
Сейчас типичная исследовательская статья по МО выглядит примерно так:
Предлагаем новую архитектуру модели X. Как выяснилось, X превосходит SOTA (Self-Organising Tree Algorithm, самоорганизующийся древовидный алгоритм) на Y%. Таким образом, X лучше, чем текущий SOTA. Наш код доступен онлайн.
И на этом академические исследования обычно заканчиваются. Однако с точки зрения производства этого не достаточно. Нет никакой гарантии, что модель, которая хорошо выглядит “на бумаге”, станет эффективной в производстве.
В этой статье будут рассмотрены дополнительные задачи, сопутствующие созданию моделей не только для научных исследований, но и для производства. Вы узнаете:
- почему производительность в офлайне не гарантирует производительность в онлайне;
- почему не все ошибки одинаковы;
- почему, помимо производительности модели, важны время задержки и объяснимость;
- почему не стоит доверять спискам лидеров МО.
Производительность в офлайне не гарантирует производительность в онлайне
Исследования в области МО сосредоточены исключительно на офлайн-производительности. Исследователя интересует, как модель работает на статичном историческом тестовом наборе данных.
В сфере производства первоочередной задачей становится онлайн-производительность. Тут важно, насколько успешнее стал бизнес после того, как модель была развернута, а также как она обрабатывает операции, связанные с реальными пользователями в реальном мире.
Например:
- при обнаружении мошенничества подходящей офлайн-метрикой может быть ROC-AUC, а подходящей онлайн-метрикой — убытки по чарджбэку от пропущенных мошеннических операций;
- в поисковом ранжировании подходящей офлайн-метрикой может быть NDGC, а подходящей онлайн-метрикой — коэффициент кликабельности;
- при ранжировании рекламы подходящей офлайн-метрикой также является NDGC, но может понадобится измерить общий доход от рекламы онлайн.
Некоторые исследовательские группы в области МО, такие как Netflix и Booking.com, обнаружили: улучшение производительности модели в офлайн-режиме не является гарантией того, что модель станет работать лучше в онлайне. Некоторые модели лучше работают в офлайн-режиме и хуже в онлайне. Диаграмма разброса показателей офлайн- и онлайн-моделей из статьи Booking.com показывает полное отсутствие корреляции:
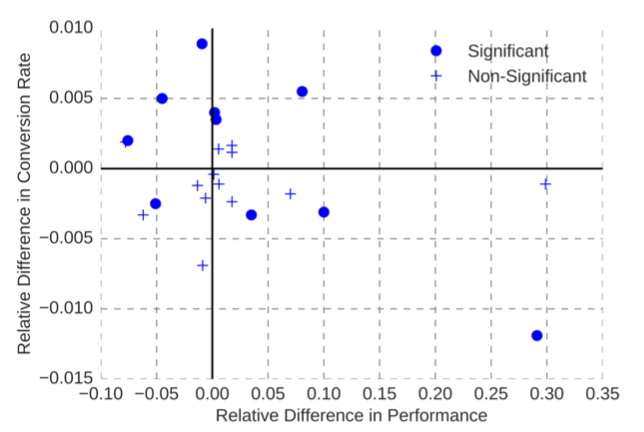
С чем это связано?
Одна из причин заключается в том, что офлайн-метрика — это всего лишь прокси-показатель для бизнес-метрики, которую необходимо оптимизировать. Офлайн- и онлайн-метрики могут коррелировать, но эта корреляция не идеальна. Модель, которая подверглась чрезмерному обучению в отношении прокси-метрики, может значительно отклониться от фактической метрики, представляющей бизнес-интерес. Это может быть особенно проблематично для глубоких нейронных сетей из-за большого количества свободных параметров. Авторы статьи Netflix предупреждают:
“Если модели глубокого обучения дать неправильную задачу, она решит ее более точно, чем менее мощные модели”.
На помощь приходит улучшение прокси-метрики. Например, исследователи из YouTube обнаружили, что оптимизация модели по времени просмотра работает лучше, чем оптимизация по кликам. Дело в том, что модель, оптимизированная по кликам, в итоге отдает предпочтение видео с рекламой-приманкой, не представляющим особой ценности для пользователя.
Ошибка ошибке — рознь
Еще одна проблема с прокси-метриками связана с тем, что мы допускаем, что нет качественных различий между популяциями, совершающими ошибки. Однако это предположение не всегда верно: не все ошибки одинаковы.
Например, при выявлении мошенничества в электронной коммерции большую роль играет скорость движения товара. Ложные отрицательные результаты для продуктов с высокой скоростью (например, цифровых видеоигр) имеют гораздо большее значение, поскольку недобросовестные игроки могут нанести огромный ущерб за короткий промежуток времени. Таким образом, модель с меньшим количеством ошибок в целом, но большим количеством ошибок для высокоскоростных продуктов может привести к гораздо большему количеству проблемных долгов и, следовательно, к ухудшению бизнес-показателей.
Еще одна область, в которой ошибки имеют качественные различия, — это ранжирование рекламы. Исследователи из Microsoft обнаружили, что ошибки при оценке низкой вероятности оказывают гораздо большее влияние на бизнес-метрику — доход от рекламы — по сравнению с ошибками при оценке высокой вероятности. Это объясняется тем, что гораздо хуже показать пользователю нерелевантную рекламу, чем не показать релевантную: в худшем случае пользователь может быть раздражен настолько, что просто уйдет.
