
Pandas может делать все. Практически все. Но (как бы ни хотелось, чтобы было иначе) ему не хватает скорости. Pandas просто не поспевает за темпами, соответствующими увеличению объемов и сложности современных наборов данных.
Создатель Pandas Уэс Маккинни утверждает, что придерживался следующего правила при разработке своей библиотеки:
Объем оперативной памяти должен в 5–10 раз превышать объем набора данных.
Возможно, вы игнорировали это правило, когда набор данных Iris только появился, но сегодня все иначе. Вы просто не сможете загрузить набор данных объемом 100 ГБ (что уже обычное дело в наше время), если ваша оперативная память строго ограничена 64 ГБ.
Конечно, есть отличные альтернативы, такие как Dask. Но Dask не реализует новую функциональность. Он растягивает синтаксис Pandas на несколько процессов (потоков) и игнорирует основные проблемы производительности и памяти.
Polars, о котором пойдет речь в этой статье, был написан на языке Rust с нуля, чтобы исправить все недостатки Pandas. Он уже быстрее, чем готовящийся к выпуску Pandas 2.0 с PyArrow-бекэндом.
Сосредоточимся на синтаксисе и функциональности Polars и посмотрим, как совершить переход с Pandas на Polars за семь простых шагов, чтобы, возможно, никогда больше не пользоваться Pandas.
0. Чтение/запись данных
CSV, несмотря на свою досадную медлительность, по-прежнему является одним из самых популярных форматов файлов для хранения данных. Итак, начнем с функции read_csv в Polars.
Кроме очевидного преимущества в скорости, она отличается от своего “собрата” из Pandas только количеством параметров (у Pandas в read_csv их 49) и синтаксисом.
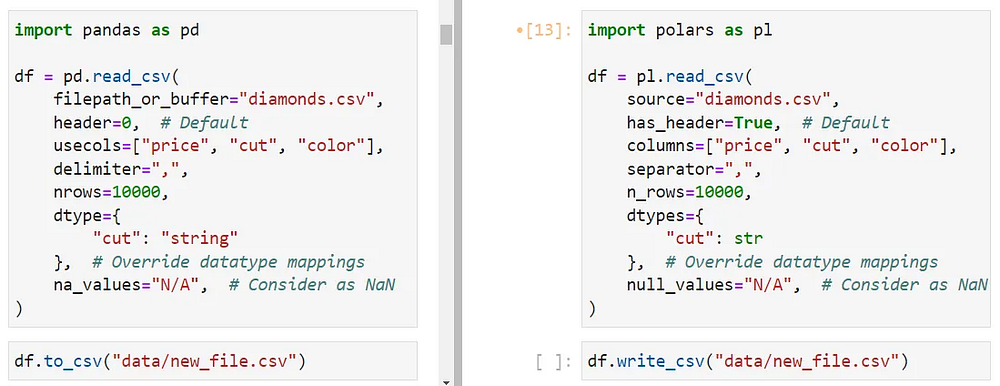
Названия параметров не должны быть проблемой, так как большинство современных IDE имеют функции заполнения вкладок или всплывающей документации (например, шорткат Shift + Tab в JupyterLab).
Если вы не знали, параметр dtype не позволяет Pandas устанавливать автоматические типы данных, предоставляя пользователю возможность задавать собственные, например тип string для cut и datetime для столбцов типа date.
Вы можете использовать то же поведение в Polars с помощью dtypes (обратите внимание на “s”), хотя он не позволяет задавать типы через строки. Вам придется предоставить либо встроенные типы Python, либо типы Polars, такие как pl.Boolean, pl.Categorical, pl.DateTime, pl.Int64 и pl.Null для отсутствующих значений. Полный список можно посмотреть, вызвав dir(pl).
