
BERT — сегодня это одна из самых популярных и универсальных моделей ИИ. Однако из-за зависимости от операций слоя dense, точность и гибкость этой модели сопряжены с высокими вычислительными затратами.
Пытаясь решить эту проблему, в Graphcore Research на основе BERT разработали новую модель GroupBERT с групповыми преобразованиями, делающими ее идеальной для интеллектуального процессора. В GroupBERT улучшенная структура Transformer сочетается с эффективными групповыми свертками и перемножениями матриц. Пользователям интеллектуального процессора это позволяет сократить параметры модели практически вдвое, а время обучения — на 50 % при том же уровне точности.
Улучшенная BERT с интеллектуальным процессором
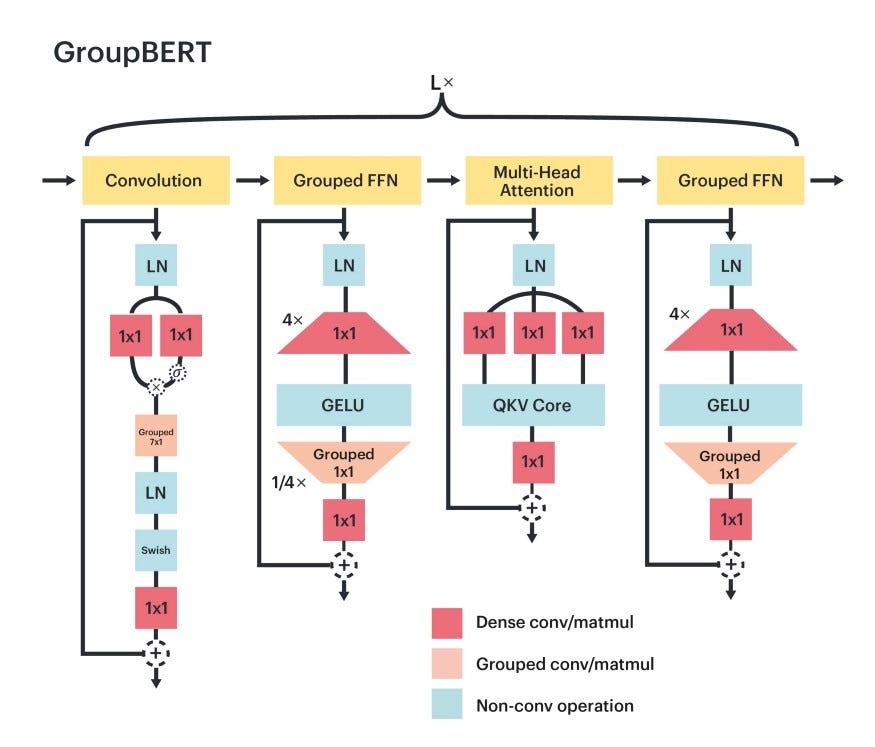
В этой работе показано, как с помощью интеллектуального процессора в Graphcore Research изучают очень эффективные и легковесные строительные блоки для получения структуры энкодера Transformer, которая более эффективна при маскированном предобучении на очень большом корпусе текстов.
Как в GroupBERT выполняются групповые преобразования? Полносвязные модули дополняются групповыми перемножениями матриц, а в структуре Transformer появляется новый модуль свертки. Поэтому каждый слой GroupBERT расширен не до двух модулей, как в исходной модели BERT, а до четырех.
В GroupBERT значительно улучшено соотношение между операциями с плавающей точкой в секунду и результатами выполнения задач, которое измеряется потерей валидации. Чтобы достичь того же значения потерь, GroupBERT требуется менее половины таких операций обычной модели BERT, в которой не задействуется потенциал ее глубины и используются только операции слоя dense.
В связи с большей глубиной и меньшей арифметической интенсивностью компонентов GroupBERT возросла важность доступа к памяти. По сравнению с операциями слоя dense, в групповых операциях меньше операций с плавающей точкой в секунду для входного тензора активации. Чтобы выполнять эти операции, имеющие низкую арифметическую интенсивность, требуется более быстрый доступ к данным, чем при вычислениях слоя dense.
Интеллектуальный процессор позволяет записывать все веса и активации на внутрипроцессорное статическое ОЗУ с очень высокой пропускной способностью 47,5 Тб/с. Поэтому теоретическое преимущество в эффективности GroupBERT можно перевести в практическое сокращение времени обучения на самых разных моделях.
