
Чат-боты изменили то, как мы взаимодействуем с цифровыми платформами. Несмотря на впечатляющие возможности базовых языковых моделей в решении сложных задач, пользовательский опыт часто остается неудовлетворительным — ощущается безличность и отстраненность.
Чтобы сделать общение более непосредственным, я задумал создать чат-бота, способного имитировать непринужденный стиль моей дружеской переписки в WhatsApp.
В этой статье расскажу о процессе создания небольшой языковой модели, которая генерирует синтетические разговоры, используя мои сообщения в чате WhatsApp в качестве входных данных. Попутно попытаюсь раскрыть внутреннюю работу архитектуры GPT в наглядной и, надеюсь, понятной форме, дополнив ее фактической реализацией на Python. Полную версию проекта можно найти на GitHub.
Примечание: класс модели в значительной степени взят из серии видео Андрея Карпати и адаптирован под мои потребности.
1. Выбор подхода
Когда речь идет об адаптации языковой модели к конкретному корпусу данных, можно использовать несколько подходов:
- Создание модели. Создание и обучение модели с нуля, включая обеспечение максимальной гибкости в плане архитектуры модели и выбора обучающих данных.
- Тонкая настройка. Использование готовой предварительно обученной модели с корректированием ее весов для более точного соответствия конкретным данным.
- Промпт-инжиниринг. Использование готовой предварительно обученной модели с включением уникального корпуса данных непосредственно в промпты, без изменения весов модели.
Поскольку основная цель этого проекта — самообразование и мне интересна архитектура современных языковых моделей, я выбрал первый подход. Правда, у него были очевидные ограничения. Учитывая объем используемых данных и доступные вычислительные ресурсы, не стоило ожидать результатов на уровне самых современных предварительно обученных моделей.
Тем не менее я надеялся, что модель сможет усвоить некоторые интересные лингвистические закономерности, что в итоге и произошло.
2. Источник данных
WhatsApp, мой основной канал общения, оказался идеальным источником для передачи моего разговорного стиля. Я просто экспортировал более чем шестилетнюю историю групповых чатов, общий объем которых превышал 1,5 миллиона слов.
Данные были спарсированы с помощью шаблона regex в список кортежей, содержащих даты отправки, имена контактов и сообщения чата.
pattern = r'\[(.*?)\] (.*?): (.*)'
matches = re.findall(pattern, text)
text = [(x1, x2.lower()) for x0, x1, x2 in matches]
[
(2018-03-12 16:03:59, "Alice", "Hi, how are you guys?"),
(2018-03-12 16:05:36, "Tom", "I am good thanks!"),
...
]
Теперь каждый элемент обрабатывался отдельно.
- Дата отправки. Я не использовал эту информацию, кроме как для преобразования в объект datetime. Однако можно посмотреть на дельты времени, чтобы отличить начало и конец обсуждения темы.
- Имя контакта. При токенизации текста каждое имя контакта рассматривается как уникальный токен. Таким образом, комбинация имени и фамилии будет считаться единым целым.
- Сообщение чата. В конце каждого сообщения добавляется специальный токен “<END>”.
3. Токенизация
Чтобы обучить языковую модель, нужно разбить язык на части (так называемые токены) и постепенно подавать их в модель. Токенизация может быть выполнена на нескольких уровнях.
- Уровень символов. Текст воспринимается как последовательность отдельных символов (включая пробелы). Такой гранулированный подход позволяет сформировать из последовательности символов все возможные слова. Однако при этом сложнее уловить семантические связи между словами.
- Уровень слов. Текст представляется как последовательность слов. Однако словарный запас модели ограничен существующими словами в обучающих данных.
- Уровень подслов. Текст разбивается на подслова, которые меньше, чем слова, но больше, чем символы.
Начав с токенизатора на уровне символов, я понял, что трачу время впустую. Модель обучалась на последовательности символов повторяющихся слов вместо того, чтобы сосредоточиться на семантических отношениях между словами в предложении.
Ради концептуальной простоты, решил перейти на токенизатор на уровне слов, игнорируя доступные библиотеки для более сложных стратегий токенизации.
from nltk.tokenize import RegexpTokenizer
def custom_tokenizer(txt: str, spec_tokens: List[str], pattern: str="|\d|\\w+|[^\\s]") -> List[str]:
"""
Tokenize text into words or characters using NLTK's RegexpTokenizer, considerung
given special combinations as single tokens.
:param txt: The corpus as a single string element.
:param spec_tokens: A list of special tokens (e.g. ending, out-of-vocab).
