
Не секрет, что успех больших языковых моделей (LLM) во многом зависит от нашей способности подсказывать им надлежащие инструкции и примеры. По мере того, как новое поколение LLM набирает все большую мощь, промпты становятся достаточно сложными, чтобы считаться программами. Эти программы-промпты во многом похожи на рецепты — и те, и другие содержат набор инструкций, следование которым позволяет преобразовать исходные материалы, будь то данные или ингредиенты.
Промпт-инжиниринг подобен совершенствованию рецепта. Домашние повара часто придерживаются общих рецептов, но вносят в них небольшие изменения — например, готовя пасту, добавляют вместо чеснока петрушку. Такие фреймворки, как DSPy, следуют общей парадигме, когда оптимизируют контекстуальные примеры. Однако шеф-повара профессионального уровня используют рецепт как источник вдохновения и часто полностью переосмысливают компоненты блюда. Например, они могут заменить такой крахмальный компонент пасты, как спагетти, свежеприготовленными клецками, сохранив прежний состав блюда.
Что позволяет профессиональным шеф-поварам работать так креативно? Дело в том, что они умеют абстрагироваться от общепринятых рецептов, беря их за основу, как в приведенном выше примере с пастой. Ручной промпт-инжиниринг подобен профессиональной кулинарии. Он может дать впечатляющие результаты, но требует много времени и знаний. Нам же нужна креативность промпт-инжиниринга, но без лишних усилий.
Сила абстрактных промптов
Допустим, нам надо оптимизировать промпт для маркировки ответов диктора. Впоследствии придется работать с разными исходными данными, но пока подключим конкретный промпт:
Instructions: Does Speaker 2's answer mean yes or no? Output labels: no, yes Input: Speaker 1: "You do this often?" Speaker 2: "It's my first time." Output:
Инструкции: означает ли ответ спикера 2 «да» или «нет»?
Выходные метки: нет, да
Вводные данные: Спикер 1: «Вы часто это делаете?». Спикер 2: «Это мой первый раз».
Вывод:
Предположим, что у нас есть абстрактное представление этого промпта, которое извлекает его отдельные компоненты и которым легко манипулировать. Что-то вроде этого:
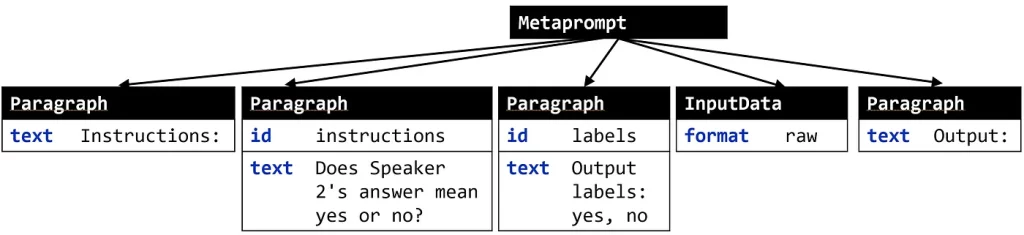
С его помощью вы сможете автоматизировать многие (полу)ручные действия, которые приходится выполнять во время быстрого создания прототипа. Небольшие правки, такие как перефразирование, — это только начало. Хотите выполнить рассуждения по цепочке логических выводов? Добавьте абзац “Let’s think step-by-step” (“Рассуждай шаг за шагом”). Как насчет изменения формата данных на JSON? Просто измените атрибут format в параметрах InputData. Можете также попробовать такие операции, как:
- переход от единичных примеров к пакетному аннотированию;
- изменение ретривера и функции ранжирования в сценарии RAG;
- изменение порядка следования абзацев;
- сжатие определенных частей инструкций и т. д.
В общем, подключите свою любимую эвристику для промпт-инжиниринга. Такое абстрактное представление промптов позволяет по-настоящему креативно подойти к делу и автоматически исследовать большое пространство возможных промптов. Но как представить промпты в виде абстрактных и модифицируемых программ на Python? Читайте далее.
Превращение промптов в абстрактные программы
“Любую проблему в информатике можно решить с помощью еще одного уровня абстракции” (Дэвид Дж. Уилер).
