
Вступление
В этой статье мы научились оркестрации контейнерных приложений с Docker Swarm. Теперь развернем ту же архитектуру с другой ведущей платформой оркестрации, Kubernetes.
Что будем создавать?
- Среду Kubernetes с одним ведущим узлом/узлом плоскости управления и тремя рабочими узлами, используя minikube.
- deployment приложения на Kubernetes для развертывания 3-уровневой архитектуры приложений с Web/Apache, Node.js и базой данных Postgres.
В этой демоверсии нет исходного кода. Акцент делается на архитектуре и инфраструктуре приложения.
Что понадобится
- Освежить в памяти эту статью о Docker Swarm.
- Знание систем и команд Linux, контейнеров Docker и таких методов оркестрации, как Docker Compose и Swarm.
- Установленный на компьютере Docker.
- Доступ к инструменту командной строки.
Что такое Kubernetes?
Это один из ведущих инструментов оркестрации контейнеров, но для более крупных и сложных рабочих нагрузок приложений, чем Docker Swarm. У Kubernetes гораздо больше гибкости, масштабируемости, надежности и специфичности развертывания рабочих нагрузок.
Значит, Kubernetes лучше Docker Swarm?
Необязательно. Хотя Docker Swarm легковеснее, он часто считается более простым в использовании и масштабировании. Как и все в мире технологий, это зависит от конкретного применения и от того, что вы пытаетесь создать.
Ключевые отличия
В Kubernetes поверх Docker добавляется уровень абстракции, поэтому здесь имеется собственный набор API для создания сетей, контейнеров и томов. Как и в docker, доступ к движку API получается через интерфейс командной строки kubectl.
Поды
Поды — базовая единица развертывания. Это почти как службы/контейнеры в Swarm, только со слоем абстракции. Внутри узла может быть несколько подов, а внутри пода — несколько контейнеров. Немного запутанно, но просто знайте: когда говорят «поды», думают о контейнерах.
Службы
В Swarm службой называются определения и развертывания контейнеров/задач. В Kubernetes службой называется сеть и стабильная конечная точка/адрес для взаимодействия подов друг с другом или со внешними службами. Имеется три основных типа служб: ClusterIP, NodePort и LoadBalancer.
Установка minikube и Hyperkit
Для создания контейнерного приложения нужна локальная среда разработки. minikube — отличный инструмент с уже установленным kubectl для реализации многоузловых кластеров Kubernetes локально на компьютерах.
Устанавливайте minikube, как считаете нужным. Для моей macOS проще диспетчером пакетов Homebrew, им устанавливается и среда виртуальной машины.
brew install minikube
Чтобы запустить многоузловой кластер локально, для minikube нужен драйвер виртуальной машины Hyperkit, VirtualBox или Parallels. Установим Hyperkit:
brew install hyperkit
Настройка кластера
Контейнерные рабочие нагрузки запускаются в «узлах», то есть физических или виртуальных машинах/серверах, где обеспечиваются высокая доступность и отказоустойчивость.
В Swarm узлам присваиваются управляющие или рабочие роли. В Kubernetes принцип тот же, но узлы разделены на роли плоскости управления со всеми ведущими узлами и рабочие роли.
Настроим кластер в minikube:
- Один ведущий узел/узел плоскости управления.
- Три рабочих узла.
В minikube по умолчанию локальной машине присваивается ведущий узел/узел плоскости управления, всем остальным — рабочие узлы.
minikube start --driver hyperkit --nodes 4

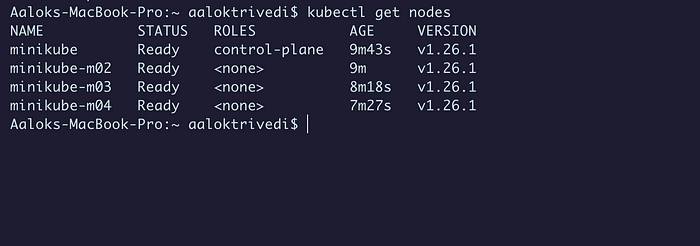
Получаем узлы:
kubectl get nodes
Ограничение присваивания подов
Поды планируются только в рабочих узлах, поэтому добавим в плоскость управления специальные инструкции в виде запрета на размещение подов. Этим запретом отклоняется набор подов для узла: планировщику указывается не планировать поды, если у них нет соответствующего допуска.
kubectl taint nodes node_name key1=value1:NoSchedule
Развертывание уровня фронтенда/веба
Вся инфраструктура приложения развертывается одним файлом YAML, аналогичным Docker Compose. Но YAML-файлы Kubernetes немного сложнее и подробнее. Управлять конфигурациями развертывания проще, если разделить их на хорошо организованные файлы.
