
Когда в реальном времени считываются/записываются миллиарды строк данных пользовательского уровня, обслуживание сотен запросов в секунду со средней задержкой в несколько миллисекунд — непростая задача. Здесь требуется серьезная, недешевая инфраструктура и команда экспертов.
Нельзя ли обойтись кластером k8s и базой данных с открытым исходным кодом? Ведь это отсутствие простоев при отработке отказа, миллисекундное время отклика, вертикальное и горизонтальное масштабирование, разделение данных по ядрам процессора, полностью распределенные операции чтения/записи и многое другое.
Расскажем, как ScyllaDB становится основной производственной БД реального времени вместо MongoDB. Scylla — это Open Source версия Apache Cassandra на C++ со всеми преимуществами БД кольцевой архитектуры без главного узла, лишенная всех этих пресловутых проблем Cassandra: недостатков виртуальной машины Java, сборки мусора с «остановкой мира», большого объема занимаемой памяти, медленного запуска, прогрева JIT и его сложной настройки.
В Scylla имеется готовый к продакшену HELM chart. Это оператор k8s и конфигурация по технологии plug and play («включи и играй») с открытым исходным кодом и безупречной работой на спотовых, то есть непостоянных экземплярах, стоимость вычислений в которых вчетверо ниже обычной.
В заключение расскажем, как выполнять ежечасное резервное копирование с VolumeSnapshots на k8s для беспроблемного восстановления, применять расширение тома в k8s 1.24 для динамического увеличения размера диска, настраивать оповещения и дашборды Grafana.
Почему не MongoDB ?
Чем плоха Mongo? У нее открытый исходный код, поддерживается разделение данных, но совершенно иная архитектура — с единой точкой отказа. При «падении» главного узла, то есть координатора, в БД начинается отработка отказа, во время которого БД недоступна.
Кроме того, для достижения высокой доступности каждый сегмент Mongo должен запускаться как набор реплик — больше узлов. Кольцевая архитектура Cassandra в этом смысле превосходнее. Драйвер Scylla «знает» о сегментах и добирается до конкретного узла/процессора, ответственного за запрашиваемую строку, делая распределение действительным.
Но почему так важны отработка отказов без простоев и высокая доступность? На спотовых экземплярах — а это 1/4 стоимости вычислений — часто ежедневно случаются отработки отказов: узлы в k8s постоянно уничтожаются и воссоздаются, что чревато завершением всех запущенных в них подов/процессов, в том числе БД.
Установка Scylla
Сначала запустим локально, используя драйверы и что-нибудь на Cassandra Query Language:
docker run -p 9042:9042 -p 7002:7000 -p 7001:7001 -p 9160:9160 -p 9180:9180 --name scylla --hostname scylla -d scylladb/scylla --smp 1 --developer-mode 1
Этой командой запустится одноузловой кластер Scylla. Так в режиме разработчика Scylla требуется минимум ресурсов в отличие от Cassandra, с которой у Docker Engine много работы.
Применение драйвера Scylla
Вот простой пример на Golang с использованием официального драйвера Scylla:
import "github.com/gocql/gocql"
func Connect(config Config) (*gocql.Session, error) {
cluster := gocql.NewCluster(config.Hosts...)
cluster.Keyspace = config.KeySpace
cluster.CQLVersion = "3.11"
cluster.RetryPolicy = &gocql.ExponentialBackoffRetryPolicy{
NumRetries: 5, Min: time.Millisecond * 5, Max: time.Second * 5}
cluster.ProtoVersion = 3
cluster.PoolConfig.HostSelectionPolicy = gocql.TokenAwareHostPolicy(
gocql.RoundRobinHostPolicy())
cluster.ConnectTimeout = time.Second * 10
cluster.Consistency = gocql.One
if config.Timeout != nil {
cluster.Timeout = *config.Timeout
}
cluster.Authenticator = gocql.PasswordAuthenticator{
Username: config.Username, //'cassandra' по умолчанию
Password: config.Password, //'cassandra' по умолчанию
}
session, err := cluster.CreateSession()
if err != nil {
return nil, err
}
return session, nil
}
Здесь стоит обратить внимание вот на что:
cluster.PoolConfig.HostSelectionPolicy = gocql.TokenAwareHostPolicy(
gocql.RoundRobinHostPolicy())
Драйвером-клиентом TokenAware с помощью ключа раздела пробуется первый сегмент, затем методом циклического перебора — следующий, если первый недоступен. Для этого необходимо подключиться не к порту Cassandra по умолчанию 9042, а к порту Scylla с поддержкой сегментов 19042.