Чтобы представить промпты абстрактно, преобразуем их сначала в программу промптов не в символьной записи, разбив на отдельные компоненты, реализованные в виде классов Python:
class Component:
def __init__(self, **kwargs): pass
class Metaprompt(Component): pass
class Paragraph(Component): pass
class InputData(Component): pass
prompt = Metaprompt(
children=[
Paragraph(text="Instructions: "),
Paragraph(
id="instructions",
text="Does Speaker 2's answer mean yes or no?",
),
Paragraph(id="labels", text="Output labels: yes, no"),
InputData(),
Paragraph(text="Output: "),
]
)
Это похоже на то, что делает DSPy, хотя и в более общих чертах, поскольку у нас представлена и внутренняя структура промптов.
Теперь превратим эту запись в программу промптов в символьной записи, чтобы можно было вносить в нее произвольные изменения (что также выходит за рамки статических программ DSPy). Это можно сделать с помощью pyGlove — библиотеки для символьного объектно-ориентированного программирования (SOOP). pyGlove превращает классы Python в манипулируемые символьные объекты, свойства которых остаются полностью редактируемыми после инстанцирования.
При использовании pyGlove все, что нам нужно сделать, — добавить декоратор pg.symbolize:
import pyglove as pg
@pg.symbolize
class Component:
def __init__(self, **kwargs): pass
Теперь можно запрашивать и изменять программы промптов с помощью целого ряда спецификаторов, подобно работе с DOM-деревом. Допустим, требуется преобразовать программу, приведенную выше, в следующую:
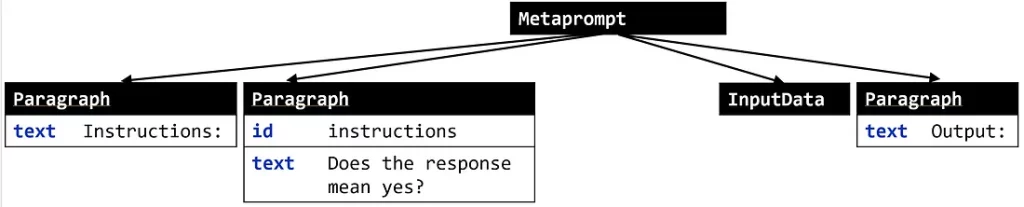
Обратите внимание: теперь мы спрашиваем “Does the response mean yes?” (Означает ли ответ „да“?), а не предоставляем выходные метки “yes” (да) и “no” (нет). Чтобы добиться этого, нам нужно: 1) изменить текст инструкции; 2) удалить третий узел. С помощью pyGlove это сделать очень просто:
prompt.rebind({'children[1].text': 'Does the response mean yes?'})
prompt.rebind({'children[2]': pg.MISSING_VALUE})
print(prompt)
Вывод подтверждает, что мы добились успеха:
Metaprompt(
children = [
0 : Paragraph(
text = 'Instructions: '
),
1 : Paragraph(
id = 'instructions',
text = 'Does the response mean yes?'
),
2 : InputData(),
3 : Paragraph(
text = 'Output: '
)
]
)
pyGlove дает возможность работать с классами (и функциями) Python так, как будто они все еще являются исходным кодом, без особых накладных расходов. Теперь, имея гибкие представления, которыми легко манипулировать, применим их на практике.
У нас уже есть способ представлять и изменять промпты, но все еще нет процесса их автоматической оптимизации.
Профессиональный повар, выяснив компоненты рецепта и абстрагируясь от него, перепробует множество вариантов. Он будет оптимизировать вкус, стоимость или способ подачи блюда, пока не добьется оптимального результата. Чтобы сделать то же самое с абстракциями, понадобится поисковой алгоритм, цель поиска, а также набор помеченных образцов, позволяющий определить успешность результатов.
Думаете, придется реализовывать это самостоятельно? Нам поможет SAMMO (structure-aware multi-objective metaprompt optimization — многоцелевая оптимизация метапромптов со структурной поддержкой) — Python-библиотека для создания и оптимизации программ промптов в символьной записи.
Тренировка: настройка инструкций с помощью SAMMO
Для ознакомления с основным процессом работы SAMMO, настроим инструкции в приведенном выше примере с промптом. После разбора этого простого примера, рассмотрим более сложные случаи применения, такие как RAG-оптимизация или сжатие.