Время задержки имеет значение
В исследовательских работах по МО редко обсуждается время задержки. В конце концов, тестовый набор фиксирован, и достаточно провести единоразовую оценку, чтобы указать количественный показатель в статье.
Однако в производстве модель должна работать как часть сервиса, которым ежедневно пользуются миллионы или даже миллиарды пользователей. Критически важным показателем в приложениях, ориентированных на пользователей, является время задержки одного запроса, т. е. время, необходимое для получения ответа от сервера на один запрос пользователя.
Насколько важно время задержки модели? В ходе эксперимента исследователи из Booking.com ввели искусственные задержки в свой сервис, чтобы выяснить это. Каков же был результат? Оказывается, время задержки имеет статистически значимую отрицательную корреляцию с коэффициентом конверсии пользователей. Увеличение задержки на 30% приводит к снижению конверсии на полпроцента. “Релевантная стоимость для нашего бизнеса”, — пишут исследователи в своей статье.
Авторы сообщают, что на основании этого вывода Booking.com оптимизировал свою систему МО для учета времени задержки, используя простые линейные модели, созданные собственными силами с минимальным набором функций.
Объяснимость имеет значение
Разница между моделью на бумаге и моделью в производстве заключается в том, что модель в производстве совершает операции, которые влияют на реальных пользователей. Ложные положительные и ложные отрицательные результаты могут привести к эскалациям. И если это произойдет, хорошо бы иметь объяснения, почему модель допустила ошибку. Поэтому объяснимость — это еще одно свойство модели, которое имеет значение в производстве, но не так часто обсуждается в научных статьях.
Как правило, чем сложнее модель, тем труднее объяснить ее прогноз. В весах простой линейной модели уже закодировано то, на что она ориентирована, и они могут дать некое представление о том, почему происходят определенные ошибки.
Ситуация усложняется, когда речь идет о случайном лесе и форсированных деревьях, а с глубокими нейронными сетями дело обстоит еще труднее. Такие инструменты, как SHAP, помогают объяснять решения сложных моделей, но они увеличивают время задержки. А, как было доказано ранее, оно имеет большое значение в приложениях, ориентированных на пользователя.
Если объяснимость и время задержки являются жесткими требованиями, то простая линейная модель может стать лучшим выбором для производства, даже если она уступает более сложным моделям в производительности.
Эффекты поиска в другом месте и списки лидеров МО
Распространенной практикой в исследованиях МО является оценка нескольких моделей на одном и том же тестовом наборе для сравнения их производительности. Проблема этой практики заключается в том, что (в силу одной лишь случайности) ожидается, что одни модели превзойдут другие, даже если все они одинаково хороши.
Другими словами, пока проверяется достаточно большое количество моделей на тестовом наборе, рано или поздно гарантированно находится модель, которая превзойдет ту, что мы пытаемся “забраковать”, просто в силу случайности. Это также известно как эффект поиска в другом месте.
Как правило, чем больше разница в производительности офлайн- моделей и чем больше тестовый набор, тем статистически значимее результат. Точная статистическая значимость может быть рассчитана с помощью статистического фреймворка, известного как множественная проверка гипотез.
Используя этот фреймворк, исследователь ИИ Лорен Окден-Рейнер вычислила статистическую значимость результатов лидеров конкурса Kaggle по сегментации медицинских изображений. Результат? Разница между моделью №1 и моделью №192 может быть признана статистически значимой, учитывая количество данных и разницу в баллах. А что насчет моделей, находящихся между номерами 1 и 191? С точки зрения строгой статистики, невозможно сделать вывод, что какая-то из них лучше другой.
Действительно ли одна модель лучше других? Возможно, и нет: она может оказаться лучше по простой случайности.
Заключение
В заключение — несколько практических советов для вашего следующего проекта по МО.
- Воспринимайте показатели офлайн-производительности с долей скепсиса. Рассматривайте их как проверку работоспособности, а не как гарантию эффективности в производстве. Вместо этого, полагайтесь на рандомизированные контролируемые испытания для оценки эффективности модели в производстве.
- В дополнение к офлайн-производительности измеряйте время задержки модели. Задержка реакции имеет четкую отрицательную корреляцию с пользовательским опытом, и стоит избежать ее увеличения, если только модель не сможет компенсировать негативное влияние существенным увеличением производительности. Если объяснимость и время задержки являются критическими параметрами, то простая линейная модель может быть лучшим вариантом.
- Не все ошибки одинаковы. Изучите влияние различных типов ошибок из разных популяций на бизнес-метрику, которую пытаетесь оптимизировать. Модель с лучшим AUC может совершать меньше ошибок, но они будут достаточно грубыми, чтобы привести к ухудшению общей производительности.
- Не стоит полагаться на модель, показавшую наивысшие результаты в списке лидеров конкурса МО. Возможно, ей просто повезло.
Читайте также:
- 6 алгоритмов машинного обучения, которые должен знать каждый исследователь данных
- Почему лучшее - враг хорошего в MLOps?
- #04TheNotSoToughML | “Давай, минимизируй ошибки” — Но достаточно ли этого?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Samuel Flender: Is My Model Really Better?





