
Контент-платформы успешно развиваются за счет предоставления пользователям востребованного ими материала. Чем больше актуального контента размещается на платформе, тем дольше пользователь остается на сайте, что в свою очередь зачастую приводит к увеличению доходов компании.
Если вы когда-либо посещали новостной веб-сайт, интернет-издание или блог-платформу, то наверняка сталкивались с работой рекомендательного движка. Он учитывает содержание вашей истории просмотров и предлагает дополнительный контент, способный вас заинтересовать.
В качестве простого решения можно рассмотреть реализацию платформой рекомендательного движка на основе тегов. Например, вы прочитали статью с тегом “Бизнес” — и вот вам еще 5 дополнительных публикаций из этой области. Однако поиск по сходству и алгоритм МО являются более эффективным подходом к разработке такого рода инструмента.
В ближайшее время мы займемся сборкой приложения Flask на Python, которое задействует Pinecone, сервис поиска по сходству, для создания своего собственного рекомендательного движка статей.
Общий обзор демонстрационного приложения
Ниже представлена краткая анимация, отображающая принцип работы нашего демонстрационного приложения. Изначально на странице дан перечень из 10 статей. Пользователь может скомбинировать их любым способом и поместить в историю просмотров. При нажатии на кнопку Submit эта история используется в качестве входной информации для запроса базы данных публикаций, вслед за чем происходит вывод еще 10 дополнительных статей.

Как видно, предлагаемые тематически смежные статьи отличаются исключительной точностью! В этом примере возможны 1024 комбинации истории просмотров, которые могут использоваться в качестве входных данных, и каждая из них выдает содержательные результаты.
Итак, как же нам это удалось?
Работа над приложением началась с поиска датасета новых статей на Kaggle. Используемый для наших целей вариант содержит 143 000 свежих публикаций из 15 главных интернет-изданий, но мы ограничились лишь первыми 20 000. (Исходный же датасет, частью которого является выбранный набор данных, насчитывает свыше 2 млн статей!)
На следующем этапе мы подредактировали датасет, переименовав парочку столбцов и удалив ненужные из них. Далее для создания векторных представлений (метаданных для алгоритмов МО, выявляющих сходство между различными видами входной информации) пропустили статьи через соответствующую модель обучения GloVe, после чего вставили эти векторные представления в векторный индекс, управляемый Pinecone.
Таким образом мы все подготовили для поиска тематически связанного контента. При отправки пользователем истории просмотров происходит запрос к конечной точке API, использующей SDK Pinecone для уточнения индекса векторных представлений. В результате она возвращает 10 новых похожих статей и отображает их в UI приложения. Вот и весь процесс! Довольно просто, не так ли?
Если хотите поэкспериментировать, то можете ознакомиться с полным вариантом кода приложения на GitHub. Файл README содержит инструкции по запуску приложения на локальном компьютере.
Пошаговый разбор кода демонстрационного приложения
Итак, мы познакомились с механизмом внутренней работы приложения. Теперь же углубимся в процесс его разработки. Как ранее упоминалось, у нас приложение Flask на Python, задействующее SDK Pinecone. HTML использует файл шаблона, а остальная часть фронтенда создается с помощью статических активов CSS и JS. В целях упрощения весь код бэкенда находится в файле app.py, который представлен ниже:
from dotenv import load_dotenv
from flask import Flask
from flask import render_template
from flask import request
from flask import url_for
import json
import os
import pandas as pd
import pinecone
import re
import requests
from sentence_transformers import SentenceTransformer
from statistics import mean
import swifter
app = Flask(__name__)
PINECONE_INDEX_NAME = "article-recommendation-service"
DATA_FILE = "articles.csv"
NROWS = 20000
def initialize_pinecone():
load_dotenv()
PINECONE_API_KEY = os.environ["PINECONE_API_KEY"]
pinecone.init(api_key=PINECONE_API_KEY)
def delete_existing_pinecone_index():
if PINECONE_INDEX_NAME in pinecone.list_indexes():
pinecone.delete_index(PINECONE_INDEX_NAME)
def create_pinecone_index():
pinecone.create_index(name=PINECONE_INDEX_NAME, metric="cosine", shards=1)
pinecone_index = pinecone.Index(name=PINECONE_INDEX_NAME)
return pinecone_index
def create_model():
model = SentenceTransformer('average_word_embeddings_komninos')