Шаг 1. Определение начального промпта
Мы уже практически сделали это выше. SAMMO ожидает функцию, поэтому придется обернуть промпт в функцию. Если хотите сохранить дополнительную информацию, оберните ее в Callable. Для запуска проведем обертку также в компонент Output.
def starting_prompt():
instructions = MetaPrompt(
Paragraph(text="Instructions: "),
Paragraph(
id="instructions",
text="Does Speaker 2's answer mean yes or no?",
),
Paragraph(id="labels", text="Output labels: yes, no"),
InputData(),
Paragraph(text="Output: "),
)
return Output(instructions.with_extractor())
Шаг 2. Подготовка данных
SAMMO использует простую структуру данных под названием DataTable для сопряжения входов и выходов (меток). Она позволяет регистрировать и оценивать результаты.
mydata = DataTable.from_records(
records, # список {"input": <>, "output": <>}
constants={"instructions": default_instructions},
)
Шаг 3. Определение цели
Поскольку мы заинтересованы в оптимизации точности, именно это и реализуем ниже:
def accuracy(y_true: DataTable, y_pred: DataTable) -> EvaluationScore:
y_true = y_true.outputs.normalized_values()
y_pred = y_pred.outputs.normalized_values()
n_correct = sum([y_p == y_t for y_p, y_t in zip(y_pred, y_true)])
return EvaluationScore(n_correct / len(y_true))
Шаг 4. Выбор набора мутаторов
Здесь вам предоставляется возможность проявить максимум креативности. Можете реализовать собственные операторы, генерирующие новые варианты промптов, или положиться на готовые операторы мутации, предлагаемые SAMMO.
Выберем, как показано ниже, последний вариант, воспользовавшись сочетанием перефразирования и вывода инструкций из нескольких примеров с метками, реализовав APE (Automatic Prompt Engineering — автоматический промпт-инжиниринг).
mutation_operators = BagOfMutators(
starting_prompt=StartingPrompt(d_train),
InduceInstructions({"id": "instructions"}, d_train),
Paraphrase({"id": "instructions"}),
)
Шаг 5. Запуск оптимизации
runner = OpenAIChat(
model_id="gpt-3.5-turbo-16k",
api_config={"api_key": YOUR_KEY},
cache="cache.tsv",
)
prompt_optimizer = BeamSearch(runner, mutation_operators, accuracy, depth=6)
transformed = prompt_optimizer.fit_transform(d_train)
Вводный пример промпта, взятый из задачи BigBench implicatures, будем использовать для проведения эксперимента. Если запустить оптимизацию со 100 образцами для обучения и тестирования и бюджетом для оценки 48 кандидатов, то увидим, что SAMMO повышает точность начального промпта с 0,56 до 0,77, позволяя добиться оптимизации на 37,5%. Какие инструкции сработали лучше всего?
...
Paragraph(
"Consider the dialogue, context, and background "
"information provided to determine the most suitable output label",
id="instructions",
)
...
Интересно, что разным LLM подходят совершенно разные инструкции. Модель GPT-3.5 предпочла общие инструкции, как показано выше. Llama-2 для вывода лучшего промпта, выбранного SAMMO, при тех же настройках обучения и бюджета использовала пустую строку в части инструкций:
...
Paragraph(
"",
id="instructions",
)
...
Практика: настройка RAG
Теперь посмотрим, как преобразовать RAG-пайплайн в программу в символьной записи и настроить ее с помощью SAMMO. В качестве прикладной задачи будем использовать семантический парсинг, который позволяет преобразовывать пользовательские запросы в конструкции DSL (domain-specific language — предметно-ориентированный язык), например, для запроса к какой-либо базе данных или вызова внешнего API.
Чтобы создать стартовый промпт, включаем список всех операторов, используем ретривер на основе эмбеддинга, чтобы получить пять few-shot-примеров, а затем инструктируем LLM выводить ответ в том же формате, что и примеры.
class RagStartingPrompt:
def __init__(self, dtrain, examples, embedding_runner):
self._examples = examples
self._dtrain = dtrain
self._embedding_runner = embedding_runner
def __call__(self, return_raw=False):
structure = [
Section("Syntax", self._dtrain.constants["list_of_operators"]),
Section(
"Examples",
EmbeddingFewshotExamples(
self._embedding_runner, self._examples, 5
),
),
Section(
"Complete and output in the same format as above",
InputData(),
),
]
instructions = MetaPrompt(
structure,
render_as="markdown",
data_formatter=JSONDataFormatter(),
)
return Output(
instructions.with_extractor(),
on_error="empty_result",
)
Теперь, имея программу в символьной записи, проявим креативный подход. Для проведения мутаций исследуем:
- различное количество few-shot-примеров;
- различные форматы (XML, JSON, построчный) для few-shot-примеров;
- предоставление или непредоставление дополнительной информации о DSL;
- отображение пар вход-выход или групп входов и выходов.