:param pattern: By default the corpus is tokenized on a word level (split by spaces).
Numbers are considered single tokens.
>> note: The pattern for character level tokenization is '|.'
"""
pattern = "|".join(spec_tokens) + pattern
tokenizer = RegexpTokenizer(pattern)
tokens = tokenizer.tokenize(txt)
return tokens
["Alice:", "Hi", "how", "are", "you", "guys", "?", "<END>", "Tom:", ... ]
Оказалось, что словарный запас моих обучающих данных составляет примерно 70 000 уникальных слов. Однако, поскольку многие слова встречаются только один или два раза, я решил заменить такие редкие слова специальным токеном “<UNK>”. В результате словарный запас сократился примерно до 25 000 слов, что привело к уменьшению модели, которую нужно будет обучать позже.
from collections import Counter
def get_infrequent_tokens(tokens: Union[List[str], str], min_count: int) -> List[str]:
"""
Identify tokens that appear less than a minimum count.
:param tokens: When it is the raw text in a string, frequencies are counted on character level.
When it is the tokenized corpus as list, frequencies are counted on token level.
:min_count: Threshold of occurence to flag a token.
:return: List of tokens that appear infrequently.
"""
counts = Counter(tokens)
infreq_tokens = set([k for k,v in counts.items() if v<=min_count])
return infreq_tokens
def mask_tokens(tokens: List[str], mask: Set[str]) -> List[str]:
"""
Iterate through all tokens. Any token that is part of the set, is replaced by the unknown token.
:param tokens: The tokenized corpus.
:param mask: Set of tokens that shall be masked in the corpus.
:return: List of tokenized corpus after the masking operation.
"""
return [t.replace(t, unknown_token) if t in mask else t for t in tokens]
infreq_tokens = get_infrequent_tokens(tokens, min_count=2)
tokens = mask_tokens(tokens, infreq_tokens)
["Alice:", "Hi", "how", "are", "you", "<UNK>", "?", "<END>", "Tom:", ... ]
4. Индексирование
Следующий шаг после токенизации — преобразование слов и специальных токенов в числовые представления. При использовании фиксированного списка словаря каждое слово было проиндексировано по его позиции. Затем закодированные слова были подготовлены в виде тензоров PyTorch.
import torch
def encode(s: list, vocab: list) -> torch.tensor:
"""
Encode a list of tokens into a tensor of integers, given a fixed vocabulary.
When a token is not found in the vocabulary, the special unknown token is assigned.
When the training set did not use that special token, a random token is assigned.
"""
rand_token = random.randint(0, len(vocab))
map = {s:i for i,s in enumerate(vocab)}
enc = [map.get(c, map.get(unknown_token, rand_token)) for c in s]
enc = torch.tensor(enc, dtype=torch.long)
return enc
torch.tensor([8127, 115, 2363, 3, ..., 14028])
Для оценки качества модели на невидимых данных тензор был разделен на две части. Теперь обучающий (train.pt) и проверочный (valid.pt) наборы готовы к подаче в языковую модель.

5. Архитектура модели
Я решил применить архитектуру GPT, которая была популяризирована в статье “Все, что вам нужно, — это внимание” (“Attention is All you Need”). Поскольку я создавал генератор языка, а не бота, отвечающего на вопросы, мне было достаточно архитектуры только декодера (в правой части).
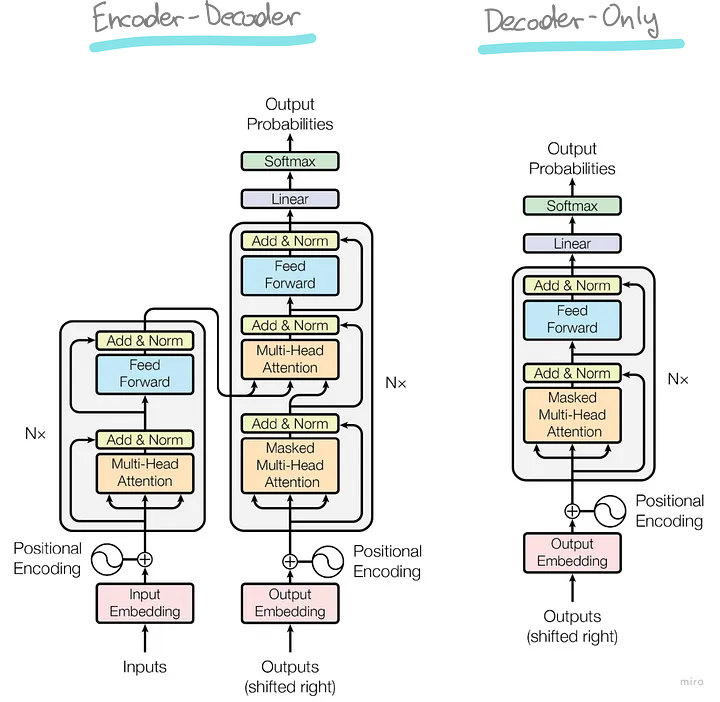
В следующих разделах разберем каждый компонент архитектуры GPT, определив его роль и базовые матричные операции. Начиная с подготовленного обучающего теста, будем пропускать через модель примерный контекст из 3 слов, пока не добьемся предсказания следующего токена.
