
Виртуальные потоки, представленные в Java 19, предназначены для ускорения одновременных сетевых запросов. В данной статье мы сравним пропускную способность обычных и виртуальных потоков, выполняющих HTTP-запросы. Для этой цели воспользуемся двумя виртуальными машинами в Google Cloud. У каждой из них 8-ядерный процессор и 16 ГБ памяти. Одна машина послужит сервером, а другая — клиентом.
Серверная машина запускает небольшое приложение Spring Boot и возвращает значение параметра i, полученное в URL:
@SpringBootApplication
@RestController
public class Main {
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
@GetMapping("/")
public String hello(@RequestParam(value = "i") String i) {
return i;
}
}
В клиентском приложении в качестве контрольной меры используется сумма возвращаемых значений. Это объясняется необходимостью убедиться, что все одновременные запросы привели к корректным ответам.
Клиентское приложение отправляет одинаковые наборы одновременных HTTP-запросов, применяя традиционный кэшированный пул потоков и отдельные виртуальные потоки. Порядковый номер каждого HTTP-запроса присваивается параметру i:
public class Network {
List<Callable<String>> tasks;
int repeats;
public Network(String[] args) {
var ip = args[2];
var urls = IntStream.range(0, Integer.parseInt(args[0]))
.mapToObj(i -> "http://" + ip + ":8080/?i=" + i).toList();
tasks = urls.stream().map(url -> (Callable<String>) () -> fetchURL(url)).toList();
repeats = Integer.parseInt(args[1]);
}
HttpClient client = HttpClient.newBuilder().followRedirects(HttpClient.Redirect.NEVER).build();
String fetchURL(String url) throws IOException, InterruptedException {
var request = HttpRequest.newBuilder().uri(URI.create(url)).build();
return client.send(request, HttpResponse.BodyHandlers.ofString()).body();
}
String execute(ExecutorService executor) throws Exception {
try (executor) {
var s = System.currentTimeMillis();
var sum = executor.invokeAll(tasks).stream().mapToInt(f -> Integer.valueOf(f.resultNow())).sum();
return (System.currentTimeMillis() - s) + "\t" + sum;
}
}
void assessExecutors() throws Exception {
out.println("CPU count " + Runtime.getRuntime().availableProcessors());
out.println("cached\t\t\tvirtual");
out.println("time\tsum\t\ttime\tsum");
for (var i = 0; i < repeats; i++) {
var cached = execute(Executors.newCachedThreadPool());
var virtual = execute(Executors.newVirtualThreadPerTaskExecutor());
out.println(cached + "\t\t" + virtual);
}
}
public static void main(String[] args) throws Exception {
new Network(args).assessExecutors();
}
}
Основной класс Network ожидает 3 аргумента командной строки: количество одновременно отправляемых запросов, количество повторных измерений и IP-адрес серверной машины.
В отличие от отложенных задач официальной документации разница между обычными и виртуальными потоками очевидна даже при 1 000 одновременных запросах. Сетевые запросы в виртуальных потоках выполняются на 40% быстрее:
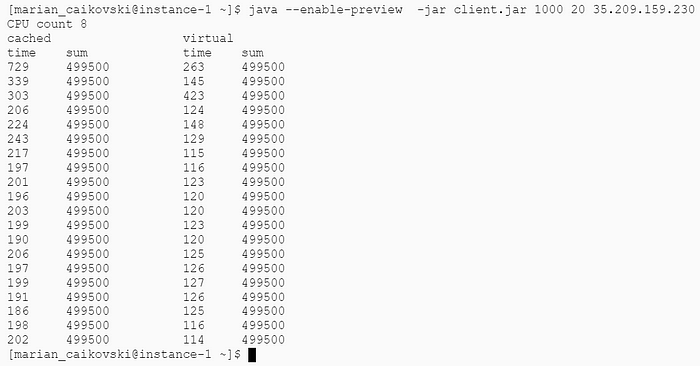
Полагаю, что численные показатели улучшения больше зависят от характеристик виртуальной машины, чем от Java, и поэтому не играют решающей роли. Но суть в том, что виртуальные потоки обеспечивают более высокую пропускную способность сетевых запросов.
