
В современном мире, где активно используются облачные сервисы и бесконечно совершенствуются решения для резервного копирования, хранить дорогие сердцу проекты на простом внешнем жестком диске становится уже неактуально. Но недавно я узнала, правда, не по своей воле, что музыканты все еще предпочитают именно такой способ.
Суть проблемы
Интересные выходные выдались у меня, когда один из внешних жестких дисков мужа перестал работать. Как назло, им оказался именно тот, где он хранил все свои последние музыкальные проекты, звуковые эффекты для стриминга и так называемые “стемы”, обеспечивающие ему авторские права на музыку.
Встал вопрос: днями и ночами успокаивать мужа, скорбящего из-за потери результатов целого года работы или постараться спасти максимально возможный объем данных. Победил здравый смысл, и я погрузилась в интернет в поисках нужного решения. Но первая попытка не увенчалась успехом. Диск оказался усеян беспорядочными нечитаемыми секторами, которые беспричинно замедляли сканирование, выполняемое Disk Drill или аналогичными приложениями. Кроме того, прерывались любые попытки автоматического или ручного резервного копирования из-за произвольного размонтирования и повторного монтирования диска при каждом сбое программы.
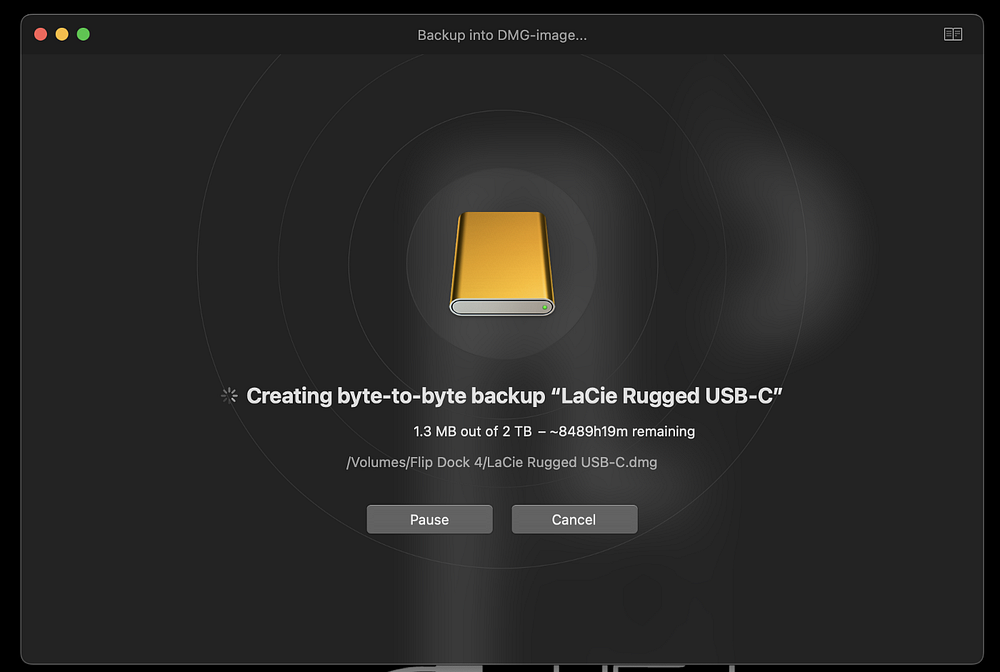
Обнадеживал тот факт, что диск все еще определялся и читался, хотя и медленно. В результате кропотливой работы выяснилось: копирование отдельных файлов работает и с относительно нормальной скоростью при условии, что они не повреждены. Таким образом, чтобы сохранить максимальный объем данных, нужно изучить каждый файл и попытаться его скопировать. Далее смотрим — работает ли он или вызывает ошибку I/O. Что-то получается! Но речь идет о 500 ГБ данных в самых разных каталогах, подкаталогах, под-под-под-подкаталогах…. К счастью, мы можем автоматизировать эту процедуру!
Решение Python
Поскольку проблема специфичная, то и скрипт для резервного копирования файлов пришлось писать конкретно под нее. Но отдельные компоненты решения могут пригодится для собратьев по несчастью в похожих ситуациях.
Последовательность действий скрипта.
1. Воспроизведение дерева каталогов в резервном каталоге iCloud
- Выбираем подмножество каталогов для резервного копирования.
- Для каждого найденного каталога создаем одноуровневый элемент в месте резервного копирования.
- Составляем список отдельных файлов с полными путями из каждого найденного каталога (для копирования на этапе 2).
- Сохраняем список файлов для последующего поиска и выборки.
Код для данного этапа:
import os
hd_folder = '/Volumes/CorruptedDrive/'
dest_folder = '/where/I/want/the/backup/to/go'
# Экономьте время, выполняя резервное копирование только действительно важного подмножества каталогов
important_folders = ['Completed Songs', 'Sound Effects', 'WIPs']
os.mkdir(dest_folder)
individual_files = []
for folder in important_folders:
print('NOW WALKING %s' % folder)
for root, dirs, files in os.walk(hd_folder+folder):
make_dir(root, hd_folder, dest_folder)
for f in files:
individual_files.append(root+'/'+f)
В зависимости от количества каталогов и подкаталогов данная процедура занимает какое-то время, но по итогу мы получаем список всех отдельных файлов с полными путями на жестком диске.
Этим вариантом мы заменили копирование каждого файла при обходе каталогов, поскольку оно предусматривает чрезмерно длительную процедуру резервного копирования и может сопровождаться частыми прерываниями из-за непредвиденных ошибок. В нашем же случае я просто один раз составляю список и обращаюсь к нему по ходу дальнейшей работы.
