
Простота языка SQL обманчива. Многие его диалекты позволяют пользователям делать запросы к базам данных, используя синтаксис, похожий на английский. Казалось бы, что ожидаешь, то и получаешь… или нет?
Время от времени я сталкиваюсь с запросом, который выдает результат, совершенно отличный от предполагаемого. Так SQL знакомит меня со своими тонкими нюансами. В этой статье поделюсь тремя головоломками, попавшимися мне недавно. Чтобы было интереснее, оформил их в виде загадок. Попробуйте разгадать их до прочтения каждого раздела до конца!
Для создания таблиц в каждом примере я использовал обобщенные табличные выражения (CTE, Common Table Expressions), так что вам не придется запрашивать производственные таблицы вашей компании! Но если вы хотите освоить SQL, рекомендую создать собственную базу данных и таблицы для экспериментирования.
Обратите внимание на то, что все запросы составлены в Postgres. При использовании другого диалекта вы можете получить другие результаты. Наконец, последнее важное замечание: фактические данные и темы в каждом запросе являются лишь иллюстративными примерами.
Загадка 1. Специфика временной метки
Представьте, что у вас есть таблица под названием purchases (закупки) со столбцами id (идентификатор закупки), amount (денежная сумма) и dt (время совершения закупки). Допустим, она выглядит следующим образом:
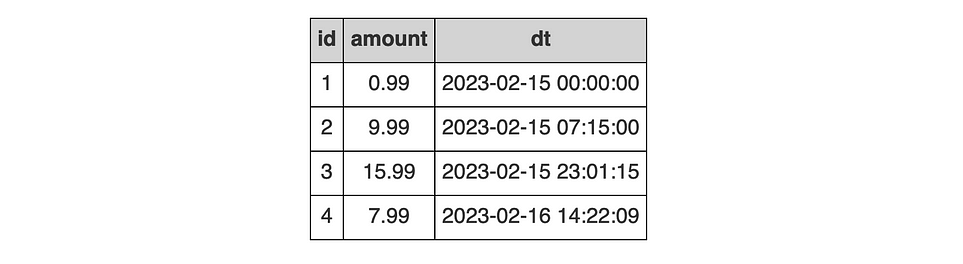
В виде CTE это будет выглядеть примерно так. Обратите внимание на два момента. Во-первых, необходимо указать, что столбец dt является временной меткой (timestamp), чтобы он не интерпретировался как строка. Во-вторых, типы данных можно указать только для одной из строк, а остальные данные являются предполагаемыми.
WITH purchases(id, amount, dt) AS (
VALUES
(1::bigint, 0.99::float, '2023-02-15 00:00:00 GMT'::timestamp),
(2, 9.99, '2023-02-15 07:15:00 GMT'),
(3, 15.99, '2023-02-15 23:01:15 GMT'),
(4, 7.99, '2023-02-16 14:22:09 GMT')
)
...
Теперь подсчитаем сумму закупок, совершенных 15 февраля. Можно написать запрос, подобный приведенному ниже:
...
SELECT
SUM(amount) AS sum
FROM purchases
WHERE
dt = '2023-02-15'
Загадочным образом получаем следующий ответ:

Что произошло? 15 февраля было совершено три закупки с идентификаторами 1, 2 и 3. Поэтому сумма должна быть $26,97. Вместо этого, была учтена только первая закупка.
Подсказка
Если изменить фильтр на 2023-02-16, то не будет возвращено ни одной строки.
Ответ
Формат столбца dt — это временная метка, которая включает как дату, так и время. Фильтр WHERE указывает только дату. Вместо того чтобы отклонить этот запрос, Postgres автоматически переформатирует строку даты в 2023-02-15 00:00:00, что соответствует только первой транзакции в таблице. Поэтому мы получили только сумму одной строки.
Чтобы выбрать все строки, соответствующие 15 февраля, нужно сначала привести временную метку к дате.