Начнем с уровня фронтенда/веба и развернем поды, в которых содержатся веб-серверы Apache:
Служба фронтенда/веба
В Docker служба — это образ или тип образа, запускаемый в контейнере Apache, NGINX, Node, Postgres и т. д. Фактически это описание и роль разворачиваемого в кластере контейнера или задачи.
Службой в Kubernetes называется сеть и стабильная конечная точка / адрес для взаимодействия подов между собой или с внешними службами. Имеется три основных типа служб: ClusterIP, NodePort и LoadBalancer.
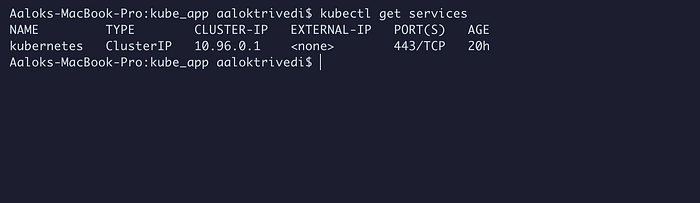
В ClusterIP создаются виртуальные IP-адреса для взаимодействия подов друг с другом. Это служба по умолчанию, предоставляется кластеру для взаимодействия узлов плоскости управления с рабочими узлами:
kubectl get services
С помощью NodePort в плоскости управления указываются и выделяются конкретные порты для внешнего доступа. Этот тип службы понадобится для доступа к сайту через порт 80.
Создадим новый YAML-файл frontend-kube-app.yml:
apiVersion: v1
kind: Service
metadata:
name: web-httpd-service
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
app: web-httpd
---
Каждый объект или kind относится к определенной группе API, поэтому важно знать указываемую apiVersion. Версия объекта находится командой:
kubectl api-resources
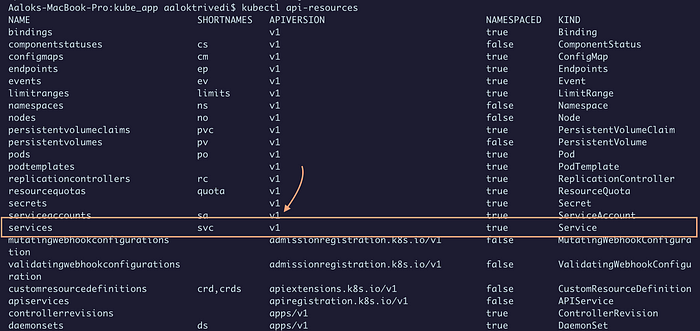
В metadata даем службе имя — это обязательно.
В type указываем Nodeport и порт 80.
Очень важны метки и понятие selector, используемое в службе для разрешения трафика подам с соответствующими метками.
Символом --- обозначается конец объекта и разрыв.
Рекомендуем получать подробные сведения о каждом разделе объекта не из документации, а командой
explain. Например, с применением точечной записи детализировать конкретные области. Так сkubectl explain service.specполучаем объяснение каждой опции этой категории.
Развертывание фронтенда/веба
Deployment похожи на службы Docker. Это набор инструкций и спецификаций для подов: образ, количество реплик, порты, политики перезапуска и т. д.
В объекте service того же файла создаем Deployment:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-httpd-deployment
spec:
selector:
matchLabels:
app: web-httpd
replicas: 10
template:
metadata:
labels:
app: web-httpd
spec:
containers:
- name: web-httpd
image: httpd:2.4.55
ports:
- containerPort: 80
Deployment довольно простой, но со спецификациями поподробнее он немного сложнее.
Развертывания с подами находятся в kind: Deployment, с собственной группой API. А в разделе selector у matchlabel то же имя, что у селектора web-httpd-service: они подключаются друг к другу.
В template указываются сведения о контейнере: имя, образ, порт.
