
В разделении фронтенда от бэкенда есть множество преимуществ:
- Самая значительная причина, почему API популярны, в том, что API позволяют получать данные из любого источника: веб-клиента, мобильных приложений, десктоп приложений и т.д…
- Разделение задач. Давно прошли те дни, когда вы пользовались одним приложением, в котором все связано вместе. Представьте, что у вас очень замысловатое, сложное приложение. Единственный выход — нанимать чрезвычайно квалифицированных разработчиков, из-за естественной сложности.
Я сторонник того, чтобы нанимать юниоров и обучать их, и именно поэтому я считаю, что следует разделять задачи. Разграничивая задачи, вы снижаете сложность вашего приложения, разделяя ответственность на «микро-сервисы», так, каждая команда будет специализироваться на своём микро-сервисе.
Как уже упоминалось, процесс расширения штата происходит куда быстрее, благодаря разделению ответственности (backend team, frontend team, dev ops team, и так далее).

Дальновидность и начало работы
Мы будем строить очень мощный и гибкий API GraphQL на основе NodeJs с документацией Swagger, работающей на MongoDB.
Основным костяком нашего API будет Hapi.js. Мы рассмотрим все технологии в мельчайших деталях.
В итоге у нас будет очень мощный GraphQL API с отличной документацией.
Вишенкой на торте станет интеграция с клиентом (React, Vue, Angular).
Нам понадобится:
- Установленный NodeJs
- Базовый JavaScript. Если вы не уверены, что у вас достаточно знаний, по ссылке вы найдёте лучшие курсы по JavaScript.
- Терминал (подойдёт любой, но лучше на основе bash).
- Текстовый редактор (подойдёт любой).
- MongoDb (инструкция по установке). Для Mac:
brew install mongodb.
Вперёд!
Откройте терминал и создайте проект. В директории проекта мы инициализируем Node.
Создаём наш проект.
Далее нам нужно настроить Hapi сервер. Устанавливаем зависимости. Можете использовать Yarn или NPM.

yarn add hapi nodemon
Прежде чем мы продолжим, давайте поговорим о Hapi.js, что это такое и какая нам от этого польза.

Hapi мотивирует разработчика сфокусироваться на логике многократного применения вместо того, чтобы тратить время на создание инфраструктуры.
Вместо того, чтобы использовать Express, мы выбираем Hapi. В двух словах, Hapi — это фреймворк для Node. Причина, по которой я выбрал Hapi — это простота и гибкость по сравнению с шаблонным кодом.
Hapi позволяет нам быстро создавать API.
Если есть желание, посмотрите этот ускоренный курс hapi.js:
Вторая зависимость, которую мы установили, это старый добрый nodemon. Nodemon автоматически перезапускает наш сервер, когда мы вносим изменения. Это значительно ускоряет разработку.
Давайте откроем наш проект в текстовом редакторе. Для этого я использую Visual Studio Code.
Настройка сервера Hapi очень проста. Создайте файл index.js в корневом каталоге, с таким содержанием:
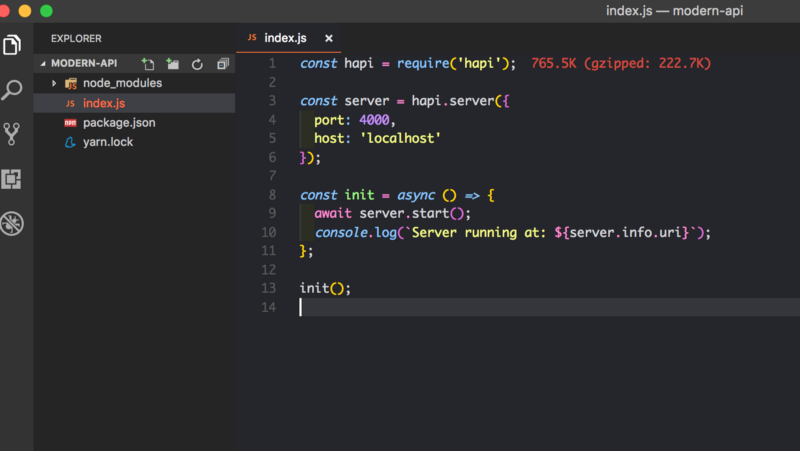
- Мы запрашиваем зависимость
hapi - Во-вторых, мы создаём константу server, которая создаёт новый экземпляр нашего Hapi сервера. В качестве аргументов мы передаём объект с параметрами port и host.