SELECT
SUM(amount) AS sum
FROM purchases
WHERE
DATE(dt) = '2023-02-15'
На этот раз получаем ожидаемый результат:

Загадка 2. Зависимые и независимые фильтры
Итак, следующая загадка. У вас есть таблица users (пользователи) со столбцами: “no_login_l28” (“не заходил на сайт в течение последних 28 дней”), “has_never_posted” (“никогда не создавал публикации”) и “is_new_account” (“является новым пользователем”).
Ваша задача — удалить все строки, которые удовлетворяют любому из трех условий. Возьмем для примера таблицу ниже. Допустим, вам нужно вернуть только постоянных и активных пользователей, то есть тех, кто заходил на сайт в течение последних 28 дней, делал публикации ранее и не является новым пользователем.
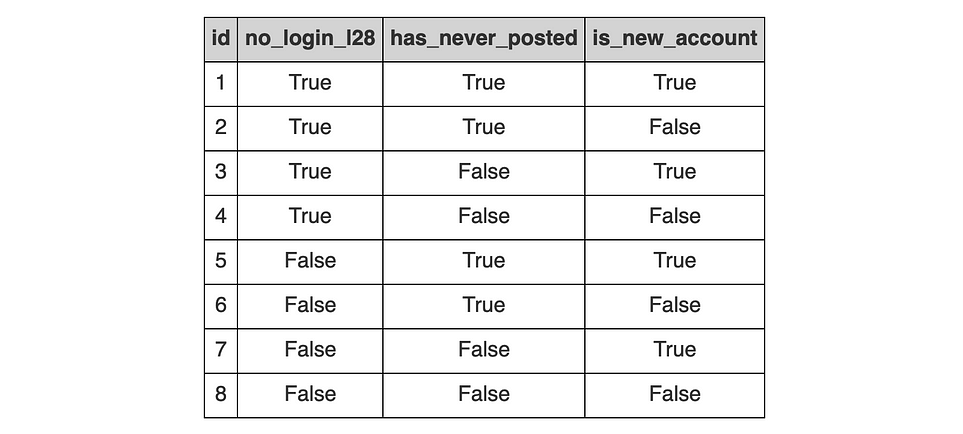
Другими словами, нужно запросить только пользователя 8, который имеет значения False для no_login_l28, has_never_posted и is_new_account.
Начнем с верхней части запроса.
WITH users(id, no_login_l28, has_never_posted, is_new_account) AS (
VALUES
(1, True, True, True),
(2, True, True, False),
(3, True, False, True),
(4, True, False, False),
(5, False, True, True),
(6, False, True, False),
(7, False, False, True),
(8, False, False, False)
)
SELECT
id
FROM users
WHERE
...
Как нужно структурировать предложение WHERE в запросе? Задумайтесь на минуту — будьте осторожны, чтобы не вернуть строки, в которых любой из столбцов имеет значение False.
Когда будете готовы, посмотрите приведенные ниже варианты. Два из них правильные, а два — неправильные.
Вариант 1. Множество AND NOT
WHERE
NOT no_login_l28
AND NOT has_never_posted
AND NOT is_new_account
Вариант 2. Множество OR NOT
WHERE
NOT no_login_l28
OR NOT has_never_posted
OR NOT is_new_account
Вариант 3. NOT + сгруппированные OR
WHERE
NOT (
no_login_l28
OR has_never_posted
OR is_new_account
)
Вариант 4. NOT + сгруппированные AND
WHERE
NOT (
no_login_l28
AND has_never_posted
AND is_new_account
)
Подсказка
Когда условия в фильтре оцениваются отдельно, а когда вместе? Если они оцениваются вместе, можно ли свести все условия к одному значению True или False?