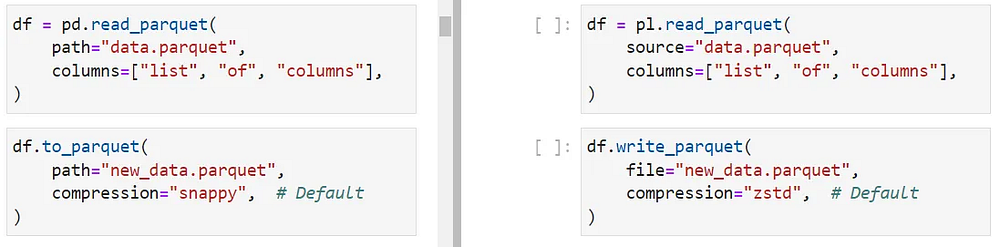
Чтение и запись файлов Parquet, которые намного быстрее и экономнее расходуют память, чем CSV, также поддерживаются в Polars с помощью функций read_parquet и write_parquet.
1. Создание структур данных Series и DataFrames
Чтение данных из файлов применяется не всегда. Как и в Pandas, в Polars можно создавать DataFrames и Series с нуля, а синтаксис практически идентичен:
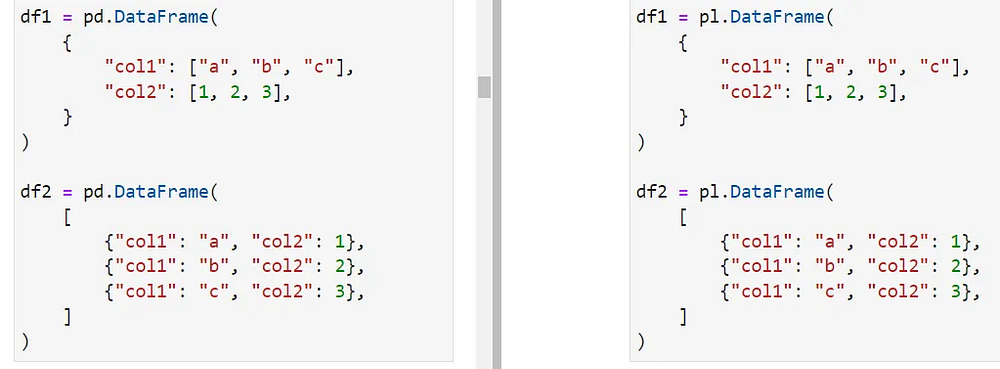
В Polars также есть много имен и методов DataFrames, по поведению (почти) идентичных DataFrames в Pandas. Итак, встречайте:
apply(применение пользовательских функций к каждой строке DataFrame);corr(корреляционная матрица);describe(сводная статистика, сводка из 5 чисел);drop(удаление столбцов из DataFrame);explode(распаковка заданного столбца в длинный формат; когда ячейки содержат несколько значений, например[1, 2, 3]);head,tailиsample(n)(получение различных представлений DataFrame: верхнее, нижнее, случайное);iter_rows(возвращает итератор строк DataFrame, содержащих значения на языке Python);max,mean,median,sum,stdи обычный комплект распространенных математических и статистических функций.
Полный список методов DataFrame в Polars смотрите на этой странице документации.
2. Понимание выражений в Polars
В основе Polars лежит система обработки запросов, которая работает с пользовательскими выражениями. Система обработки запросов и выражения — два важнейших компонента, обеспечивающих молниеносную производительность, которой свойственен, как сказано в руководстве пользователя Polars, “поразительный параллелизм”.
Вы будете шокированы тем, насколько выражения Polars напоминают SQL, сохраняя при этом прочную связь со знакомым синтаксисом Pandas.
Подобно SQL-запросам, вы можете писать выражения для решения многих задач, включая:
- создание новых столбцов из существующих;
- получение представлений данных после некоторого преобразования;
- сводная статистика;
- обработка и очистка данных;
- использование операторов GroupBy
df.filter(pl.col('column') == 'some_value')
В приведенном выше запросе выражением является pl.col('column)' == 'some_value', и оно, как вы догадались, фильтрует DataFrame по строкам, где column равен some_value.
