
Polars — это библиотека Python для работы с датафреймами, по скорости превосходящая Pandas.
Как и Pandas, Polars подходит для скрейпинга сайтов. С ее помощью можно читать любые CSV-файлы, опубликованные на сайте, и даже извлекать таблицы из HTML-страниц.
Однако в настоящее время в Polars нет функции .read_html, как в Pandas. Поэтому я покажу обходной путь, позволяющий превратить таблицы с HTML-страниц в Polars-датафреймы.
Примечание. Если вы не знакомы с Polars, посмотрите это видео, чтобы узнать ее преимущества перед Pandas и изучить наиболее распространенные функции, которые помогут начать работу.
Скрейпинг нескольких CSV-файлов с использованием Polars
Не скачивайте по одному CSV-файлы, загруженные на сайт, а прочитайте их с помощью Polars. Для этого нужно получить ссылку на файлы и использовать .read_csv.
Мы используем сайт Football-Data, который предоставляет исторические данные о футбольных матчах высших лиг всего мира. Проведем скрейпинг CSV-файла из Premier League (Премьер-лига).
Вот как выглядит сайт:
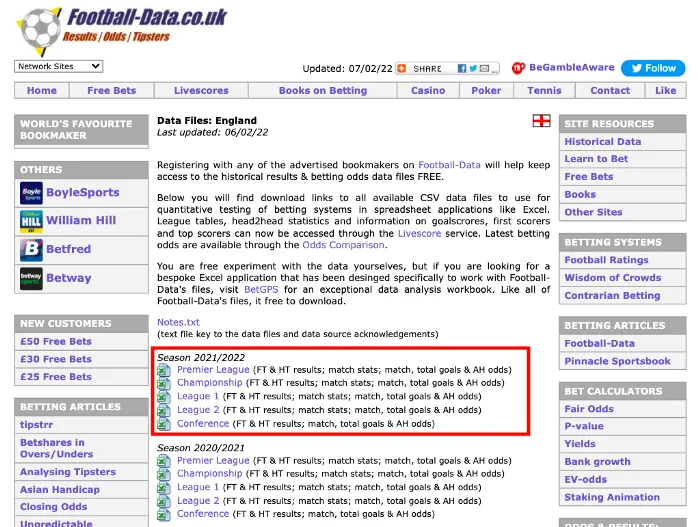
Чтобы CSV-файл “Премьер-лига” оказался в списке сверху, нужно сначала получить его ссылку. Для этого наведите курсор на CSV-файл и нажмите “Copy Link Address” (“Копировать адрес ссылки”).
Получаем такую ссылку.
Теперь прочитаем ее с Polars.
import polars as pl
pl.read_csv('https://www.football-data.co.uk/mmz4281/2122/E0.csv')
Получаем следующий датафрейм Polars со всеми данными:
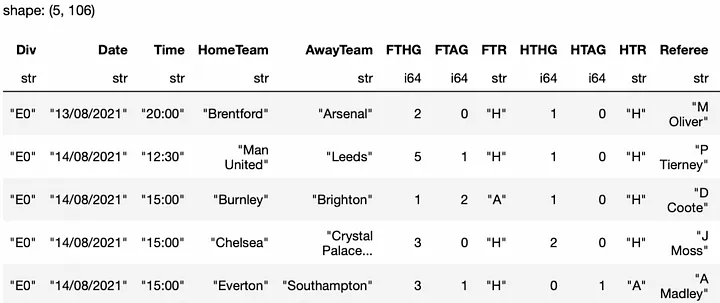
Но это только CSV-файл с данными Премьер-лиги. Чтобы получить файлы с данными других лиг, таких как Championship (Чемпионат), League 1 (Лига 1) и League 2 (Лига 2), нужно добавить цикл for.
Вот как это сделать:
import polars as pl
leagues = ['E0', 'E1', 'E2', 'E3', 'EC'] # список лиг
frames = []
for league in leagues:
df = pd.read_csv(root + "2122" + "/" + league + ".csv")
frames.append(df)
Приведенный выше цикл извлечет CSV-файлы из всех соревнований в сезоне 21/22. Список leagues содержит идентификатор каждой лиги. Например, “E0” означает Премьер-лигу.
Те же шаги можно выполнить для извлечения файлов из нескольких сезонов.
Теперь посмотрим, как извлекать данные из таблиц на HTML-страницах.
Скрейпинг HTML-страниц с Polars (обходной путь)
На момент написания статьи в Polars не было функции .read_html, которая позволяла бы легко извлекать таблицы из HTML-страниц. Однако есть обходной путь, который поможет превратить таблицы из HTML-страниц в Polars-датафреймы.
Для этого в дополнение к Polars нужно установить следующие библиотеки:
!pip install pandas
!pip install lxml
!pip install pyarrow
Pandas и lxml помогут извлечь данные, а pyarrow понадобится для превращения Pandas-датафрейма в Polars-датафрейм.
Извлечем табличные данные из статьи Википедии “List of The Simpsons episodes (seasons 1–20) (“Список эпизодов “Симпсонов”, сезоны 1–20”):
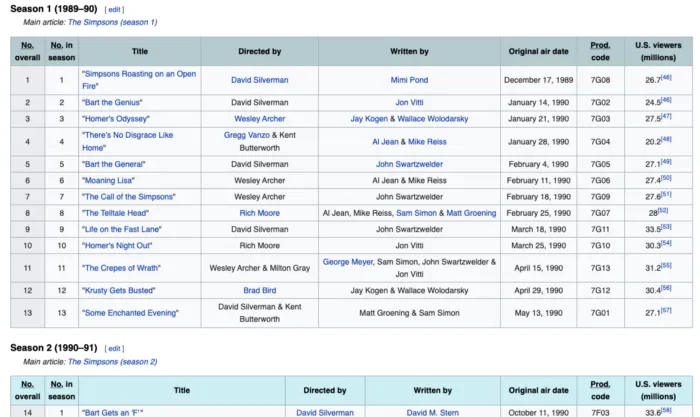
Сначала используем .read_html Pandas для извлечения таблиц из Википедии:
import pandas as pd
my_list = pd.read_html('https://en.wikipedia.org/wiki/List_of_The_Simpsons_episodes_(seasons_1%E2%80%9320)')
my_list содержит список датафреймов. Каждый датафрейм — это таблица со страницы Википедии.
Выберем случайную таблицу и назовем ее pandas_df.
pandas_df = my_list[5]
Теперь нужно использовать .from_pandas, чтобы превратить Pandas-датафрейм в Polars-датафрейм.
polars_df = pl.from_pandas(pandas_df)
Теперь у нас есть Polars-датафрейм со всеми собранными данными.
Чтобы превратить все Pandas-датафреймы из my_list в Polars-датафреймы, можно использовать списковое включение.
my_new_list = [pl.from_pandas(pandas_df) for pandas_df in my_list]
Вот и все! Теперь вы можете пользоваться всеми преимуществами Polars! Чтобы узнать больше о Polars, ознакомьтесь с официальной документацией или посмотрите полное руководство по Polars.
Читайте также:
- 4 альтернативы Pandas: ускоренное выполнение анализа данных
- Новая библиотека превосходит Pandas по производительности
- Лучшие практики разработки на Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи The PyCoach: Super Fast Web Scraping with Polars in Python





