
Проблемы
Большинство методов семантической сегментации на основе СNN (convolutional neural network, сверточной нейронной сети) сосредоточены на простом получении правильных предсказаний без обучения модели различать классы. По этой причине характеристики менее распространенных классов могут быть проигнорированы.
Из-за визуального сходства классы обладают общими высокоуровневыми признаками, что может привести к запутанным результатам в областях, где классы смешиваются или граничат между собой. Например, фон может сливаться с объектом, поскольку они имеют схожую силу активации.
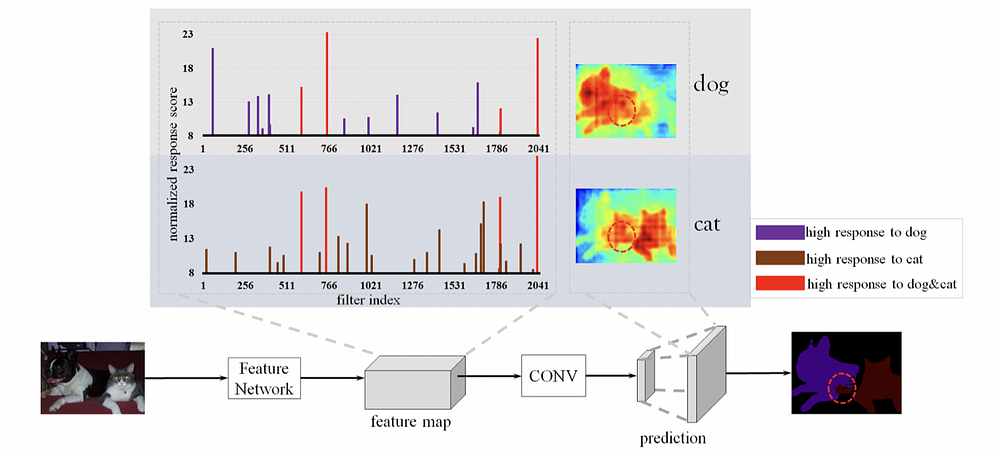
Наглядной демонстрацией проблемы является рисунок 1. При рассмотрении степени интенсивности внимания становится очевидно: большинство современных моделей кодировщиков-декодеров будут проявлять сильную нейронную активацию на участках, где два и более объекта “смешаны”. Иначе говоря: имеют нечеткие границы или области со схожими пространственными паттернами. Когда дело доходит до прогнозов, такие модели не должны придавать большого внимания этим “смешанным” частям.
Решение
Авторы статьи ”Семантическая сегментация с обратным вниманием” разработали метод определения этих особых “смешанных” областей и усиления слабых активаций для захвата целевого объекта. В результате сеть обучается не только распознавать фоновый класс, но и дифференцировать различные объекты, находящиеся на изображении.
Новая архитектура, предназначенная для решения вышеупомянутой задачи, была названа RAN (reverse attention network, сеть обратного внимания).
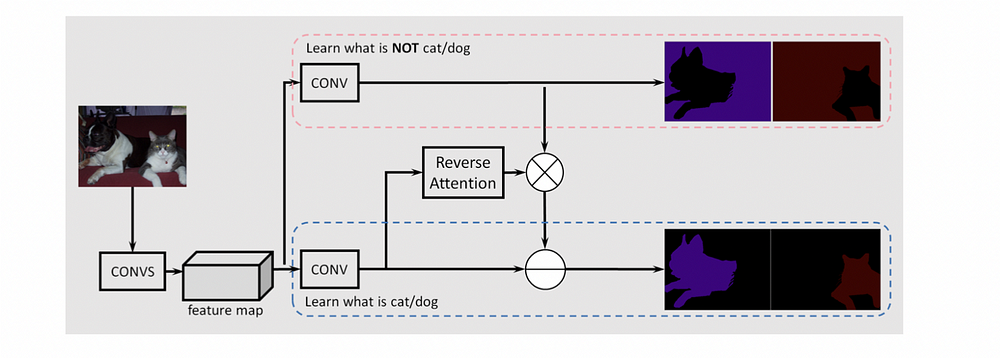
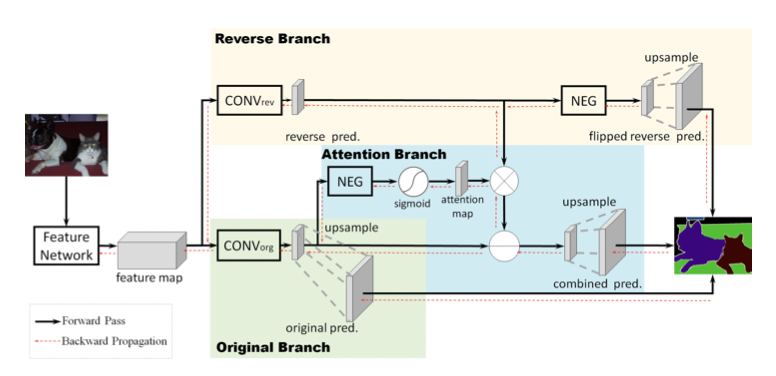
В RAN есть две различные ветви (одна обозначена красной пунктирной линией, другая — синей), предназначенные для изучения признаков фона и признаков объекта.