5.1. Назначение модели
Прежде чем углубляться в технические особенности модели, важно понять ее основное назначение. При использовании только архитектуры декодера цель заключается в декодировании структуры языка для точного предсказания следующего токена в последовательности, учитывая контекст предыдущих токенов.
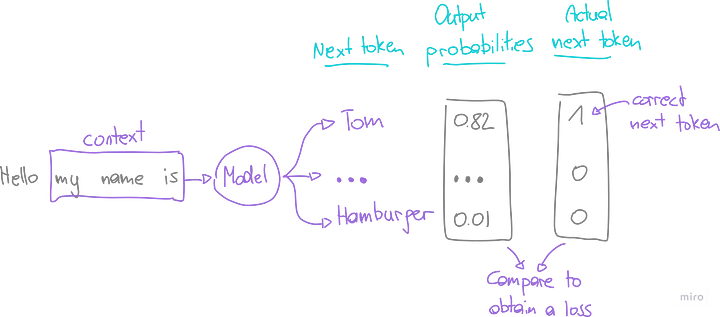
При подаче последовательности индексированных токенов, модель проходит через серию матричных умножений с различными весовыми матрицами. На выходе получается вектор, представляющий вероятность того, что каждый токен является следующим в последовательности при учете входного контекста.
Оценка модели
Эффективность модели оценивается по обучающим данным, где известен фактический следующий токен. Задача состоит в том, чтобы максимизировать вероятность правильного предсказания следующего токена.
Однако в машинном обучении мы часто фокусируемся на понятии “потери”, которое количественно выражает ошибку или вероятность неправильного прогноза. Чтобы рассчитать этот показатель, вероятности выхода модели надо сравнить с фактическим следующим токеном (используя кросс-энтропию).
Оптимизация
Имея представление о текущих потерях, мы стремимся минимизировать их с помощью алгоритма обратного распространения. Этот процесс включает в себя итеративное введение последовательностей токенов в модель и корректировку весовых матриц для повышения производительности.
На каждом изображении желтым цветом выделены весовые матрицы, которые будут оптимизированы в ходе этой процедуры.
5.2. Эмбеддинг на выходе
До сих пор каждый токен в последовательности был представлен целочисленным индексом. Однако такая упрощенная форма не отражает связи и сходства слов. Для решения этой задачи надо перевести одномерные индексы в высокоразмерные пространства с помощью эмбеддинга (встраивания, или представления данных в виде векторов).
- Эмбеддинги слов (word-embeddings). Отражают суть слова n-мерным вектором плавающих значений.
- Позиционные эмбеддинги (positional-embeddings). Подчеркивают важность позиции слова в предложении, также представленной в виде n-мерного вектора плавающих значений.
Для каждого токена находим его словесный и позиционный эмбеддинг, а затем суммируем их по элементам. В результате получаем эмбеддинг на выходе (output embedding) каждого токена в контексте.
В приведенном ниже примере контекст состоит из 3 токенов. В конце процесса эмбеддинга каждый токен представлен n-мерным вектором (где n — размер эмбеддинга, настраиваемый гиперпараметр).