Развертывание подов и службы
Теперь самое простое. Применяем конфигурацию и указываем на файл YAML:
kubectl apply -f ./frontend/frontend-kube-app.yml
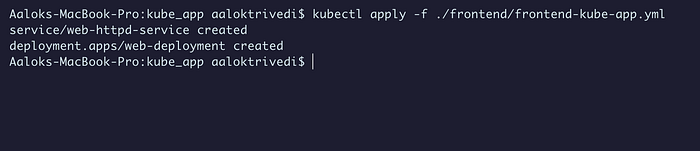
Командой kubectl get all -o wide получаем все данные о службе и поде для кластера:
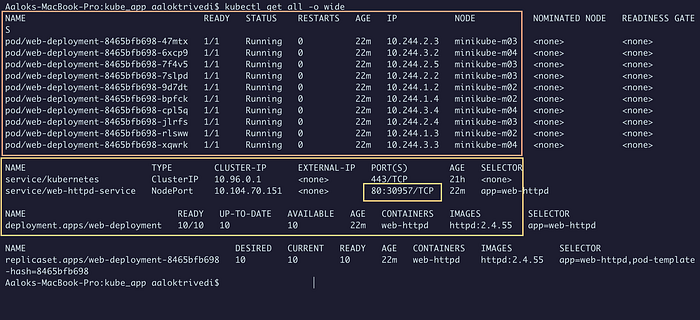
Все десять подов готовы к работе, их нет в ведущем узле/узле плоскости управления.
Зато имеется служба NodePort и сопоставление ее портов. Возможен ли доступ к веб-серверу по любому из IP-адресов узла с портом NodePort? Его номер — справа. IP-адрес узла получаем командой kubectl get nodes -o wide:
Так мы развернули в кластере первые поды Kubernetes.
Развертывание уровня бэкенда/приложения
Первый уровень готов, он практически многоразовый — меняются только спецификации в соответствии с задачами приложения.
Пока нет исходного кода и ничего подключать не нужно, сделаем для бэкенда приложения простой Deployment. В каталоге backend создаем новый YAML-файл backend-kube-app.yml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nodejs-app-deployment
spec:
selector:
matchLabels:
app: nodejs-app
replicas: 4
template:
metadata:
labels:
app: nodejs-app
spec:
containers:
- name: nodejs-app
image: node:19-alpine3.16
command: ["sleep", "100000"]
Вводим в command sleep для целей тестирования: контейнер останется открытым и запущенным.
Снова запускаем команду apply и получаем результаты:
kubectl apply -f ./backend/backend-kube-app.yml
kubectl get all -o wide
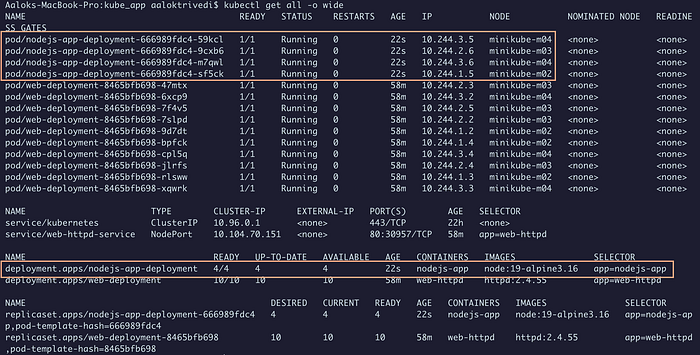
4/4 подготовленных пода запущены.
Развертывание уровня бэкенда / базы данных
Заключительный этап — развертывание базы данных Postgres приложения. Она чуть сложнее, вот что понадобится.
ConfigMapдля хранения секретов: имен пользователей и паролей.PersistantVolumeиPersistantVolumeClaimдля определения и выделения хранилища для базы данных A.Serviceдля подключения БД.Deploymentдля определения и развертывания пода БД в кластере.
Создаем ConfigMap
Данные всегда лучше отделять от кода, и если в разработке, то с ConfigMap. В Kubernetes для этого имеется собственная группа API.
В каталоге БД создаем новый YAML-файл postgres-config.yml:
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-config
labels:
app: postgres-db
data:
POSTGRES_DB: postgresdb
POSTGRES_USER: admin
POSTGRES_PASSWORD: mypass
Здесь сохранятся переменные окружения: имя БД, пользователь и пароль. Опять же, важны метки labels: они понадобятся Deployment для подключения к конфигурации.
Применяем ConfigMap к кластеру:
kubectl apply -f ./database/postgres-config.yml
Создаем PersistantVolume и PersistantVolumeClaim
Поды временны, с ними исчезают все их данные, поэтому для БД понадобится постоянное хранилище. Здесь мы определим емкость, доступ и hostPath тома.
После создания тома понадобится PersistantVolumeClaim, которым определяется, как пользователи запрашивают и потребляют ресурсы PV.