Сгруппированные полносвязные слои
Исходный слой энкодера Transformer состоит из двух модулей: многоголового внимания и полносвязной сети.
Во многих работах акцент сделан на повышении эффективности этого слоя. Так, в работе Tay et al. (2020) описываются разнообразные подходы, большинство модификаций которых направлены на сокращение квадратичной вычислительной зависимости модуля многоголового внимания от длины последовательности.
В BERT же большая часть вычислений выполняется с относительно небольшой длиной последовательности — 128, а модулем полносвязной сети потребляется гораздо больше ресурсов — на него приходится почти ⅔ операций с плавающей точкой в секунду во время выполнения модели.
Структура модуля полносвязной сети очень проста: две матрицы и нелинейность. В первой матрице представление проецируется на более крупную размерность — обычно в четыре раза большую, чем скрытое представление модели.
За этой операцией расширения размерности следует функция активации без насыщения, которой выполняется нелинейное преобразование представления и его разреживание.
Наконец — посредством матрицы, в которой осуществляется проецирование на меньшую размерность, — разреженное расширенное представление сжимается до размерности модели.
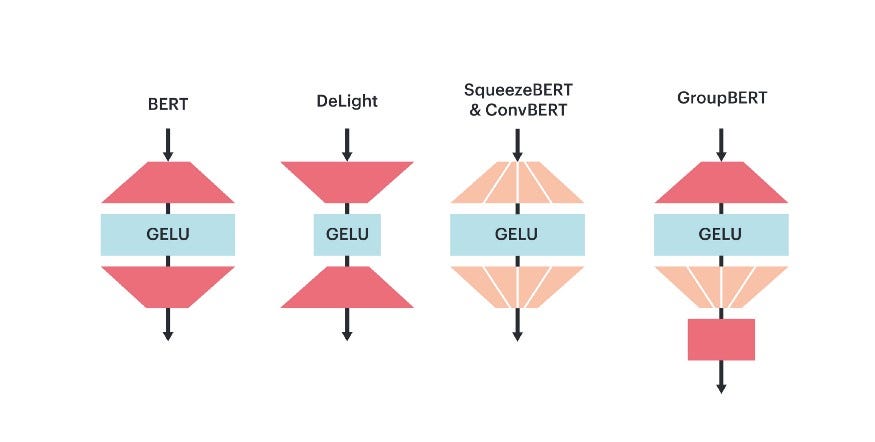
В GroupBERT появилась новая схема, по которой вычисления в полносвязной сети выполняются дешевле и быстрее. Ключевой вывод: разреженность, к которой приводит группирование, лучше применяется к матрицам, получающим разреженные входные данные. Поэтому групповое перемножение матриц представлено только для второй матрицы (где выполняется проецирование на меньшую размерность), так что она становится блочно-диагональной.
Однако групповые операции приводят к ограничению локальности во входящем скрытом представлении, лимитируя распространение информации канала во время преобразования. Для решения этой проблемы группы смешиваются с тем, что проецируется на выходе, наподобие блока многоголового внимания, где скрытое представление тоже разделяется на много голов.
В целом эта схема сгруппированной полносвязной сети позволяет GroupBERT сократить число параметров слоя полносвязной сети на 25 % при минимальном снижении результатов выполнения задач. Она отличается от всех предыдущих методов, где делались попытки применять групповые преобразования, но к обеим матрицам. В результате получалось несвязное скрытое представление со значительным падением производительности:
Групповая свертка как дополнение к механизму внимания
Вычисление внимания «все со всеми» для длин последовательностей в BERT не приводит к значительным вычислительным затратам.
Однако в недавнем исследовании (Cordonnier et al. 2020) было показано, что использование только многоголового внимания может быть избыточным — в первую очередь для языковых моделей. Часть голов внимания в слое Transformer переходит в сверточный режим — для моделирования исключительно локальных взаимодействий токенов.
Чтобы уменьшить избыточность вычисления карт внимания слоя dense — для моделирования локального взаимодействия внутри последовательности — в GroupBERT появился специальный модуль свертки. Групповая свертка выступает в роли скользящего окна, смешивая информацию между близкими друг к другу лексемами слов.
Затем в энкодер добавляется дополнительная сгруппированная полносвязная сеть, следующая за модулем свертки. Это обеспечивает соединение каждого модуля обработки токенов с модулем сгруппированной полносвязной сети обработки функций.