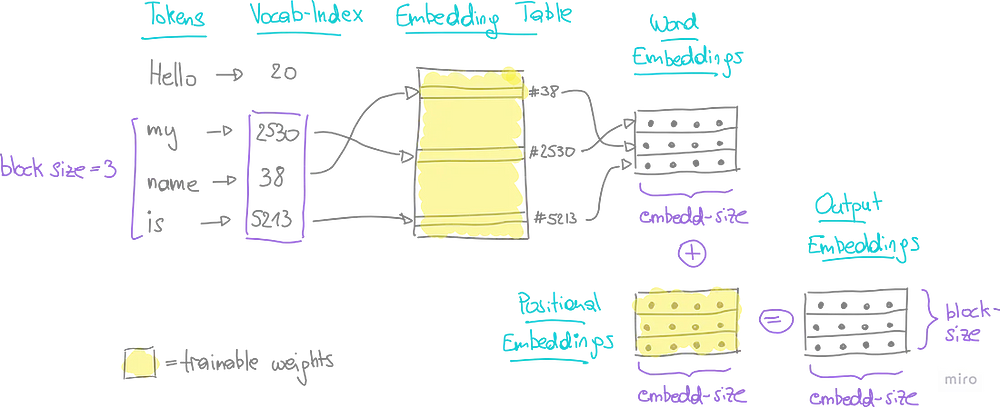
PyTorch предлагает специальные классы для таких эмбеддингов. В рамках класса нашей модели определяем словесные и позиционные эмбеддинги следующим образом (передавая размеры матрицы в качестве аргументов):
self.word_embedding = nn.Embedding(vocab_size, embed_size)
self.pos_embedding = nn.Embedding(block_size, embed_size)
5.3. Механизм самовнимания
Хотя словесные эмбеддинги дают общее представление о сходстве слов, истинное значение слова часто зависит от контекста. Например, английское слово “bat” может означать как животное (летучая мышь), так и спортивный инвентарь (бита) в зависимости от предложения. Именно здесь в игру вступает механизм самовнимания (self-attention head) — ключевой компонент архитектуры GPT.
Механизм самовнимания ориентируется на три основные понятия: Запрос (Query), Ключ (Key) и Значение (Value).
- Запрос (Q). Представление текущего токена, для которого необходимо рассчитать внимание. Запрос сродни вопросу: “На что я, как текущий токен, должен обратить внимание в остальном контексте?”.
- Ключ (K). Представление каждого токена во входной последовательности. Ключ сопоставляется с запросом для определения показателя внимания. Ключ показывает, насколько сильно токен запроса должен фокусироваться на других токенах в контексте. Высокий показатель означает, что следует уделить больше внимания.
- Значение (V). Это также представление каждого токена во входной последовательности, однако роль значения заключается в применении окончательных весов к показателю внимания.
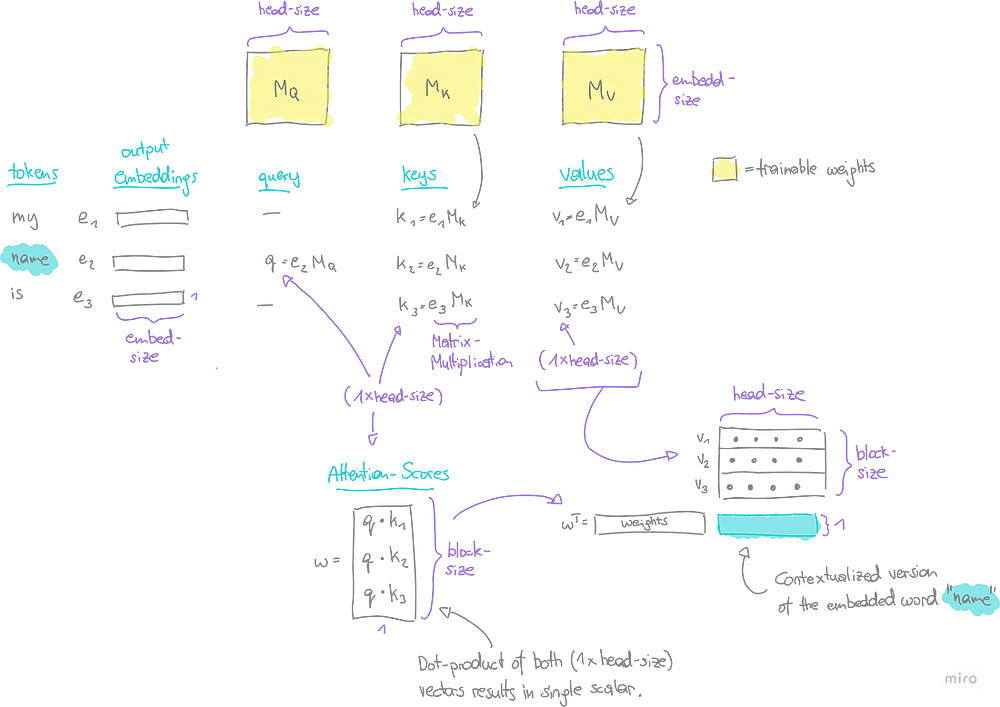
Пример
В нашем примере все токены контекста уже представлены в форме эмбеддинга в виде n-мерных векторов (e1, e2, e3). Механизм самовнимания принимает их в качестве входных данных, чтобы выдать контекстуализированную версию для каждого из них, по одной за раз.