Когда вы запустите это выражение само по себе, вы не получите булеву структуру Series, как это было бы в Pandas:
type(pl.col("column") == "some_value")
polars.expr.expr.Expr
Это потому, что выражения оцениваются только в соответствии с определенными контекстами. В Polars есть три основных контекста:
- Выборка данных (Selecting data). В контексте
selectвыражения применяются к столбцам и должны создавать столбцы одинаковой длины в результате. Это поведение должно быть знакомо вам еще со времен работы с SQL. Функцияfilterтакже привязана к этому контексту. - Группирование данных (Grouping data). В контексте
groupbyвыражения работают над группами, а результаты могут иметь любую длину, поскольку группа может иметь много членов. - Добавление новых столбцов (Adding new columns). В этом контексте выражения используются для создания новых столбцов с нуля или из уже существующих.
Рассмотрим каждый контекст подробнее.
3. Выборка данных
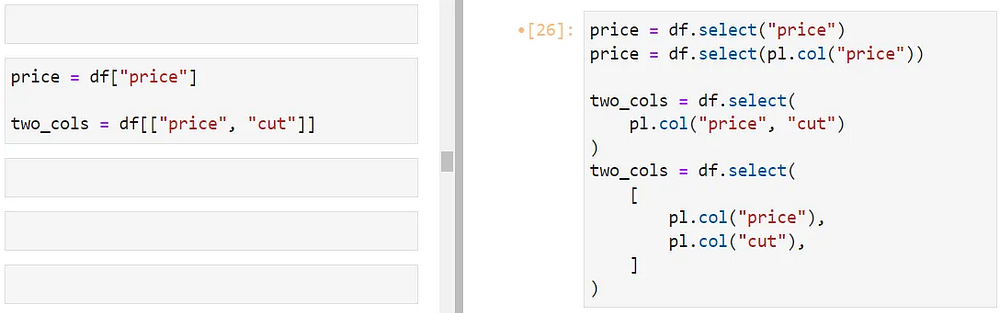
Нотация скобок в Pandas уступает место выражениям в Polars для выбора столбцов.
Чтобы выбрать один столбец, можно использовать его литеральное имя внутри select или воспользоваться рекомендуемой функцией pl.col для ссылки на столбцы.
Для множественного выбора можно перечислить имена столбцов через запятую внутри pl.col или в виде списка pl.col-ссылок внутри select. Различия между этими синтаксисами рассмотрим чуть позже.
Для выбора данных Polars предлагает функциональность, недоступную в таком объеме в Pandas. Например, в Polars можно исключить столбцы из выборки с помощью exclude:
df.select(pl.exclude("price")).head()

Можно также использовать регулярные выражения между символами ^ и $. Ниже показано, как выбрать все столбцы, которые начинаются с буквы c:
df.select(pl.col("^c.+$")).head()

Polars предоставляет возможность разбить на подмножества DataFrame на основе типа данных, что может напомнить вам select_dtypes из Pandas (слева):
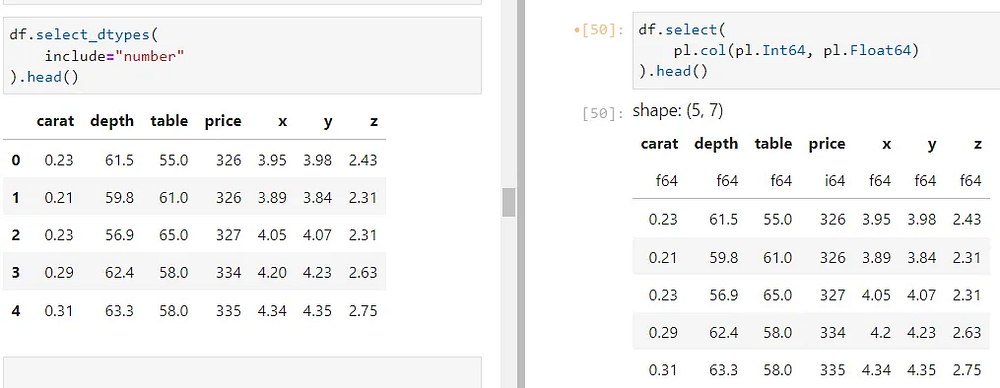
Чтобы выбрать все числовые столбцы, используем типы Int64 и Float64 внутри pl.col.
