
Вы новичок в области инженерии данных и хотите узнать больше о современных инфраструктурах данных? Тогда эта статья для вас! В сегодняшнем руководстве мы объединим инженерию данных и Формулу-1. И постараемся не усложнять.
Введение
Я твердо убежден в том, что лучше всего описывать концепции на примерах, хотя некоторые из моих университетских преподавателей говорили: “Если вам нужен пример для пояснения, значит, вы ничего не поняли”.
Так или иначе, я не уделял должного внимания университетским занятиям, и сегодня собираюсь рассказать о слоях данных с помощью примера.
Бизнес-сценарий и архитектура данных
Представьте: в следующем году команда Red Thunder Racing обратится к нам с просьбой создать новую инфраструктуру данных.
Сегодня при проведении чемпионатов Формулы-1 данные занимают куда более важное место, чем 20 или 30 лет назад. Гоночные команды улучшают показатели благодаря феноменальному подходу, основанному на данных, внося улучшения с каждой миллисекундой.
Речь идет не только о времени прохождения круга. Формула 1 — это многомиллиардный бизнес. Оптимизация вовлеченности болельщиков — не просто развлечение, а привлекательность спорта повышается не просто ради забавы гонщиков. Эти мероприятия приносят доход.
Надежная инфраструктура данных — обязательное условие конкурентоспособности в бизнесе Формулы-1.
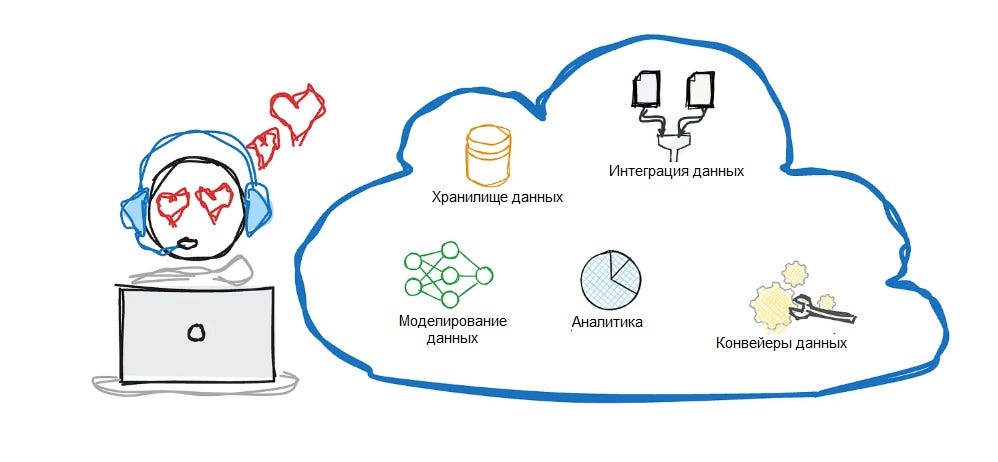
Мы построим архитектуру данных для поддержки гоночной команды. Начнем с трех канонических слоев: озера данных, хранилища данных и витрины данных.
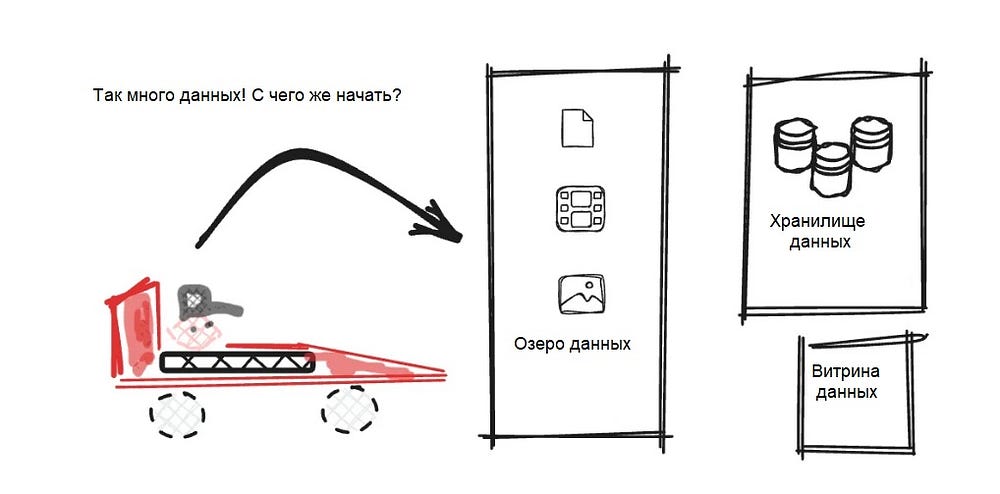
Озеро данных (Data Lake)
Озеро данных будет служить репозиторием необработанных и неструктурированных данных, полученных из различных источников в экосистеме Формулы 1. Сюда войдут телеметрические данные с болидов (например, давление в шинах в секунду, скорость, расход топлива), характеристики гонщиков, время прохождения круга, погодные условия, ленты социальных сетей, продажа билетов, регистрация болельщиков на маркетинговые мероприятия, покупка атрибутики…
В нашем консолидированном озере данных можно хранить любые данные: неструктурированные (аудио, видео, изображения), полуструктурированные (JSON, XML) и структурированные (CSV, Parquet, AVRO).