- При оценке токена “name” (“имя”) вектор запроса q получается путем умножения его встроенного вектора v2 на обучаемую матрицу M_Q.
- В то же время для каждого токена в контексте вычисляются векторы ключей (k1, k2, k3) путем умножения каждого встроенного вектора (e1, e2, e3) на обучаемую матрицу M_K.
- Векторы значений (v1, v2, v3) получаются аналогичным образом, только умножаются на другую обучаемую матрицу M_V.
- Показатель внимания w вычисляется как скалярное произведение вектора запроса и каждого вектора ключа в отдельности.
- Наконец, все векторы значений складываем в матрицу и умножаем на показатель внимания, чтобы получить контекстуализированный вектор для токена “name”.
class Head(nn.Module):
"""
This module performs self-attention operations on the input tensor, producing
an output tensor with the same time-steps but different channels.
:param head_size: The size of the head in the multi-head attention mechanism.
"""
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(embed_size, head_size, bias=False)
self.query = nn.Linear(embed_size, head_size, bias=False)
self.value = nn.Linear(embed_size, head_size, bias=False)
def forward(self, x):
"""
# input of size (batch, time-step, channels)
# output of size (batch, time-step, head size)
"""
B,T,C = x.shape
k = self.key(x)
q = self.query(x)
# вычисление показателя внимания
wei = q @ k.transpose(-2,-1)
wei /= math.sqrt(k.shape[-1])
# избегайте опережения
tril = torch.tril(torch.ones(T, T))
wei = wei.masked_fill(tril == 0, float("-inf"))
wei = F.softmax(wei, dim=-1)
# взвешенная агрегация значений
v = self.value(x)
out = wei @ v
return out
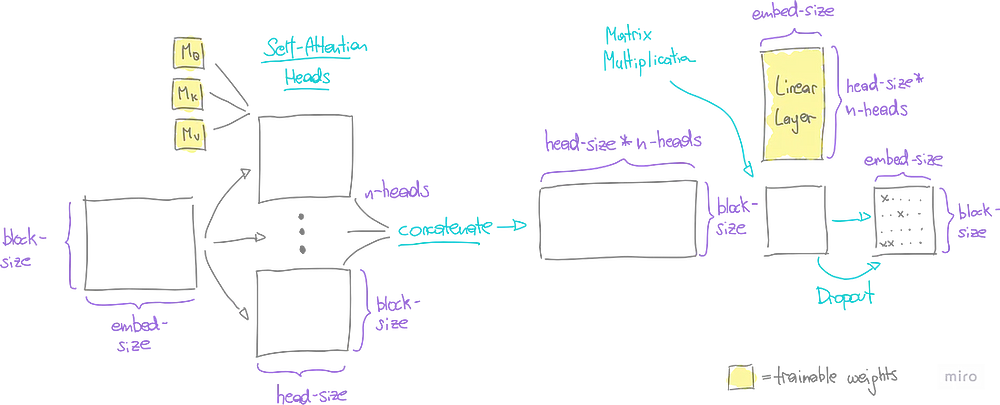
5.4. Маскированное многоголовое внимание
Язык сложен, и уяснить все его нюансы не так-то просто. Одного набора расчетов внимания часто бывает недостаточно, чтобы уловить все тонкости сочетания слов. Вот тут-то и пригодится идея многоголового внимания (multi-head attention) в модели GPT.
Представьте, что несколько пар глаз смотрят на данные по-разному, замечая уникальные детали. Затем эти отдельные наблюдения складываются в одну общую картину. Чтобы сохранить контроль над этой картиной и сделать ее совместимой с остальной частью модели, будем использовать линейный слой/обучаемые веса (linear layer/trainable weights), чтобы сжать ее до исходного эмбеддинг-размера.
Наконец, для проверки того, что модель не просто запоминает обучающие данные, но и успешно справляется с прогнозированием нового текста, будем использовать выпадающий слой (dropout layer). Он случайным образом отключает часть данных во время обучения, что помогает модели стать более адаптируемой.
class MultiHeadAttention(nn.Module):
"""
This class contains multiple `Head` objects, which perform self-attention
operations in parallel.