Попробуем простой запрос:
func Ping(session *gocql.Session) error {
var str = new(string)
if err := session.Query("SELECT uuid() FROM system.local;").Scan(str); err != nil {
return err
}
if str == nil || len(*str) == 0 {
return errors.New("failed sanity check")
}
return nil
}
// альтернатива «select 1;» в SQL
Переходим в облако
Поиграв с ключами разделов, сегментами уровней согласованности и коэффициентами репликации, установим оператор k8s.
Вот chart. Внимание: его README.md устарел и некорректен.
В репозитории содержится три helm chart:
- scylla;
- scylla operator;
- scylla manager.
Первая — сама БД, основа которой — ScyllaCluster CRD, то есть определение специального ресурса k8s. Это yaml-файл для настройки кластера scylla: его размера, ресурсов, файловой системы и т. д.
В scylla operator устанавливается контроллер k8s, где из этого yaml создаются StatefullSet, службы и другие сущности k8s.
scylla manager — это фактически служба-синглтон для автоматизации задач, подключаемая ко всем узлам scylla. Ею выполняются внутрикластерные задачи, такие как восстановление и резервное копирование в облачном хранилище.
Для установки и настройки этих chart используем ArgoCD с его откатами механики GitOps и возможностью наблюдать происходящее в K8S: не запускаем команду установки helm, а нажимаем несколько кнопок пользовательского интерфейса и добавляем в гит-репозиторий yaml-файлы.
В scylla-operator обнаружена проблема с ValidatingWebhookConfiguration: прежде чем применяться оператором в кластере, Scylla CRD проверяется небольшим контроллером, определяемом в этом yaml. Если проверка не пройдена, оператором ничего не выполняется.
Просто удаляем этот файл, стараясь не трогать CRD. Причина проблемы не известна, но это и не важно: плагином IDEA helm распознается определение CRD и предоставляется автодополнение ввода.
Конфигурация scylla operator предельно проста: нужно только определить nodeSelector в k8s и tolerations запрета на размещение подов в узлах, если они необходимы. То есть определяются узлы k8s, на которых запускается оператор. Это та же технология plug and play («включи и играй»).
Переходим к scylla manager в Chart.yaml:
apiVersion: v2
name: scylla-manager
description: Scylla Manager automates database operations.
version: 0.0.0 # перезаписывается во время публикации
appVersion: "1.7" # перезаписывается во время публикации
dependencies:
- name: scylla
version: 1.0.0
repository: file://../scylla
В директиве dependencies объявляется об импорте chart scylla в scylla-manager, поэтому вопреки тому, что указано в README, при установке устанавливаются то и другое.
В конфигурации values.yaml имеется раздел для Scylla, где все и происходит:
Определение Scylla CRD «staging»