Ответ
Вариант 1. Этот вариант поставил меня в тупик. Специалист по анализу данных из моей команды представил PR с таким фильтром, который, как я был уверен, пропустит строки 2–7, поскольку запрос удалит только пользователей со значениями False для всех трех столбцов. Но, к моему удивлению, вариант 1 таки сработал, так как три фильтра были оценены независимо. ✅
Вариант 2. Этот фильтр я изначально считал правильным, поскольку не понимал, что фильтры будут оцениваться независимо. Но на самом деле этот фильтр вернет пользователей 2–8, поскольку все, у кого есть хотя бы одно значение True для no_login_l28, has_never_posted и is_new_account, будут пропущены. ❌
Вариант 3. Изначально я думал, что фильтр должен быть оформлен именно так. Если пользователь имеет значение True для любого из no_login_l28, has_never_posted и is_new_account, то строки 3–5 оцениваются как True, NOT меняет значение на False, и эти строки в итоге исключаются. Этот вариант действительно работает, и мне он гораздо понятнее, чем вариант 1. Тем не менее оба варианта верны. ✅
Вариант 4. Возвращает тот же неверный результат, что и вариант 2. Строки 3–5 имеют значение True только для пользователя 1. Это означает, что, когда мы перевернем булево значение с помощью NOT, все остальные пользователи будут пропущены. ❌
Загадка 3. Левые объединения, действующие как внутренние объединения
Взгляните на запрос ниже. Есть две таблицы: customers (клиенты) и reviews (отзывы). Таблица customers содержит id (идентификатор клиента) и total_spend (сумма в долларах, потраченная клиентом за время пребывания на платформе).
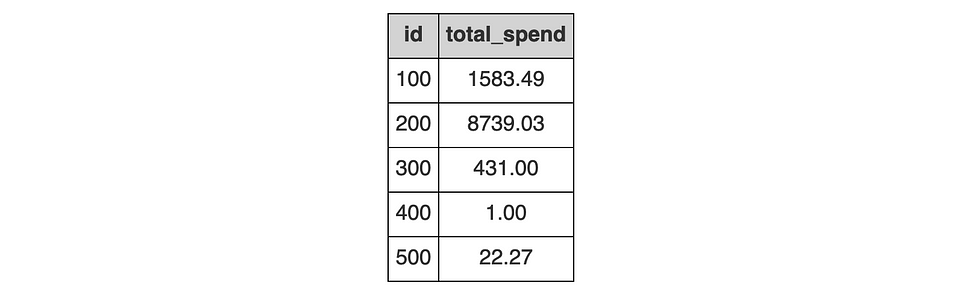
Таблица reviews содержит информацию о клиентские отзывах: id (идентификатор отзыва), customer_id (идентификатор клиента) и reported_as_spam (информация о зарегистрированных спам-отзывах).
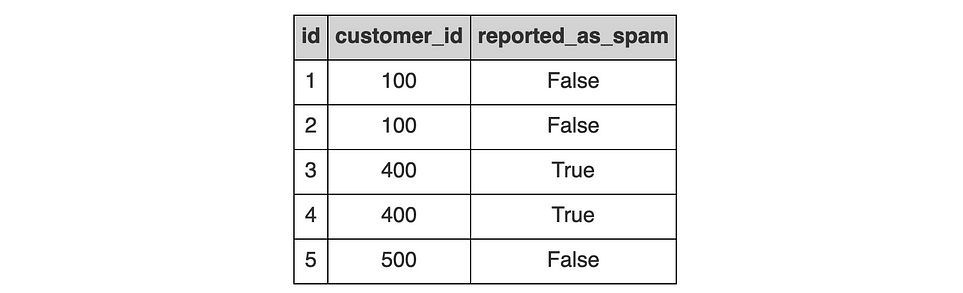
Вот подзапрос для создания двух CTE:
WITH customers(id, total_spend) AS (
VALUES
(100, 1583.49),
(200, 8739.03),
(300, 431.00),
(400, 1.00),
(500, 22.27)
),
reviews(id, customer_id, reported_as_spam) AS (
VALUES
(1, 100, False),
(2, 100, False),
(3, 400, True),
(4, 400, True),
(5, 500, False)
)
...
Теперь предположим, что вас интересует взаимосвязь между общими расходами клиента и количеством его неспамных отзывов. Поскольку не каждый клиент оставил отзыв, нужно объединить reviews и customers с помощью левого соединения. Можно построить запрос следующим образом:
...
