
Современное информационное пространство активно наполняется изображениями, сгенерированными моделями глубокого обучения. Генеративное искусство, создаваемое такими нейросетями, как DALL-E, Midjourney, Stable Diffusion и Craiyon, стало феноменом.
Эти модели генерируют только 2D-изображения, но существует относительно простой способ превратить их в 3D-формат.
Данное руководство научит вас использовать машинное обучение для создания полигональных сеток (далее 3D-сеток) из 2D-изображений генеративного искусства. Получившиеся 3D-сетки можно рассматривать с разных ракурсов и задействовать в качестве игрового и видеоконтента. На тот случай, если вы не умеете программировать, — здесь этот навык не потребуется!

Исходное изображение, отмеченное как source image, создано путем преобразования текста в изображение по описанию “Визуализация Пита Буттиджича”. Справа представлена автоматически сгенерированная 3D-сетка, а также способы ее затенения и текстурирования.
Разберем подробно сам процесс создания.
Исходное изображение автоматически генерируется нейросетью Stable Diffusion по описанию “Визуализация Пита Буттиджича”.
Алгоритм придает изображению художественный или мультипликационный вид. Можете поэкспериментировать сами.
Изображения справа демонстрируют 3D-сетку, автоматически сгенерированную из исходного варианта с помощью современных методов МО, которые будут рассмотрены далее.
Готовую 3D-сетку можно визуализировать посредством программ 3D-моделирования, применить к ней затенение и желаемую текстуру. Отметим, что исходное изображение может повторно использоваться в качестве текстуры.
Однако вернемся непосредственно к самому механизму преобразования исходного изображения в 3D-сетку. Этот процесс называется “монокулярная оценка глубины” (MDE).
Для создания 3D-сетки необходимо определить для каждого пикселя значение глубины, обозначающее его расстояние от камеры.
Имеется в виду расстояние каждой точки изображения от камеры. Алгоритмы для MDE как раз вычисляют такие значения. Лично у меня был опыт работы с методами DenseDepth и MiDaS. Ниже приведен пример спрогнозированной глубины каждого пикселя изображения. Получаемый результат называется каналом глубины:

Исходное изображение (№1). Оно проходит через алгоритм оценки глубины для вычисления канала глубины. С учетом полученных данных каждому пикселю присваиваются уникальные координаты в 3D-пространстве, а именно значения (x, y, z).
Изображение оценки глубины (№2). Цвет каждого пикселя в канале глубины указывает на расстояние до камеры: белые пиксели находятся ближе к ней, а черные — дальше.
Изображение 3D-сетки (№3). 3D-сетка создается на основе данных, предоставляемых исходным изображением и каналом глубины. Проще говоря, вы берете каждый пиксель и двигаете его ближе или дальше в зависимости от значения глубины. В результате для каждого пикселя определяется свое положение в 3D-пространстве.
К счастью, есть полезный сайт, который одним щелчком мыши помогает решать все вышеперечисленные задачи. Просто открываем ссылку и загружаем изображение, которое нужно преобразовать в 3D-сетку.
В следующем примере возьмем сгенерированное изображение человека, похожего на Уолта Диснея, и превратим его в 3D-сетку:
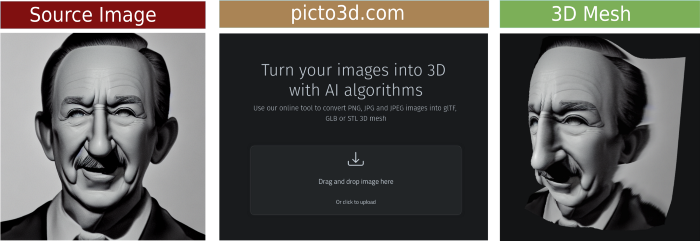
Вы можете менять интенсивность глубины — иначе говоря, глубину пространства, а также экспериментировать с рядом других параметров. А самое главное преимущество сайта заключается в том, что он позволяет сохранять полученные 3D-модели в разных файловых форматах. Рекомендуется использовать формат .stl, поскольку он наиболее распространенный.
Но на этом процесс не заканчивается. Предстоит поработать с текстурой и довести 3D-сетку до оптимального качества. Для этого очистим текстуру в программе 3D-моделирования. Воспользуемся бесплатным ПО под названием Blender, доступным для Windows, Mac и Linux. Ссылка для скачивания.
Открываем Blender, импортируем скаченный файл *.stl и получаем следующий результат:
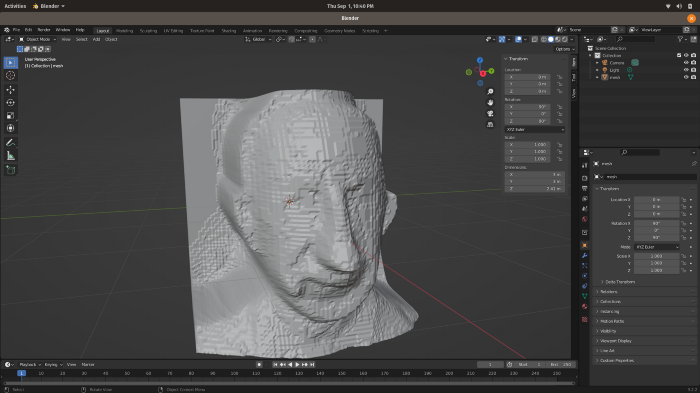
Результат хороший, но не совершенный. Последовательным нажатием на объект сначала левой, потом правой кнопкой мыши открываем меню. Выбираем в нем самую первую команду shade smooth (пер. сглаживание затенения) и применяем. 3D-сетка выглядит намного лучше:
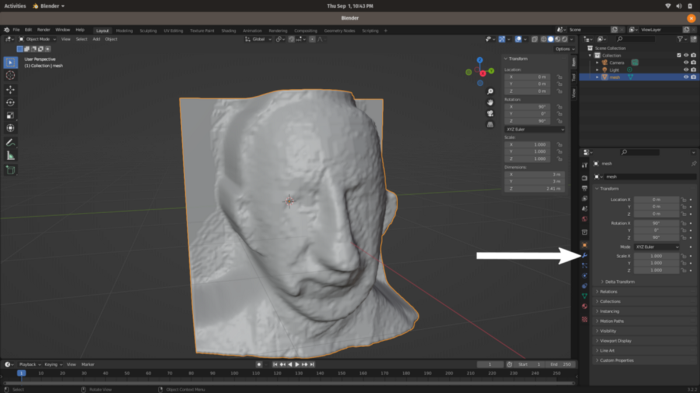
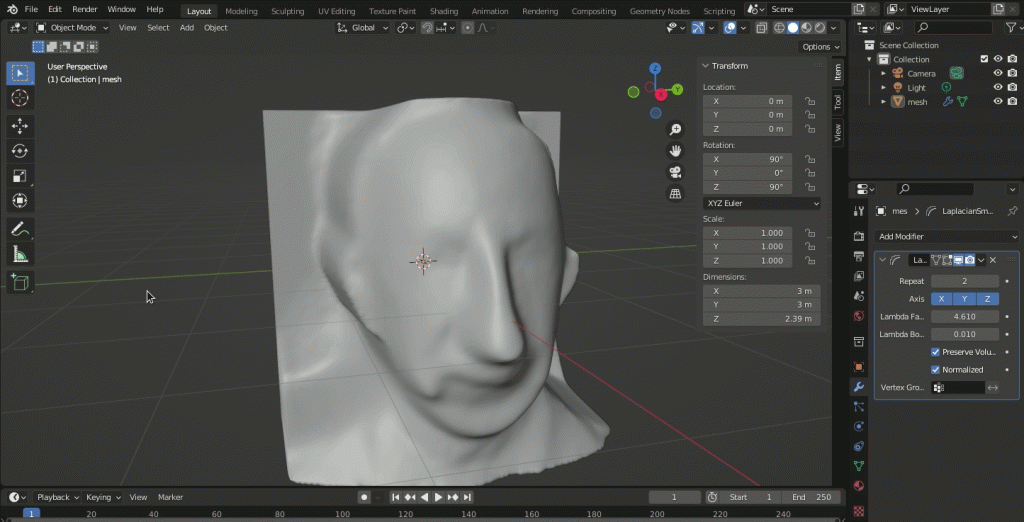