"""
def __init__(self):
super().__init__()
head_size = embed_size // n_heads
heads_list = [Head(head_size) for _ in range(n_heads)]
self.heads = nn.ModuleList(heads_list)
self.linear = nn.Linear(n_heads * head_size, embed_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
heads_list = [h(x) for h in self.heads]
out = torch.cat(heads_list, dim=-1)
out = self.linear(out)
out = self.dropout(out)
return out
5.5. Нейронная сеть прямого распространения
Слой многоголового внимания первоначально фиксирует контекстуальные отношения в последовательности. Глубина сети увеличивается за счет двух последовательных линейных слоев, которые в совокупности образуют нейронную сеть прямого распространения.
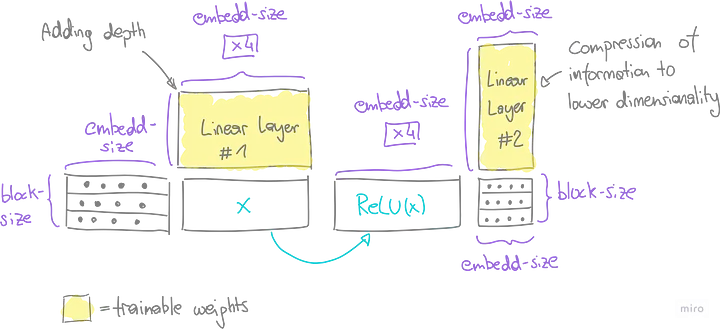
В начальном линейном слое увеличиваем размерность (в нашем случае в 4 раза), что расширяет возможности сети в плане обучения и демонстрации более сложных признаков. К каждому элементу полученной матрицы применяется функция ReLU, что позволяет распознавать нелинейные шаблоны.
Затем второй линейный слой действует как компрессор, уменьшая расширенные размеры до исходной формы — размер блока умножается на эмбеддинг-размер (block-size x embedding-size). Завершает процесс выпадающий слой, случайным образом отключающий элементы матрицы с целью обобщения модели.
class FeedFoward(nn.Module):
"""
This module passes the input tensor through a series of linear transformations
and non-linear activations.
"""
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(embed_size, 4 * embed_size),
nn.ReLU(),
nn.Linear(4 * embed_size, embed_size),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
5.6. Элементы Add и Norm
Теперь связываем воедино многоголовое внимание и нейронную сеть прямого распространения, вводя еще два важнейших элемента:
- Add — остаточные соединения (Residual Connections). Эти соединения выполняют поэлементное добавление выхода слоя к его неизмененному входу. В процессе обучения модель регулирует акцент на преобразованиях слоев в зависимости от их полезности. Если преобразование считается несущественным, его веса и, соответственно, выход слоя стремятся к нулю. В этом случае по крайней мере неизмененный вход будет пропущен через остаточное соединение, что помогает сгладить проблему исчезающего градиента.
- Norm — нормализация слоев (Layer Normalization). Этот метод нормализует каждый встроенный вектор в контексте путем вычитания его среднего значения и деления на его стандартное отклонение. Этот процесс также гарантирует, что градиенты во время обратного распространения не подвергаются взрывному росту и не исчезают.
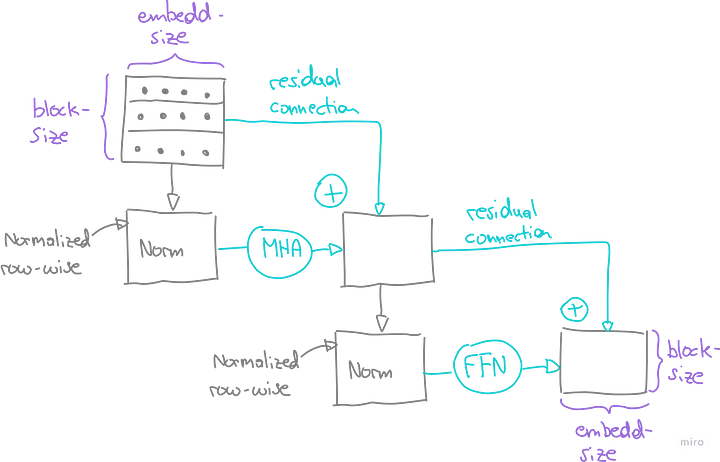
Цепочка слоев многоголового внимания и нейронной сети прямого распространения, связанная с элементами “Add и Norm”, объединяется в блок. Такая модульная конструкция позволяет формировать последовательность блоков. Количество этих блоков является гиперпараметром, определяющим глубину архитектуры модели.
class Block(nn.Module):
"""
This module contains a single transformer block, which consists of multi-head
self-attention followed by feed-forward neural networks.