# scylla-manager values.yaml
# ...
scylla:
cpuset: false
automaticOrphanedNodeCleanup: true
repairs:
- name: "weekly manager-rack repair"
intensity: "2"
interval: "7d"
dc: [ "manager-dc" ]
serviceMonitor:
promRelease: staging-prometheus-operator
create: true
developerMode: true
scyllaImage:
tag: 5.2.0
agentImage:
tag: 3.0.0
datacenter: manager-dc
racks:
- name: staging
placement:
tolerations:
- key: "infra"
operator: "Exists"
effect: "NoSchedule"
members: 3
storage:
capacity: 6Gi
storageClassName: xfs-class
resources:
limits:
cpu: 1
memory: 1000Mi
requests:
cpu: 250m
memory: 200Mi
Ключевое в этой конфигурации — xfs в storageClassName, рекомендуется в scylla для большей производительности. В chart не содержится определение класса storage, добавляем его самостоятельно:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: xfs-class
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-ssd
csi.storage.k8s.io/fstype: xfs
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
С флагом allowVolumeExpansion размер диска PVC во время работы БД без проблем увеличивается.
Вот результат установки обоих chart с помощью ArgoCD:
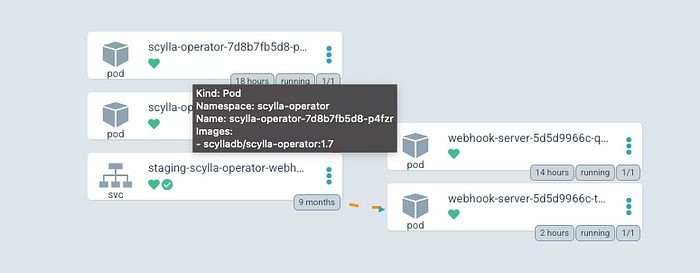
Высокодоступный оператор Scylla готов к работе, у него две реплики. На основе его CRD создаем кластер scylla:
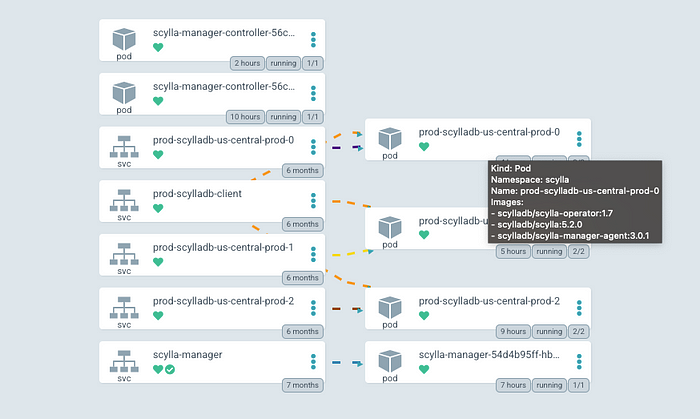
Это кластер из трех узлов. Каждым подом запускаются сама БД, scylla manager и клиенты оператора. Так заменяется целая команда экспертов, автоматизируются задачи администрирования, операционные задачи.
Мониторинг
Ни одна производственная БД не обходится без мониторинга и системы оповещений. В scylla operator применяется конфигурация мониторинга служб Prometheus:
scylla:
...
serviceMonitor:
promRelease: staging-prometheus-operator
create: true
С этим флагом оператором создается два средства контроля за службами:
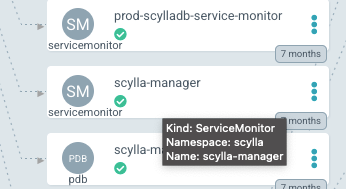
Так, чтобы определять дашборды Grafana и оповещения, с помощью Prometheus периодически собираются метрики БД, сохраняются в БД временны́х рядов, выполняются запросы PromQL.
Prometheus оставляем за рамками статьи, но сейчас это отраслевой стандарт.
Дашборды
JSON-дашбордов Grafana нет в helm chart Scylla, добавим их отсюда:
Для этого создаем ConfigMaps k8s и помечаем их как grafana dashboard, в Helm такая возможность имеется:
{{- range $path, $_ := .Files.Glob "dashboards/scylla/*.json" }}
{{- $filename := trimSuffix (ext $path) (base $path) }}
apiVersion: v1
kind: ConfigMap
metadata:
name: scylla-dashboard-{{ $filename }}
namespace: monitoring
labels:
grafana_dashboard: "1"
app.kubernetes.io/managed-by: {{ $.Release.Name }}
app.kubernetes.io/instance: {{ $.Release.Name }}
data:
{{ base $path }}: |-
{{ $.Files.Get $path | indent 4 }}
---
{{- end }}
С помощью фрагмента кода выше в k8s добавляется пять configmap с пометкой grafana_dashboard: "1" и подключается к Grafana.