На данный момент качество модели остается прежним, мы только изменили метод затенения: с плоского на Гуро. Теперь необходимо устранить неровности. Для этой цели потребуется модификатор. Нажимаем на кнопку, обозначенную стрелкой на изображении выше, открываем меню и добавляем модификатор (add modifier).
Воспользуемся модификатором сглаживания Лапласа Laplacian Smoothing. Выбираем его, устанавливаем повторение в значение 2 (англ. repeat) и лямбда-фактор 4.6 (англ. Lambda Factor). Значение повторения указывает, сколько раз применяется сглаживание. Значение лямбда примерно определяет степень сглаживания. Чем выше значения, тем больше степень сглаживания. Полученный результат выглядит так:
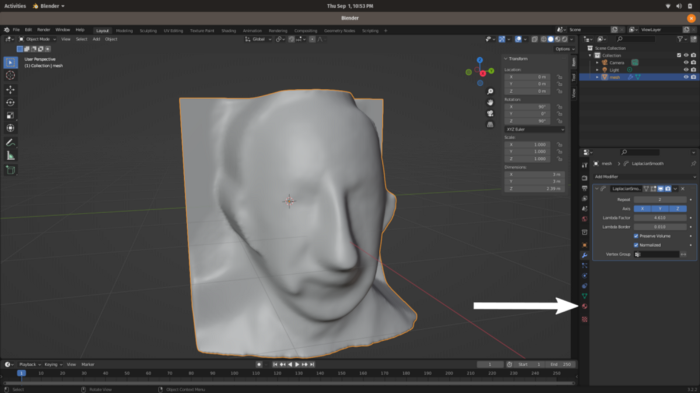
Получилось довольно неплохо. Теперь нужны текстуры.
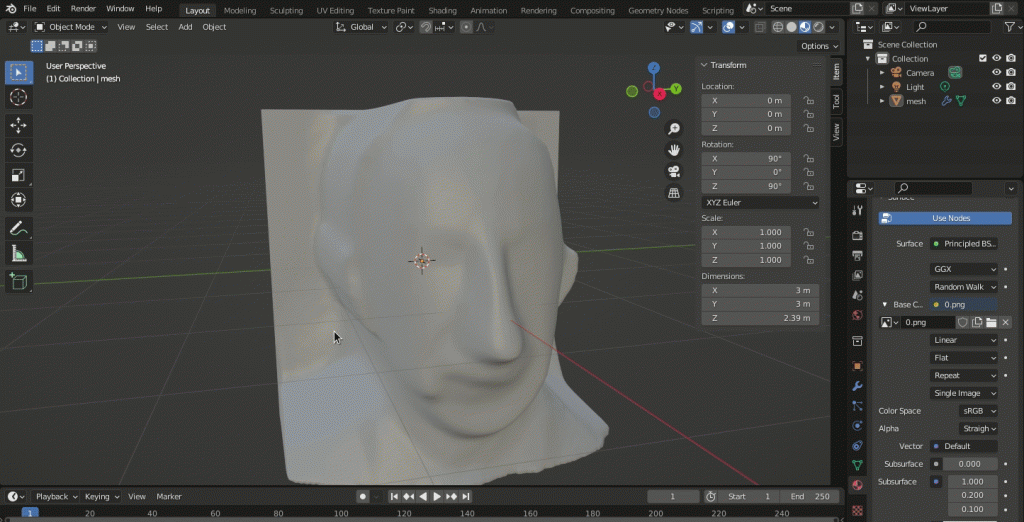
Для этого переходим в меню свойств материалов, кнопка которого обозначена стрелкой на изображении выше.
Нажимая new, создаем новый материал. После этого устанавливаем Basecolor (пер. базовый цвет) для исходного изображения Уолта Диснея. Следующее GIF-изображение показывает, как это сделать: просто нажимаем на желтую точку рядом с Basecolor и выбираем текстуру изображения Image Texture из файла:
Осталось только убедиться в правильном расположении текстуры на поверхности модели.
Для этого переходим в меню редактирования UV. В левой части редактора UV выбираем исходное изображение.
В правой части редактора выбираем пункт меню UV -> Project from View, как показано на следующем GIF-изображении:
Оранжевые точки поверх текстуры — это координаты 3D-сетки. Необходимо убедиться в их корректном наложении.
Что мы и делаем, нажимая на клавишу s для масштабирования.
Теперь возвращаемся в меню рабочего пространства Layout и получаем итоговую модель:

После импорта и очистки модели в Blender можно настраивать свет, менять перспективу и добавлять другие объекты.
Результаты получаются весьма впечатляющими. Приведем примеры:


Читайте также:
- Создание интерфейсов, удобных для алгоритмов
- Как создавать диаграммы с помощью ChatGPT
- ЕС ужесточает регулирование в сфере использования искусственного интеллекта
Читайте нас в Telegram, VK и Дзен
Перевод статьи Heni Ben Amor: DALL-E to 3D: How to Turn Your Generative Art Into 3D Meshes

, notify() и notifyAll() в Java")