- В-третьих, мы создаём асинхронное выражение с именем init. Внутри метода init у нас есть другой асинхронный метод, который запускает сервер. Обратите внимание на
server.start(),внизу мы вызываем функциюinit().
Если вы не уверены на счёт async await – посмотрите это видео:
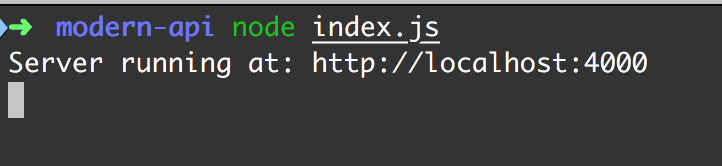
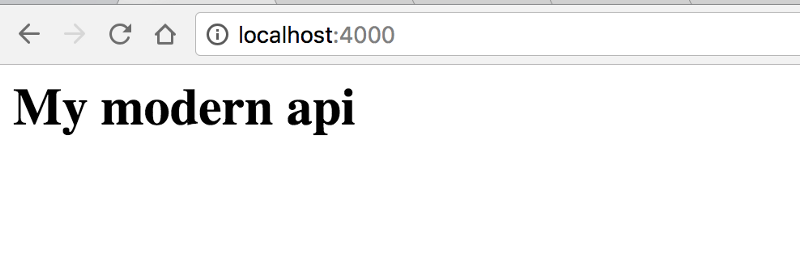
Теперь, если мы перейдём на http://localhost:4000 , то должны увидеть следующее:
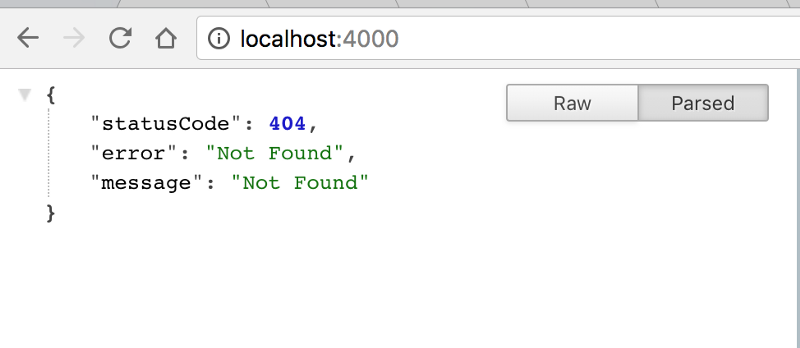
Что вполне нормально, так как сервер Hapi ожидает маршрут и обработчика. Подробнее об этом через секунду.
Давайте быстренько добавим скрипт для запуска нашего сервера с nodemon. Откройте package.json и отредактируйте скрипт.

Теперь мы можем двигаться дальше ?
Маршрутизация
Маршрутизация с Hapi очень интуитивна. Скажем, если нажать / , как вы думаете что произойдёт? Здесь играют роль три основных компонента.
- Какой путь? ―
path - Какой HTTP метод? Это
GET—POSTметод, или что-то другое? ―method - Что произойдёт, если маршрут будет пройден? ―
handler
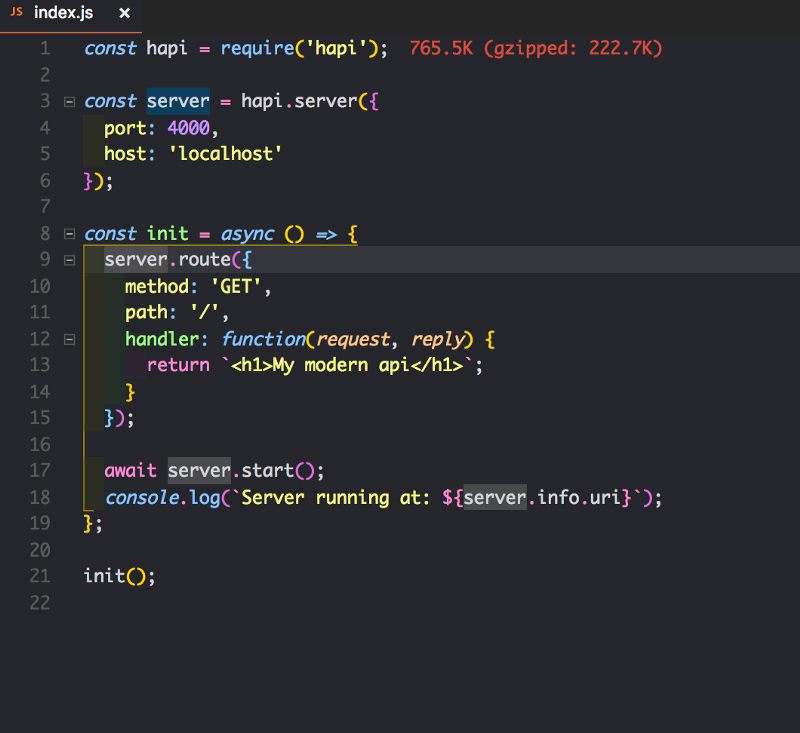
Внутри метода init мы присоединили новый метод к нашему серверу, названный route, с параметрами, в качестве аргумента.