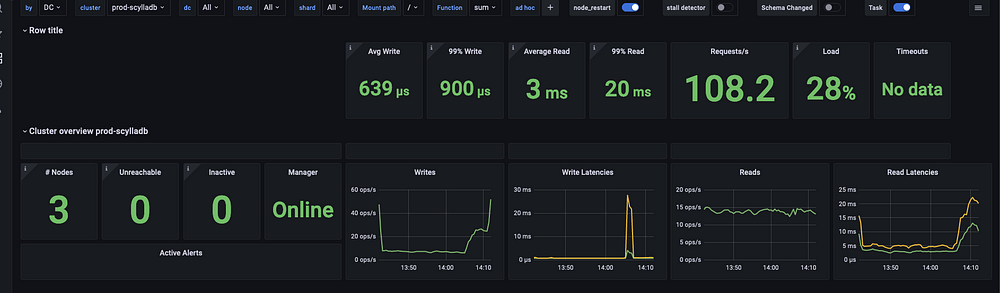
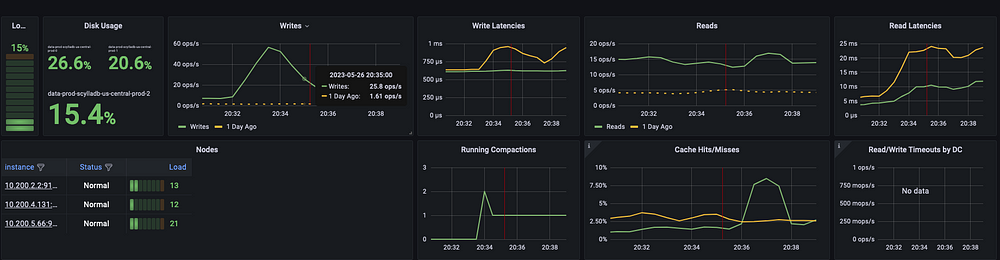

Среди множества графиков со всеми нюансами экспортируемых метрик для скрупулезного мониторинга всего, что происходит с БД, приведенный выше очень важен. В нем описаны все отработки отказов за последние 25 часов.
Каждый раз, когда в k8s уничтожается спотовый экземпляр, планируется новый под Scylla, присоединяемый к кластеру за пару минут без каких-либо простоев. Мы запускаем Scylla уже почти год: работает как часы.
Рекомендуем всегда выделять в пуле дополнительный узел, с высокой вероятностью обеспечивая наличие минимум одного узла для планирования нового пода БД. Цена немного увеличится, но это гораздо экономичнее обычных узлов.
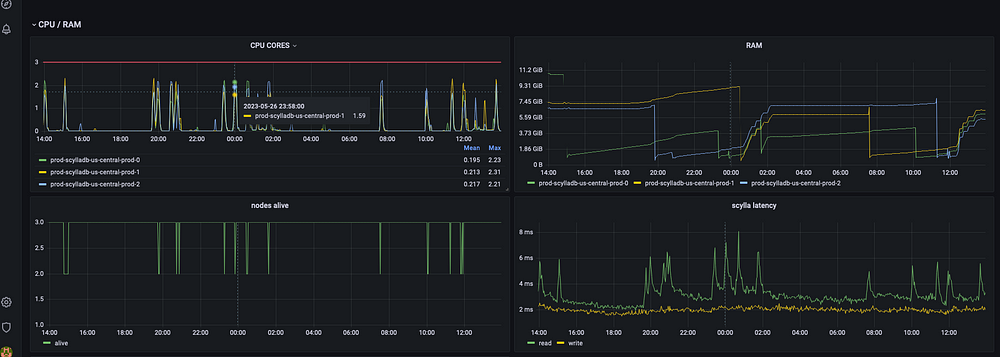
Каждый раз, когда уничтожается экземпляр Scylla, наблюдается короткий скачок процессора, на пару миллисекунд увеличивается задержка, а оперативная память сваливается из-за исчезновения всего создаваемого в ней при помощи Scylla кеша.