SELECT
c.id,
c.total_spend,
COALESCE(COUNT(r.id), 0) AS n_reviews
FROM customers c
LEFT JOIN reviews r
ON c.id = r.customer_id
WHERE
NOT r.reported_as_spam
GROUP BY
1, 2
ORDER BY
1
Готовы? Вот что выходит:

Где же клиенты 200, 300 и 400? Почему они были удалены и как вернуть их обратно?
Подсказка
Если создать CTE для reviews с отфильтрованными спам-отзывами, а затем объединить эти CTE, получим ли мы тот же результат?
Ответ
При внимательном изучении ситуации видно, что клиенты 200 и 300 не оставили ни одного отзыва. У 400 есть только спам-отзывы, но и они были полностью удалены. Поскольку выполнено левое объединение, эти клиенты все еще должны быть в таблице и иметь 0 для n_reviews. Вместо этого левое объединение действует, как внутреннее объединение.
Проблема, как выяснилось, заключается в том, что предложения WHERE оцениваются после объединения. Левое объединение приносит нулевые значения reported_as_spam для клиентов 200 и 300. Затем фильтр WHERE удаляет все строки, в которых значение reported_as_spam равно True, что удаляет пользователя 400. Однако этот фильтр также удаляет нулевые значения, поэтому пользователи 200 и 300 также будут удалены.
Чтобы выполнить эту задачу правильно, нужно предварительно отфильтровать reviews перед объединением с customers. Можно, как указано в подсказке, создать CTE для reviews и там выполнить фильтрацию. Но гораздо эффективнее выполнить фильтрацию внутри объединения.
Можно сделать это, добавив AND NOT r.reported_as_spam в блок LEFT JOIN. См. ниже:
...
SELECT
c.id,
c.total_spend,
COALESCE(COUNT(r.id), 0) AS n_reviews
FROM customers c
LEFT JOIN reviews r
ON c.id = r.customer_id
AND NOT r.reported_as_spam
GROUP BY
1, 2
ORDER BY
1
Теперь получим ожидаемый результат.
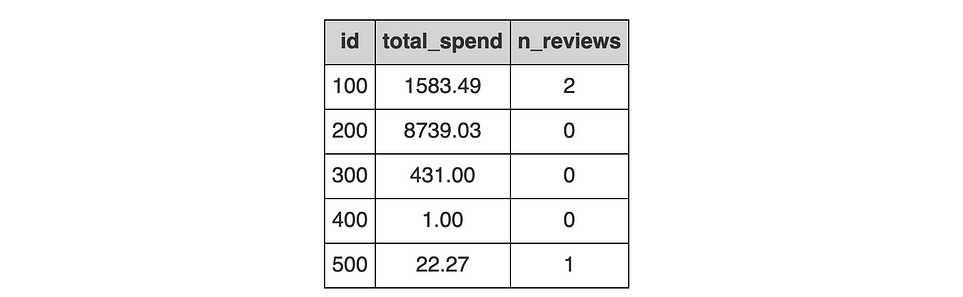
Заключение
В этой статье описаны три особенности SQL, которые могут привести к неожиданным результатам: специфичность временной метки, зависимые и независимые фильтры, а также левые соединения, действующие как внутренние соединения. Я специально привел простые примеры, чтобы сосредоточить внимание на синтаксисе. Но вы, скорее всего, столкнетесь с подобными нюансами в больших и сложных запросах.
Выявить эти ошибки бывает сложно, особенно в запросах с большим количеством компонентов. Когда меня смущает результат, я стараюсь разбить запрос на части и проверить результат каждого компонента. Но если вы сомневаетесь, напишите несколько простых CTE с тестовыми данными и убедитесь, что результаты соответствуют ожиданиям.
Читайте также:
- 5 рекомендаций по оптимизации запросов SQL
- 6 SQL-запросов, о которых должен знать каждый дата-инженер
- Лёгкое пополнение баз данных в приложениях платформы .NET
Читайте нас в Telegram, VK и Дзен
Перевод статьи Matt Sosna: SQL Riddles to Test Your Wits





