
Прежде всего, отметим, что структура данных Map, о которой многие знают, но редко или вообще не используют, не так уж и незначительна, как кажется. В этой статье остановимся на некоторых фундаментальных темах и выясним, для чего нужна структура данных Map и когда она может быть полезна.
Что такое нотация Big O?
Понимание нотации Big O имеет решающее значение для анализа эффективности и масштабируемости алгоритмов и структур данных. Она позволяет разработчикам оценить, как будут работать алгоритмы при увеличении размера входных данных. Эта нотация обеспечивает стандартизированный способ выражения наихудшего сценария времени выполнения алгоритма в зависимости от размера входных данных. Разработчикам важно выбирать алгоритмы и структуры данных с благоприятными временными сложностями, чтобы обеспечить эффективную работу, особенно при работе с большими массивами данных.
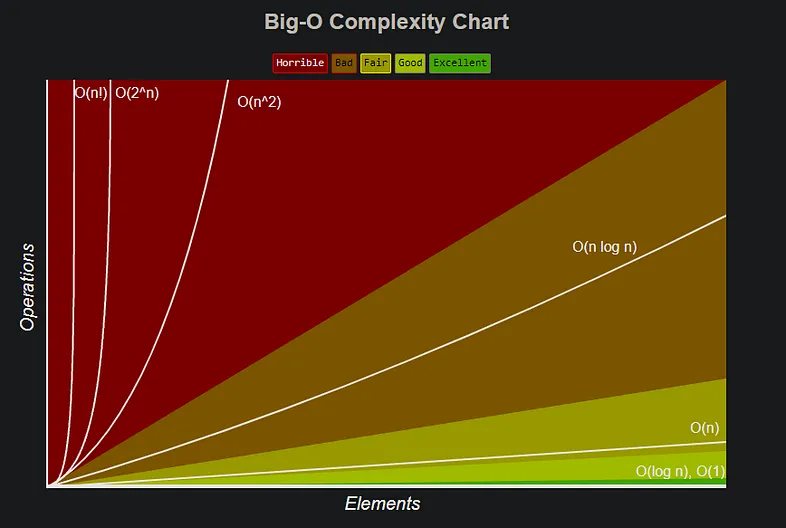
При анализе этих данных становится очевидным: лучше всего, чтобы используемые методы не зависели от размера ’n’ данных. Хотя по отдельности эти операции могут быть достаточно быстрыми, чтобы остаться незамеченными, сочетание нескольких операций одновременно или вложенные циклы подчас значительно ухудшают пользовательский опыт.
Как работает метод find()?
Как известно, метод find() в JavaScript выполняет линейный поиск в массиве. Он возвращает первый элемент, удовлетворяющий заданному условию, и перебирает все данные, пока не найдет этот элемент. Поэтому, рассматривая наихудший сценарий, когда искомый элемент является последним элементом массива, мы говорим, что его временная сложность составляет O(n). В книге Адитьи Бхаргавы “Grokking Algorithms” эта ситуация показана следующим образом:
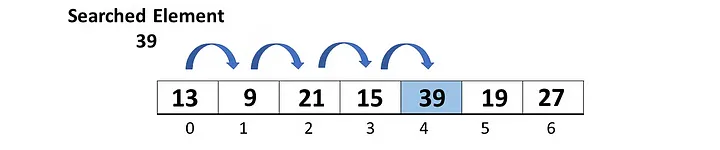
Представьте, что вы новый клиент на рынке, пытающийся определить цены на покупаемые товары из имеющегося у вас списка товаров. Вы повторяете этот процесс для каждого товара от начала до конца. Не очень похоже на повседневную практику, не так ли? А теперь представьте, что у вас есть более опытный коллега, который знает наизусть цены на все товары. Звучит здорово, правда? На самом деле ваш опытный коллега, который знает все и возвращает все цены с временной сложностью O(1), то есть с постоянным временем, не зависящим от количества товаров, — это HashMap. Итак, рассмотрим HashMap подробней.
Что такое HashMap?