Создаем новый YAML-файл postgres-pvc-pv.yml:
kind: PersistentVolume
apiVersion: v1
metadata:
name: postgres-pv-volume # Задается имя PV
labels:
type: local # Тип PV задается local
app: postgres-db
spec:
storageClassName: manual
capacity:
storage: 5Gi # Задается том PV
accessModes:
- ReadWriteMany
hostPath:
path: "/mnt/data"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: postgres-pv-claim # Задается имя PVC
labels:
app: postgres-db
spec:
storageClassName: manual
accessModes:
- ReadWriteMany # Задается доступ для чтения и записи
resources:
requests:
storage: 5Gi # Задается размер тома
Применяем PV и PVC к кластеру:
kubectl apply -f ./database/postgres-pvc-pv.yml
Создаем службу
Создадим пока только простую службу NodePort с указанием порта 5432.
Создаем новый YAML-файл database-kube-app.yml:
apiVersion: v1
kind: Service
metadata:
name: postgres # Задается имя службы
labels:
app: postgres-db # Метки и селекторы
spec:
type: NodePort # Задается тип службы
ports:
- port: 5432 # Задается порт для запуска приложения postgres
selector:
app: postgres-db
---
Создаем Deployment
В том же файле создадим параметры развертывания для БД Postgres:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-db-deployment # Задается имя Deployment
spec:
replicas: 1
selector:
matchLabels:
app: postgres-db
template:
metadata:
labels:
app: postgres-db
spec:
containers:
- name: postgres-db
image: postgres:10.1 # Задается образ
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 5432 # Указывается порт контейнера
envFrom:
- configMapRef: # Сопоставляется переменная окружения из ConfigMap
name: postgres-config
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: postgres-volume
volumes:
- name: postgres-volume
persistentVolumeClaim:
claimName: postgres-pv-claim # Сопоставляется утверждение из PersistantVolumeClaim
Переменные окружения envFrom и тома из конфигурации и PVC сопоставляются, в этом проявляется важность имен и меток.
Применяем службу и Deployment к кластеру:
kubectl apply -f ./database/postgres-pvc-pv.yml
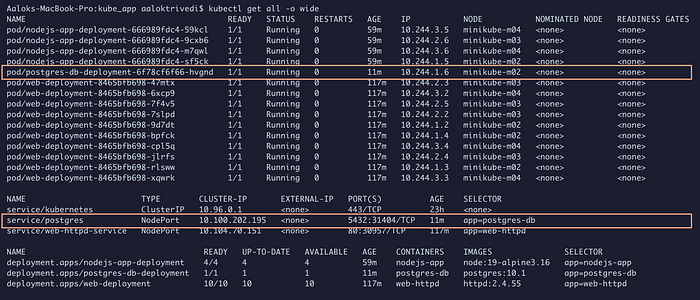
Тестируем подключение к базе данных
Наконец, проверяем подключение:
kubectl exec -it [pod-name] -- psql -h localhost -U admin --password -p 5432 postgresdb
Чтобы получить список всех БД, вводим пароль БД и \l:
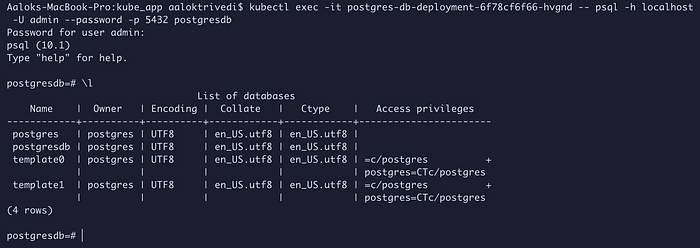
Подключение имеется.
Мы развернули высокодоступную, отказоустойчивую инфраструктуру приложения с Kubernetes. Возможность упаковать ее и импортировать в любую среду с минимальными изменениями или вообще без них — вот в чем прелесть Kubernetes и контейнерных приложений в целом.
Удаление
По завершении запускаем minikube stop для остановки среды или minikube delete для удаления всех ресурсов.
Читайте также:
- Развертывание Kubernetes с пользовательским файлом index.html в поде Nginx с ConfigMap
- Развертывание фронтенда и бэкенда приложения на Kubernetes
- Kubernetes избавляется от Docker
Читайте нас в Telegram, VK и Дзен
Перевод статьи Aalok Trivedi: Using Kubernetes to deploy a 3-tier containerized application infrastructure





