах, где производительность и эффективность имеют решающее значение, но и открывает широкие перспективы для веб-приложений по мере развития инструментальных цепочек.
В настоящее время проблема больших размеров двоичных файлов несколько ограничивает использование WASM во фронтенд-приложениях, где скорость загрузки и выполнения чрезвычайно важна. Однако это не постоянное ограничение, а скорее текущее препятствие. По мере совершенствования инструментальных цепочек WASM в таких техниках, как встряска деревьев и оптимизация двоичного вывода, можно ожидать, что размеры двоичных файлов значительно сократятся.
Будущее WASM для веб-систем выглядит многообещающе. С развитием инструментальных цепочек, способных создавать более компактные и эффективные двоичные файлы, возрастет потенциал WASM для революционного изменения производительности и возможностей веб-приложений. Это не только повысит эффективность бэкенд-систем, но и может радикально изменить способ развертывания и запуска сложных приложений в браузере, сделав их такими же эффективными и мощными, как и их нативные аналоги.
Читайте также:
- WebAssembly с Go: вывод веб-приложений на новый уровень
- Новые API браузера, необходимые каждому веб-разработчику
- WebAssembly: секретное оружие в разработке высокооптимизированных и безопасных веб-приложений
Читайте нас в Telegram, VK и Дзен
Перевод статьи Yuji Isobe: I was understanding WASM all wrong!