HashMap — структура данных в виде хэш-таблицы. Это хранилище, которое может сопоставлять ключи с соответствующими им значениями. Когда вы предоставляете ему ключ, он возвращает значение, связанное с этим ключом, и вы можете выполнять операции вставки и удаления, используя одно и то же значение ключа в хэш-таблице. Таким образом, это очень быстрая система хранения данных, требующая сложности O(1) по времени для всех операций.
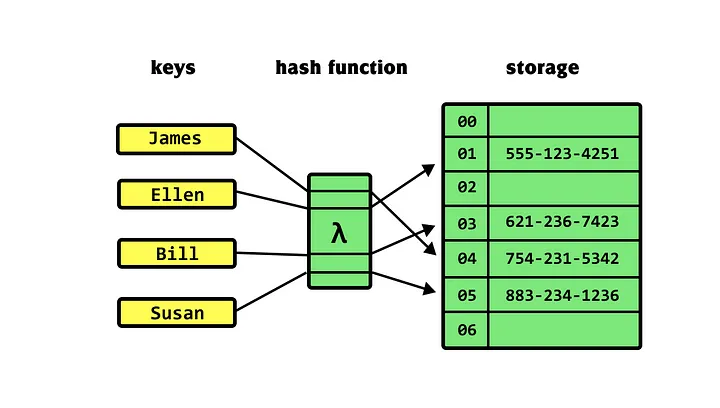
Однако есть некоторые моменты, о которых следует знать: например, ключи, распределенные с помощью неэффективной хэш-функции, могут “столкнуться” (получить одно и то же хэш-значение), что затруднит поиск. Также к снижению производительности может привести наличие хэш-таблицы со скоростью заполнения более 70%.
Когда и почему стоит использовать Map, а не массив?
В пользовательских интерактивных компонентах обычно применяют метод find(), реже filter. Это происходит в ситуациях, когда необходимости получить данные на основе параметров в динамических маршрутах, манипулировать определенным фрагментом данных либо получить данные, выбранные из выпадающего списка или введенные в поле ввода. Все эти операции работают линейно и имеют временную сложность O(n). Посмотрим, как легко выполнить все эти задачи с помощью Map.
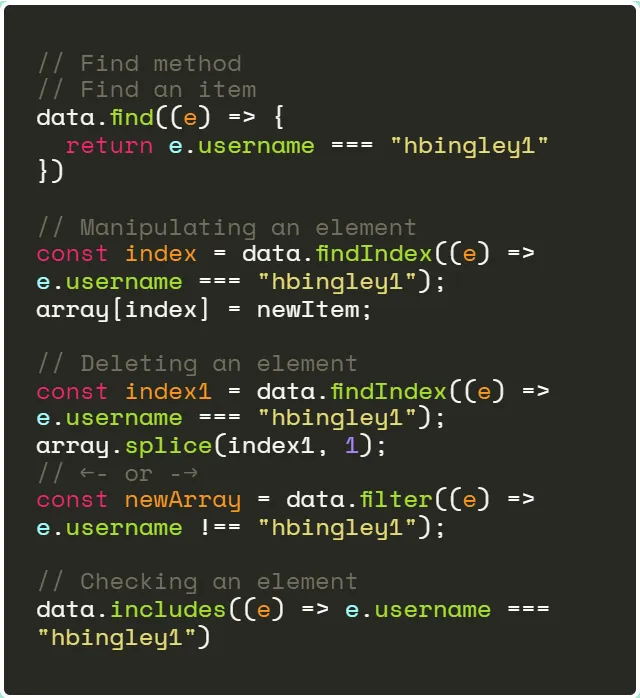
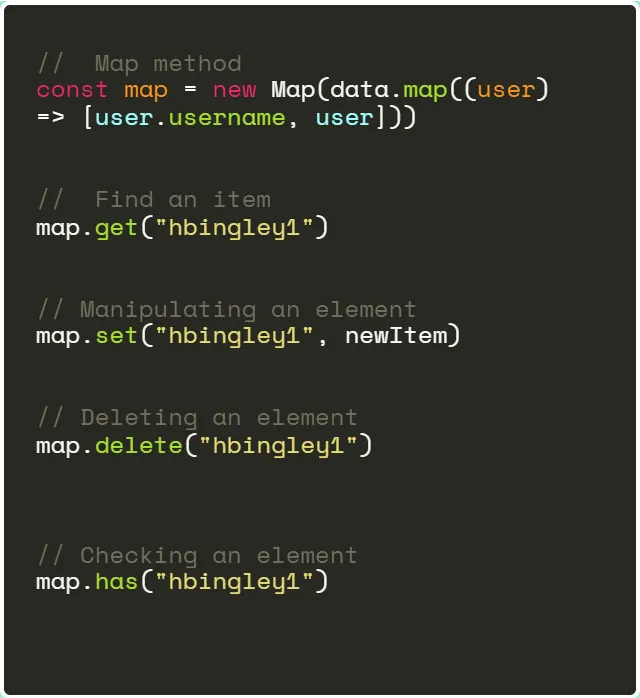
Что такое Map?