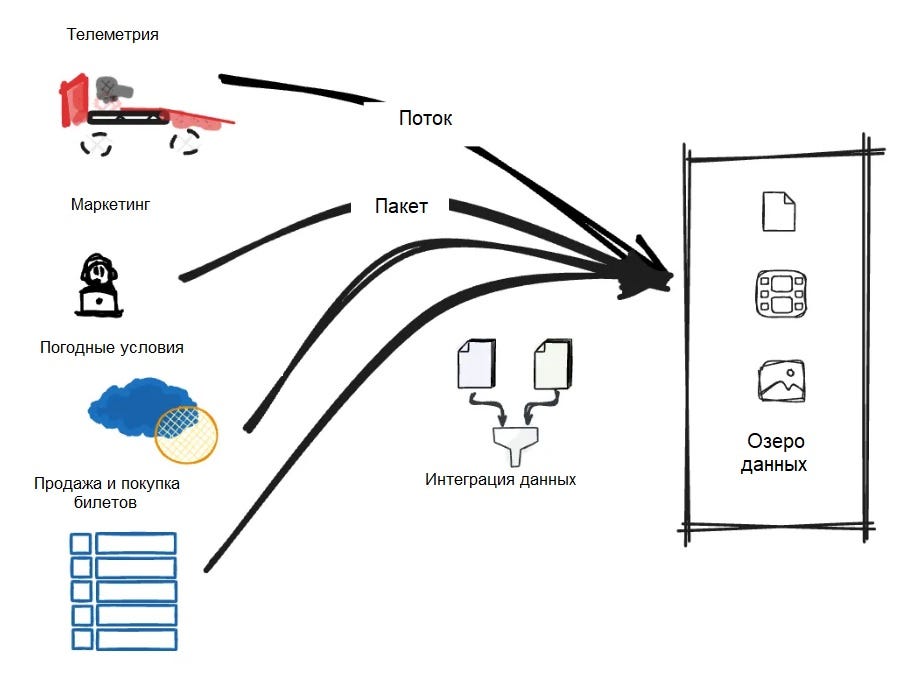
Мы столкнемся с первыми проблемами, когда будем интегрировать и консолидировать все в одном месте. Мы создадим пакетные задания, извлекающие записи из маркетинговых инструментов, а также будем работать с потоковыми телеметрическими данными в реальном времени (к ним будут предъявляться очень низкие требования по задержкам).
Нам понадобится интегрировать целый перечень систем, каждая из которых поддерживает свой протокол или интерфейс: Kafka Streaming, SFTP, MQTT, REST API и другие.
Мы не будем одиноки в процессе сбора данных. К счастью, на рынке существуют инструменты интеграции данных, которые можно использовать для настройки и поддержки конвейеров ввода данных в одном месте (например, Fivetran, Hevo, Informatica, Segment, Stitch, Talend и др.).
Мы не станем полагаться на сотни скриптов Python, прописанных в таблицах crontab, или запускать собственные процессы, обрабатывающие потоки данных из тем Kafka. Мы воспользуемся указанными инструментами, которые помогут упростить, автоматизировать и оркестровать весь ход работы.
Хранилище данных (Data Warehouse)
Несколько недель ушло на определение всех потоков данных, которые нужно интегрировать. Теперь в озеро поступают самые разнообразные данные. Пора переходить к следующему уровню.
Хранилище данных используется для очистки, структурирования и хранения обработанных данных из озера данных, обеспечивая структурированную, высокопроизводительную среду для аналитики и отчетности.
На этом этапе речь уже не идет о получении данных, и мы все больше фокусируемся на бизнес-показателях. Предлагая структурированные и регулярно обновляемые наборы данных, нужно подумать о том, как эти данные будут использоваться нашими коллегами. Так, необходимо принять во внимание следующее:
- Показатели автомобилей. Телеметрические данные очищаются, нормализуются и интегрируются для получения единой картины.
- Обзор стратегий и закономерностей. Данные прошлых гонок используются для выявления закономерностей, показателей гонщиков и понимания влияния на результат конкретных стратегий.
- KPI команды. Сюда входят временные промежутки пит-стопов, температура в шинах перед пит-стопом и управление бюджетом, выделяемым на улучшение автомобилей.