Если мы обновим нашу страницу, то увидим возвращаемое значение root handler
Отлично, но мы можем сделать гораздо больше!
Настройка нашей базы данных
Далее мы настроим нашу базу данных. Будем использовать Mongodb и Mongoose.
Давайте посмотрим правде в глаза, писать для MongoDB валидацию, кастинг и бизнес-логику это тоска. Поэтому нам нужен Mongoose.
Следующий и последний ингредиент, связанный с нашей базой данных ― mlab. Вместо того, чтобы запускать mongo на нашем локальном компьютере, мы будем использовать облачного провайдера mlab.
Причина, по которой я выбрал mlab, заключается в бесплатном плане (полезно для прототипирования) и простоте его использования. Есть больше альтернатив, и я призываю вас изучить их все ❤
Регистрируйтесь на https://mlab.com/
Давайте создадим нашу базу данных и пользователя для неё. Это все, что мы будем редактировать в mlab.
Подключаем mongoose к mlab
Откройте index.js и добавьте следующие строки и учётные данные. Мы просто указываем mongoose, какую базу данных мы хотим подключить. Обязательно используйте свои учётные данные.
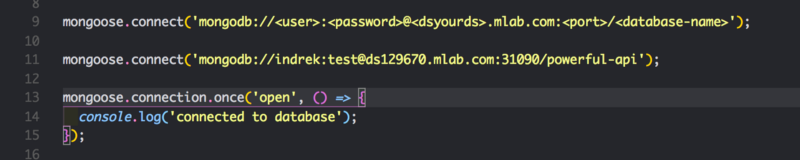
Если хотите освежить свои навыки MongoDB, здесь вы найдете целую серию уроков.
Если всё прошло гладко, мы должны увидеть в консоли сообщение ‘connected to database’
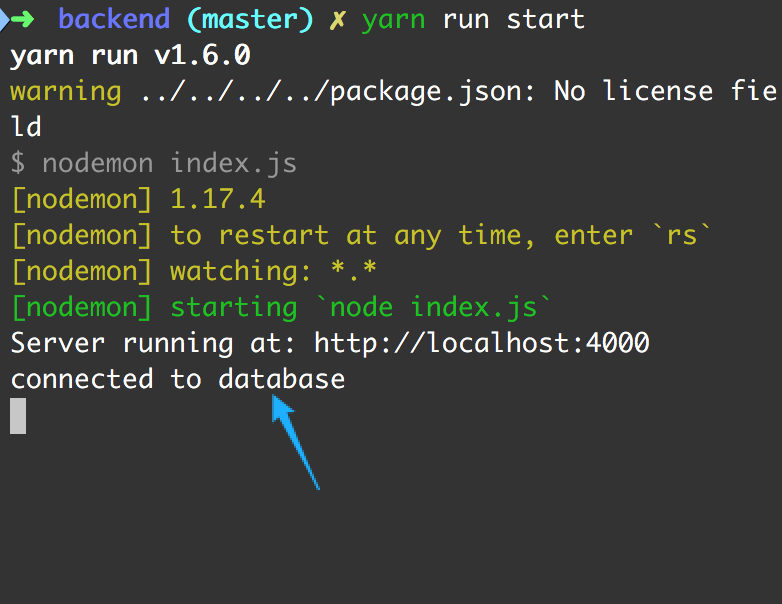
Фуух.
Хорошая работа! Сделайте небольшой перерыв и выпейте кофе. Скоро начнётся самое интересное.
Создаём модели
С mongoDB, мы придерживаемся модельного подхода. Другими словами — моделируем данные.

Это относительно простая концепция, которую легко понять. Мы просто объявляем нашу схему для коллекций. Коллекции можно рассматривать как таблицы в базе данных SQL.
Давайте создадим директорию с названием models. Внутри мы создадим файл Painting.js.