Map в JavaScript представляет собой структуру данных для сопоставления ключей со значениями. В отличие от массивов, которые индексируются по диапазону чисел, Map может использовать любое значение в качестве ключа. Такая гибкость позволяет использовать Map в различных сценариях, особенно часто при работе со сложными структурами данных или когда требуется быстрый доступ к данным.
let hashData = null;
const getUsers = async () => {
try {
const response = await fetch("https://dummyjson.com/users");
const data = await response.json();
hashData = new Map(data.users.map((user) => [user.username, user]));
// имя пользователя уникально
} catch (error) {
console.error("Hata:", error);
}
};
Чтобы преобразовать данные в Map с помощью этого метода и обеспечить уникальность ключей, нужно один раз выполнить итерацию по данным. Единственный момент, на который следует обратить внимание, — это то, что ключи должны быть уникальными. Тогда получим следующий результат:
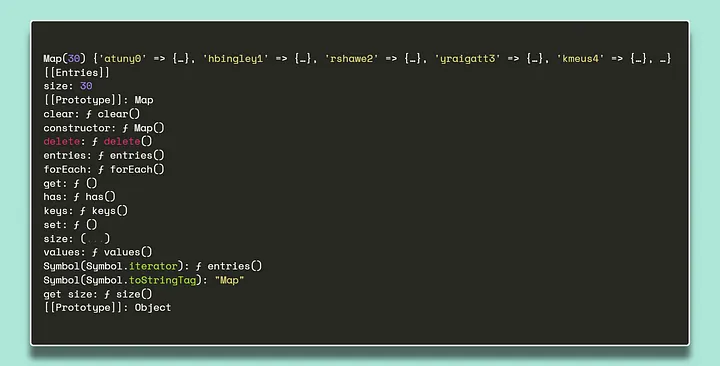
Таким образом, вместо использования find, можно получить доступ к значению, связанному с ключом в структуре данных Map, с помощью get с временной сложностью O(1), вне зависимости от размера данных. Более того, используя метод has, можно проверить существование этих данных с временной сложностью O(1) вместо использования includes с временной сложностью O(n). Ключи чувствительны к регистру, что обеспечивает нам удобство операции.
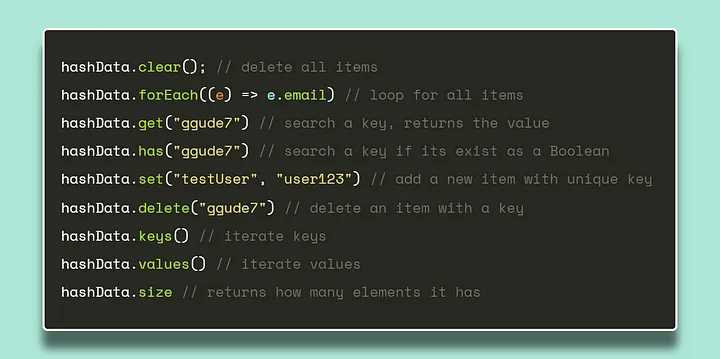
Методы структуры данных Map
Читайте также:
- Движок JavaScript, JIT-компилятор, стек, куча, память, примитивы, ссылки и сборка мусора
- Паттерн “Шаблонный метод” и его реализация в JavaScript
- Как преобразовать шестнадцатеричное число в десятичное в JavaScript
Читайте нас в Telegram, VK и Дзен
Перевод статьи Enes Talay: Stop Using Find Method in JavaScript




