
Говорят, нет ничего невозможного, но я могу делать это “ничего” каждый день (Винни-Пух).
Начиная с 30 ноября 2022 года, мы выполняем все меньше работы (почти ничего не делаем) каждый день.
Я инженер-программист, и мне нравится, что GitHub Copilot дополняет мои мысли даже быстрее, чем я думаю. Я консультируюсь с GPT о том, как решать проблемы, и создается такое впечатление, будто главный архитектор программного обеспечения находится рядом со мной в этот момент и делает обзор кода. К тому же с помощью GPT можно получать помощь по HLD и техническим вопросам. Теперь же мы хотим использовать большие языковые модели (Large Language Model) в реальном мире. Это уже не просто демо-версии, надписи типа “hello world” на экране или волшебные картинки, созданные искусственным интеллектом.
Мы также хотим воздействовать на наших клиентов с помощью LLM и интегрировать искусственный интеллект на основе данных пользователя для придания им ценности.
Так можем ли мы это сделать? Мы отвечаем на этот вопрос утвердительно.
Тест-драйв в реальном мире
В нашем случае мы хотели использовать LLM для отправки длинных действий пользователей с контентом (тысячи событий), сделанных во время браузерной сессии, и получения сводки этих действий, включая аспекты безопасности.
Аудиторы часто сталкиваются с проблемами при ручном просмотре таких сессий браузера. Им бывает сложно определить, какие сессии являются подозрительными и требуют повышенного внимания, особенно если у них нет технических знаний. Кроме того, некоторые сессии могут быть довольно длинными, что затрудняет их обзор. К сожалению, такая неэффективность может привести к потере времени и повышению рисков безопасности.
Только представьте, как было бы здорово, если бы искусственный интеллект мог просматривать длинные сессии, обобщать их и даже отмечать подозрительное поведение, которое он обнаружит.
В этой статье мы отправимся в путешествие и поделимся с вами информацией, полученной в ходе нашего исследования. Мы сосредоточимся на следующих аспектах:
- промпт-инжиниринг;
- эффективная работа с большими объемами данных;
- оптимизация количества токенов для экономии средств и сокращения задержек.
Для начала обсудим, как выбрать правильную модель для конкретных нужд.
Выбор правильной модели LLM
Формулировка задачи часто имеет большее значение, чем ее решение (Альберт Эйнштейн).
Как найти модель LLM, которая наилучшим образом соответствует вашим потребностям?
Хотя этот вопрос — тема для отдельной статьи, можете взглянуть на пост Алекса Абрамова, который поможет вам решить, какая модель лучше для вас (спойлер: нет никакой “лучшей модели”; выбирайте ту, которая подходит вам по всем параметрам: безопасность, конфиденциальность, простота, цена, ограничения по скорости, длина контента, время обработки и многое другое).
Для наших нужд лучше всего подошла Claude 2.1 (Anthropic), предоставленная Amazon Bedrock.
Итак, вы выбрали Claude, GPT или BARD в качестве большой языковой модели. Давайте убедимся, что модель эффективно взаимодействует с вами. В следующем разделе приведены полезные советы по промпт-инжинирингу, следуя которым вы получите именно те результаты, которые вам нужны. Итак, приступим!
Промпт-инжиниринг за 1000 токенов или меньше
Может, я и не пошел туда, куда собирался, но, думаю, я оказался там, где должен был оказаться (Дуглас Адамс).
Чтобы получить конечный результат, потребовалось время, и промпт-инжиниринг стал ключом к пониманию того, чего мы хотим и как этого добиться.
Многие авторы гайдов рассказывают, что лучше всего подходит для промпт-инжиниринга, но здесь мы обобщим некоторые советы, которые использовали:
- Промпт на основе роли. Иногда, задавая вопрос, полезно представить себя кем-то другим, чтобы получить ответ с определенной точки зрения. Это называется ролевой игрой. Поучаствуйте в ролевой игре с ИИ.
- Задайте формат вывода. Укажите точный формат вывода.
Например: “Ответь в формате JSON со следующей JSON-схемой”.
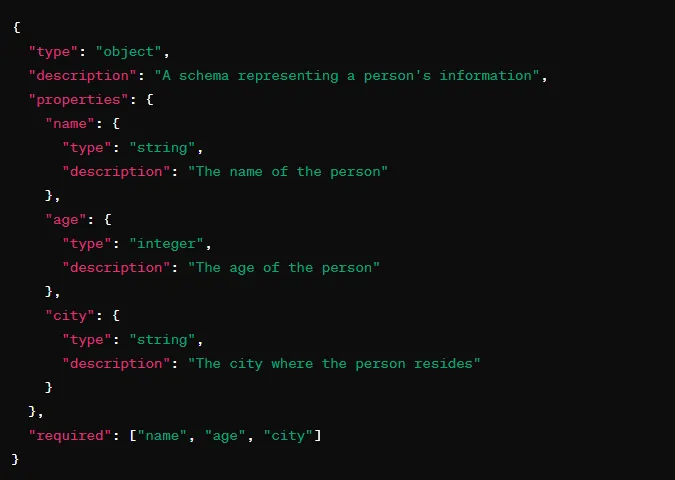
Но этого недостаточно!