"""
def __init__(self):
super().__init__()
self.sa = MultiHeadAttention()
self.ffwd = FeedFoward()
self.ln1 = nn.LayerNorm(embed_size)
self.ln2 = nn.LayerNorm(embed_size)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
5.7. Функция Softmax
После прохода нескольких блочных компонентов получаем матрицу размеров (block-size x embed-size — размер блока x эмбеддинг-размер). Чтобы преобразовать эту матрицу в требуемые размеры (block-size x vocab size — размер блока x размер словаря), пропускаем ее через последний линейный слой. Эта форма представляет запись для каждого слова в словаре в каждой позиции контекста.
Затем применяем функцию активации softmax к этим значениям, преобразуя их в вероятности. Мы успешно получили распределение вероятностей для следующего токена в каждой позиции контекста.
6. Обучение модели
Для обучения языковой модели были выбраны последовательности токенов из случайных мест в обучающих данных. Учитывая быстрый темп разговоров в WhatsApp, я решил, что длины контекста в 32 слова будет достаточно. Таким образом, были выбраны случайные фрагменты по 32 слова в качестве входа контекста и использованы соответствующие векторы, сдвинутые на одно слово, в качестве целей для сравнения.
Процесс обучения проходил следующие шаги:
- Выборка нескольких партий контекста.
- Предоставление модели этих выборок для вычисления текущих потерь.
- Применение алгоритма обратного распространения на основе текущих потерь и весов модели.
- Более полная оценка потерь на каждой 500-й итерации.
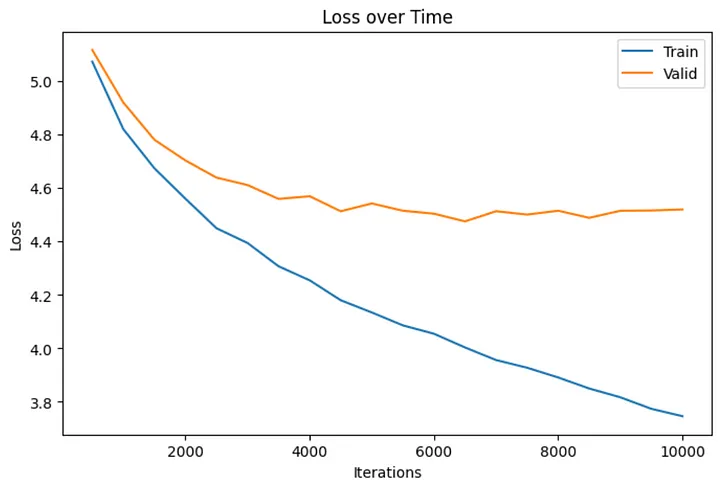
После фиксации остальных гиперпараметров модели (эмбеддинг-размера, количества голов самовнимания и т. д.) я завершил работу над моделью, содержащей 2,5 млн параметров. Учитывая ограниченный объем входных данных и скромные вычислительные ресурсы, счел это оптимальной настройкой.
Процесс обучения занял около 12 часов для 10 000 итераций. Очевидно, что обучение можно было бы прекратить раньше, так как разброс между потерями на проверочном и обучающем наборах увеличивается.
import json
import torch
from config import eval_interval, learn_rate, max_iters
from src.model import GPTLanguageModel
from src.utils import current_time, estimate_loss, get_batch
def model_training(update: bool) -> None:
"""
Trains or updates a GPTLanguageModel using pre-loaded data.
This function either initializes a new model or loads an existing model based
on the `update` parameter. It then trains the model using the AdamW optimizer
on the training and validation data sets. Finally the trained model is saved.
:param update: Boolean flag to indicate whether to update an existing model.
"""
# Загрузка данных -----------------------------------------------------------------
train_data = torch.load("assets/output/train.pt")
valid_data = torch.load("assets/output/valid.pt")
with open("assets/output/vocab.txt", "r", encoding="utf-8") as f:
vocab = json.loads(f.read())
# Инициализация / загрузка модели ---------------------------------------------------
if update:
try:
model = torch.load("assets/models/model.pt")
print("Loaded existing model to continue training.")
except FileNotFoundError:
print("No existing model found. Initializing a new model.")
model = GPTLanguageModel(vocab_size=len(vocab))
else:
print("Initializing a new model.")