Painting.js ― наша модель картины. Файл будет содержать все данные, связанные с картинами. Вот как это будет выглядеть:
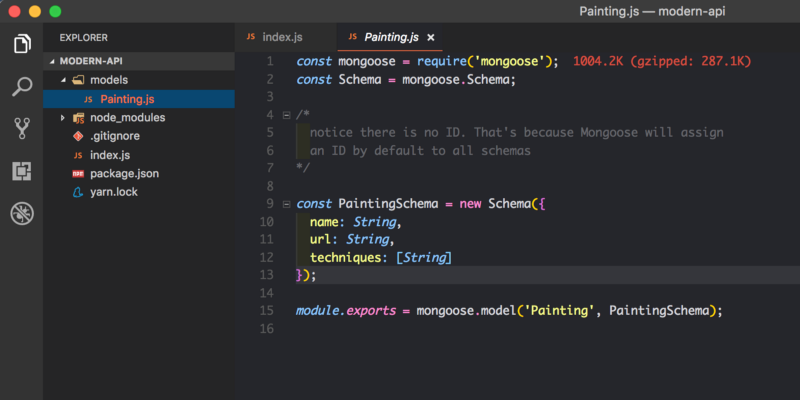
- Подключаем mongoose зависимости.
- Объявляем нашу
PaintingSchema, вызывая конструктор схемы mongoose, и передаём параметры. Обратите внимание на строгую типизацию: например, полеnameможет содержать строку, аtechniquesмассив строк. - Экспортируем модель и называем её
Painting.
Давайте извлечём все наши картины из базы данных
Сначала нам нужно импортировать модель Painting в index.js

Добавляем новые маршруты
В идеале, мы хотим иметь конечные точки URL, отражающие наши действия.
например, /api/v1/paintings — /api/v1/paintings/{id}, и так далее.
Давайте начнём с маршрута GET и POST. GET извлекает все картины, а POSTдобавляет новую.
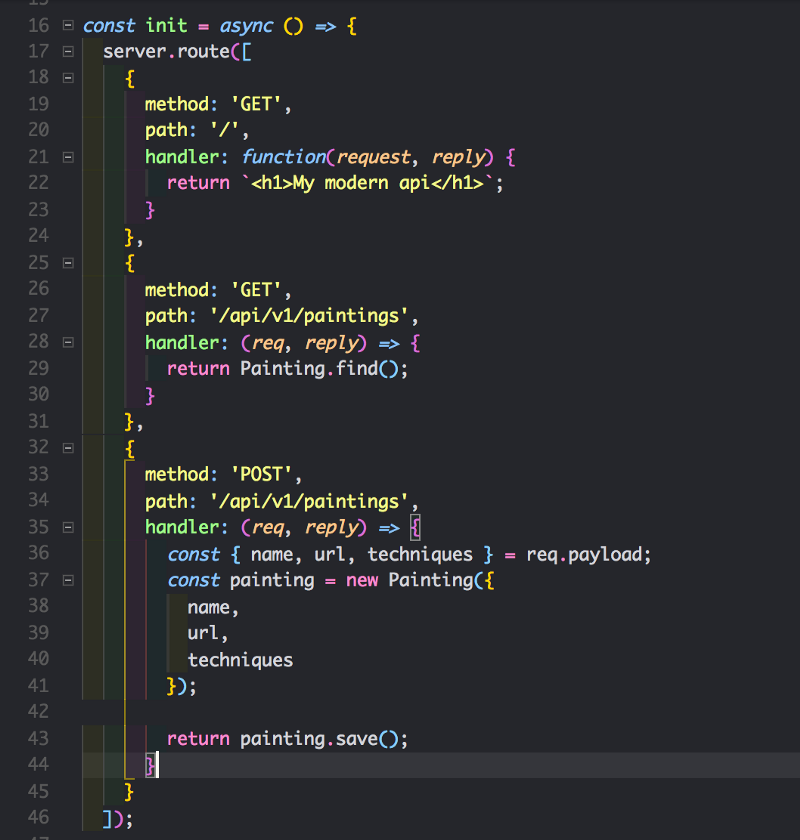
Обратите внимание, что мы изменили маршрут на массив объектов, вместо одного объекта. А ещё, стрелочные функции ?