4. Фильтрация данных
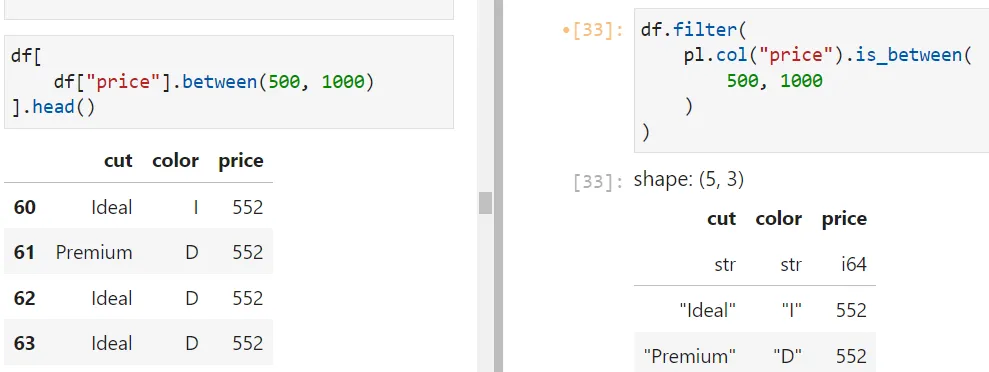
В Polars можно использовать функцию filter для разбития DataFrames на подмножества с булевым индексированием. Например, использование функции is_between для столбца создает выражение для фильтрации числовых столбцов в определенном диапазоне.
Вы можете объединить несколько условных выражений с помощью знакомых булевых операторов & (AND) и | (OR). В приведенном ниже примере выбираем строки, в которых столбец color (цвет) имеет значение либо ‘E’, либо ‘J’, а price (цена бриллиантов) ниже 500:
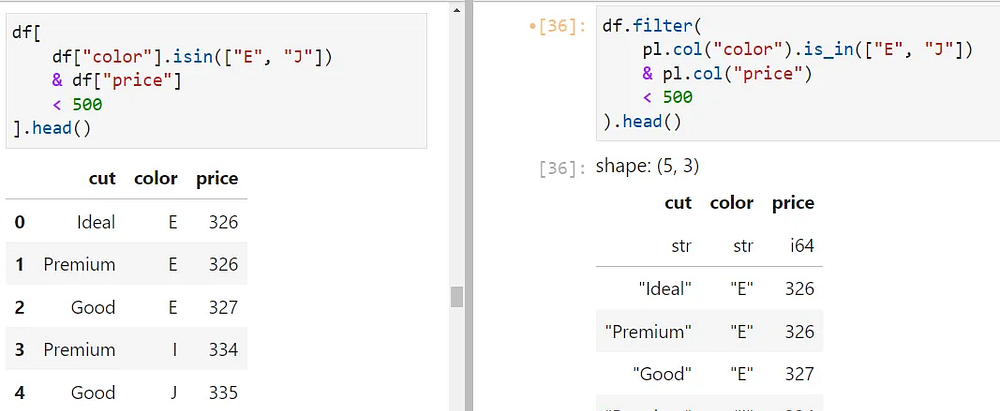
Обратите также внимание, как используется is_in в Polars (справа).
5. Создание новых столбцов
В Polars можно создавать новые столбцы в контексте with_columns. В примере ниже new_col определяется с помощью pl.col('price') ** 2. Столбцу также присваивается псевдоним, и так он получает имя (та же функция, что и у ключевого слова as в SQL).