Примерно такое же улучшение производительности наблюдается при 3 000 и 5 000 одновременных запросах:
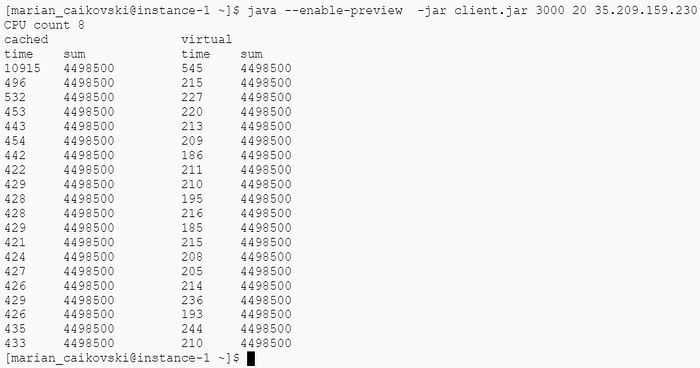
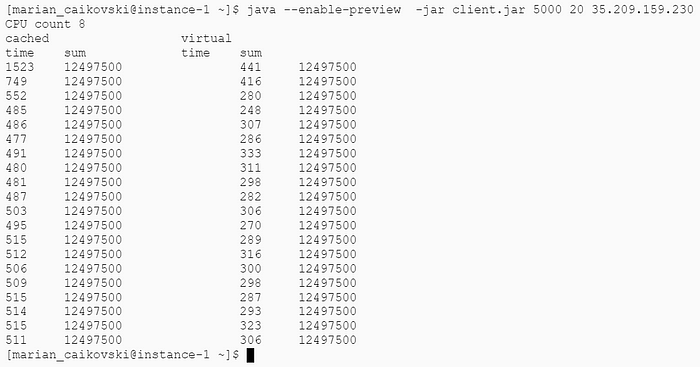
При 10 000 одновременных запросах сервер перестает отвечать до момента своего перезапуска. Это ограничение виртуальной машины, а не Java.
Виртуальный поток и секрет его скоростных преимуществ
Согласно документации, виртуальные потоки предназначены для тех случаев, когда одновременные задачи исчисляются тысячами, и большую часть времени выполнения находятся в состоянии ожидания, например ожидают ответы от сети или базы данных. В отличие от обычного, виртуальный поток не связан с выделенным потоком ОС.
Среда выполнения Java реализует виртуальные потоки, используя пул потоков ОС. Когда виртуальный поток ждет ответ от сети, среда выполнения присваивает поток ОС виртуальному потоку, который должен выполнить какую-либо задачу. Получив ответ от сети, среда возобновляет выполнение приостановленного потока в первом доступном потоке ОС.
Виртуальные потоки обеспечивают превосходство серверных приложений Java над Node.js
Механизм работы виртуального потока напоминает Node.js. Там код JavaScript выполняется одним потоком, но сетевые запросы являются асинхронными и осуществляются всеми доступными потоками ОС. В результате Java не смогла существенно превзойти Node.js по пропускной способности сетевых запросов.