model = GPTLanguageModel(vocab_size=len(vocab))
# инициализация оптимизатора
optimizer = torch.optim.AdamW(model.parameters(), lr=learn_rate)
# количество параметров модели
n_params = sum(p.numel() for p in model.parameters())
print(f"Parameters to be optimized: {n_params}\n", )
# Обучение модели ------------------------------------------------------------
for i in range(max_iters):
# оценка потерь на обучающем и проверочном наборе каждые 'eval_interval' шагов
if i % eval_interval == 0 or i == max_iters - 1:
train_loss = estimate_loss(model, train_data)
valid_loss = estimate_loss(model, valid_data)
time = current_time()
print(f"{time} | step {i}: train loss {train_loss:.4f}, valid loss {valid_loss:.4f}")
# выборка партии данных
x_batch, y_batch = get_batch(train_data)
# оценка потерь
logits, loss = model(x_batch, y_batch)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
torch.save(model, "assets/models/model.pt")
print("Model saved")
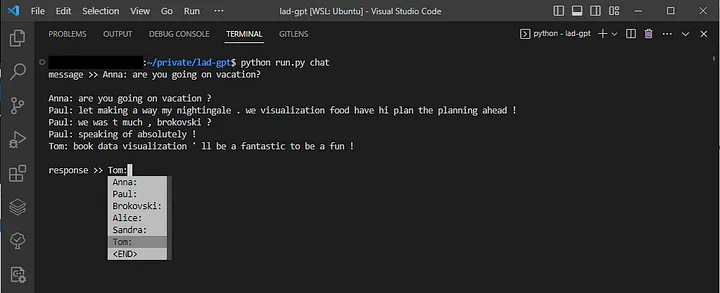
7. Режим работы чата
Для взаимодействия с обученной моделью я создал функцию, которая позволяет выбрать имя контакта через выпадающее меню и ввести сообщение, на которое модель должна ответить. Параметр “n_chats” определяет количество ответов, которые модель генерирует за один раз. Модель завершает сгенерированное сообщение, когда предсказывает, что следующим будет токен <END>.
import json
import random
import torch
from prompt_toolkit import prompt
from prompt_toolkit.completion import WordCompleter
from config import end_token, n_chats
from src.utils import custom_tokenizer, decode, encode, print_delayed
def conversation() -> None:
"""
Emulates chat conversations by sampling from a pre-trained GPTLanguageModel.
This function loads a trained GPTLanguageModel along with vocabulary and
the list of special tokens. It then enters into a loop where the user specifies
a contact. Given this input, the model generates a sample response. The conversation
continues until the user inputs the end token.
"""
with open("assets/output/vocab.txt", "r", encoding="utf-8") as f:
vocab = json.loads(f.read())
with open("assets/output/contacts.txt", "r", encoding="utf-8") as f:
contacts = json.loads(f.read())
spec_tokens = contacts + [end_token]
model = torch.load("assets/models/model.pt")
completer = WordCompleter(spec_tokens, ignore_case=True)
input = prompt("message >> ", completer=completer, default="")
output = torch.tensor([], dtype=torch.long)
print()
while input != end_token:
for _ in range(n_chats):
add_tokens = custom_tokenizer(input, spec_tokens)
add_context = encode(add_tokens, vocab)
context = torch.cat((output, add_context)).unsqueeze(1).T
n0 = len(output)
output = model.generate(context, vocab)
n1 = len(output)
print_delayed(decode(output[n0-n1:], vocab))
input = random.choice(contacts)
input = prompt("\nresponse >> ", completer=completer, default="")
print()
Заключение
Из-за конфиденциальности моих личных чатов я не могу представить здесь примеры промптов и бесед.
Тем не менее можно ожидать, что модель такого масштаба будет успешно изучать общую структуру предложений, выдавая осмысленные результаты с соблюдением порядка слов. В моем случае она также улавливала контекст тем, ярко выраженных в обучающих данных. Так, поскольку в моих личных чатах частой темой является теннис, имена теннисистов и слова, связанные с теннисом, обычно выводились вместе.
Однако, оценивая связность сгенерированных предложений, признаю, что результаты не вполне оправдали мои и без того скромные ожидания. Но, конечно, я могу обвинить и своих друзей в том, что они писали слишком много лишнего, ограничивая возможности модели научиться чему-то полезному…
Чтобы увидеть хотя бы примерный результат, можете посмотреть, как работает модель фиктивного языка на 200 обученных фиктивных сообщениях.
Читайте также:
- Большой языковой модели недостаточно: внедрение Context Fusion & Toolkit в корпоративные решения. Часть 1
- Как язык SudoLang помогает общаться с языковыми моделями. Руководство для новичков
- О машинном обучении простым языком
Читайте нас в Telegram, VK и Дзен
Перевод статьи Bernhard Pfann: Build a Language Model on Your WhatsApp Chats