Этот явный недостаток образуется из-за спотовых экземпляров, но в нашем случае стоит поступиться короткими, очень небольшими всплесками задержки ради значительного уменьшения стоимости вычислений.
Оповещения
Не хватает в официальном chart и встроенных оповещений, они имеются в другом проекте. Добавим их в пользовательское расширение helm chart Scylla. Эти оповещения — о времени безотказной работы, задержке, оперативной памяти, процессоре, дисковом пространстве — самые критически важные, на мой взгляд:
- name: scylla_live_nodes
message: scylla has < 3 nodes for more than 30m
expr: count(up{job="scylla",container="scylla"}) < 3
severity: error
for: 30m
- name: scylla_read_latency
message: avg scylla read takes more than a second
expr: sum(rate(scylla_storage_proxy_coordinator_read_latency_sum[60s]))/(sum(rate(scylla_storage_proxy_coordinator_read_latency_count[60s])) + 1) > 1000000
severity: warn
- name: scylla_write_latency
message: avg scylla write takes more than a second
expr: sum(rate(scylla_storage_proxy_coordinator_write_latency_sum[60s]))/(sum(rate(scylla_storage_proxy_coordinator_write_latency_count[60s])) + 1) > 1000000
severity: warn
- name: scylla_node_unreachable
message: scylla node unreachable
expr: (count(scrape_samples_scraped{job="scylla"}==0) OR vector(0)) > 0
severity: error
for: 15m
- name: scylla_node_inactive
message: scylla node inactive
expr: count(scylla_node_operation_mode!=3)OR vector(0) > 0
severity: error
for: 15m
- name: scylla_disk_below_50
message: scylla available disk below 50
expr: 100 - (kubelet_volume_stats_available_bytes{job="kubelet", namespace=~"scylla", metrics_path="/metrics"} / kubelet_volume_stats_capacity_bytes{job="kubelet", namespace=~"scylla", metrics_path="/metrics"} * 100) > 50
severity: error
- name: scylla_cpu_above_50
message: scylla cpu > 50%
expr: sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_rate{namespace="scylla", pod=~"prod-scylladb.*"}) by (pod) > 50
severity: warn
for: 15m
- name: scylla_high_ram
message: scylla ram > 12
expr: sum(container_memory_working_set_bytes{namespace="scylla", container!="", image!="", pod=~"prod-scylladb-us.*"}) by (pod) > 12700000000
severity: warn
for: 15m
- name: scylla_manager_offline
message: scylla manager offline
expr: (sum(scylla_manager_task_active_count{type=~"repair"}) or on() vector(0)) + (sum(scylla_manager_task_active_count{type=~"backup"})*2 or on() vector(0)) + (sum(scylla_manager_server_current_version{}) or on() vector(-1)) > 0
severity: warn
for: 15m
Бонус
Увеличение размера диска, или как избежать нехватки места на диске
В k8s 1.24 наконец-то появился долгожданный функционал расширения тома, с которым эта задача сильно упрощается.
Вот определение PVC, созданное с помощью K8S StateFullSet:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
volume.beta.kubernetes.io/storage-provisioner: pd.csi.storage.gke.io
finalizers:
- kubernetes.io/pvc-protection
labels:
app: scylla
app.kubernetes.io/managed-by: scylla-operator
app.kubernetes.io/name: scylla
scylla/cluster: stg-scylladb
scylla/datacenter: us-central
scylla/rack: stg
name: data-stg-scylladb-us-central-prod-2
namespace: scylla
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: xfs-class
volumeMode: Filesystem
volumeName: pvc....