return model
def prepare_data(data):
# переименовываем id столбцов и удаляем ненужные из них
data.rename(columns={"Unnamed: 0": "article_id"}, inplace = True)
data.drop(columns=['date'], inplace = True)
# из каждой статьи извлекаем только несколько первых предложений для ускорения векторных вычислений
data['content'] = data['content'].fillna('')
data['content'] = data.content.swifter.apply(lambda x: ' '.join(re.split(r'(?<=[.:;])\s', x)[:4]))
data['title_and_content'] = data['title'] + ' ' + data['content']
# создаем векторное представление на основе названия и столбцов статьи
encoded_articles = model.encode(data['title_and_content'], show_progress_bar=True)
data['article_vector'] = pd.Series(encoded_articles.tolist())
return data
def upload_items(data):
items_to_upload = [(row.id, row.article_vector) for i, row in data.iterrows()]
pinecone_index.upsert(items=items_to_upload)
def process_file(filename):
data = pd.read_csv(filename, nrows=NROWS)
data = prepare_data(data)
upload_items(data)
pinecone_index.info()
return data
def map_titles(data):
return dict(zip(uploaded_data.id, uploaded_data.title))
def map_publications(data):
return dict(zip(uploaded_data.id, uploaded_data.publication))
def query_pinecone(reading_history_ids):
reading_history_ids_list = list(map(int, reading_history_ids.split(',')))
reading_history_articles = uploaded_data.loc[uploaded_data['id'].isin(reading_history_ids_list)]
article_vectors = reading_history_articles['article_vector']
reading_history_vector = [*map(mean, zip(*article_vectors))]
query_results = pinecone_index.query(queries=[reading_history_vector], top_k=10)
res = query_results[0]
results_list = []
for idx, _id in enumerate(res.ids):
results_list.append({
"id": _id,
"title": titles_mapped[int(_id)],
"publication": publications_mapped[int(_id)],
"score": res.scores[idx],
})
return json.dumps(results_list)
initialize_pinecone()
delete_existing_pinecone_index()
pinecone_index = create_pinecone_index()
model = create_model()
uploaded_data = process_file(filename=DATA_FILE)
titles_mapped = map_titles(uploaded_data)
publications_mapped = map_publications(uploaded_data)
@app.route("/")
def index():
return render_template("index.html")
@app.route("/api/search", methods=["POST", "GET"])
def search():
if request.method == "POST":
return query_pinecone(request.form.history)
if request.method == "GET":
return query_pinecone(request.args.get("history", ""))
return "Only GET and POST methods are allowed for this endpoint"Рассмотрим и поясним основные части файла app.py:
Строки 1–14. Импортируем зависимости, на которых базируется приложение.
dotenvдля чтения переменных среды из файла.env;flaskдля настройки веб-приложения;jsonдля работы с JSON;osтакже для получения переменных среды;pandasдля взаимодействия с датасетом;pineconeдля SDK Pinecone;reдля работы с регулярными выражениями (RegEx)requestsдля выполнения API запросов с целью скачивания датасета;statisticsдля полезных статистических методов;sentence_transformersдля модели векторного представления данных;swifterдля работы с датафреймом pandas.
Строка 16. Предоставляем шаблонный код, сообщая Flask имя приложения.
Строки 18–20. Определяем ряд констант, используемых в приложении: имя индекса Pinecone, имя файла датасета и количество строк для чтения из файла CSV.
Строки 22–25. Метод initialize_pinecone получает ключ API из файла .env и применяет его для инициализации Pinecone.
Строки 27–29. Метод delete_existing_pinecone_index ищет в экземпляре Pinecone имеющиеся индексы с таким же именем, как article-recommendation-service. По мере их нахождения они удаляются.
Строки 31–35. Метод create_pinecone_index создает новый индекс, задействуя выбранное имя article-recommendation-service, метрику сходства cosine и только один шард.
Строки 37–40. Метод create_model использует библиотеку sentence_transformers для работы с моделью GloVe, с помощью которой мы в дальнейшем закодируем векторные представления.
Строки 62–68. Метод process_file считывает файл CSV и затем вызывает методы prepare_data и upload_items, о которых речь пойдет далее.
Строки 42–56. Метод prepare_data вносит корректировки в датасет, переименовывая столбец id и удаляя столбец date. После этого он берет первые четыре строки каждой статьи и объединяет их с ее названием, тем самым формируя новое поле, которое послужит данными для кодирования. Можно было бы создать векторные представления на основе всего тела статьи, но для ускорения процесса ограничимся указанным количеством.