Благодаря этим дополнительным модулям у локальных взаимодействий токенов появляется специальный легковесный элемент модели. Это, в свою очередь, улучшает результаты механизма многоголового внимания при моделировании только дальних взаимодействий — ведь на локальные взаимодействия токенов тратится меньше емкости внимания.
На рисунке 3 показаны карты внимания по валидационному множеству предобучения из BERT и GroupBERT. Здесь четко видно, как свертки делают внимание более эффективным при дальних взаимодействиях — рисунок более плавный и равномерно распределенный:

Заставляем параметры модели считать
Нормализация
Во многих работах рассматривался лучший способ применения нормализации в Transformer. И хотя предпочтительный метод нормализации — это всегда нормализация слоя, есть два варианта ее применения: PreNorm и PostNorm.
В PostNorm нормализуется вывод суммы соединения быстрого доступа и блока residual, а в PreNorm — представление ветви блока residual перед применением любых проекций внутри (см. рисунок 4):

В стандартной реализации BERT применяется PostNorm, где результаты выполнения задач лучше, чем у PreNorm, при стандартной скорости обучения. Но мы обнаружили, что конфигурация PreNorm гораздо стабильнее и может работать на более высоких скоростях обучения, недоступных для модели PostNorm.
В GroupBERT применяется PreNorm и достигаются более высокие результаты выполнения задач: в модели теперь может стабильно обеспечиваться увеличение скорости обучения в 4 раза по сравнению с базовым уровнем PostNorm, в котором на таких высоких скоростях обучения имеет место расхождение. Более высокие скорости обучения важны для улучшения обобщения модели и достижения более высокой скорости сходимости.
Но более высокие скорости обучения не ведут к экономии вычислительных затрат напрямую. Ведь для более высоких результатов выполнения задач требовалась бы модель покрупнее, что чревато ростом вычислительных затрат. А вот когда более высокие скорости обучения достигаются за счет повышения стабильности модели, это ведет к повышению эффективности использования параметров модели.
Прореживание
Во многих языковых моделях, основанных на архитектуре Transformer, применяется прореживание: оно сокращает переобучение набора данных для обучения и способствует обобщению. Но BERT предобучена на очень большом наборе данных, и в этом случае переобучение — обычно не проблема. Поэтому во время предобучения прореживание из GroupBERT убирается.
Операции с плавающей точкой в секунду, связанные с умножением масок прореживания, несущественны: эту оптимизацию по отношению к таким операциям также можно считать нейтральной. Однако генерирование масок прореживания может вести к значительным накладным расходам пропускной способности, поэтому устранение этого метода регуляризации в BERT целесообразно для убыстрения модели и улучшения результатов выполнения задач.
Хотя предобучение на наборе данных «Википедии» предпочтительно проводить без прореживания, последнее остается очень важным инструментом при дообучении GroupBERT: наборы данных дообучения на несколько порядков меньше, чем корпус предобучения.
GroupBERT — трансформер с интеллектуальным процессором
Прежде чем объединять все описанные выше модификации в единую модель, проверим эффективность каждого компонента.
Но сгруппированные полносвязные сети сокращают число выполняемых в модели операций с плавающей точкой в секунду, а добавление модуля свертки — увеличивает. По этой причине прямое сравнение с BERT некорректно, ведь модели могут потреблять неодинаковое количество ресурсов.
Чтобы определить качество улучшений в моделях разных размеров, нужно сопоставить их с логарифмической интерполяцией между средними, базовыми и крупными моделями BERT.