Еще раз сравним производительность Java и Node.js. В данном примере одни и те же одновременные запросы к одному и тому же серверу отправляются кодом JavaScript:
import { argv } from 'process';
const [requests, repeats, ip] = argv.slice(2);
const urls = Array.from({ length: requests }, (e, i) => `http://${ip}:8080/?i=${i}`);
console.log("attempt\ttime\tsum");
for (let i = 0; i < repeats; i++) {
const start = Date.now();
const contents = await Promise.all(urls.map(url =>
fetch(url).then(res => res.text())));
console.log(i+"\t"+(Date.now() - start)+"\t"+contents.map(s => parseInt(s)).reduce((t, v) => t + v, 0));
}
Выполним код, задействуя Node.js 19. При 5 000 запросах код всякий раз не срабатывает:
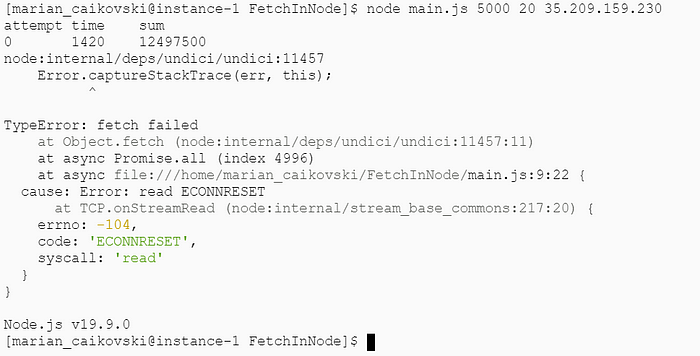
Клиент Java обрабатывает все 5 000 запросов без исключения. Видимо, проблема в Node.js или в его нестабильном методе fetch(). Таким образом, HTTP-клиент Java кажется более эффективным.
Однако при 1 000 и 3 000 запросов время выполнения примерно такое же, как и в примере с клиентом Java при использовании кэшированного пула потоков:
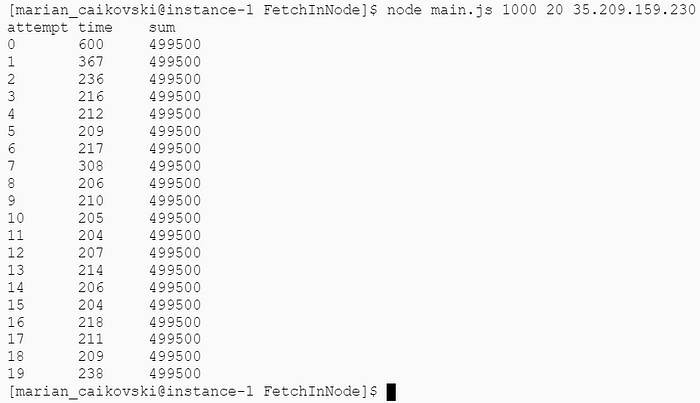
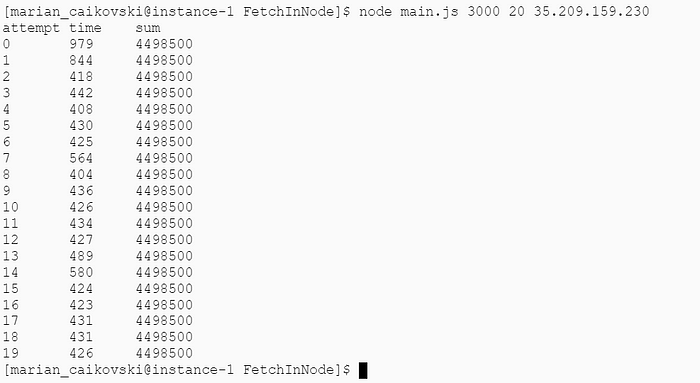
Java с виртуальными потоками явно превосходит Node.js.
Заключение
Виртуальные потоки — важное улучшение в Java. Разработчики, работающие над приложениями с высокой пропускной способностью, только выиграют от приобретения этой новой функциональности. Кроме того, фанаты реактивных библиотек получают в свое распоряжение более удобный способ для выполнения сетевых запросов.
Ссылка для скачивания исходного кода.
Читайте также:
- Все о ключевых словах static и final
- Альтернатива Java 8: что умеет VAVR
- Создаем юнит-тесты с помощью ИИ-инструмента
Читайте нас в Telegram, VK и Дзен
Перевод статьи Marian Čaikovski: A Modern Way to Efficiently Execute Concurrent Network Requests in Java