Строки 58–60. Благодаря методу upload_items мы получаем векторные представления для каждой статьи путем ее кодирования с помощью модели. Далее они вставляются в индекс Pinecone.
Строки 70–74. Методы map_titles и map_publications генерируют словари заголовков и названий изданий для упрощения поиска статей по их ID.
Каждый из описанных выше методов вызывается в строках 98–104, когда запускается бэкенд приложения. Этот спектр действий готовит нас к заключительному этапу, подразумевающему выполнение фактического запроса индекса Pinecone на основе пользовательского ввода.
Строки 106–116. Определяем два маршрута для приложения: для главной страницы и конечной точки API. Главная страница обеспечивает файл шаблона index.html наряду с активами JS и CSS, а конечная точка API предоставляет возможность поиска для запроса индекса Pinecone.
И наконец, в строках 76–96 метод query_pinecone принимает на вход историю просмотров пользователя, преобразует ее в векторное представление и запрашивает индекс Pinecone для поиска похожих статей. Метод вызывается в момент обращения к конечной точке /api/search, что происходит каждый раз при отправке пользователем нового поискового запроса.
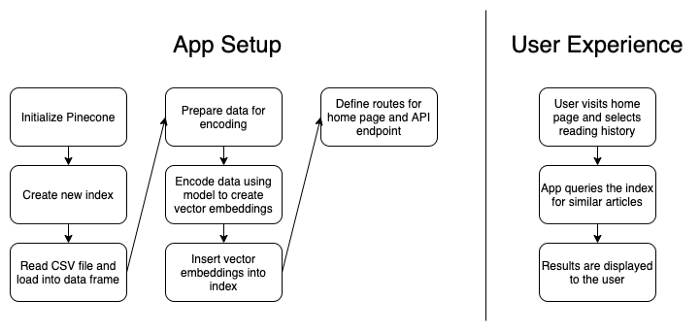
Визуально схема рабочего процесса приложения выглядит следующим образом:
Настройка приложения: Инициализация Pinecone — Генерация нового индекса — Считывание файла CSV и загрузка в датафрейм — Подготовка данных для кодирования — Кодирование данных с помощью модели для создания векторных представлений — Включение векторных представлений в индекс — Определение маршрутов для главной страницы и конечной точки API.
Опыт пользователя: Пользователь заходит на главную страницу и выбирает историю просмотров — Приложение запрашивает индекс похожих статей — Отображение результатов
Примерные сценарии
Подводя итоги, разъясним, как все-таки выглядит опыт пользователя. Рассмотрим 3 сценария с учетом его увлечений спортом, технологиями и политикой.
В качестве своей истории просмотров фанат спорта выбирает первые 2 статьи об известных теннисистах Серене Уильямс и Энди Маррее. После отправки этих вариантов приложение предлагает ему в ответ статьи об Уимблдоне, US Open (открытом чемпионате США по теннису), Роджере Федерере и Рафаэле Надале. Прям в яблочко!
Любитель технологий предпочитает статьи о Samsung и Apple, вследствие чего приложение ему выдает материалы о Samsung, Apple, Google, Intel и iPhones. И снова удачная подборка!
Интересующийся политикой пользователь делает выбор в пользу одной статьи про фальсификацию результатов голосования. В этом случае приложение реагирует серией материалов об ID участников голосования, выборах в США 2020 года, явке избирателей и доказательствах нарушений на выборах (и их необоснованности).
Три из трех! Наш рекомендательный движок работает очень эффективно.
Заключение
Мы создали простое приложение для решения насущных задач. Если сайты смогут дополнительно предлагать пользователю интересующий его контент, то помимо еще большего удовлетворения от предоставляемых материалов он будет дольше оставаться на сайте, что приведет к увеличению прибыли компании. И все в выигрыше!
Подход, основанный на поиске по сходству, способствует подборке более точных рекомендаций в соответствии с запросами пользователя. А сервис Pinecone как раз облегчает выполнение этой задачи, позволяя сосредоточиться на том, что вам удается лучше всего — разработке интересной платформы с качественным информативным содержанием.
Читайте также:
- Привет, новый мир «Искусственного интеллекта»
- Машинное обучение. С чего начать?
- Топ-10 курсов по машинному и глубокому обучению в 2020
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tyler Hawkins: Build an Article Recommendation Engine With AI/ML