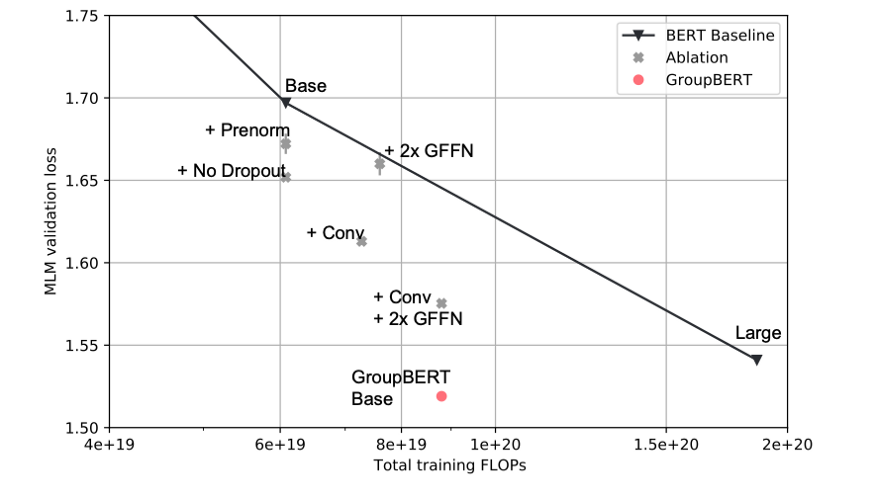
На рисунке 5 представлено исследование фрагментарной абляции каждого улучшения, появившегося в GroupBERT. При каждом добавлении в модель эффективность по Парето в сравнении с базовым уровнем BERT растет. А в базовой GroupBERT Base те же потери валидации MLM (моделей машинного обучения), что и в крупной модели BERT Large, хоть у нее и менее 50 % параметров:
Чтобы окончательно убедиться в неизменном превосходстве GroupBERT над BERT и другими моделями, где делались попытки применять групповые преобразования в Transformer, мы показываем на рисунке 6, что преимущество GroupBERT Base над BERT Large сохраняется в моделях разных масштабов. Для этого добавляем к базовой модели GroupBERT Base еще две отличающиеся по размерам, создавая сплошной Парето-фронт:
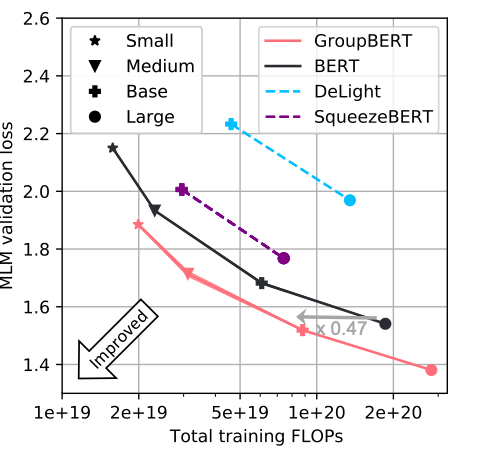
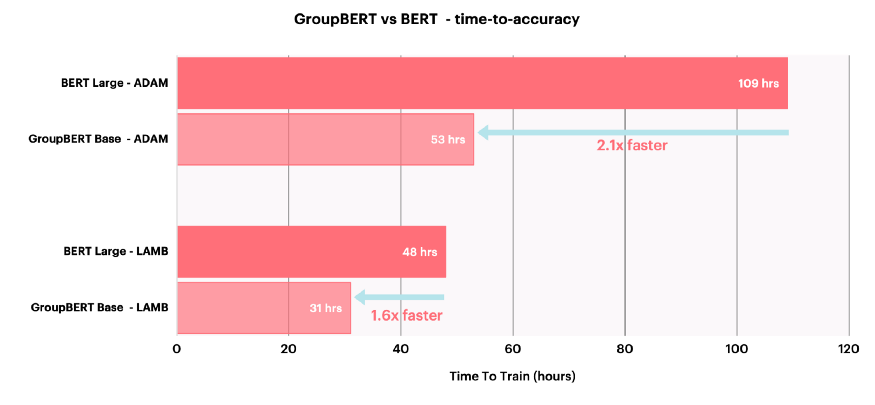
GroupBERT — модель с интеллектуальным процессором, поэтому теоретическая экономия в том, что касается операций с плавающей точкой в секунду, выражается также в сокращении времени сквозного предобучения, необходимого для достижения заданного уровня точности валидации:
Главные выводы
Результаты показывают, что:
- с помощью групповых преобразований могут создаваться гораздо более эффективные модели;
- сочетание сверток со вниманием «все со всеми» слоя
denseположительно сказывается даже на задачах, в которых требуются дальние взаимодействия; - с помощью интеллектуального процессора теоретическая экономия в операциях с плавающей точкой в секунду переводится в практическое сокращение вычислительного времени;
- значительного роста производительности можно добиться скорее за счет улучшения архитектуры, нежели простого изменения масштабов модели.
В итоге GroupBERT позволяет добиться почти 2-кратного улучшения — в сравнении с исходной моделью BERT — по производительности предобучения, обеспечивая более быстрые и эффективные вычисления.
Читайте также:
- Тематическое моделирование с помощью BERT
- BERT - коротко о главном
- Как обучить модель квантового МО, используя данные из CSV?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Ivan Chelombiev: Getting more bang for your buck out of pre-trained language models with GroupBERT