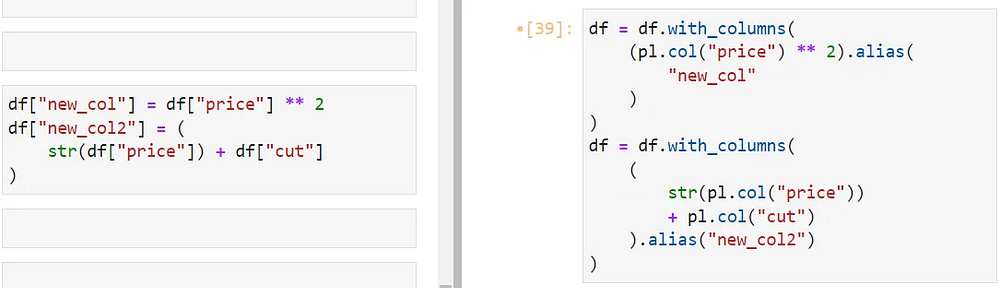
Во втором примере объединяем два столбца (хотя это и не имеет смысла), чтобы продемонстрировать, как с помощью Polars можно объединять целочисленные и строковые столбцы. Вы можете использовать любые нативные функции и операторы Python или сторонних разработчиков для столбцов, на которые ссылается pl.col.
Если хотите, чтобы новый столбец был вставлен в DataFrame, переопределите исходную переменную df.
Строковые колонки в Polars имеют знакомый интерфейс
.strдля специальных функций работы с текстом, таких какcontainsиlengths. Полный список можно посмотреть здесь. Есть также интерфейсы.cat,.dtи.arrдля специализированных категориальных, временных функций и функций работы с массивами.
6. Функция groupby
Не думаю, что можно обойтись без упоминания операций Groupby:
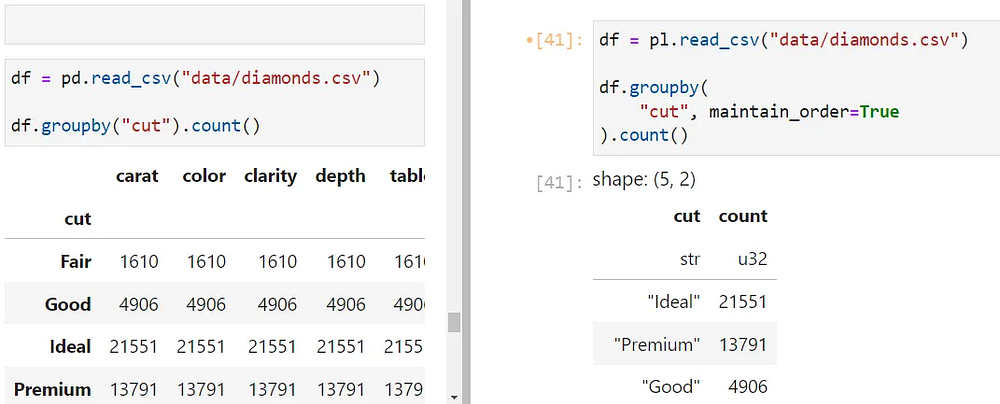
При использовании функции groupby в Polars не забудьте указать maintain_order=True, чтобы группы не отображались беспорядочно. Также, в отличие от Pandas, выражение groupby(col_name) работает только с заданным столбцом. Чтобы сгруппировать все столбцы по col_name, необходимо использовать контекст aggregation. Вот его синтаксис:
df.groupby(
"cut", maintain_order=True
).agg(pl.col("*").count())
После контекста groupby подключаете контекст aggregation и указываете, какие столбцы он затрагивает. Затем подключаете любую функцию к результату, например count.