За дальнейшее выделение информации, полученной моделью от класса object, отвечает структура обратного внимания. Она генерирует маски для каждого класса, чтобы усилить активации класса object в смешанной области.
В завершение прогнозы объединяются для получения окончательного прогноза.
Сеть обратного внимания (RAN)
Для более детального рассмотрения предложенной модели обратимся к рисунку 3.
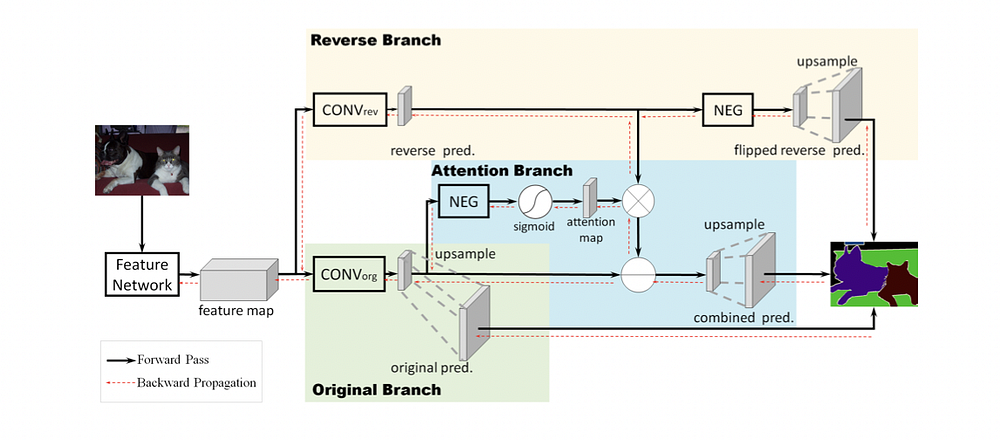
После получения входного изображения процесс можно разбить на несколько этапов.
- Создается карта признаков с использованием выбранной архитектуры модели (обычно ResNet-101 или VGG16, но возможны и другие вариации) для изучения признаков объекта.
- Затем карта разделяется на две ветви.
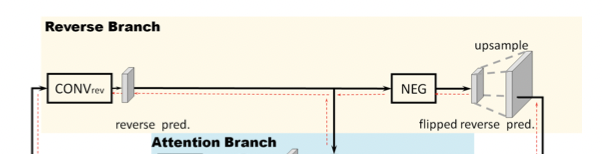
Обратная ветвь (RB)
Сначала обучается слой CONV_rev, выделенный желтым цветом, для явного изучения “класса reverse object” — это обратные эталонные данные для класса object.
Чтобы получить класс reverse object, фон и другие классы устанавливаются на 1, а класс object — на 0.
Однако, когда необходимо решить проблему многоклассовой сегментации, обычно используется альтернативный способ, при котором перед подачей в классификатор, основанный на функции softmax, меняется знак всех активаций по классам (блок NEG). Этот подход позволяет обучить слой CONV_rev, используя ту же самую метку по классам “ground-truth” (“эталонные данные”).