- Мы создали
GETс путём /api/v1/paintings. Внутри обработчика, мы вызываем схему mongoose. У Mongoose есть встроенные методы, например удобный методfind(), который возвращает все картины, так как мы не указали условий поиска. Поэтому он возвращает все записи. - Также, мы создали
POSTдля того же пути. Потому что, мы следуем правилам REST. Давайте разберём обработчик маршрута. Помните, в нашей схемеPaintingмы объявили три поля:name—url—techniques
Здесь мы просто принимаем эти аргументы из запроса (сделаем это чуть позже с помощью Postman) и передаём их в схему mongoose. После завершения передачи аргументов мы вызываем метод save() для нашей новой записи, который сохраняет её в базу данных mlab.
Если мы перейдём по ссылке http://localhost:4000/api/v1/paintings, то увидим пустой массив.
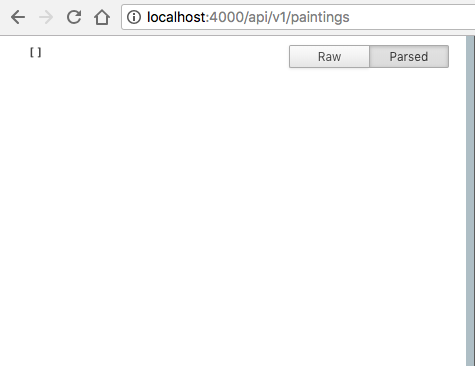
Почему пустой? Мы ведь ещё не добавили никаких записей. Давайте сделаем это прямо сейчас!

Установите Postman и откройте его, он доступен для всех платформ.
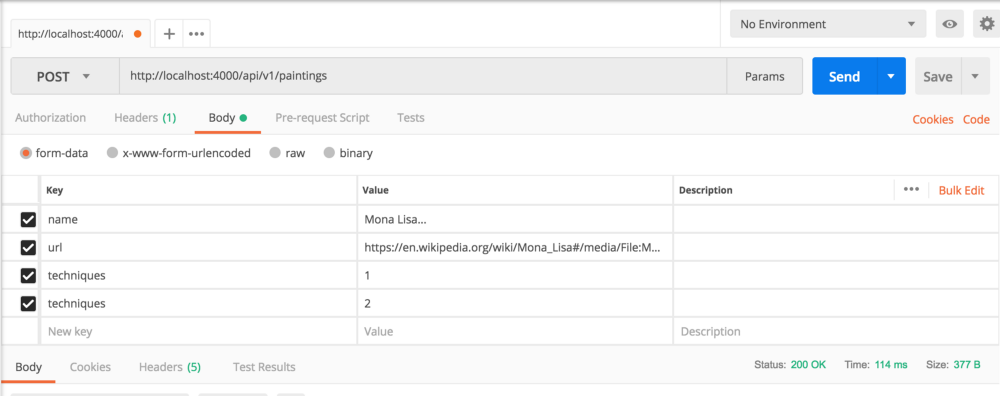
- В левом углу можно выбрать метод. Выберете
POST. - Рядом с методом
POSTу нас есть поле URL. Это адрес, на который мы отправим наш метод. - Справа есть синяя кнопка, которая отправляет запрос.
- Ниже поля URL можно выбрать опции. Нажмите на body и заполните поля, как в примере.
{
"name": "Mona Lisa",
"url": "https://en.wikipedia.org/wiki/Mona_Lisa#/media/File:Mona_Lisa,_by_Leonardo_da_Vinci,_from_C2RMF_retouched.jpg",
"techniques": ["Portrait"]
}
Давайте откроем ссылку http://localhost:4000/api/v1/paintings
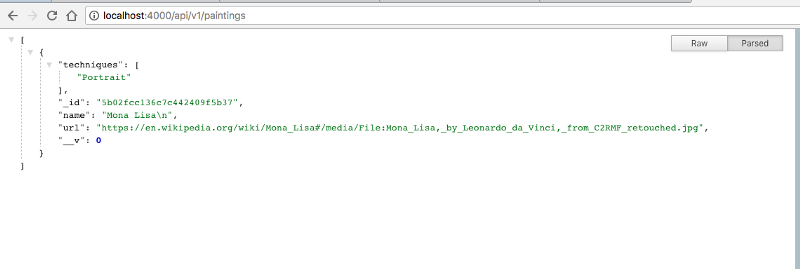
Отлично! Нам ещё многое предстоит сделать! На очереди — GraphQL!
Вот исходный код на случай, если он кому-то понадобится 🙂
Перевод статьи: Indrek Lasn How to set-up a powerful API with Nodejs, GraphQL, MongoDB, Hapi, and Swagger