На наш запрос о предоставлении сводки в указанном выше формате был получен следующий забавный ответ: “Конечно, я предоставлю вам сводку в формате JSON”. Затем был прикреплен JSON. Но это не то, о чем я просила. Ни до, ни после JSON не должно быть текста.
Чтобы справиться с этой проблемой, попробуйте воспользоваться советом “Вложить слова в уста Клода”, написав начало ответа Клода. Например, добавьте символ “{Json)” в начало ответа помощника, чтобы указать, что ответ должен начинаться только в формате JSON.
- Few-shot-промптинг. Добавьте примеры к заданному промпту, чтобы смоделировать вывод. ИИ лучше поймет ваши ожидания, и результат будет более точным.
- Человекоподобное взаимодействие. Взаимодействуя с ИИ, обращайтесь с ним как с человеком. Разбивайте сложные задачи на более мелкие и понятные части. Так ИИ будет лучше понимать инструкции. Проверить, насколько понятны эти инструкции, можно, показав их другу и спросив у него, сможет ли он их выполнить.
- Ограничение контента. Четко определите границы контента. Например, никогда не раскрывайте в своей сводке значения паролей или секретных данных, а только упоминайте об их использовании. Если нужно показать предложение, в котором они содержатся, завуалируйте его.
Помните, что главное — это эксперименты и постоянное совершенствование. Пробуйте, пока не найдете идеальный промпт для своих нужд.
Итак, наши промпты идеально подогнаны под наши потребности, а это значит, что мы готовы к решению следующей задачи: обработке большого количества данных.
Большие данные и проблемы квот
Вы можете откладывать дела, но время ждать не будет (Бенджамин Франклин).
На пути к интеграции LLM в реальный мир мы столкнулись с интересными проблемами при работе с большим объемом данных. ИИ, каким бы мощным он ни был, может выдавать неточный ответ, когда имеет дело с огромными массивами информации.
Чтобы преодолеть это препятствие, мы разбили данные на более мелкие и управляемые фрагменты (чанки). Такой подход не только повысил точность, но и положительно сказался на общей производительности.
Вы можете сделать это двумя способами.
Сбор и обобщение
Первый способ предполагает разделение данных на фрагменты, самостоятельную обработку каждого сегмента и последующее соединение их вместе для получения полного ответа. Это похоже на головоломку: каждый кусочек укладывается в общую картину.
Преимуществом этого метода является возможность одновременного выполнения нескольких запросов.
Кусок за куском (чанк за чанком)
Второй метод немного динамичнее. В этом случае мы отправляем данные по частям, но есть один нюанс. В каждый кусок мы также включаем результаты предыдущего куска, в результате чего получается связная и полная сюжетная линия.
Но есть еще ограничения и квоты. Поговорим о цифрах. Вот скриншот, на котором показаны данные по квотам от Amazon:
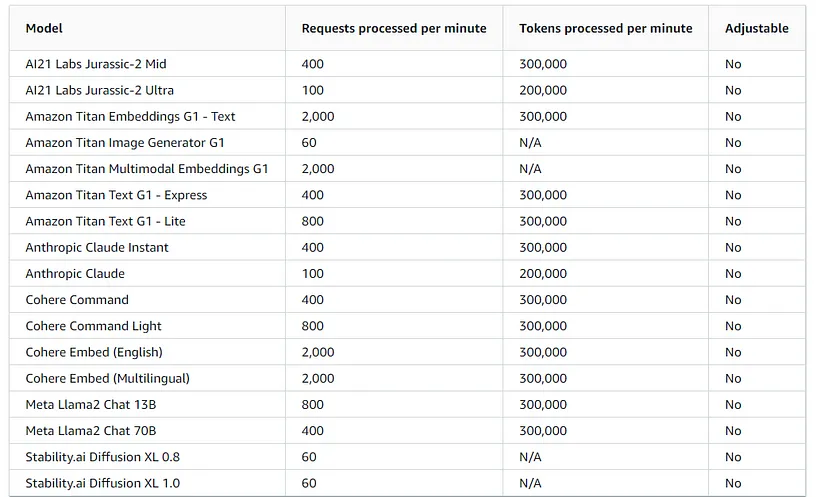
Эти показатели очень важны в контексте нашей статьи. Дело не только в скорости, но и в общей производительности, которая согласуется с конкретными требованиями.
Будьте осторожны! Применяя подход “Сбор и обобщение” при одновременном выполнении нескольких запросов (и вообще при одновременном выполнении нескольких запросов), помните о том, что не следует превышать указанные ограничения. Чтобы обеспечить сбалансированную производительность, учитывайте пороговые значения одновременной работы и применяйте стратегические задержки для достижения оптимальных результатов.
Есть ли способ преодолеть это препятствие? Есть ли другие методы, кроме использования стратегической задержки?