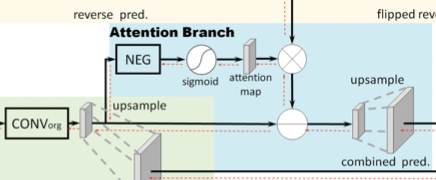
Ветвь обратного внимания (RAB)
Вместо того чтобы напрямую применять поэлементное вычитание к исходному прогнозу путем активаций обратной ветви (что снижает производительность), предлагается использовать ветвь обратного внимания для выделения областей, пропущенных исходным прогнозом (включая смешанные и фоновые области). Вывод обратного внимания генерирует маску, ориентированную на класс, чтобы усилить карту обратной активации.
Как показано на рис. 3 и рис. 5, исходная карта признаков входного изображения подается в слой CONV_org.
Затем значения пикселей полученной карты признаков переворачиваются блоком NEG.
Потом применяется сигмоидная функция для преобразования значений пикселей в диапазоне [0, 1], после чего карта признаков подается на карту внимания, где применяется маска внимания.
Вышеупомянутые шаги можно свести к формуле 1, где i, j обозначают расположение пикселей.
Таким образом, область с малой или отрицательной реакцией будет выделена с помощью NEG и сигмоидной операции, но области с положительной активацией (или оценками уверенности) будут подавляться в обратной ветви внимания.
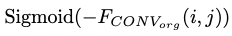
Объединение результатов
Затем карта из ветви обратного внимания (Reverse Attention Branch) поэлементно перемножается с картой из обратной ветви (Reverse Branch). Полученная карта вычитается из исходного прогноза для получения окончательного прогноза.
Обучение
Этот момент выходит за рамки данной статьи, поэтому просто приведем отрывок оригинального текста из статьи.
«Для обучения предложенной RAN мы проводим обратное распространение потери кросс-энтропии на трех ветвях одновременно и используем softmax-классификаторы на трех выходах прогноза. Со всеми тремя потерями необходимо считаться для обеспечения сбалансированного сквозного процесса обучения.
Потеря оригинального прогноза и потеря обратного прогноза позволяют CONVorg и CONVrev параллельно изучать целевые классы и их обратные классы. Кроме того, потеря комбинированного прогноза позволяет сети изучать обратное внимание.
Предложенную RAN можно эффективно обучать на основе предварительно обученной FCN. Это указывает на то, что RAN является улучшенной версией FCN, так как в процесс ее обучения добавлены более релевантные указания».
Производительность
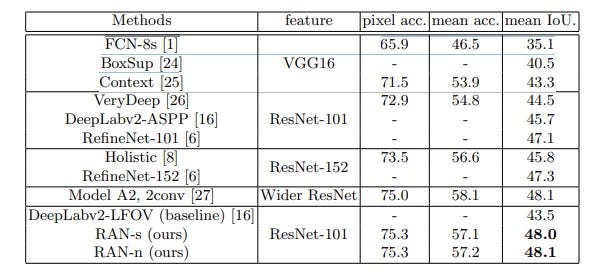
Таблица 1. Сравнение оценок эффективности семантической сегментации изображений (%) на 5 105 тестовых изображениях из набора данных PASCAL Context.
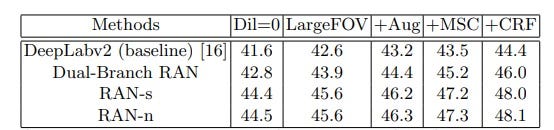
Таблица 2. Исследование абляции различных RAN на наборе данных PASCAL-Context для оценки преимуществ предложенной RAN. Мы сравниваем результаты при различных настройках сети с использованием conv-фильтров расширенных решений, дополнения данных, проектных разработок MSC и постобработки CRF.
Читайте также:
- Когда не следует использовать нейронные сети
- GraphSAGE: как масштабировать графовые нейронные сети до миллиардов соединений
- Как галлюцинируют нейросети
Читайте нас в Telegram, VK и Дзен
Перевод статьи Leo Xu and Daniel Wang: Explained: Reverse Attention Network (RAN) in Image Segmentation