Вот еще один пример, в котором показана группировка по качеству огранки бриллиантов и возвращается среднее числовое значение для каждой группы:
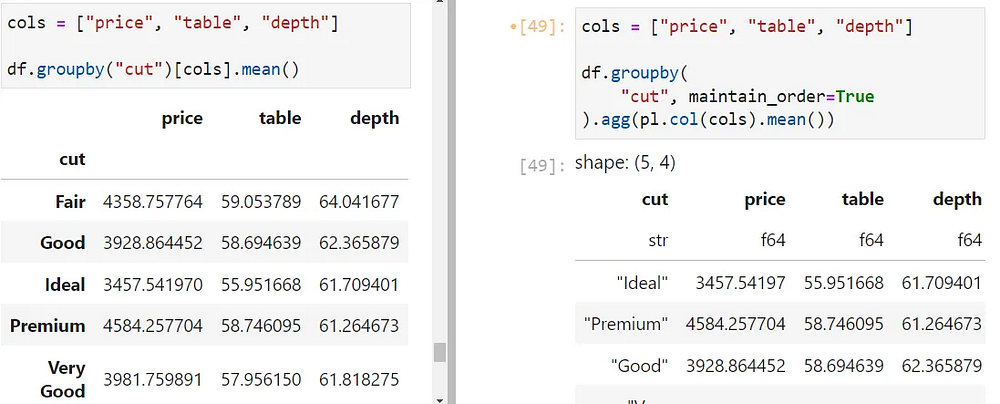
Чтобы узнать больше о расширенных выражениях groupby в Polars, перейдите по этой ссылке.
7. Ленивый API в Polars
Одна из крутых особенностей Polars — ленивый API. В нем запросы не выполняются построчно, а обрабатываются системой обработки запросов по методу “из конца в конец”.
Именно здесь мы видим оптимизацию запросов и магию поразительного параллелизма. Можно перевести любое выражение, написанное в режиме eager, в ленивый режим с помощью всего двух ключевых слов:
import polars as pl
df = pl.read_csv("data/diamonds.csv")
query = df.lazy().filter(
pl.col("cut") == "Ideal"
)
type(query)
polars.lazyframe.frame.LazyFrame
При добавлении функции lazy() перед подключением выражения к цепочке, DataFrame становится LazyFrame. В этот момент запрос не выполняется, и можно соединить в цепочку еще несколько выражений. Когда все готово, вызываете функцию collect(), чтобы получить результат:
query.collect().head()
В режиме eager в Polars работа и так идет быстро, а ленивый режим добавляет системе обработки запросов дополнительное (тройное) ускорение.
Если хотите сделать ленивый API настройкой по умолчанию, используйте функции scan_* при чтении данных вместо read_*:
df = pl.scan_csv("data/diamonds.csv")
q1 = df.filter(
pl.col("cut") == "Ideal"
)
q1.collect().head()
Таким образом, вам не придется каждый раз писать функцию lazy().
Если набор данных превышает возможности вашей оперативной памяти, можно использовать потоковую передачу, при которой Polars будет обрабатывать данные партиями. Эта функция включается в lazy API установкой streaming=True внутри collect. Узнайте больше об этой функции здесь.
Заключение
Polars пока новичок (я имею в виду, что он только осваивается в мире программирования), но уже очень популярен. Только взгляните на его конкурентов в категории общедоступного ПО:
- Pandas, выпущенный в 2011 году, имеет 37,5 тыс. звезд на GitHub.
- Apache Spark, выпущенный в 2014 году, имеет 26,8 тыс. звезд.
- Vaex, выпущенный в 2017 году, имеет 7,9 тыс. звезд.
- Dask, выпущенный в 2015 году, имеет 10,9 тыс. звезд.
- Apache Arrow, выпущенный в 2016 году, имеет 11,4 тыс. звезд.
Для сравнения: Polars был выпущен в 2020 году и уже набрал 15,9 тыс. звезд, то есть уже находится на полпути к своим конкурентам.
Возможно, ситуация изменится, когда выйдет Pandas 2.0, но, на мой взгляд, Polars уже сейчас является достойным соперником Pandas.
Читайте также:
- 4 альтернативы Pandas: ускоренное выполнение анализа данных
- Быстрый веб-скрейпинг с библиотекой Polars
- 12 декораторов Python, которые улучшают код
Читайте нас в Telegram, VK и Дзен
Перевод статьи Bex T.: 7 Easy Steps To Switch From Pandas to Lightning Fast Polars And Never Return
 улучшить написание кода на Swift")