Мы понимаем, что задержка прямо пропорциональна количеству входных и выходных токенов, а значит, решение проблемы заключается в оптимизации токенов. Именно это нам и нужно!
Оптимизация токенов LLM для повышения эффективности в плане цены, задержек и пропускной способности
Бесплатных обедов не бывает (Милтон Фридман).
Почему нужно минимизировать токены? Они не предоставляются бесплатно. Их использование влияет на стоимость, пропускную способность и задержку.
Для каждой модели установлена своя цена. Например, использование модели Claude 2.1 будет стоить 0,008 доллара за 1000 входных токенов. Вроде бы не так много, но представьте, чего стоит работа с большими объемами данных. Одна сессия может стоить около 1 доллара, а для функции, используемой многими клиентами и сессиями, это очень дорого!
Кроме того, есть еще и задержка по максимальному количеству обработки токенов в минуту, которая прямо пропорциональна количеству входных и выходных токенов. Для Claude максимальное количество токенов, обрабатываемых в минуту, составляет 200K. Таким образом, оптимизация токенов становится неотъемлемой частью процесса разработки.
В начале мы сгенерировали сессию с 30К токенов, но по мере продвижения вперед смогли сгенерировать ту же сессию, используя всего ~8К токенов.
Расскажем о некоторых приемах по минимизации токенов.
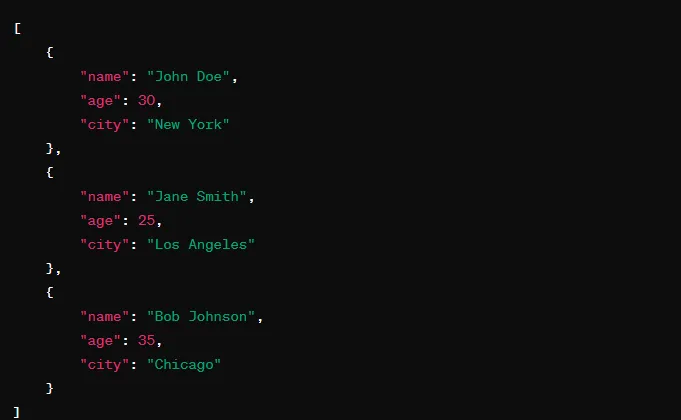
1. Формат CSV/Minified JSON. Часто этот способ может дать более 50% экономии. Если позволяют данные, намного лучше будет использовать формат CSV/YAML. Если же нет, то хотя бы минифицируйте входные/выходные данные в формате JSON. Еще один бонус: сокращение времени обработки на 50%!
Приведем несколько примеров:


2. Оптимизация форматов. Оптимизация использования токенов выходит за рамки форматов. Возьмем, к примеру, даты. Преобразовав такой “человеческий” формат, как “Четверг, 1 февраля 2024 года, 11:34:53” (Thursday, February 1, 2024, 11:34:53 AM)(17 токенов) в так называемое время эпохи — epoch time (‘1706787293000’ — 5 токенов), мы провернули трюк, позволяющий сэкономить токены. Этот прием можно применить к любому формату. Вы можете использовать научную нотацию вместо числового представления, когда речь идет о больших числах, и многое другое.
3. “Обрезка” URL. Еще одним примером минимизации токенов является “обрезка” URL. URL-адреса, часто перегруженные токенами, можно сократить. Рассмотрим этот URL с 59 токенами:

Но параметры запроса в URL не представляют интереса. Однако, разделив их, можно добиться того же результата, используя всего 8 токенов.
4. Избирательность в отношении полей. Создавая входные данные, будьте избирательны в выборе полей. Не все поля могут быть важны для понимания со стороны модели или генерирования значимого ответа. Исключите ненужные поля, чтобы уменьшить количество токенов. Например, при обработке данных о пользователях, исключение важных деталей, таких как второе имя и дополнительный адрес, может заметно изменить ситуацию.
Теперь модель соответствует нашим потребностям и точно реагирует на вводимые данные. Мы также успешно оптимизировали расходы, задержку и использование токенов и почти готовы развернуть ее для применения на практике.
Будущее LLM в реальных сценариях
Где-то что-то невероятное ждет, чтобы о нем узнали (Карл Саган).
За последний год искусственный интеллект изменил правила игры и то, как мы думаем, разрабатываем и выполняем задачи. Надеюсь, эта статья подарила вам несколько классных идей по оказанию реального влияния на LLM и использования ее на практике. Думаю, вам стоит самим попробовать и испытать на своем опыте все трудности и волнение от работы с моделью. Хотя мы не можем говорить о конкретных перспективах, открытия и инновации в мире ИИ убеждают нас в том, что исследования в этой сфере продолжаются, благодаря чему мы скоро узнаем что-то новое.
Читайте также:
- Как работает искусственный интеллект
- Повышение эффективности промпт-инжиниринга путем поиска по программам в символьной записи
- Прогнозирование настроений на фондовом рынке с помощью OpenAI и Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tamar Yankelevich: LLM in a Real-Feature World