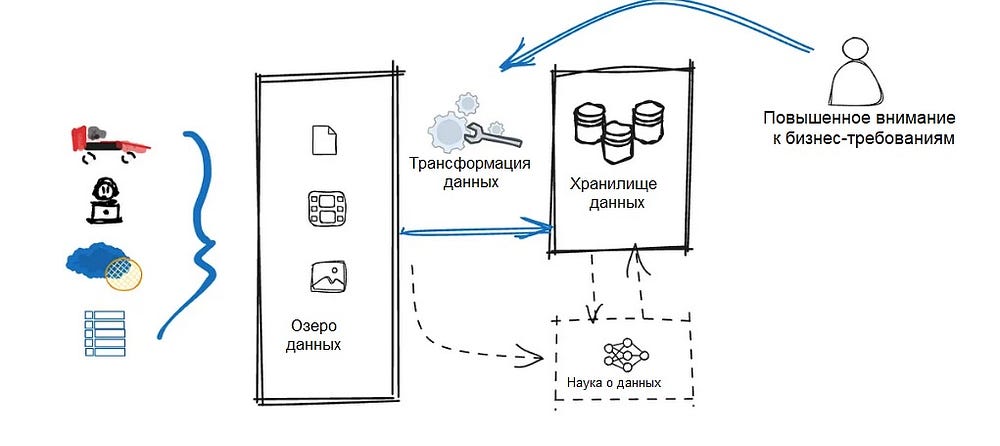
У нас будет множество конвейеров, предназначенных для преобразования и нормализации данных.
Как и в случае с интеграцией данных, на рынке представлено множество продуктов для упрощения и эффективного управления конвейерами данных. Эти инструменты рационализируют процесс работы с данными, сокращают операционные расходы и повышают эффективность разработки (к ним относятся такие продукты, как Apache Airflow, Azure Data Factory, DBT, Google DataForm и др.).
Витрины данных (Data Marts)
Между хранилищами и витринами данных существует тонкая грань.
Не стоит забывать, что мы работаем в Red Thunder Racing, крупной компании, в которой тысячи сотрудников заняты в самых разных областях.
Данные должны быть доступны и соответствовать требованиям конкретных подразделений. Модели данных строятся с учетом потребностей бизнеса.
Витрины данных — это специализированные подмножества хранилищ данных, ориентированные на конкретные бизнес-функции.
- Витрина показателей автомобилей. Команда RnD анализирует данные, касающиеся эффективности двигателя, аэродинамики и надежности. Инженеры будут использовать эту базу данных для оптимизации настроек автомобиля под различные гоночные трассы или для проведения симуляций, чтобы определить наилучшую конфигурацию автомобиля в зависимости от погодных условий.
- Витрина вовлеченности болельщиков. Сотрудники маркетингового отдела анализируют данные социальных сетей, опросы фанатов и рейтинги зрителей, чтобы понять предпочтения любителей гонок. Специалисты по маркетингу используют эти данные для разработки индивидуальных маркетинговых стратегий, создания атрибутики и большей осведомленности о Fan360.
- Витрина бухгалтерской аналитики. Сотрудникам финансового отдела тоже нужны данные (речь идет о большом количестве цифр). Сейчас, как никогда, гоночным командам приходится иметь дело с бюджетными ограничениями и правилами. Важно следить за распределением бюджета, доходами и контролем расходов в целом.
Кроме того, часто требуется обеспечить доступ к конфиденциальным данным только для уполномоченных групп. Например, сотрудникам RnD-отдела может потребоваться эксклюзивный доступ к телеметрической информации, и им нужно, чтобы эти данные анализировались с помощью определенной модели данных. Однако им может быть не разрешен (или не интересен) доступ к финансовым отчетам.
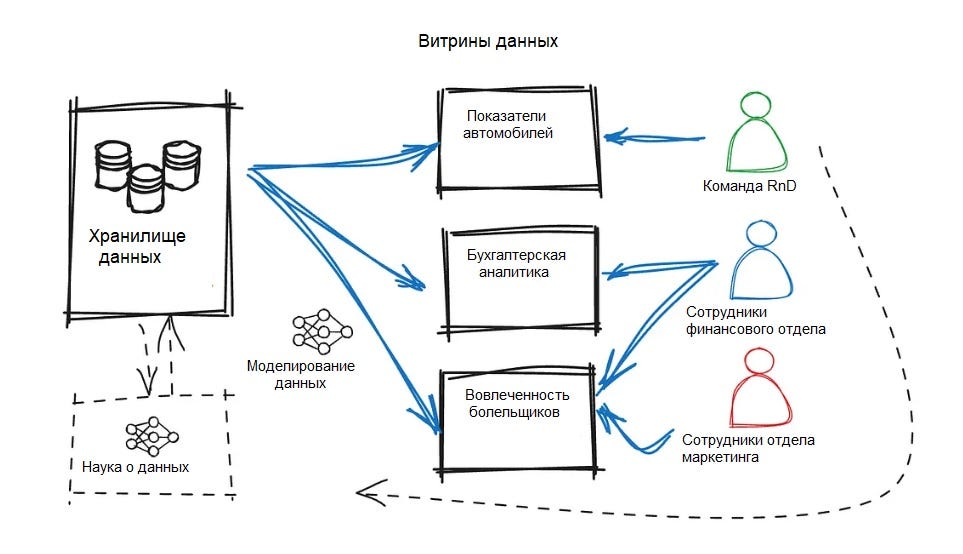
Многоуровневая архитектура данных позволит Red Thunder Racing использовать всю мощь данных для оптимизации производительности автомобилей, принятия стратегических решений, расширения маркетинговых кампаний… и не только!