Не забудьте сохранить список в файл, если опасаетесь, что скрипт в какой-то момент перестанет работать! Поскольку я предпочитаю numpy, то сделала так:
import numpy as np
np.savetxt('individual_files.txt', np.array(individual_files), fmt='%s')
Можно рассмотреть еще более интересный вариант: записать каждый путь к файлу в самом цикле. Пусть это будет домашним заданием для тех “счастливчиков”, которым приходится воспроизводить этот скрипт.
2. Копирование каждого отдельного файла в местоположение его одноуровневого элемента на iCloud
- Загружаем список файлов.
- Инициализируем массив флагов для отслеживания процесса выполнения. Эта процедура помогает, если вы не знаете, какие ошибки перехватываете, и неперехваченные нарушают цикл. Кроме того, она пригодится для будущего анализа соотношения объемов восстановленных и потерянных данных диска.
- Используем конструкцию
try/exceptдля копирования каждого файла с обновлениями массива флагов в зависимости от успешного результата или перехваченных исключений.
Я быстро заметила, что не все подкаталоги были созданы в цикле os.walk(), поэтому сначала пришлось внести коррективы на основе списка файлов:
files = np.loadtxt('individual_files.txt', delimiter='\n', dtype='str')
for file in files:
newfile = file.replace(hd_folder, dest_folder)
flist = newfile.split('/')
# Следующий цикл проверяет, существуют ли каталоги на всех уровнях, доступных по имени файла
for i in range(2,len(flist)):
print('/'.join(flist[0:i]), os.path.isdir('/'.join(flist[0:i])))
if os.path.isdir('/'.join(flist[0:i])):
pass
else:
os.mkdir('/'.join(flist[0:i]))
Я также решила прописать логику для обработки файлов, которые слишком долго копируются. Они не выбрасывают ошибку, но замедляют весь процесс, чего хотелось бы избежать:
# Дополнительный код для вызова TimeOutException и копирования
import signal
import time
class TimeOutException(Exception):
pass
def alarm_handler(signum, frame):
print("ALARM signal received")
raise TimeOutException()
def copy_file(filename, root_dir, dest_dir):
newfile = filename.replace(root_dir, dest_dir)
shutil.copy2(filename, newfile)
time.sleep(1)
signal.signal(signal.SIGALRM, alarm_handler)
signal.alarm(300) # I give each file 5 minutes before timeout
Далее цикл резервного копирования:
import shutil
flags = np.zeros(len(files))
i = 0 # Отслеживание процесса выполнения загрузки списка файлов
j = 0 # Подсчет последовательно обнаруженных проблем с ошибкой "Файл не найден"
while i < len(files):
print('COPYING %s [%s/%s]' % (files[i], i, len(files)))
if flags[i] == 1 or os.path.exists(files[i].replace(hd_folder, dest_folder)):
print('File exists, skipping!')
flags[i] = 1
i+=1
else:
try:
copy_file(files[i], hd_folder, dest_folder)
flags[i] = 1
i+=1
j=0 # Сброс счетчика
except FileNotFoundError:
if j > 1:
print('File really not found, aborting.')
flags[i] = -1
i += 1
j = 0 # Сброс счетчика
else:
print('File not found, retrying %s/2...' % str(j+1))
time.sleep(120)
i = i
j += 1
except IOError:
print('I/O error, aborting')
flags[i] = -2
i += 1
except TimeOutException:
print('Timeout, aborting')
flags[i] = -3
i += 1
signal.alarm(0)
except Exception as ex:
print(ex)
flags[i] = -999
i += 1
finally:
signal.alarm(300)
Как видно, в коде отслеживаются несколько разных типов ошибок, и вот почему.
- Ошибка
FileNotFoundErrorвозникает в двух случаях: при произвольном размонтировании и повторном монтировании диска или при невозможности обнаружения файла. Для отслеживания обоих сценариев добавляется методtime.sleep(120), выделяющий время для повторного монтирования диска, а также счетчик(j), отсчитывающий количество попыток в поисках файла. Если его не удается обнаружить два раза подряд, он пропускается и отмечается флагом как ненайденный (флаг-1). - Ошибка
IOErrorприводит к установке флага, обозначающего, что файл поврежден или утерян (флаг-2). - Ошибка
TimeOutException. Каждому файлу выделяется 5 минут на копирование. В случае превышения этого лимита времени выбрасывается исключениеTimeOutExceptionи устанавливается флаг-3. К пропущенным файлам можно вернуться, если они просто слишком большие или чрезвычайно важные. - Все другие исключения отмечены флагом
-999, указывающим на то, что они не относятся к вышеперечисленным (и к ним можно вернуться позднее для более детального изучения).
Ну вот и все!
Этот простой подход на основе Python помог сохранить 78% важных данных на поврежденном внешнем диске, тогда как навороченные приложения не смогли восстановить даже один байт.

Что касается потраченного времени: написание скрипта — менее 30 минут, диагностика неисправностей — около 1 часа и само резервное копирование — 2 дня. Если вам кажется, что это слишком долго, то вспомните — Disk Drill планировал потратить на выполнение этой задачи 8489 часов. В зависимости от объема резервного копирования и запасов вашего терпения процедуру можно еще больше оптимизировать с помощью многопроцессорной обработки.
И все это бесплатно!
Читайте также:
- Как автоматизировать операции Kubernetes посредством Python
- Arduino и Visual Studio Code
- 10 полезных инструментов и библиотек для программистов и IT профессионалов
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Angela Kochoska: Corrupted Hard Drive? Python to the Rescue!