Если попытаться изменить определение STS и увеличить размер диска, в K8S появится ошибка с указанием, что единственный способ изменить дисковое пространство — воссоздать StateFullSet. В будущем это может поменяться, а пока просто редактируем PVC на месте и увеличиваем размер его диска:
resources:
requests:
storage: 6Gi
Активируется расширение тома, и диск «увеличивается» на запрашиваемый размер, не влияя на запущенный под. Но этот функционал доступен с версии k8s 1.24, и только если поддерживается классом storage.
После увеличения диска запускаем в каждом узле скрипт scylla_io_setup: диски протестируются, сгенерируются файлы io.conf и io_properties.yaml.
Периодические моментальные снимки томов
Другой полезный ресурс K8S — VolumeSnapshot, с помощью которого в k8s создается снимок диска для последующего воссоздания PVC, заполненного данными из него. Этот снимок сжат и сохраняется в облачном хранилище, поэтому оплачивается только размер используемого сжатого диска, а не емкость диска для резервного копирования.
Но снимок резервной копии делается сразу после ее создания. Поэтому, чтобы периодически делать резервные копии, нужно чем-то периодически создавать и удалять такие Volumesnapshot, чем и занимается этот Open Source проект. В нем имеется CRD ScheduledVolumeSnapshot такой:
apiVersion: k8s.ryanorth.io/v1beta1
kind: ScheduledVolumeSnapshot
metadata:
labels:
app.kubernetes.io/instance: prod-scylladb
name: scylla-snapshot-data-prod-scylladb-us-central-prod-0
namespace: scylla
spec:
persistentVolumeClaimName: data-prod-scylladb-us-central-prod-0
snapshotClassName: scylla-backup-prod-scylladb
snapshotFrequency: 1
snapshotRetention: 23
snapshotLabels:
db: scylla
Каждому PVC требуется один ScheduledVolumeSnapshot, в свойстве спецификации persistentVolumeClaimName должно содержаться имя целевого PVC для резервного копирования. У этого простого ресурса своя задача: снимок каждого PVC делается ежечасно и хранится 12 часов.
Восстановление из снимка
В k8s это так же просто, как сделать такой снимок.
Нужно лишь воссоздать PVC со спецификацией dataSource, которая ссылается на конкретный снимок:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: data-staging-scylladb-manager-dc-stg-0
namespace: scylla
spec:
accessModes:
- ReadWriteOnce
dataSource:
apiGroup: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: scylla-snapshot-data-staging-scylladb-manager-dc-stg-0-1684392311
resources:
requests:
storage: 7G
storageClassName: xfs-class
volumeMode: Filesystem
Имена снимков получаем с помощью kubectl:
kubectl get VolumeSnapshot -n scylla
Проверяем, что снимок рабочий, запуская это:
kubectl describe VolumeSnapshot <SNAPSHIOT_NAME> -n scylla
И находим событие SnapshotReady, которым объявляется о его готовности или выставлении флага Ready to use true.
Заключение
ScyllaDB оказалась отличной БД с открытым исходным кодом, которая оправдывает возлагаемые на нее ожидания. Замечательно, что она находится в свободном доступе.
Как разработчик, я не имею отношения к ScyllaDB, но благодарен и выражаю искреннюю признательность их сообществу за приверженность открытому программному обеспечению и возможность применять такую замечательную технологию.
Читайте также:
- Раскрываем возможности контейнеризации. Зачем дата-сайентистам Docker и Kubernetes?
- Простое развёртывание графовой базы данных: JanusGraph
- Структуры данных, которые необходимо знать каждому программисту
Читайте нас в Telegram, VK и Дзен
Перевод статьи Igor Domrev: ScyllaDB on K8S: Conquering Intense Workloads with Spot Instances and zero downtime