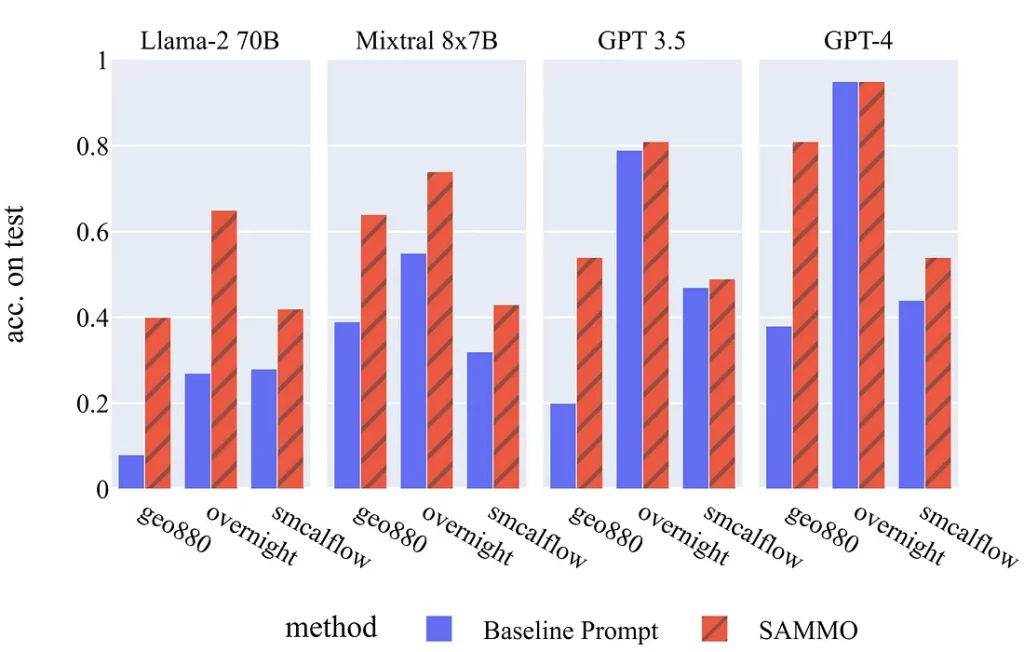
Запустив SAMMO с этими примерами и общим бюджетом для оценки 24 кандидатов, видим четкую тенденцию. Ниже приведены оценки точности по тестовым наборам для четырех разных LLM (речь идет о трех различных датасетах). В подавляющем большинстве случаев видим, что SAMMO может существенно поднять производительность даже самых высокомощных LLM.
Выводы
Преобразование промптов в программы в символьной записи — мощная технология, позволяющая исследовать большое пространство возможных промптов и настроек. Как профессиональный повар анализирует и переосмысливает рецепты для создания кулинарных новинок, так и символьное программирование позволяет применить тот же уровень креативности и экспериментаторства в автоматическом промпт-инжиниринге.
SAMMO реализует поиск по программам в символьной записи с помощью набора операторов мутации и поисковой программы. В эмпирическом плане это может привести к значительному повышению точности как при настройке инструкций, так и при настройке RAG, независимо от бэкенда LLM.
Расширяйте возможности SAMMO с помощью пользовательских операторов мутации, чтобы использовать предпочтительные для вас методы промпт-инжиниринга или реализовать цели, выходящие за рамки точности (например, стоимость). Счастливого приготовления промптов!
Читайте также:
- Решение крупномасштабных задач машинного обучения на Python
- Mito: быстрый анализ данных на Python
- Как создать на Python скринер акций и выполнить анализ настроений на основе ИИ
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tobias Schnabel: Supercharging Prompt Engineering via Symbolic Program Search