Это все?
Конечно, нет! Мы едва пробежались “по верхам” архитектуры данных. Вероятно, есть еще сотни точек интеграции, которые мы должны были рассмотреть. Более того, мы ограничились лишь упоминанием таких понятий, как трансформации данных и моделирование данных.
Мы совсем не затронули науку о данных, которая, вероятно, заслуживает отдельной статьи, а также не упомянули об управлении, наблюдаемости, безопасности данных и многом другом.
Но, как говорится, не все сразу. Мы и так разобрали много чего, включая наш первый проект архитектуры данных (ниже).
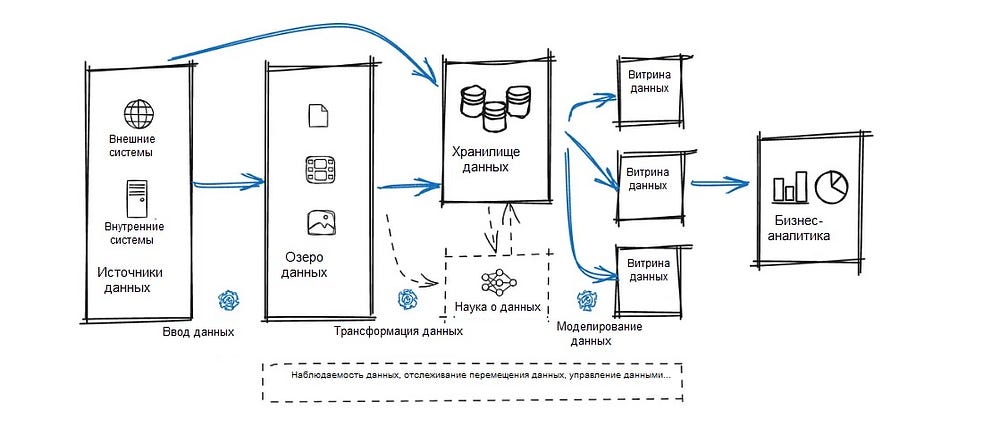
Вывод
Инженерия данных — это волшебное царство, которому посвящено множество книг.
На протяжении всего пути инженеры по данным будут работать с неограниченным количеством инструментов интеграции, разнообразными платформами данных, нацеленными на охват одного или нескольких вышеупомянутых слоев (например, AWS Redshift, Azure Synapse, Databricks, Google BigQuery, Snowflake и т. д.), инструментами бизнес-аналитики (например, Looker, PowerBI, Tableau, ThoughtSpot и др.) и конвейерами данных.
Наша карьера дата-инженера в Red Thunder Racing только начинается, и мы должны оставить достаточно пространства для выбора из широкого ассортимента инструментов!
Слои данных можно часто объединять вместе, иногда в рамках одной платформы. Производители платформ и инструментов для работы с данными с каждым днем поднимают планку и сокращают разрыв друг от друга, выпуская все новые функции. Конкуренция на этом рынке очень высока.
- Всегда ли нужно озеро данных? Это зависит от конкретной ситуации.
- Всегда ли нужно, чтобы данные сохранялись как можно быстрее (так называемая потоковая обработка и обработка в реальном времени)? Зависит от того, какие требования к свежести данных предъявляют бизнес-пользователи.
- Всегда ли нужно полагаться на сторонние инструменты для управления конвейерами данных? Это зависит от конкретной ситуации!
- <Любой другой вопрос, который у вас может возникнуть>? Это зависит от конкретной ситуации!
Читайте также:
- Проект инженерии данных с DAG Airflow «от и до». Часть 1
- Принципы SOLID в инженерии данных. Часть 1
- 5 уникальных подходов Google к инженерии данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Matteo Consoli: Data Engineering: A Formula 1-inspired Guide for Beginners





